随机森林实现回归预测(糖尿病数据集)
文章目录
-
- **1.实验简介**
- **2.算法分析**
- **3.具体实现**
- **4.代码**
- **5.结果分析**
1.实验简介
本次实验需要实现一个随机森林模型并在糖尿病数据集上进行回归预测。
2.算法分析
随机森林是由N颗简单的决策树组合而成,对于分类任务随机森林的输出可以采用简单的投票法决定随机森林的预测值;对于回归任务来说,就是把N颗回归决策树的输出结果进行平均。
对于随机森林来进行回归任务,可以分两个部分来实现。第一部分我们先实现回归决策树,第二部分在回归决策树的基础上实现回归随机森林。
3.具体实现
3.1 回归决策树
在上一次实验的分类决策树基础上实现回归决策树有以下的改变:
- 增益的衡量 在这里我们用方差来替代
- 叶子节点的预测值由占多数的类别改为平均值
- 在寻找最佳属性及其阈值时,直接取实际的数据作为候选阈值,不用排序再取两个数据的均值
- 划分过的属性在之后的划分还能继续使用
- 因为没有了属性使用的限制,需要实现树的深度的控制max_depth这个参数。另外,也需实现min_samples这个参数
3.2 回归随机森林
回归森林使用N棵回归决策树, 这里有两点需要注意:
-
样本的随机性
对于每棵树输入的数据需要是不同的,如果对N棵树输入同样的数据,那得出的结果都是一样的,随机森林也就没有了意义。所以,对于每一棵树,使用的数据是训练集通过随机有放回的采样得到的。 -
属性的随机性
寻找最优划分属性时,先随机选出一部分,再在这一部分中选取增益最大属性的。
4.代码
import math
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestRegressor # 导入随机森林训练模型
from sklearn.metrics import r2_score # 使用拟合优度r2_score对实验结果进行评估
from sklearn.model_selection import train_test_split
from sklearn import datasets
class DecisionNode(object):
def __init__(self, f_idx, threshold, value=None, L=None, R=None):
self.f_idx = f_idx
self.threshold = threshold
self.value = value
self.L = L
self.R = R
# 改变:不需要排序,取实际的数据作为划分点
def find_best_threshold(dataset: np.ndarray, f_idx: int): # dataset:numpy.ndarray (n,m+1) x<-[x,y] f_idx:feature index
best_gain = -math.inf # 先设置 best_gain 为无穷小
best_threshold = None
candidate = list(set(dataset[:, f_idx].reshape(-1)))
for threshold in candidate:
L, R = split_dataset(dataset, f_idx, threshold) # 根据阈值分割数据集,小于阈值
gain = calculate_var_gain(dataset, L, R) # 根据数据集和分割之后的数
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大
best_gain = gain
best_threshold = threshold
return best_threshold, best_gain
def calculate_var(dataset: np.ndarray):
y_ = dataset[:, -1].reshape(-1)
var = np.var(y_)
return var
def calculate_var_gain(dataset, l, r):
var_y = calculate_var(dataset)
var_gain = var_y - len(l) / len(dataset) * calculate_var(l) - len(r) / len(dataset) * calculate_var(r)
return var_gain
def split_dataset(X: np.ndarray, f_idx: int, threshold: float):
L = X[:, f_idx] < threshold
R = ~L
return X[L], X[R]
def mean_y(dataset):
y_ = dataset[:, -1]
return np.mean(y_)
def build_tree(dataset: np.ndarray, f_idx_list: list, depth, max_depth, min_samples): # return DecisionNode 递归
# 怎么判断depth
class_list = [data[-1] for data in dataset] # 类别 dataset 为空了,
n, m = dataset.shape
k = int(math.log(m, 2)) + 1
if n < min_samples:
return DecisionNode(None, None, value=mean_y(dataset))
elif depth > max_depth:
return DecisionNode(None, None, value=mean_y(dataset))
# 全属于同一类别
elif class_list.count(class_list[0]) == len(class_list):
return DecisionNode(None, None, value=mean_y(dataset))
else:
# 找到使增益最大的属性
best_gain = -math. inf
best_threshold = None
best_f_idx = None
# 选取部分属性进行最优划分
f_idx_list_random = list(np.random.choice(m-1, size=k, replace=False))
for i in f_idx_list_random:
threshold, gain = find_best_threshold(dataset, i)
if gain > best_gain: # 如果增益大于最大增益,则更换最大增益和最大阈值
best_gain = gain
best_threshold = threshold
best_f_idx = i
# 创建分支
L, R = split_dataset(dataset, best_f_idx, best_threshold)
if len(L) == 0:
depth += 1
L_tree = DecisionNode(None, None, mean_y(dataset)) # 叶子节点
else:
depth += 1
L_tree = build_tree(L, f_idx_list, depth, max_depth, min_samples) # return DecisionNode
if len(R) == 0:
R_tree = DecisionNode(None, None, mean_y(dataset)) # 叶子节点
else:
R_tree = build_tree(R, f_idx_list, depth, max_depth, min_samples) # return DecisionNode
return DecisionNode(best_f_idx, best_threshold, value=None, L=L_tree, R=R_tree)
def predict_one(model: DecisionNode, data):
if model.value is not None:
return model.value
else:
feature_one = data[model.f_idx]
branch = None
if feature_one >= model.threshold:
branch = model.R # 走右边
else:
branch = model.L # 走左边
return predict_one(branch, data)
# 有放回随机采样
def random_sample(dataset):
n, _ = dataset.shape
sub_data = np.copy(dataset)
random_data_idx = np.random.choice(n, size=n, replace=True) # 0~(n-1) 产生n个 有放回采样
sub_data = sub_data[random_data_idx]
return sub_data[:, 0:-1], sub_data[:, -1]
class Random_forest(object):
def __init__(self, min_samples, max_depth):
self.min_samples = min_samples # 节点样本数量少于 min_samples, 叶子节点
self.max_depth = max_depth # 最大深度
def fit(self, X: np.ndarray, y: np.ndarray) -> None:
dataset_in = np.c_[X, y]
f_idx_list = [i for i in range(X.shape[1])]
depth = 0
self.my_tree = build_tree(dataset_in, f_idx_list, depth, self.max_depth, self.min_samples)
def predict(self, X: np.ndarray) -> np.ndarray: # 递归 how?
predict_list = []
for data in X:
predict_list.append(predict_one(self.my_tree, data))
return np.array(predict_list)
if __name__ == "__main__":
X, y = datasets.load_diabetes(return_X_y=True)
y_predict_list = []
r2_score_list = []
tree_number = []
MAE_list = []
MAPE_list = []
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
print(y_test.shape) # 89*1
dataset = np.c_[X_train, y_train]
np.seterr(divide='ignore', invalid='ignore')
T = 100
for i in range(T):
X_train_samples, y_train_samples = random_sample(dataset)
m = Random_forest(min_samples=5, max_depth=20)
m.fit(X_train_samples, y_train_samples)
y_predict = m.predict(X_test)
y_predict_list.append(y_predict) # 二维数组
print("epoc", i+1, " done")
y_ = np.mean(y_predict_list, axis=0) # 当前的预测值
score = r2_score(y_test, y_)
r2_score_list.append(score)
tree_number.append((i + 1))
errors = abs(y_ - y_test)
MAE_list.append(np.mean(errors)) # 平均绝对误差
mape = 100 * (errors / y_test)
MAPE_list.append(np.mean(mape)) # 平均绝对百分比误差
#
# print("r2_score_list", r2_score_list)
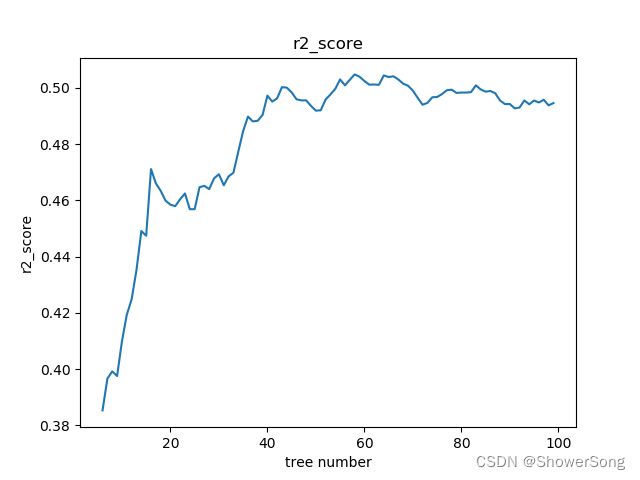
plt.plot(tree_number[5:-1], r2_score_list[5:-1])
plt.title('r2_score')
plt.xlabel('tree number')
plt.ylabel('r2_score')
plt.show()
# print("MAE_list", MAE_list)
#
# print("MAPE_list", MAPE_list)
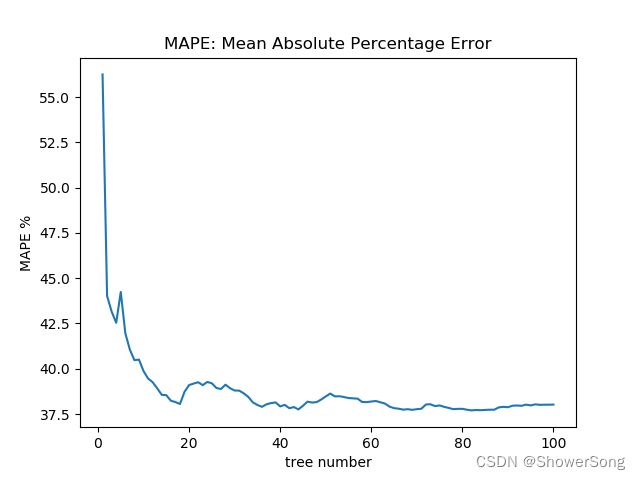
plt.plot(tree_number, MAPE_list)
plt.xlabel('tree number')
plt.ylabel('MAPE %')
plt.title("MAPE: Mean Absolute Percentage Error")
plt.show()
y_result = np.mean(y_predict_list, axis=0) # 最终结果
print("r2_score:", r2_score(y_test, y_result))
errors1 = abs(y_result - y_test) # 平均绝对误差
print('Mean Absolute Error:', np.round(np.mean(errors1), 2), 'degrees.')
mape = 100 * (errors1 / y_test) # 平均绝对百分比误差
print('MAPE:', np.round(np.mean(mape), 2), '%.')
# accuracy = 100 - np.mean(mape)
# print('Accuracy:', round(accuracy, 2), '%.')
# ---------------------------画图------------------------------
plt.figure(figsize=(20, 5))
plt.plot([i for i in range(y_test.shape[0])], y_test, color='red', alpha=0.8, label="y_test")
plt.plot([i for i in range(y_test.shape[0])], y_result, color='blue', alpha=0.8, label="y_result")
plt.legend(loc="upper right")
plt.title("My Random forest")
plt.show()
# ----------------------------------sklearn--------------------------------
regressor = RandomForestRegressor(n_estimators=100, min_samples_leaf=5)
regressor.fit(X_train, y_train) # 拟合模型
y_pred = regressor.predict(X_test)
print('sklearn score:{}'.format(r2_score(y_test, y_pred))) # 显示训练结果与测试结果的拟合优度
errors = abs(y_pred - y_test)
# Print out the mean absolute error (mae)
print('Mean Absolute Error:', np.round(np.mean(errors), 2), 'degrees.')
mape = 100 * (errors / y_test)
accuracy = 100 - np.mean(mape)
print('Accuracy:', round(accuracy, 2), '%.')
# ---------------------------画图------------------------------
plt.figure(figsize=(20, 5))
plt.plot([i for i in range(y_test.shape[0])], y_test, color='red', alpha=0.8, label="y_test")
plt.plot([i for i in range(y_test.shape[0])], y_pred, color='blue', alpha=0.8, label="y_pred")
plt.legend(loc="upper right")
plt.title("sklearn RandomForestRegressor")
plt.show()
5.结果分析
5.1 与sklearn自带的随机森林模块对比
这里绘制了两张折线图,展现了真实值与预测值的差别,可以看出:
- 两种方法的真实值与预测值的走势轨迹都大致相同。
- 上下两幅图的预测值走势是基本相同的,看出两种方法预测出的结果差别不大。
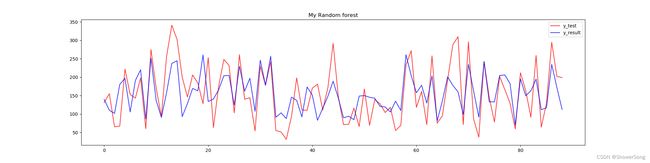

下表也能看出两种方法得出的结果差别不大

5.2 决策树数目对随机森林的影响
下面两幅图分别是r2_score和MAPE随决策树数目的变化曲线图。可以看出从1-20棵树变化时,两幅图的曲线都变化很快,快速收敛。在达到40棵树时,收敛效果都已经很好了,再增加的基分类器(决策树)的数目,效果基本不会提升。