目标识别及yolov5总结
一、目标识别总结
本着好记性不如烂笔头的原则,我对学习目标识别和yolov5的内容进行总结,以下内容总结自黄海广博士所整理的吴恩达老师深度学习ppt上的内容,图片间接来源于吴恩达老师深度学习课程ppt上,其中有一张图来源于白勇老师的腾讯课堂,正文中会指出。
1.早期的滑动窗口目标检测
选择不同尺寸的窗安装一定步长遍历整幅图片,对从窗口截取出的一张张小图片再进行卷积并最后进行分类,确定图片中是否有(用0或1表示)小汽车,理论上说尝试不同尺寸的窗口,总能框出小汽车。
缺点:对每个剪切出的小图片都运用卷积,切滑窗需要时间,计算成本过高。

2.滑动窗口卷积实现
原本是滑窗后逐个单独进行卷积运算,最终分别进行全连接和softmaxt,对于全连接,如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。
但其实全连接可以只用一次卷积实现对所有窗口的卷积计算
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络全连接层转化成卷积层
其实就是采用了1x1的卷积核,比如用4个卷积核对1x1x400的图像做卷积就可以得到1x1x4的tensor,其中的的元素,进行softmax后就代表了4个类别(比如行人,汽车,摩托车,背景)各自的概率。

下面以16x16x3的图片作为输入,对其做4次上述的卷积运算既可以得到2x2x4的结果

但其实4次中很多计算是共享的,只用做一次就可以,假设原始图片28x28x3我们只要做一轮卷积运算就可以,就可以得出多次先滑窗后卷积的结果。比如最后的8x8x4的最上层8像素等同于对原始28x28x3图片按照14x14大小的窗口滑动8次,并对产生的8个小图分别卷积的结果。



滑窗方式总结:
对于如下图片原本需要用14x14的窗口做滑窗->剪切->送入卷积网络的处理,现在我们可以一轮做完所有的这种操作,只需用14x14的卷积核最整张图片进行卷积处理即可产生单独滑窗->卷积的效果

3.Bounding box 预测
第2部分滑动窗口时离散的位置集合,有的框即使预测出了目标,可能也不能完美匹配目标位置,有一种比较火的方法用来得到更精确地bbox,他就是yolo(you only look once)算法。
引入grid cell,用来分割整幅图,以下图grid cell为3x3时为例进行说明,每个cell对应输出的形式为y=[px, bx, by, bh, bw, c1, c2, c3],px代表目标框的置信度,有目标为1,无目标(背景)是为0;接下来4位是边界框的位置,最后三位c1代表行人,c2代表汽车,c3代表摩托车,那么最终模型预测出的绿色框和黄色框的结果应如图中用相应颜色写出的向量所示。

4.交并比IOU
训练时如何确定损失,推理时如何判断预测的bbox的准确性?
假设算法推理的结果时紫色框,Ground Truth是红色框,那么IOU就等于他们的交集/并集合,这种最基本的IOU效果不好,训练稳定性差,比如若BBox在GT内部,则该值无法刻画中心点距离,长宽比等情况,后来又有改进版的GIOU,DIOU,CIOU。最后一种完美的从重叠度、中心点距离、长宽比的维度评判出计算的BBox和GT的匹配度,因而yolov5训练时采用CIOU,但defer时由于没有GT,故只能采用DIOU。在计算机检测任务中一般IOU>0.5就算预测正确,当然你也可以指定其他值。


5.非极大值抑制NMS
如下图所示,实际运行目标检测算法时,模型计算的结果可能是1、2、3都预测出了图中的同一辆车,4、5、6同时预测出另一辆车,我们显然不希望得出这样的计算结果,为此yolo的最后加入了NMS模块。

NMS的的工作流程是什么呢?以19x19 grid cell的原始图为例,最后得到19x19x8的预测结果,最终有361个结果,假设对于右边的车有相邻编号4、5、6的格子都举手说我预测出了一辆车,中心就在我的格子里,但事实是该区域只有一辆车。NMS首先选出px最大的框,把他作为真实框(在这之前其实是先discard掉px <=0.6的预测结果),同时把其他和其预测为同一目标的框干掉,最后只剩下图中高亮的框对于目标置信度0.9,另外的0.6和0.7的被干掉。

然后循环进行下一次操作,再从剩下结构中选出最大的,比如0.8,对应左边的车,对和其预测结果一致的y计算IOU并将IOU>0.5的discard。这里注意实际情况是可能出现两辆车中心重合,且其GT框的IOU是很高的情况,但我们更愿意相信是预测错误,因而NMS大多数情况下的discard并非误杀。

6.Anchor Box
目前为止一个grid cell只能检测一个目标,对于下图中两种对象重点重合于一个cell的无能为力。Anchor Boxe的引入可以解决检测多目标的难题,以2个Anchor为例,把原先单目标检测的扩充为y=[, , , ℎ, , 1, 2, 3, , , , ℎ, , 1, 2, 3]。对于不同特征的目标,实现设置好Anchor box的大小和尺寸,我们把Anchor1设置成用来预测人,Anchor2预测车子,然后进行训练,训练时把和GT的IOU大的作为计算的结果,通过不停的迭代修正Anchor box, 从而得到各个实际目标对应的BBox。
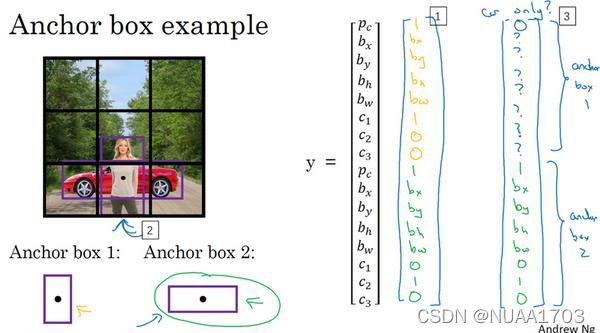
两个Anchor对于一个cell中有三个对象的情况无能为力,为了提高预测的准确性,可以增加grid cell,cell越小越不容易在同一个cell中存在多于2个的object。如果我们就是要在一个cell中可以预测多个object,就必须增加Anchor数。对于yolov5,有三种尺寸的特征图,每个Feature Map有三种尺寸规格的Anchor。另外当需要预测两个形状和尺寸相近的objec,以上所提算法难以应对。
对于两个Anchor(只能预测两类object)时,我们需要分别对每一个类别(Anchor)单独做NMS。

二、yolov5总结
主要参考知乎江大白的文章,yolo模型人为可分为输入端、Backbone、Neck和Prediction。yolov3,yolov4,和yolov5结构示意图分别如下:
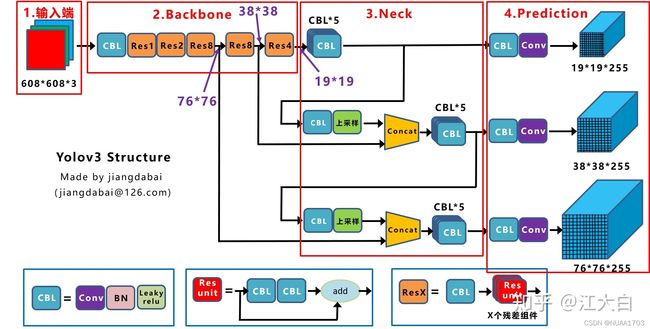
yolov5和yolov4结构很相近,主要包含:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
下图只将yolov5划分为BackBone和Head:

1.输入端
后期补充;
2.BackBone
1) Focus
就是把长宽方向的尺度转换到深度方向,最后便于计算?

yolov5s中Focus中的用的卷积核是32个,对应的tensor尺寸为 32x12x3x3
2) CSP1_x、CSP2_x
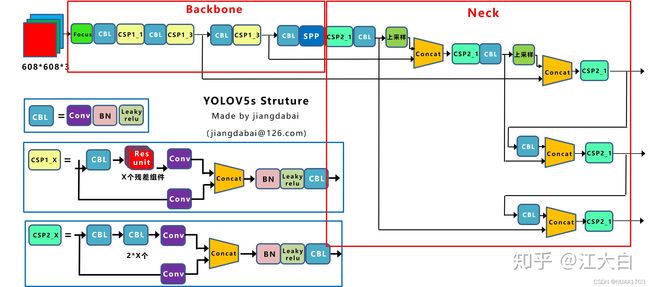
3) SPP
SPP池化是有padding的,所以不改变尺寸。
3.Neck
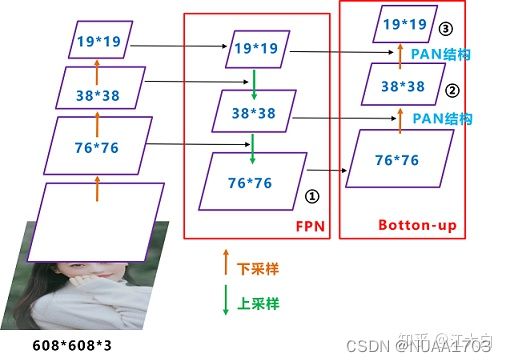
1) FPN+PAN
采用FPN+PAN(上采样+下采样)的结构,将模型图中部分画成立体就成了下图
其实BackBone里是进行了五次下采样(stride为2的卷积,608-304-152-76-38-19),只看最后三次,然后到了Neck进行了三次上采样,将19x19转换为76x76
4.输出端
1) Bounding box损失函数+NMS非极大值抑制
参考第一部分的内容。
正文完。
附录:
以下两张图引用自CSDN:\lambda
YOLOv5s网络结构详解

正文的部分参考:
- 吴恩达深度学习课程及黄海广博士的笔记;
- https://zhuanlan.zhihu.com/p/172121380;