Long tailed 长尾分布论文汇总
什么是长尾分布?
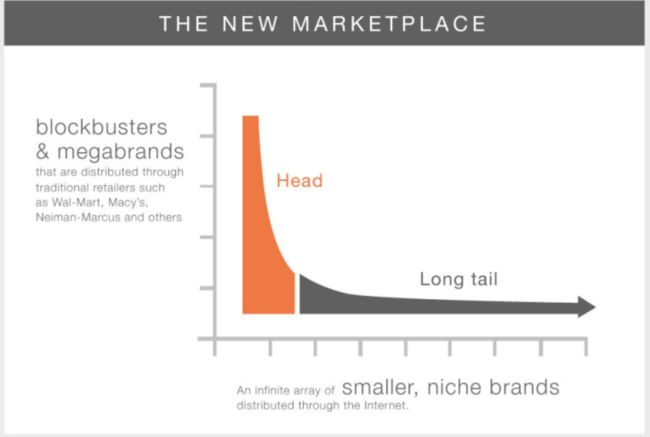
长期以来研究人员做图像、文本分类时使用的大多是均衡数据集:MNIST, CIFAR 10, CIFAR 100等,但是现实生活中的数据分布是非常不均衡的。有的类会占绝大多数,有的类别却很少出现。如果对这种分布不加以考虑,会导致尾部类别(tail)的预测结果受到很大影响,会严重的偏向头部类(head),如图所示:
目前对于长尾分布已经有很多工作去优化、考虑,在这里对最近自己看的论文进行总结。
计算机视觉
Class-Balanced Loss Based on Effective Number of Samples cvpr 2019
论文地址这篇文章从有效数字的角度出发,考虑到每一个类别中数目的不一样,在损失函数中显式地去加入类别>相关的参数,使得分类结果得到提高。并且对CIFAR 10和CIFAR 100进行处理,手动地让它成为长尾数据集
Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective CVPR 2020
论文地址
该文章认为由于训练集当中数据不多,无法让模型学习到很好的表征,所以从域适应的角度来考虑,对于目标域t (测试集)以及源域s (训练集) 对于尾类y 的 P t ( x ∣ y ) / P s ( x ∣ y ) P_t(x|y)/P_s(x|y) Pt(x∣y)/Ps(x∣y)并不相等,然而这个条件分布并没有办法直接估计,所以在论文中去学习这个参数,使得结果相比于上一篇有了进一步提升。
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition CVPR 2020
论文地址
该篇文章提出了一种两分支模型,分别利用uniform sampler 和 reverse sampler进行数据采样之后,利用共享的特征提取器提取特征,最后用累积学习的方法学习分类器,最后得到loss。
Equalization Loss for Long-Tailed Object Recognition CVPR 2020
论文地址
一个类别的每个正样本可以被视为其他类别的负样本,使尾部类别接收更多负的梯度。基于在,该文章提出了均衡损失,通过简单地忽略稀有类别的梯度来解决长尾稀有类别的问题。均衡损失保护在网络中处于不利地位的类别参数更新。
Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection CVPR 2021
论文地址
Equalization loss的改良版
Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax CVPR 2020
论文地址
还没看
Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification ECCV 2020
论文地址
DECOUPLING REPRESENTATION AND CLASSIFIER FOR LONG-TAILED RECOGNITION ICLR 2020
论文地址
这篇文章提出了在长尾分布数据集下进行训练的时候,表征学习是正常的(采用正常采样方法,而不是基于类别进行采样),不正常的是分类器(classifier)。所以这篇文章提出了两阶段学习,第一阶段正常训练,但是二阶段只保留backbone,利用多种方法对分类器进行重构:重新训练分类器,分类器正则,最近邻等,最后达到了最佳性能。
Identifying and Compensating for Feature Deviation Imbalanced Deep Learning Nips2020
论文地址
该文章提出了CDT loss,假设原始分类器某一类权重为 z i z_i zi,那么这个loss就是对其做如下处理: z i α \frac{z_i}{\alpha} αzi,其中 α = N m a x / N i \alpha=N_{max}/N_i α=Nmax/Ni, N m a x N_{max} Nmax代表类别数最多的类包含的训练集数量, N i N_i Ni代表第i类所有的训练集数量
Balanced Meta-Softmax for Long-Tailed Visual Recognition Nips2020
论文地址
该文章提出了BSCEloss,假设原始分类器某一类权重为 z i z_i zi,那么这个loss就是对其做如下处理: z i ^ = z i + l o g ( N i ) \hat{z_i}=z_i+log(N_i) zi^=zi+log(Ni), N i N_i Ni代表第i类所有的训练集数量。BSCE和CDT虽然非常简单,但是效果出奇的好
Long-Tailed Classification by Keeping the Good and Removing the Bad Momentum Causal Effect NIPS 2020
论文地址
这篇文章从上一篇文章进行讨论,端到端学习一直是深度学习的目标,但是上一篇论文采用两阶段训练的效果反而更好,这是让人费解的。他们在研究过程中发现SGD的动量momentum是引入数据分布的原因,但是单纯地去掉动量效果会极大的变差。于是他们考虑保留动量好的部分,去掉动量坏的部分,最终达到了更好的结果。
这篇文章涉及非常多的理论知识,很难懂,推荐去作者的知乎去学习:链接
Improving Calibration for Long-Tailed Recognition CVPR 2021
论文地址
这篇文章讨论了深度学习模型的校准错误(Expected Calibration Error)ECE,发现当引入了长尾之后模型的ECE急剧升高,但是现有的方法并没有改善。于是使用了mixup策略,label aware smoothing和BN层的shift learning来提高性能。
Contrastive Learning based Hybrid Networks for Long-Tailed Image Classification CVPR 2021
论文地址
采用了对比学习和课程学习的方法,在一阶段过程中训练backbone和分类器,并得到了最优的结果。
Distribution Alignment: A Unified Framework for Long-tail Visual Recognition CVPR 2021
论文地址
这篇文章指出了两阶段框架下对classifier的不同调整方式,假设原始分类器某一类的权重为 z i z_i zi,对它进行变换之后的结果为 z i ^ = α z i + β \hat{z_i } = \alpha z_i+\beta zi^=αzi+β,在这里 α \alpha α被称为magnitude, β \beta β被称为margin。以前的工作有调整magnitude的,也有调整margin的,但是这个工作把两者都考虑进来并且一起训练,取得了最好的效果
PML: Progressive Margin Loss for Long-tailed Age Classification CVPR 2021
论文地址
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition CVPR 2021
论文地址
该文章利用了一种Nips2020里的一种隐式数据增强的手法,并且用元学习来训练这种数据增强方法所需的协方差,最后达到了很好的性能(CIFAR100-100的数据集中能有48%的acc)
Bag of Tricks for Long-Tailed Visual Recognition with Deep Convolutional Neural
Networks AAAI 2021
论文地址
对现有的long tail的方法进行总结,并且集合各种trick来验证哪些trick可以同时使用,哪些trick是冲突的,给出了trick的最优组合。
LONG-TAILED RECOGNITION BY ROUTING DIVERSE DISTRIBUTION-AWARE EXPERTS ICLR 2021
论文地址
提出了Routing Diverse Experts 来同时减少长尾分类的分类器的bias 和 variance。主要分成三个idea:1. 多个分类器共享结构。 2. 分布感知的 diversity loss 3. 专家(expert)(classifier)路由模块
截止笔者目前看到的SOTA
Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision ICCV 2021
论文地址
Parametric Contrastive Learning ICCV 2021
论文地址
改进对比学习学习类别的表征(和improving Calibration … 是同一团队)
ACE: Ally Complementary Experts for Solving Long-Tailed Recognition in One-Shot ICCV 2021 Oral
论文地址
Breadcrumbs: Adversarial Class-Balanced Sampling for Long-tailed Recognition
论文地址
GistNet: a Geometric Structure Transfer Network for Long-Tailed Recognition ICCV 2021
论文地址
短文
Class-Balanced Distillation for Long-Tailed Visual Recognition ICCV 2021
论文地址
蒸馏这么有用吗.jpg
Adaptive Logit Adjustment Loss for Long-Tailed Visual Recognition AAAI 2022
论文地址
多Experts 还是管用.jpg
Memory-based jitter: Improving visual recognition on long-tailed data with diversity in memory AAAI 2022
论文地址
也是配合多experts的
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification AAAI 2022
论文地址
隐式数据增强类文章,但是实验对比是不公平的
文本分类
在文本分类当中long tail的现象也有,但是文本的label大多是multi label,和图像的单label不一样。所以处理的方式也有所差别
Deep Learning for Extreme Multi-label Text Classification SIGIR 2017
论文地址
开山之作,没什么好说的,idea在现在看来也比较简单
SGM: Sequence Generation Model for Multi-Label Classification COLING 2018
论文地址
采用seq2seq的方法来预测label
AttentionXML: Label Tree-based Attention-Aware Deep Model for High-Performance Extreme Multi-Label Text Classification NIPS 2019
论文地址
构造label tree,然后分层构造模型来进行预测。
Taming Pretrained Transformers for Extreme Multi-label Text Classification SIGKDD 2020
论文地址
首先利用二叉树将label进行聚类,然后模型先预测label在哪个簇里,簇内利用ranking model进行预测。