Linux(二)
Linux day01
-
- 7.9 磁盘分区类
-
- 7.9.1 df 查看磁盘空间使用情况
- 7.9.2 fdisk 查看分区
- 7.9.3 mount/umount 挂载/卸载
- 7.10 进程线程类
-
- 7.10.1 ps 查看当前系统进程状态
- 7.10.2 kill 终止进程
- 7.10.3 pstree 查看进程树
- 7.10.4 top 查看系统健康状态
- 7.10.5 netstat 显示网络统计信息
- 7.11 crond 系统定时任务
-
- 7.11.1 crond 服务管理
- 7.11.2 crontab 定时任务设置
- 第八章 软件包管理
-
- 8.1 RPM
-
- 8.1.1 RPM概述
- 8.1.2 RPM查询命令(rpm -qa)
- 8.1.3 RPM卸载命令(rpm -e)
- 8.1.4 RPM安装命令(rpm -ivh)
- 8.2 YUM仓库配置
-
- 8.2.1 YUM概述
- 8.2.2 YUM的常用命令
- 8.2.3 修改网络YUM源
- 第九章 Shell编程
-
- 9.1 概述
- 9.2 Shell脚本的执行方式
- 9.3 Shell中的变量
-
- 9.3.1 定义变量
- 9.3.2 将命令的返回值赋给变量
- 9.3.3 设置环境变量
- 9.3.4 位置参数变量
- 9.3.5 预定义变量
- 9.4 运算符
- 9.5 条件判断
-
- 9.5.1 判断语句
- 9.5.2 常用判断条件
- 9.6 流程控制
-
- 9.6.1 if 判断
- 9.6.2 case 语句
- 9.6.3 for 循环
- 9.6.4 while 循环
- 9.7 read读取控制台输入
- 9.8 函数
-
- 9.8.1 系统函数
- 9.8.2 自定义函数
- 第十章 常见错误及解决方案
7.9 磁盘分区类
7.9.1 df 查看磁盘空间使用情况
df: disk free 空余硬盘
1)基本语法:
df 选项 (功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况)
2)选项说明

3)案例实操
(1)查看磁盘使用情况
[root@hadoop101 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 15G 3.5G 11G 26% /
tmpfs 939M 224K 939M 1% /dev/shm
/dev/sda1 190M 39M 142M 22% /boot
7.9.2 fdisk 查看分区
1)基本语法:
fdisk -l (功能描述:查看磁盘分区详情)
2)选项说明

3)经验技巧:
该命令必须在root用户下才能使用
4)功能说明:
(1)Linux分区
Device:分区序列
Boot:引导
Start:从X磁柱开始
End:到Y磁柱结束
Blocks:容量
Id:分区类型ID
System:分区类型
(2)Win7分区

5)案例实操
(1)查看系统分区情况
[root@hadoop101 /]# fdisk -l
Disk /dev/sda: 21.5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x0005e654
Device Boot Start End Blocks Id System
/dev/sda1 * 1 26 204800 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 26 1332 10485760 83 Linux
/dev/sda3 1332 1593 2097152 82 Linux swap / Solaris
7.9.3 mount/umount 挂载/卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中包含了一整套的文件和目录,并将一个分区和一个目录联系起来,要载入的那个分区将使它的存储空间在这个目录下获得。
0)挂载前准备(必须要有光盘或者已经连接镜像文件)

1)基本语法:
mount [-t vfstype] [-o options] device dir (功能描述:挂载设备)
umount 设备文件名或挂载点 (功能描述:卸载设备)
2)参数说明

2)案例实操
(1)挂载光盘镜像文件
[root@hadoop101 ~]# mkdir /mnt/cdrom/ 建立挂载点
[root@hadoop101 ~]# mount -t iso9660 /dev/cdrom /mnt/cdrom/ 设备/dev/cdrom挂载到 挂载点 : /mnt/cdrom中
[root@hadoop101 ~]# ll /mnt/cdrom/
(2)卸载光盘镜像文件
[root@hadoop101 ~]# umount /mnt/cdrom
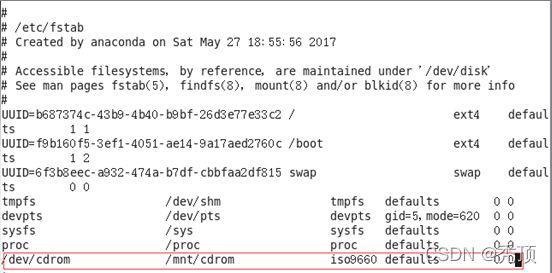
3)设置开机自动挂载:
[root@hadoop101 ~]# vi /etc/fstab
添加红框中内容,保存退出。
7.10 进程线程类
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系统资源。
7.10.1 ps 查看当前系统进程状态
ps:process status 进程状态
1)基本语法:
ps aux | grep xxx (功能描述:查看系统中所有进程)
ps -ef | grep xxx (功能描述:可以查看子父进程之间的关系)
2)选项说明

3)功能说明
(1)ps aux显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的ID号
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty1-tty7代表本地控制台终端,tty1-tty6是本地的字符界面终端,tty7是图形终端。pts/0-255代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台
START:该进程的启动时间
TIME:该进程占用CPU的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
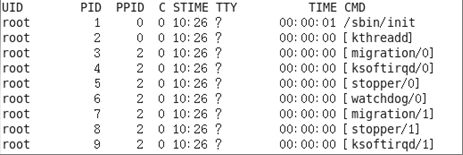
(2)ps -ef显示信息说明
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
4)经验技巧:
如果想查看进程的CPU占用率和内存占用率,可以使用aux;
如果想查看进程的父进程ID可以使用ef;
5)案例实操
[root@hadoop101 datas]# ps aux

7.10.2 kill 终止进程
1)基本语法:
kill [选项] 进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
2)选项说明

3)案例实操:
(1)杀死浏览器进程
[root@hadoop101 桌面]# kill -9 5102
(2)通过进程名称杀死进程
[root@hadoop101 桌面]# killall firefox
7.10.3 pstree 查看进程树
1)基本语法:
pstree [选项]
2)选项说明

3)案例实操:
(1)显示进程pid
[root@hadoop101 datas]# pstree -p
(2)显示进程所属用户
[root@hadoop101 datas]# pstree -u
7.10.4 top 查看系统健康状态
1)基本命令
top [选项]
2)选项说明

3)操作说明:

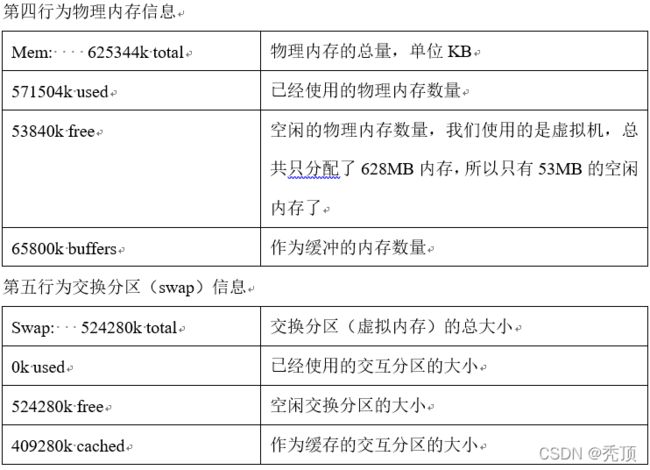
4)查询结果字段解释
第一行信息为任务队列信息
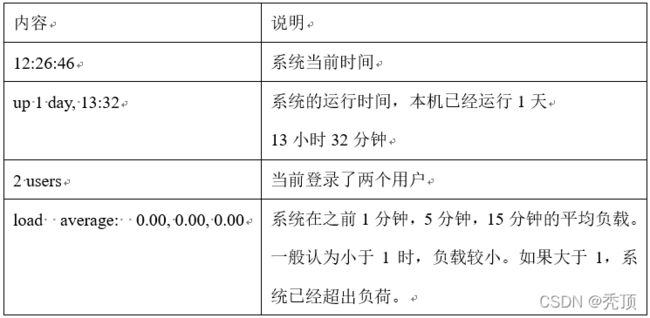
第二行为进程信息

5)案例实操
[root@hadoop101 atguigu]# top -d 1
[root@hadoop101 atguigu]# top -i
[root@hadoop101 atguigu]# top -p 2575
执行上述命令后,可以按P、M、N对查询出的进程结果进行排序。
7.10.5 netstat 显示网络统计信息
1)基本语法:
netstat -anp (功能描述:此命令用来显示整个系统目前的网络情况。例如目前的连接、数据包传递数据、或是路由表内容)
2)选项说明

3)案例实操
(1)通过进程号查看该进程的网络信息
[root@hadoop101 hadoop-2.7.2]# netstat -anp | grep 火狐浏览器进程号
udp 0 0 192.168.1.101:33893 192.168.1.2:53 ESTABLISHED 4043/firefox
udp 0 0 192.168.1.101:47416 192.168.1.2:53 ESTABLISHED 4043/firefox
unix 2 [ ACC ] STREAM LISTENING 28916 4043/firefox /tmp/orbit-atguigu/linc-fcb-0-382f8b667a38a
unix 3 [ ] STREAM CONNECTED 28919 4043/firefox /tmp/orbit-atguigu/linc-fcb-0-382f8b667a38a
7.11 crond 系统定时任务
7.11.1 crond 服务管理
1)重新启动crond服务
[root@hadoop101 ~]# service crond restart
7.11.2 crontab 定时任务设置
1)基本语法
crontab [选项]
2)选项说明

3)参数说明
[root@hadoop101 ~]# crontab -e
(1)进入crontab编辑界面。会打开vim编辑你的工作。
-
-
-
-
- 执行的任务
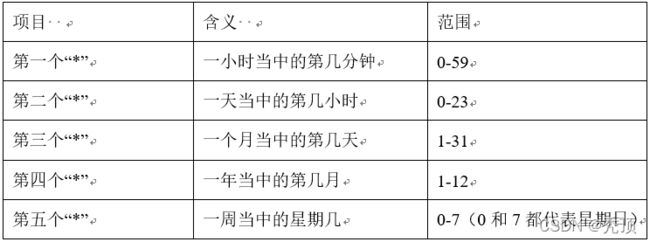
(2)特殊符号

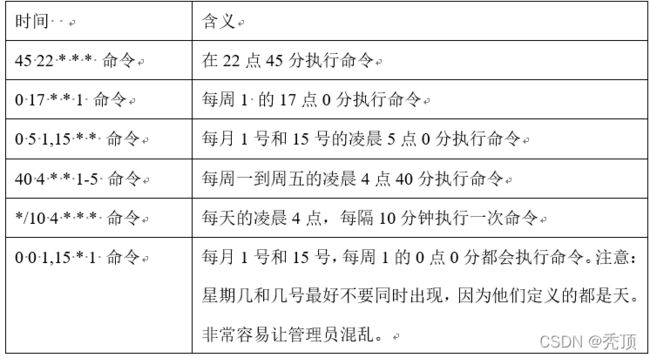
(3)特定时间执行命令
4)案例实操:
(1)每隔1分钟,向/root/bailongma.txt文件中添加一个11的数字
*/1 * * * * /bin/echo ”11” >> /root/bailongma.txt
- 执行的任务
-
-
-
第八章 软件包管理
8.1 RPM
8.1.1 RPM概述
RPM(RedHat Package Manager),Rethat软件包管理工具,类似windows里面的setup.exe是Linux这系列操作系统里面的打包安装工具,它虽然是RedHat的标志,但理念是通用的。
RPM包的名称格式
Apache-1.3.23-11.i386.rpm
- “apache” 软件名称
- “1.3.23-11”软件的版本号,主版本和此版本
- “i386”是软件所运行的硬件平台
- “rpm”文件扩展名,代表RPM包
8.1.2 RPM查询命令(rpm -qa)
1)基本语法:
rpm -qa (功能描述:查询所安装的所有rpm软件包)
2)经验技巧:
由于软件包比较多,一般都会采取过滤。rpm -qa | grep rpm软件包
3)案例实操
(1)查询firefox软件安装情况
[root@hadoop101 Packages]# rpm -qa |grep firefox
firefox-45.0.1-1.el6.centos.x86_64
8.1.3 RPM卸载命令(rpm -e)
1)基本语法:
(1)rpm -e RPM软件包
(2) rpm -e --nodeps 软件包
2)选项说明

3)案例实操
(1)卸载firefox软件
[root@hadoop101 Packages]# rpm -e firefox
8.1.4 RPM安装命令(rpm -ivh)
1)基本语法:
rpm -ivh RPM包全名
2)选项说明

3)案例实操
(1)安装firefox软件
[root@hadoop101 Packages]# pwd
/media/CentOS_6.8_Final/Packages
[root@hadoop101 Packages]# rpm -ivh firefox-45.0.1-1.el6.centos.x86_64.rpm
warning: firefox-45.0.1-1.el6.centos.x86_64.rpm: Header V3 RSA/SHA1 Signature, key ID c105b9de: NOKEY
Preparing... ########################################### [100%]
1:firefox ########################################### [100%]
8.2 YUM仓库配置
8.2.1 YUM概述
YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
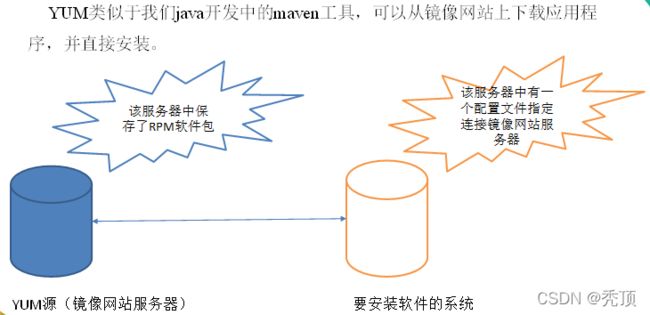
8.2.2 YUM的常用命令
1)基本语法:
yum [选项] [参数]
2)选项说明

3)参数说明

4)案例实操实操
(1)采用yum方式安装tree软件
[root@hadoop101 ~]#yum -y install tree
8.2.3 修改网络YUM源
默认的系统YUM源,需要连接国外apache网站,网速比较慢,可以修改关联的网络YUM源为国内镜像的网站,比如网易163。
1)前期文件准备
(1)前提条件linux系统必须可以联网
(2)在Linux环境中访问该网络地址:http://mirrors.163.com/.help/centos.html,在使用说明中点击CentOS6->再点击保存

(3)查看文件保存的位置
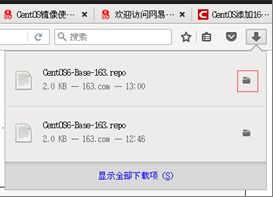
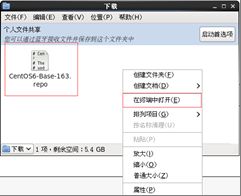
在打开的终端中输入如下命令,就可以找到文件的保存位置。
[atguigu@hadoop101 下载]$ pwd
/home/atguigu/下载
2)替换本地yum文件
(1)把下载的文件移动到/etc/yum.repos.d/目录
[root@hadoop101 下载]# mv CentOS6-Base-163.repo /etc/yum.repos.d/
(2)进入到/etc/yum.repos.d/目录
[root@hadoop101 yum.repos.d]# pwd
/etc/yum.repos.d
(3)用CentOS6-Base-163.repo替换CentOS-Base.rep
[root@hadoop101 yum.repos.d]# mv CentOS6-Base-163.repo CentOS-Base.rep
3)安装命令
(1)[root@hadoop101 yum.repos.d]#yum clean all
(2)[root@hadoop101 yum.repos.d]#yum makecache
(3)[root@hadoop101 yum.repos.d]# yum -y install createrepo
4)测试
[root@hadoop101 yum.repos.d]#yum -y install httpd
第九章 Shell编程
9.1 概述
Shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用Shell来启动、挂起、停止甚至是编写一些程序。
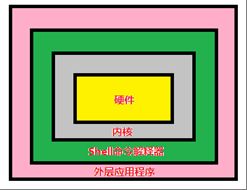
Shell还是一个功能相当强大的编程语言,易编写、易调试、灵活性强。Shell是解释执行的脚本语言,在Shell中可以调用Linux系统命令。
9.2 Shell脚本的执行方式
2)脚本格式
(1)脚本以#!/bin/bash开头
(2)脚本必须有可执行权限
3)第一个Shell脚本
(1)需求:创建一个Shell脚本,输出helloworld
(2)实操:

4)脚本的常用执行方式
第一种:输入脚本的绝对路径或相对路径
(1)首先要赋予helloworld.sh 脚本的+x权限
[atguigu@hadoop101 datas]$ chmod 777 helloworld.sh
(2)执行脚本
/root/helloWorld.sh
./helloWorld.sh
第二种:bash或sh+脚本(不用赋予脚本+x权限)
sh /root/helloWorld.sh
sh helloWorld.sh
9.3 Shell中的变量
1)Linux Shell中的变量分为,系统变量和用户自定义变量。
2)系统变量: H O M E 、 HOME、 HOME、PWD、 S H E L L 、 SHELL、 SHELL、USER等等
3)显示当前shell中所有变量:set
9.3.1 定义变量
1)基本语法:
(1)定义变量:变量=值
(2)撤销变量:unset 变量
(3)声明静态变量:readonly变量,注意:不能unset
2)变量定义规则0
(1)变量名称可以由字母、数字和下划线组成,但是不能以数字开头。
(2)等号两侧不能有空格
(3)变量名称一般习惯为大写
3)案例实操
(1)定义变量A
A=8
(2)撤销变量A
unset A
(3)声明静态的变量B=2,不能unset
readonly B=2
(4)可把变量提升为全局环境变量,可供其他shell程序使用
export 变量名
9.3.2 将命令的返回值赋给变量
1)A=ls -la 反引号,运行里面的命令,并把结果返回给变量A
2)A=$(ls -la) 等价于反引号
9.3.3 设置环境变量
1)基本语法:
(1)export 变量名=变量值 (功能描述:将shell变量输出为环境变量)
(2)source 配置文件 (功能描述:让修改后的配置信息立即生效)
(3)echo $变量名 (功能描述:查询环境变量的值)
2)案例实操:
(1)在/etc/profile文件中定义JAVA_HOME环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(2)查看环境变量JAVA_HOME的值
[atguigu@hadoop101 datas]$ echo $JAVA_HOME
/opt/module/jdk1.8.0_144
9.3.4 位置参数变量
1)基本语法
$n (功能描述:n为数字,$0代表命令本身,$1- 9 代 表 第 一 到 第 九 个 参 数 , 十 以 上 的 参 数 , 十 以 上 的 参 数 需 要 用 大 括 号 包 含 , 如 9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如 9代表第一到第九个参数,十以上的参数,十以上的参数需要用大括号包含,如{10})
∗ ( 功 能 描 述 : 这 个 变 量 代 表 命 令 行 中 所 有 的 参 数 , * (功能描述:这个变量代表命令行中所有的参数, ∗(功能描述:这个变量代表命令行中所有的参数,*把所有的参数看成一个整体)
@ ( 功 能 描 述 : 这 个 变 量 也 代 表 命 令 行 中 所 有 的 参 数 , 不 过 @ (功能描述:这个变量也代表命令行中所有的参数,不过 @(功能描述:这个变量也代表命令行中所有的参数,不过@把每个参数区分对待)
$# (功能描述:这个变量代表命令行中所有参数的个数)
2)案例实操
(1)输出输入的的参数1,参数2,所有参数,参数个数

(3) ∗ 与 *与 ∗与@的区别

a) ∗ 和 *和 ∗和@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 2 … 2 … 2…n的形式输出所有参数
b)当它们被双引号“”包含时,“$*”会将所有的参数作为一个整体,以“$1 2 … 2 … 2…n”的形式输出所有参数;“$@”会将各个参数分开,以“$1” “ 2 ” … ” 2”…” 2”…”n”的形式输出所有参数
9.3.5 预定义变量
1)基本语法:
$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行不正确了。)
$$ (功能描述:当前进程的进程号(PID))
$! (功能描述:后台运行的最后一个进程的进程号(PID))
2)案例实操

9.4 运算符
1)基本语法:
(1)“ ( ( 运 算 式 ) ) ” 或 “ ((运算式))”或“ ((运算式))”或“[运算式]”
(2)expr m + n
注意expr运算符间要有空格
(3)expr m - n
(4)expr *, /, % 乘,除,取余
2)案例实操:计算(2+3)X4的值
(1)采用$[运算式]方式
[root@hadoop101 datas]# S=$[(2+3)*4]
[root@hadoop101 datas]# echo $S
(2)expr分布计算
S=`expr 2 + 3`
expr $S \* 4
(3)expr一步完成计算
expr `expr 2 + 3` \* 4
9.5 条件判断
9.5.1 判断语句
1)基本语法:
[ condition ](注意condition前后要有空格)
#非空返回true,可使用$?验证(0为true,>1为false)
2)案例实操:
[atguigu] 返回true
[] 返回false
[condition] && echo OK || echo notok 条件满足,执行后面的语句
9.5.2 常用判断条件
1)两个整数之间比较
= 字符串比较
-lt 小于
-le 小于等于
-eq 等于
-gt 大于
-ge 大于等于
-ne 不等于
2)按照文件权限进行判断
-r 有读的权限
-w 有写的权限
-x 有执行的权限
3)按照文件类型进行判断
-f 文件存在并且是一个常规的文件
-e 文件存在
-d 文件存在并是一个目录
4)案例实操
(1)23是否大于等于22
[ 23 -ge 22 ]
(2)student.txt是否具有写权限
[ -w student.txt ]
(3)/root/install.log目录中的文件是否存在
[ -e /root/install.log ]
9.6 流程控制
9.6.1 if 判断
1)基本语法:
if [ 条件判断式 ];then
程序
fi
或者
if [ 条件判断式 ]
then
程序
fi
注意事项:(1)[ 条件判断式 ],中括号和条件判断式之间必须有空格
2)案例实操

9.6.2 case 语句
1)基本语法:
case $变量名 in
“值1”)
如果变量的值等于值1,则执行程序1
;;
“值2”)
如果变量的值等于值2,则执行程序2
;;
…省略其他分支…
*)
如果变量的值都不是以上的值,则执行此程序
;;
esac
2)案例实操

9.6.3 for 循环
1)基本语法1:
for 变量 in 值1 值2 值3…
do
程序
done
2)案例实操:
(1)打印输入参数

3)基本语法2:
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
4)案例实操
(1)从1加到100

9.6.4 while 循环
1)基本语法:
while [ 条件判断式 ]
do
程序
done
2)案例实操
(1)从1加到100

9.7 read读取控制台输入
1)基本语法:
read(选项)(参数)
选项:
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)。
参数
变量:指定读取值的变量名
2)案例实操
读取控制台输入的名称

9.8 函数
9.8.1 系统函数
1)basename基本语法
basename [pathname] [suffix]
basename [string] [suffix] (功能描述:basename命令会删掉所有的前缀包括最后一个(‘/’)字符,然后将字符串显示出来。
选项:
suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
2)案例实操
[atguigu@hadoop101 opt]$ basename /opt/test.txt
test.txt
[atguigu@hadoop101 opt]$ basename /opt/test.txt .txt
test
3)dirname基本语法
dirname 文件绝对路径 (功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分))
4)案例实操
[atguigu@hadoop101 opt]$ dirname /opt/test.txt
/opt
9.8.2 自定义函数
1)基本语法:

2)经验技巧:
(1)必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先编译。
(2)函数返回值,只能通过$?系统变量获得,可以显示加:return返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
3)案例实操
(1)计算输入参数的和

第十章 常见错误及解决方案
1)虚拟化支持异常情况如下几种情况

![]()


问题原因:宿主机BIOS设置中的硬件虚拟化被禁用了
解决办法:需要打开笔记本BIOS中的IVT对虚拟化的支持
