Flink 多种时间概念、Watermark、allowedLateness、SideOutput概念及应用
背景
- Window窗口函数,flink怎么知道哪个是字段是对应的时间呢?
- 由于网络问题,数据先产生,但是乱序延迟了,那属于哪个时间窗呢?
- Flink里面定义窗口,可以引用不同的时间概念
Flink里面时间分类
事件时间EventTime
- 事件发生的时间
- 是每个单独事件在其产生进程上发生的时间,这个时间通常在记录进入 Flink 之前记录在对象中
- 在事件时间中,时间值取决于数据产生记录的时间
进入时间 IngestionTime
- 事件到进入Flink
处理时间ProcessingTime
- 事件被flink处理的时间
- 正在执行相应操作的机器的系统时间
- 是最简单的时间概念,不需要流和机器之间的协调,它提供最佳性能和最低延迟
- 但是在分布式和异步环境中,处理时间有不确定性,存在延迟或乱序问题
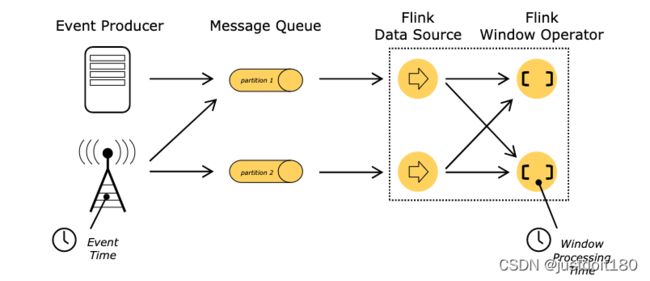
各种时间引发的思考
- 事件时间已经能够解决所有的问题了,那为何还要用处理时间呢?
- 处理时间由于不用考虑事件的延迟与乱序,所以处理数据的速度高效
- 如果一些应用比较重视处理速度而非准确性,那么就可以使用处理时间,但结果具有不确定性
- 事件时间有延迟,但是能够保证处理的结果具有准确性,并且可以处理延迟甚至无序的数据
举个例子
一个电商平台,要统计双十一每分钟内成交额,你认为是哪个时间比较好?
(EventTime) 下单支付时间是2021-11-11 00:00:10
(IngestionTime ) 进入Flink时间2021-11-11 00:01:15(网络拥堵、延迟)
(ProcessingTime)进入窗口时间2021-11-11 00:04:30(网络拥堵、延迟)
时间概念总结:
一般我们都是用EventTime事件时间进行处理统计数据,但数据由于网络问题延迟、乱序到达会导致窗口计算数据不准确。
需求:
比如时间窗是 [12:01:01,12:01:10 ) ,但是有数据延迟到达当 12:01:10 秒数据到达的时候,不立刻触发窗口计算而是等一定的时间,等迟到的数据来后再关闭窗口进行计算。
Watermark 水位线
- 由flink的某个operator操作生成后,就在整个程序中随event数据流转
- With Periodic Watermarks(周期生成,可以定义一个最大允许乱序的时间,用的很多)
- With Punctuated Watermarks(标点水位线,根据数据流中某些特殊标记事件来生成,相对少)
- 衡量数据是否乱序的时间,什么时候不用等早之前的数据
- 是一个全局时间戳,不是某一个key下的值
- 是一个特殊字段,单调递增的方式,主要是和数据本身的时间戳做比较
- 用来确定什么时候不再等待更早的数据了,可以触发窗口进行计算,忍耐是有限度的,给迟到的数据一些机会
注意
Watermark 设置太小会影响数据准确性,设置太大会影响数据的实时性,更加会加重Flink作业的负担
需要经过测试,和业务相关联,得出一个较合适的值即可
公式:
Watermaker = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
窗口触发计算的时机
watermark之前是按照窗口的关闭时间点计算的 [12:01:01,12:01:10 )
watermark之后,触发计算的时机
- 窗口内有数据
- Watermaker >= Window EndTime窗口结束时间
触发计算后,其他窗口内数据再到达也被丢弃
数据流中的事件是有序

数据流中的事件是无序
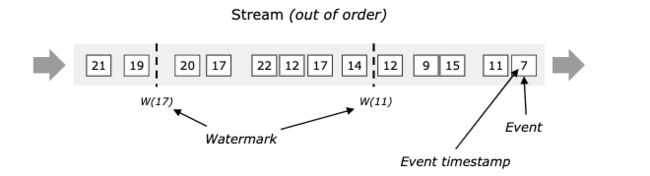
案例剖析:
window大小为10s,窗口是W1 [23:12:00~23:12:10) 、 W2[23:12:10~23:12:20)
下面是数据的event time
数据A 23:12:07
数据B 23:12:11
数据C 23:12:08
数据D 23:12:17
数据E 23:12:09
没加入watermark,由上到下进入flink
数据B到了之后,W1就进行了窗口计算,数据只有A
数据C 迟到了3秒,到了之后,由于W1已经计算了,所以就丢失了数据C
加入watermark, 允许5秒延迟乱序,由上到下进入flink
数据A到达
watermark = 12:07 - 5 = 12:02 < 12:10 ,所以不触发W1计算, A属于W1
数据B到达
watermark = max{ 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, B属于W2
数据C到达
watermark = max{12:08, 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, C属于W1
数据D到达
watermark = max{12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 触发W1计算, D属于W2
数据E到达
watermark = max{12:09, 12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 之前已触发W1计算, 所以丢失了E数据
Watermaker 计算 = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
什么时候触发W1窗口计算
Watermaker >= Window EndTime窗口结束时间
当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
示例
需求:
- 分组统计不同鞋子的成交总价
- 数据有乱序延迟,允许3秒的时间
时间工具类
/**
* date 转 字符串
*
* @param time
* @return
*/
public static String format(long timestamp) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
ZoneId zoneId = ZoneId.systemDefault();
String timeStr = formatter.format(new Date(timestamp).toInstant().atZone(zoneId));
return timeStr;
}
/**
* 字符串 转 date
*
* @param time
* @return
*/
public static Date strToDate(String time) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime localDateTime = LocalDateTime.parse(time, formatter);
return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());
}
watermark代码示例:
构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<String> ds = env.socketTextStream("127.0.0.1",8888);
DataStream<Tuple3<String, String,Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple3<String, String,Integer>> out) throws Exception {
String[] arr = value.split(",");
out.collect(Tuple3.of(arr[0], arr[1],Integer.parseInt(arr[2])));
}
});
SingleOutputStreamOperator<Tuple3<String, String,Integer>> watermakerDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy
//指定最大允许的延迟/乱序 时间
.<Tuple3<String, String,Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(
(event, timestamp) -> {
//指定POJO的事件时间列
return TimeUtil.strToDate(event.f1).getTime();
}
));
SingleOutputStreamOperator<String> sumDS = watermakerDS.keyBy(new KeySelector<Tuple3<String, String,Integer>, String>() {
@Override
public String getKey(Tuple3<String, String,Integer> value) throws Exception {
return value.f0;
}
}).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new WindowFunction<Tuple3<String, String,Integer>, String, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<Tuple3<String, String,Integer>> input, Collector<String> out) throws Exception {
//存放窗口的数据的事件时间
List<String> eventTimeList = new ArrayList<>();
int total = 0;
for (Tuple3<String, String,Integer> order : input) {
eventTimeList.add(order.f1);
total = total+order.f2;
}
String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key,total, TimeUtil.format(window.getStart()),TimeUtil.format(window.getEnd()), eventTimeList);
out.collect(outStr);
}
});
sumDS.print();
env.execute("watermark job");
测试数据:
窗口 [00:00:00 ~ 00:00:10) | [00:00:10 ~ 00:00:20)
窗口时间:10s
并行度调整为1
触发窗口计算条件
- 窗口内有数据
- watermark >= 窗口endtime
- 即 当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
lining,2021-11-11 00:00:07,200
lining,2021-11-11 00:00:11,200
lining,2021-11-11 00:00:08,200
nike,2021-11-11 00:00:13,200
lining,2021-11-11 00:00:13,200
lining,2021-11-11 00:00:17,200
lining,2021-11-11 00:00:09,200
lining,2021-11-11 00:00:20,200
lining,2021-11-11 00:00:22,200
lining,2021-11-11 00:00:23,200
Flink 二次兜底延迟数据处理–>allowedLateness
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
示例:
//分组 开窗
SingleOutputStreamOperator<String> sumDS = watermarkDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {
@Override
public String getKey(Tuple3<String, String, Integer> value) throws Exception {
return value.f0;
}
})
//开窗
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
//允许 1分钟
.allowedLateness(Time.minutes(1))
//聚合, 方便调试拿到窗口全部数据,全窗口函数
.apply();
sumDS.print();
Flink 最后的兜底延迟数据处理-> 测输出流
超过了watermark的等待后,还有延迟数据到达怎么办?
watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
数据超过了allowedLateness 后,就丢失了吗?用侧输出流 SideOutput
示例
OutputTag<Tuple3<String, String,Integer>> lateData = new OutputTag<Tuple3<String, String,Integer>>("lateData"){};
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
//允许 1分钟
.allowedLateness(Time.minutes(1))
//最后的兜底容忍
.sideOutputLateData(lateData)
//不会更新之前的窗口数据,需要代码单独写逻辑处理更新之前的数据,也可以积累后批处理
sumDS.getSideOutput(lateData).print("late data");
思考:
数据有乱序延迟,如何保证在需要的窗口内获得指定的数据?
- flink采用watermark 、allowedLateness() 、sideOutputLateData()三个机制来保证获取数据
- watermark的作用是防止数据出现延迟乱序,允许等待一会再触发窗口计算,提前输出
- allowLateness,是将窗口关闭时间再延迟一段时间.设置后就像window变大了
- sideOutPut是最后兜底操作,超过allowLateness后,窗口已经彻底关闭了,就会把数据放到侧输出流
- 测输出流 OutputTag tag = new OutputTag(){}, 由于泛型查除问题,需要重写方法,加花括号
那么为什么不直接把window设置大一点呢?或者把watermark加大点? 而使用allowedLateness
- watermark先输出数据,allowLateness会局部修复数据并主动更新窗口的数据输出
- 这期间的迟到数据不会被丢弃,而是会触发窗口重新计算
应用场景?
- 实时监控平台
- 可以用watermark及时输出数据
- allowLateness 做短期的更新迟到数据
- sideOutPut做兜底更新保证数据准确性
总结
- 第一层 窗口window 的作用是从DataStream数据流里指定范围获取数据。
- 第二层 watermark的作用是防止数据出现乱序延迟,允许窗口等待延迟数据达到,再触发计算
- 第三层 allowLateness 会让窗口关闭时间再延迟一段时间, 如果还有数据达到,会局部修复数据并主动更新窗口的数据输出
- 第四层
sideOutPut侧输出流是最后兜底操作,在窗口已经彻底关闭后,所有过期延迟数据放到侧输出流,可以单独获取,存储到某个地方再批量更新之前的聚合的数据
注意
Flink 默认的处理方式直接丢弃迟到的数据
sideOutPut还可以进行分流功能
DataStream没有getSideOutput方法,SingleOutputStreamOperator才有
Watermark新接口-->WatermarkStrategy,TimestampAssigner 和 WatermarkGenerator 因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式
新接口之前是用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks ,现在可以弃用了