【翻译】YOLOX: Exceeding YOLO Series in 2021
Title: YOLOX: Exceeding YOLO Series in 2021
题目:YOLOX:2021年超越YOLO系列
作者:Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun
如有侵权,请联系删除。
论文:YOLOX: Exceeding YOLO Series in 2021
项目:https://github.com/Megvii-BaseDetection/YOLOX
文章目录
- Abstract(摘要)
- 1. Introduction(介绍)
- 2. YOLOX
-
- 2.1. YOLOX-DarkNet53
- 2.2. Other Backbones(其他骨干网络)
- 3. Comparison with the SOTA(与主流模型的对比)
- 4. 1st Place on Streaming Perception Challenge (WAD at CVPR 2021)
- 5. Conclusion(结论)
Abstract(摘要)
In this report, we present some experienced improvements to YOLO series, forming a new high-performance detector — YOLOX. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLONano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model. We hope this report can provide useful experience for developers and researchers in practical scenes, and we also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported. Source code is at https://github.com/Megvii-BaseDetection/YOLOX.
在这份报告中,我们对YOLO系列进行了一些有经验的改进,形成了一个新的高性能检测器–YOLOX。我们将YOLO检测器转换为无锚方式,并进行其他先进的检测技术,即解耦头和领先的标签分配策略SimOTA,在大规模的模型范围内获得最先进的结果。对于只有0.91M参数和1.08G FLOPs的YOLONano,我们在COCO上得到25.3%的AP,超过NanoDet 1.8%的AP;对于YOLOv3,工业界最广泛使用的检测器之一,我们在COCO上将其AP提升到47.3%,比目前的最佳实践高出3.0% AP;对于YOLOX-L,其参数数量与YOLOv4-CSP、YOLOv5-L大致相同,我们在Tesla V100上以68.9 FPS的速度在COCO上实现了50.0%的AP,比YOLOv5-L超出1.8%的AP。此外,我们使用单个YOLOX-L模型赢得了流感知挑战赛(CVPR 2021的自动驾驶研讨会)的第一名。我们希望这份报告能够为实际场景中的开发者和研究者提供有用的经验,我们还提供了支持ONNX、TensorRT、NCNN和Openvino的部署版本。源代码在https://github.com/Megvii-BaseDetection/YOLOX。
1. Introduction(介绍)
With the development of object detection, YOLO series [23, 24, 25, 1, 7] always pursuit the optimal speed and accuracy trade-off for real-time applications. They extract the most advanced detection technologies available at the time (e.g., anchors [26] for YOLOv2 [24], Residual Net [9] for YOLOv3 [25]) and optimize the implementation for best practice. Currently, YOLOv5 [7] holds the best trade-off performance with 48.2% AP on COCO at 13.7 ms.(we choose the YOLOv5-L model at 640 × 640 resolution and test the model with FP16-precision and batch=1 on a V100 to align the settings of YOLOv4 [1] and YOLOv4-CSP [30] for a fair comparison)
随着目标检测的发展,YOLO系列[23, 24, 25, 1, 7]始终追求实时应用的最佳速度和精度权衡。他们提取了当时最先进的检测技术(例如,YOLOv2[24]的锚点[26],YOLOv3[25]的剩余网[9]),并优化了最佳实践的实现。目前,YOLOv5[7]拥有最佳的权衡性能,在COCO上以13.7毫秒的速度拥有48.2%的AP。(我们选择640×640分辨率的YOLOv5-L模型,并在V100上用FP16-精度和batch=1测试该模型,使YOLOv4[1]和YOLOv4-CSP[30]的设置一致,以便进行公平比较)
Nevertheless, over the past two years, the major advances in object detection academia have focused on anchor-free detectors [29, 40, 14], advanced label assignment strategies [37, 36, 12, 41, 22, 4], and end-to-end (NMS-free) detectors [2, 32, 39]. These have not been integrated into YOLO families yet, as YOLOv4 and YOLOv5 are still anchor-based detectors with hand-crafted assigning rules for training.
尽管如此,在过去两年中,目标检测学术界的主要进展集中在无锚检测器[29, 40, 14]、高级标签分配策略[37, 36, 12, 41, 22, 4]和端到端(无NMS)检测器[2, 32, 39]。这些还没有被整合到YOLO系列中,因为YOLOv4和YOLOv5仍然是基于锚的检测器,使用手工制作的分配规则进行训练。
That’s what brings us here, delivering those recent advancements to YOLO series with experienced optimization. Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3). Indeed, YOLOv3 is still one of the most widely used detectors in the industry due to the limited computation resources and the insufficient software support in various practical applications.
这就是我们在这里的原因,通过经验丰富的优化为YOLO系列提供这些最新的进展。考虑到YOLOv4和YOLOv5对于基于锚的管道可能有点过度优化,我们选择YOLOv3[25]作为我们的起点(我们将YOLOv3-SPP设置为默认的YOLOv3)。事实上,由于在各种实际应用中计算资源有限,软件支持不足,YOLOv3仍然是业界使用最广泛的检测器之一。
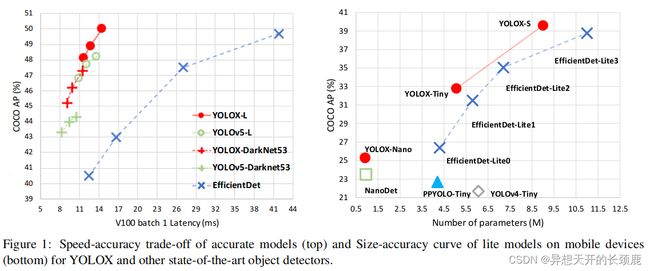
As shown in Fig. 1, with the experienced updates of the above techniques, we boost the YOLOv3 to 47.3% AP (YOLOX-DarkNet53) on COCO with 640 × 640 resolution, surpassing the current best practice of YOLOv3 (44.3% AP, ultralytics version(https://github.com/ultralytics/yolov3)) by a large margin. Moreover, when switching to the advanced YOLOv5 architecture that adopts an advanced CSPNet [31] backbone and an additional PAN [19] head, YOLOX-L achieves 50.0% AP on COCO with 640 × 640 resolution, outperforming the counterpart YOLOv5-L by 1.8% AP. We also test our design strategies on models of small size. YOLOX-Tiny and YOLOX-Nano (only 0.91M Parameters and 1.08G FLOPs) outperform the corresponding counterparts YOLOv4-Tiny and NanoDet(https://github.com/RangiLyu/nanodet) by 10% AP and 1.8% AP, respectively.
如图1所示,通过上述技术的经验更新,我们将YOLOv3在640×640分辨率的COCO上的AP提升到47.3%(YOLOX-DarkNet53),大大超过了YOLOv3目前的最佳实践(44.3%的AP,ultralytics版本(https://github.com/ultralytics/yolov3))。此外,当切换到采用先进的CSPNet[31]骨干网络和额外的PAN[19]头的先进YOLOv5架构时,YOLOX-L在640×640分辨率的COCO上实现了50.0%的AP,比对应的YOLOv5-L超出了1.8%的AP。我们还在小尺寸的模型上测试了我们的设计策略。YOLOX-Tiny和YOLOX-Nano(只有0.91M的参数和1.08G的FLOPs)分别比对应的YOLOv4-Tiny和NanoDet(https://github.com/RangiLyu/nanodet)高出10%AP和1.8%AP。
We have released our code at https://github.com/Megvii-BaseDetection/YOLOX, with ONNX, TensorRT, NCNN and Openvino supported. One more thing worth mentioning, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
我们已经在https://github.com/Megvii-BaseDetection/YOLOX发布了我们的代码,并支持ONNX、TensorRT、NCNN和Openvino。还有一件事值得一提,我们用一个YOLOX-L模型赢得了流感知挑战赛(CVPR 2021的自动驾驶研讨会)的第一名。
2. YOLOX
2.1. YOLOX-DarkNet53
We choose YOLOv3 [25] with Darknet53 as our baseline. In the following part, we will walk through the whole system designs in YOLOX step by step.
我们选择YOLOv3[25]与Darknet53作为我们的基线。在下面的部分,我们将一步一步地走过YOLOX的整个系统设计。
Implementation details. Our training settings are mostly consistent from the baseline to our final model. We train the models for a total of 300 epochs with 5 epochs warmup on COCO train2017 [17]. We use stochastic gradient descent (SGD) for training. We use a learning rate of lr×BatchSize/64 (linear scaling [8]), with a initial lr = 0.01 and the cosine lr schedule. The weight decay is 0.0005 and the SGD momentum is 0.9. The batch size is 128 by default to typical 8-GPU devices. Other batch sizes include single GPU training also work well. The input size is evenly drawn from 448 to 832 with 32 strides. FPS and latency in this report are all measured with FP16-precision and batch=1 on a single Tesla V100.
实施的细节。从基线到最终模型,我们的训练设置基本一致。我们在COCO train2017[17]上总共训练了300个epochs,并进行了5个epochs的预热。我们使用随机梯度下降法(SGD)进行训练。我们使用lr×BatchSize/64的学习率(线性缩放[8]),初始lr=0.01,余弦lr计划。权重衰减为0.0005,SGD动量为0.9。批量大小为128,默认为典型的8-GPU设备。其他批次大小包括单GPU训练也很好。输入大小从448到832均匀地抽取,有32个步长。本报告中的FPS和延迟都是在单个Tesla V100上用FP16精度和batch=1测量的。
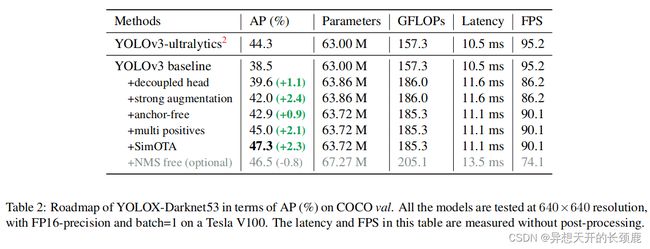
YOLOv3 baseline. Our baseline adopts the architecture of DarkNet53 backbone and an SPP layer, referred to YOLOv3-SPP in some papers [1, 7]. We slightly change some training strategies compared to the original implementation [25], adding EMA weights updating, cosine lr schedule, IoU loss and IoU-aware branch. We use BCE Loss for training cls and obj branch, and IoU Loss for training reg branch. These general training tricks are orthogonal to the key improvement of YOLOX, we thus put them on the baseline. Moreover, we only conduct RandomHorizontalFlip, ColorJitter and multi-scale for data augmentation and discard the RandomResizedCrop strategy, because we found the RandomResizedCrop is kind of overlapped with the planned mosaic augmentation. With those enhancements, our baseline achieves 38.5% AP on COCO val, as shown in Tab. 2.
YOLOv3基线。我们的基线采用了DarkNet53骨干网络和SPP层的结构,在一些论文中被称为YOLOv3-SPP[1, 7]。与原始实现[25]相比,我们稍微改变了一些训练策略,增加了EMA权重更新、余弦lr计划、IoU损失和IoU-aware分支。我们使用BCE损失来训练cls和obj分支,使用IoU损失来训练reg分支。这些一般的训练技巧与YOLOX的关键改进是正交的,因此我们把它们放在基线上。此外,我们只进行了RandomHorizontalFlip、ColorJitter和multi-scale的数据增强,而放弃了RandomResizedCrop策略,因为我们发现RandomResizedCrop与计划中的马赛克增强有一定的重叠性。通过这些改进,我们的基线在COCO值上取得了38.5%的AP,如表2所示。
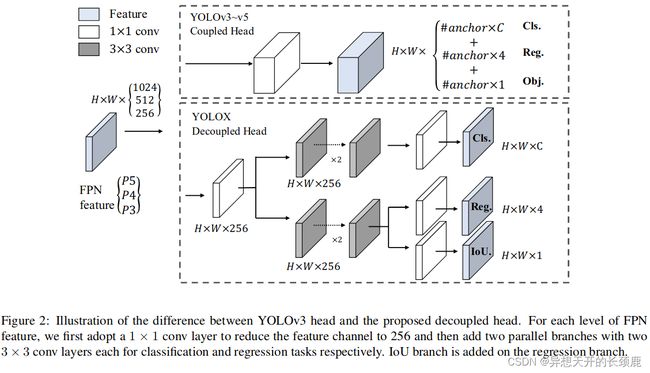
Decoupled head. In object detection, the conflict between classification and regression tasks is a well-known problem [27, 34]. Thus the decoupled head for classification and localization is widely used in the most of one-stage and two-stage detectors [16, 29, 35, 34]. However, as YOLO series’ backbones and feature pyramids ( e.g., FPN [13], PAN [20].) continuously evolving, their detection heads remain coupled as shown in Fig. 2.
解耦头。在目标检测中,分类和回归任务之间的冲突是一个著名的问题[27, 34]。因此,用于分类和定位的解耦头被广泛用于大多数单阶段和二阶段检测器中[16, 29, 35, 34]。然而,由于YOLO系列的主干和特征金字塔(如FPN[13],PAN[20])不断发展,它们的检测头仍然是耦合的,如图2所示。

Our two analytical experiments indicate that the coupled detection head may harm the performance. 1). Replacing YOLO’s head with a decoupled one greatly improves the converging speed as shown in Fig. 3. 2). The decoupled head is essential to the end-to-end version of YOLO (will be described next). One can tell from Tab. 1, the end-toend property decreases by 4.2% AP with the coupled head, while the decreasing reduces to 0.8% AP for a decoupled head. We thus replace the YOLO detect head with a lite decoupled head as in Fig. 2. Concretely, it contains a 1 × 1 conv layer to reduce the channel dimension, followed by two parallel branches with two 3 × 3 conv layers respectively. We report the inference time with batch=1 on V100 in Tab. 2 and the lite decoupled head brings additional 1.1 ms (11.6 ms v.s. 10.5 ms).
我们的两个分析实验表明,耦合的检测头可能会损害性能。1). 如图3所示,将YOLO的检测头替换为去耦合的检测头,大大改善了收敛速度。2). 解耦头对YOLO的端到端版本至关重要(接下来将介绍)。从表1可以看出,端到端属性在耦合头的情况下会减少4.2%的AP,而在解耦头的情况下,减少的AP会减少到0.8%。因此,我们用图2中的轻度解耦头取代YOLO检测头。具体来说,它包含一个1×1的卷积层以减少通道尺寸,然后是两个平行的分支,分别有两个3×3的卷积层。我们在表2中报告了在V100上使用batch=1的推理时间,轻型解耦头带来了额外的1.1毫秒(11.6毫秒对10.5毫秒)。
Strong data augmentation. We add Mosaic and MixUp into our augmentation strategies to boost YOLOX’s performance. Mosaic is an efficient augmentation strategy proposed by ultralytics-YOLOv3. It is then widely used in YOLOv4 [1], YOLOv5 [7] and other detectors [3]. MixUp [10] is originally designed for image classification task but then modified in BoF [38] for object detection training. We adopt the MixUp and Mosaic implementation in our model and close it for the last 15 epochs, achieving 42.0% AP in Tab. 2. After using strong data augmentation, we found ImageNet pre-training is no more beneficial, we thus train all the following models from scratch.
强大的数据扩增。我们将Mosaic和MixUp加入我们的增强策略中,以提高YOLOX的性能。Mosaic是由ultralytics-YOLOv3提出的一种高效的增强策略。它随后被广泛用于YOLOv4[1]、YOLOv5[7]和其他检测器[3]中。MixUp[10]最初是为图像分类任务设计的,但后来在BoF[38]中被修改为目标检测训练。我们在模型中采用MixUp和Mosaic的实现,并在最后15个epochs中关闭它,在表2中实现了42.0%的AP。在使用强大的数据增强后,我们发现ImageNet的预训练没有更多好处,因此我们从头开始训练以下所有模型。
Anchor-free. Both YOLOv4 [1] and YOLOv5 [7] follow the original anchor-based pipeline of YOLOv3 [25]. However, the anchor mechanism has many known problems. First, to achieve optimal detection performance, one needs to conduct clustering analysis to determine a set of optimal anchors before training. Those clustered anchors are domain-specific and less generalized. Second, anchor mechanism increases the complexity of detection heads, as well as the number of predictions for each image. On some edge AI systems, moving such large amount of predictions between devices (e.g., from NPU to CPU) may become a potential bottleneck in terms of the overall latency.
无锚框。YOLOv4[1]和YOLOv5[7]都遵循YOLOv3[25]的原始基于锚的管道。然而,锚框机制有许多已知的问题。首先,为了达到最佳的检测性能,需要在训练前进行聚类分析,以确定一组最佳锚点。那些聚类的锚是特定领域的,通用性较差。其次,锚点机制增加了检测头的复杂性,以及每张图像的预测数量。在一些边缘人工智能系统中,在设备之间移动如此大量的预测(例如,从NPU到CPU)可能成为整体延迟的潜在瓶颈。
Anchor-free detectors [29, 40, 14] have developed rapidly in the past two year. These works have shown that the performance of anchor-free detectors can be on par with anchor-based detectors. Anchor-free mechanism significantly reduces the number of design parameters which need heuristic tuning and many tricks involved (e.g., Anchor Clustering [24], Grid Sensitive [11].) for good performance, making the detector, especially its training and decoding phase, considerably simpler [29].
无锚检测器[29, 40, 14]在过去两年中发展迅速。这些工作表明,无锚检测器的性能可以与基于锚的检测器相媲美。无锚机制大大减少了需要启发式调整的设计参数的数量和涉及的许多技巧(例如,锚聚类[24],网格敏感[11]。)以获得良好的性能,使检测器,特别是其训练和解码阶段,大大简化[29]。
Switching YOLO to an anchor-free manner is quite simple. We reduce the predictions for each location from 3 to 1 and make them directly predict four values, i.e., two offsets in terms of the left-top corner of the grid, and the height and width of the predicted box. We assign the center location of each object as the positive sample and pre-define a scale range, as done in [29], to designate the FPN level for each object. Such modification reduces the parameters and GFLOPs of the detector and makes it faster, but obtains better performance – 42.9% AP as shown in Tab. 2.
将YOLO切换到无锚的方式是非常简单的。我们将每个位置的预测值从3减少到1,并使其直接预测四个值,即网格左上角的两个偏移量,以及预测的盒子的高度和宽度。我们将每个目标的中心位置指定为正样本,并像[29]中那样预先定义一个比例范围,以指定每个目标的FPN水平。这样的修改减少了检测器的参数和GFLOPs,使其更快,但获得了更好的性能–42.9%的AP,如表2所示。
Multi positives. To be consistent with the assigning rule of YOLOv3, the above anchor-free version selects only ONE positive sample (the center location) for each object meanwhile ignores other high quality predictions. However, optimizing those high quality predictions may also bring beneficial gradients, which may alleviates the extreme imbalance of positive/negative sampling during training. We simply assigns the center 3×3 area as positives, also named “center sampling” in FCOS [29]. The performance of the detector improves to 45.0% AP as in Tab. 2, already surpassing the current best practice of ultralytics-YOLOv3 (44.3% AP).
多正样本。为了与YOLOv3的分配规则保持一致,上述无锚点版本只为每个目标选择一个正样本(中心位置),同时忽略了其他高质量的预测样本。然而,优化这些高质量的预测样本也可能带来有益的梯度,这可能会缓解训练期间正/负采样的极端不平衡。我们简单地将中心的3×3区域指定为正样本区域,在FCOS[29]中也被称为 “中心采样”。如表2所示,检测器的性能提高到45.0%的AP,已经超过了目前超分析的最佳实践-YOLOv3(44.3%的AP)。
SimOTA. Advanced label assignment is another important progress of object detection in recent years. Based on our own study OTA [4], we conclude four key insights for an advanced label assignment: 1). loss/quality aware, 2). center prior, 3). dynamic number of positive anchors(The term “anchor” refers to “anchor point” in the context of anchorfree detectors and “grid” in the context of YOLO.) for each ground-truth (abbreviated as dynamic top-k), 4). global view. OTA meets all four rules above, hence we choose it as a candidate label assigning strategy.
SimOTA。高级标签分配是近年来目标检测的另一个重要进展。基于我们自己的研究OTA[4],我们总结出高级标签分配的四个关键观点。1).损失/质量aware,2).中心先验,3).每个GT的动态正样本锚(术语"锚"在无锚检测器中指 “锚点”,在YOLO中指"网格")(缩写为动态top-k),4).全局视野。OTA符合上述所有四项规则,因此我们选择它作为候选标签分配策略。
Specifically, OTA [4] analyzes the label assignment from a global perspective and formulate the assigning procedure as an Optimal Transport (OT) problem, producing the SOTA performance among the current assigning strategies [12, 41, 36, 22, 37]. However, in practice we found solving OT problem via Sinkhorn-Knopp algorithm brings 25% extra training time, which is quite expensive for training 300 epochs. We thus simplify it to dynamic top-k strategy, named SimOTA, to get an approximate solution.
具体来说,OTA[4]从全局角度分析了标签分配,并将分配程序表述为最优传输(OT)问题,在目前的分配策略中产生了SOTA的性能[12, 41, 36, 22, 37]。然而,在实践中,我们发现通过Sinkhorn-Knopp算法解决OT问题会带来25%的额外训练时间,这对于训练300个epochs来说是相当昂贵的。因此,我们将其简化为动态top-k策略,命名为SimOTA,以获得一个近似的解决方案。
We briefly introduce SimOTA here. SimOTA first calculates pair-wise matching degree, represented by cost [4, 5, 12, 2] or quality [33] for each prediction-gt pair. For example, in SimOTA, the cost between gt g i g_i gi and prediction p j p_j pj is calculated as:
我们在此简单介绍一下SimOTA。SimOTA首先计算配对程度,用成本[4, 5, 12, 2]或质量[33]来表示每个预测-gt对。例如,在SimOTA中,gt g i g_i gi和预测 p j p_j pj之间的成本被计算为。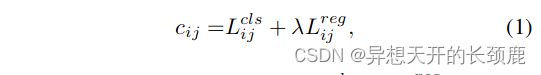
where λ λ λ is a balancing coefficient. L i j c l s L_{ij}^{cls} Lijcls and L i j r e g L_{ij}^{reg} Lijreg are classficiation loss and regression loss between gt g i g_i gi and prediction p j p_j pj. Then, for gt g i g_i gi, we select the top k k k predictions with the least cost within a fixed center region as its positive samples. Finally, the corresponding grids of those positive predictions are assigned as positives, while the rest grids are negatives. Noted that the value k k k varies for different ground-truth. Please refer to Dynamic k k k Estimation strategy in OTA [4] for more details.
其中 λ λ λ为平衡系数。 L i j c l s L_{ij}^{cls} Lijcls和 L i j r e g L_{ij}^{reg} Lijreg是gt g i g_i gi和预测 p j p_j pj之间的分类损失和回归损失。然后,对于gt g i g_i gi,我们选择固定中心区域内成本最小的前 k k k个预测样本作为其正样本。最后,这些正样本预测的相应网格被指定为正样本,而其余网格为负样本。注意到 k k k的值对于不同的GT是不同的。更多细节请参考OTA中的动态 k k k估计策略[4]。
SimOTA not only reduces the training time but also avoids additional solver hyperparameters in SinkhornKnopp algorithm. As shown in Tab. 2, SimOTA raises the detector from 45.0% AP to 47.3% AP, higher than the SOTA ultralytics-YOLOv3 by 3.0% AP, showing the power of the advanced assigning strategy.
SimOTA不仅减少了训练时间,而且还避免了SinkhornKnopp算法中额外的求解器超参数。如表2所示,SimOTA将检测器从45.0%的AP提高到47.3%的AP,比SOTA ultralytics-YOLOv3高3.0%的AP,显示了高级赋值策略的强大。
End-to-end YOLO. We follow [39] to add two additional conv layers, one-to-one label assignment, and stop gradient. These enable the detector to perform an end-to-end manner, but slightly decreasing the performance and the inference speed, as listed in Tab. 2. We thus leave it as an optional module which is not involved in our final models.
端到端YOLO。我们随即[39]增加了两个额外的卷积层,一对一的标签分配和停止梯度。这些使检测器能够以端到端的方式执行,但会略微降低性能和推理速度,如表2中所列。因此,我们把它作为一个可选的模块,不参与我们的最终模型。
2.2. Other Backbones(其他骨干网络)
Besides DarkNet53, we also test YOLOX on other backbones with different sizes, where YOLOX achieves consistent improvements against all the corresponding counterparts.
除了DarkNet53,我们还在其他不同规模的骨干网络上测试了YOLOX,在这些骨干网络上,YOLOX取得了与所有相应的同行一致的改进。
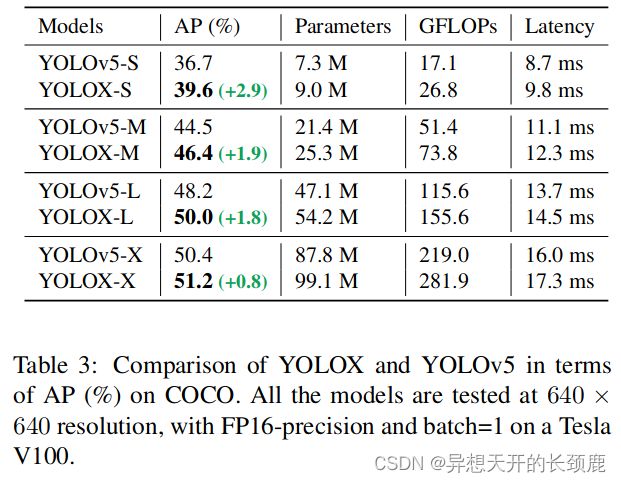
Modified CSPNet in YOLOv5. To give a fair comparison, we adopt the exact YOLOv5’s backbone including modified CSPNet [31], SiLU activation, and the PAN [19] head. We also follow its scaling rule to product YOLOX-S, YOLOX-M, YOLOX-L, and YOLOX-X models. Compared to YOLOv5 in Tab. 3, our models get consistent improvement by ∼3.0% to ∼1.0% AP, with only marginal time increasing (comes from the decoupled head).
YOLOv5中修改的CSPNet。为了进行公平的比较,我们采用了准确的YOLOv5的骨干网络,包括修改的CSPNet[31]、SiLU激活函数和PAN[19]头。我们还遵循它的缩放规则来制作YOLOX-S、YOLOX-M、YOLOX-L和YOLOX-X模型。与表3中的YOLOv5相比,我们的模型得到了一致的改进,从3.0%∼1.0%的AP,只有边际的时间增加(来自解耦头)。
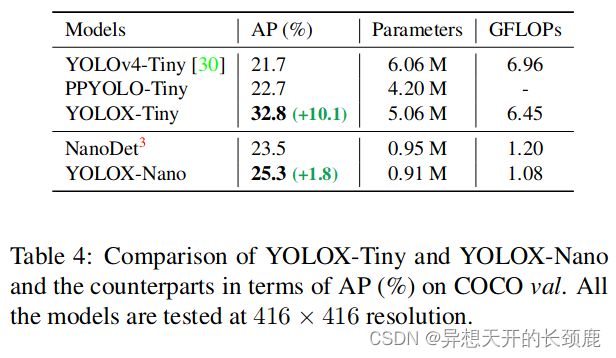
Tiny and Nano detectors. We further shrink our model as YOLOX-Tiny to compare with YOLOv4-Tiny [30]. For mobile devices, we adopt depth wise convolution to construct a YOLOX-Nano model, which has only 0.91M parameters and 1.08G FLOPs. As shown in Tab. 4, YOLOX performs well with even smaller model size than the counterparts.
Tiny和Nano探测器。我们进一步将我们的模型缩小为YOLOX-Tiny,以便与YOLOv4-Tiny[30]进行比较。对于移动设备,我们采用深度卷积来构建YOLOX-Nano模型,它只有0.91M的参数和1.08G的FLOPs。如表4所示,YOLOX在比同行更小的模型尺寸下表现良好。
Model size and data augmentation In our experiments, all the models keep almost the same learning schedule and optimizing parameters as depicted in 2.1. However, we found that the suitable augmentation strategy varies across different size of models. As Tab. 5 shows, while applying MixUp for YOLOX-L can improve AP by 0.9%, it is better to weaken the augmentation for small models like YOLOX-Nano. Specifically, we remove the mix up augmentation and weaken the mosaic (reduce the scale range from [0.1, 2.0] to [0.5, 1.5]) when training small models, i.e., YOLOX-S, YOLOX-Tiny, and YOLOX-Nano. Such a modification improves YOLOX-Nano’s AP from 24.0% to 25.3%.
模型大小和数据增强 在我们的实验中,所有的模型都保持着几乎相同的学习进度和优化参数,如2.1中所描述的。然而,我们发现,合适的增强策略在不同规模的模型中是不同的。如表5所示,虽然对YOLOX-L应用MixUp可以使AP提高0.9%,但对于像YOLOX-Nano这样的小模型来说,削弱增强效果更好。具体来说,在训练小模型,即YOLOX-S、YOLOX-Tiny和YOLOX-Nano时,我们取消了Mix up增强,并削弱了马赛克(将比例范围从[0.1, 2.0]减少到[0.5, 1.5])。这样的修改将YOLOX-Nano的AP从24.0%提高到25.3%。
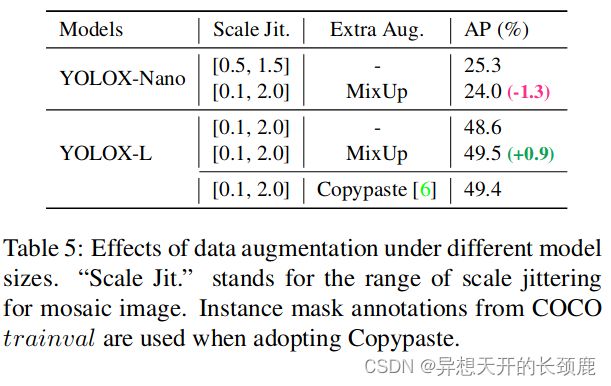
For large models, we also found that stronger augmentation is more helpful. Indeed, our MixUp implementation is part of heavier than the original version in [38]. Inspired by Copypaste [6], we jittered both images by a random sampled scale factor before mixing up them. To understand the power of Mixup with scale jittering, we compare it with Copypaste on YOLOX-L. Noted that Copypaste requires extra instance mask annotations while MixUp does not. But as shown in Tab. 5, these two methods achieve competitive performance, indicating that MixUp with scale jittering is a qualified replacement for Copypaste when no instance mask annotation is available.
对于大型模型,我们还发现,更强的增强功能更有帮助。事实上,我们的MixUp实现比[38]中的原始版本要重一部分。受Copypaste[6]的启发,我们在混合它们之前用一个随机采样的比例因子抖动了两个图像。为了了解Mixup在比例抖动方面的能力,我们在YOLOX-L上将其与Copypaste进行比较。注意到Copypaste需要额外的实例掩码注释,而MixUp不需要。但是,如表5所示,这两种方法取得了有竞争力的性能,表明在没有实例掩码注释的情况下,带规模抖动的MixUp是Copypaste的合格替代品。
3. Comparison with the SOTA(与主流模型的对比)
There is a tradition to show the SOTA comparing table as in Tab. 6. However, keep in mind that the inference speed of the models in this table is often uncontrolled, as speed varies with software and hardware. We thus use the same hardware and code base for all the YOLO series in Fig. 1, plotting the somewhat controlled speed/accuracy curve.
有一个传统是显示SOTA比较表,如表6。然而,请记住,该表中模型的推理速度往往是不可控的,因为速度随软件和硬件而变化。因此,我们在图1中对所有的YOLO系列使用相同的硬件和代码基础,绘制出有所控制的速度/准确度曲线。
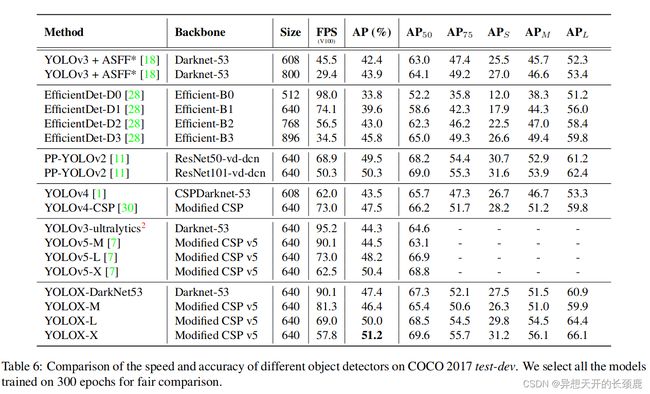
We notice that there are some high performance YOLO series with larger model sizes like Scale-YOLOv4 [30] and YOLOv5-P6 [7]. And the current Transformer based detectors [21] push the accuracy-SOTA to ∼60 AP. Due to the time and resource limitation, we did not explore those important features in this report. However, they are already in our scope.
我们注意到,有一些高性能的YOLO系列具有更大的模型尺寸,如Scale-YOLOv4 [30] 和YOLOv5-P6 [7]。而目前基于Transformer的探测器[21]将精度-SOTA推至∼60AP。由于时间和资源的限制,我们没有在本报告中探讨这些重要的功能。然而,它们已经在我们的范围内了。
4. 1st Place on Streaming Perception Challenge (WAD at CVPR 2021)
Streaming Perception Challenge on WAD 2021 is a joint evaluation of accuracy and latency through a recently proposed metric: streaming accuracy [15]. The key insight behind this metric is to jointly evaluate the output of the entire perception stack at every time instant, forcing the stack to consider the amount of streaming data that should be ignored while computation is occurring [15]. We found that the best trade-off point for the metric on 30 FPS data stream is a powerful model with the inference time ≤ 33ms. So we adopt a YOLOX-L model with TensorRT to product our final model for the challenge to win the 1st place. Please refer to the challenge website(https://eval.ai/web/challenges/challenge-page/ 800/overview) for more details.
WAD 2021上的流式感知挑战赛是通过最近提出的一个指标:流式准确度[15]对准确度和延迟进行联合评估。这个指标背后的关键见解是在每个时间瞬间联合评估整个感知堆栈的输出,迫使堆栈考虑在计算发生时应该忽略的流数据量[15]。我们发现,在30FPS数据流上,该指标的最佳权衡点是推理时间≤33ms的强大模型。因此,我们采用了YOLOX-L模型和TensorRT来制作我们的最终模型,以赢得挑战赛的第一名。更多细节请参考挑战赛网站(https://eval.ai/web/challenges/challenge-page/ 800/overview)。
5. Conclusion(结论)
In this report, we present some experienced updates to YOLO series, which forms a high-performance anchorfree detector called YOLOX. Equipped with some recent advanced detection techniques, i.e., decoupled head, anchor-free, and advanced label assigning strategy, YOLOX achieves a better trade-off between speed and accuracy than other counterparts across all model sizes. It is remarkable that we boost the architecture of YOLOv3, which is still one of the most widely used detectors in industry due to its broad compatibility, to 47.3% AP on COCO, surpassing the current best practice by 3.0% AP. We hope this report can help developers and researchers get better experience in practical scenes.
在这份报告中,我们介绍了YOLO系列的一些有经验的更新,它形成了一个高性能的无锚检测器,称为YOLOX。YOLOX配备了一些最新的先进检测技术,即解耦头、无锚和先进的标签分配策略,在所有模型大小上,YOLOX在速度和准确性之间实现了比其他同行更好的权衡。值得注意的是,我们将YOLOv3的架构提升到了47.3%的AP,超过了目前最佳实践的3.0%AP,而YOLOv3由于其广泛的兼容性,仍然是业界最广泛使用的检测器之一。我们希望这份报告能够帮助开发者和研究人员在实际场景中获得更好的体验。