【数据分析】Pandas入门教程
Pandas 教程

Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 应用
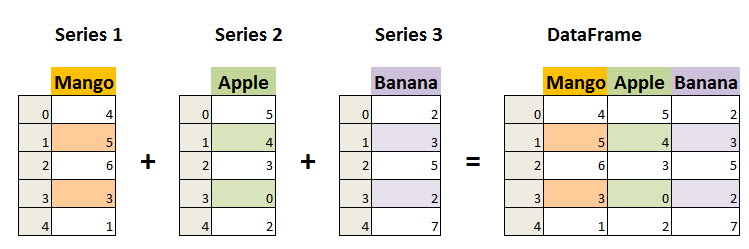
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
数据结构
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
Why Pandas
- 便捷的数据处理能力
- 牛逼的文件读取能力
- 高度封装的Matplotlib,Numpy的画图和计算
一、Series 【一维索引数组】
Pandas Series类似于表格中的一个列(colume)类似于一维数组,可以保存任何数据类型。
pd.Series(data,index,dtype,name,copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
栗子
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)

然后,我们就能通过索引值访问元素啦!
print(myvar["y"])
# Runoob
除却通过数据列表和索引列表外,我们也可以通过字典传入数据。
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
而当我们只需要字典中的一部分时,可以选择性地传入索引
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites,index=[i for i in sites.keys() if i&1])
甚至是为Series设置名称参数
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)
二、DataFrame 【二维索引矩阵(表)】
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。

pandas.DataFrame( data, index, columns, dtype, copy
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
DF的属性
- shape
- index
- columns
- values
- 返回一个
ndarray对象
- 返回一个
- T
- 转置
- head()
- tail()
索引修改
1️⃣ 增加行索引值
stock_code = ["股票_" + str(i) for i in range(stock_day_rise.shape[0])] # 必须整体全部修改 data.index = stock_code
# 注意必须全体修改!!!
2️⃣ 增加列索引值
pd.date_range(start=None,end=None, periods=None, freq='B')
# 生成时间序列
'''
start:开始时间
end:结束时间
periods:时间天数
freq:递进单位,默认1天
'B'默认略过周末
'''
# ⽣成⼀个时间的序列,略过周末⾮交易⽇
date = pd.date_range('2017-01-01', periods=stock_day_rise.shape[1], freq='B')
3️⃣ 重设索引
data.reset_index() # drop=False 不会删除原先的索引
data.reset_index(drop=True) # 删除原先的索引
4️⃣ 设置新索引
set_index(keys,drop=True)
'''
keys : 列索引名成或者列索引名称的列表
drop : boolean, default True.当做新的索引,删除原来的列
'''
Case
1️⃣create
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
'''
month year sale
0 1 2012 55
1 4 2014 40
2 7 2013 84
3 10 2014 31
'''
2️⃣ set
df.set_index('month')
# or
# 设置多索引
df.set_index(['year','month'])
创建DF
1️⃣ 通过列表
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],index=["F","S","T"],dtype=float)
print(df)
'''
Site Age
F Google 10.0
S Runoob 12.0
T Wiki 13.0
'''
2️⃣ 通过ndarray
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
'''
Site Age
0 Google 10
1 Runoob 12
2 Wiki 13
'''
3️⃣ 通过dict
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
'''
a b c
0 1 2 NaN
1 5 10 20.0
'''
如果有数据缺失,那么将返回NaN
数据访问
可以通过loc返回指定行的数据!如果没有设置索引,那么默认的索引是[0,1,…,n]
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
'''
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64
'''
指定索引后:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc[["day2","day1"]])
'''
calories duration
day2 380 40
day1 420 50
'''
而iloc属性,则是返回相对位置。
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.iloc[0,1])
'''
50
'''
# 指定索引
print(df.iloc[[0,2,1],[1,0]])
'''
duration calories
day1 50 420
day3 45 390
day2 40 380
'''
当然,还有ix组合索引。
排序
df.sort_values(by=,ascending=)
按照指定列的值进行排序。ascending=True升序
同样,也可以对给定索引重新排序
data.sort_index(ascending)
- ps. Series也可以用同样的API
运算
1️⃣ 算术运算
四则运算
eg.
data['open'].add(1) # 加
# 减
close=data['close']
open=data['open']
dat['m_price_change']=close.sub(open) # 添加一列的话,直接加就是了
# 乘
close.multiply(open)
# 除
close.div(open)
2️⃣ 逻辑运算
# > < | &
# eg.
# data[() & ()] # 逻辑与
# data[() | ()] # 逻辑或
data[(data['close']>2) & (data['open']<5)]
# query(exper)
# eg.
data.query("close > 2 & open < 5")
# isin(val)
# eg.
data[data['turnover'].isin([4.19,2.39])]
3️⃣ 统计运算
大哥describe()
| count | Number of non-NA observations |
|---|---|
| sum | 求和 |
| mean | 平均 |
| median | 中位数 |
| mode | 众数 |
| min | 最小值 |
| max | 最大值 |
| abs | 绝对值 |
| prod | 累乘 |
| std | 标准差 |
| var | 无偏方差 |
| idxmax | 最大索引 |
| idxmin | 最小索引 |
注意,坐标值默认为columns,如果想对行进行,需要指定axis=1
5️⃣ 累计统计函数
| 函数 | 作⽤ |
|---|---|
| cumsum | 计算前1/2/3/…/n个数的和 |
| cummax | 计算前1/2/3/…/n个数的最⼤值 |
| cummin | 计算前1/2/3/…/n个数的最⼩值 |
| cumprod | 计算前1/2/3/…/n个数的积 |
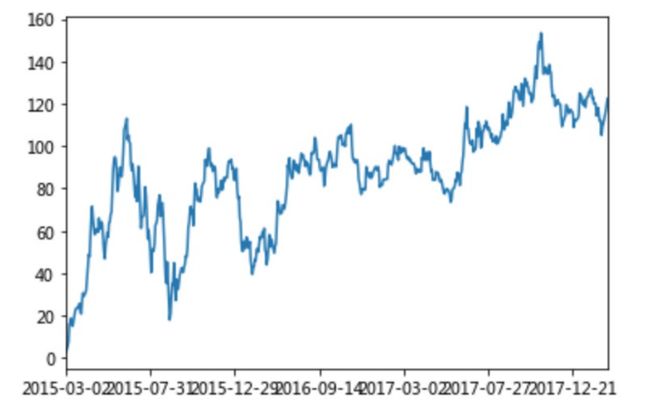
栗子 累计求和
# 对时间序列进行累计求和
data=data.sort_index()
stock_rise=data['p_change']
stock_rise.cumsum().plot()
plt.show()
6️⃣ 自定义运算
apply(func,axis=0)
栗子 求最大值-最小值
data[["open","close"]].apply(lambda x:x.max()-x.min(),axis=0)
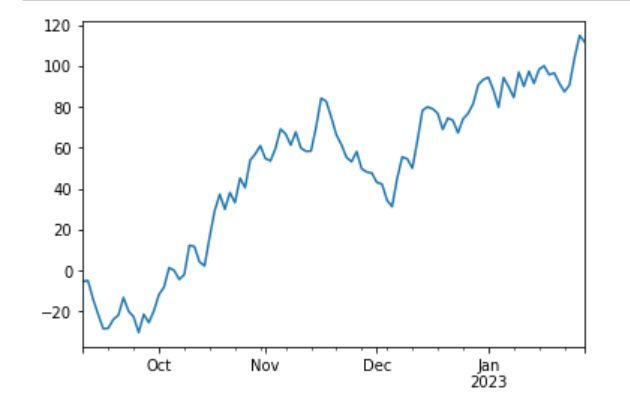
实例
import numpy as np
import pandas as pd
stock=np.random.uniform(-9.0,15.0,(100,8))
data=pd.DataFrame(stock,index=pd.date_range("20220912",periods=100,freq="B"),columns=["num_"+str(i) for i in range(1,9)])
data

import matplotlib.pyplot as plt
data=data.sort_index()
val=data['num_1']
stock=val.cumsum().plot()
plt.show()
数据离散化
Why Discretization
简化数据结构,减少连续的属性值个数。
Eg. 人类的身高本身应该是一个连续的区间,但我们可以将其分为高、中、矮几个阶段。
pd.qcut(data,q)
# 按照q的个数自动进行分组
pd.cut(data,bins)
# 指定区间分组
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
p_counts = pd.cut(p_change, bins)
# ⾃⾏分组
qcut = pd.qcut(p_change, 10)
# 计算分到每个组数据个数
qcut.value_counts()
One hot 编码
pd.get_dummies(data,prefix=None)
# prefix是分组名字
合并
Why concat
方便查询(存储时离散更优),方便关联规则挖掘与数据探查
1️⃣ pd.concat
pd.concat([data1,data2],axis=1)
# axis=0 列索引
# axis=1 航索引
2️⃣ pd.merge
merge这个API 提供了更多更复杂的方法,偏向于数据库的合并了
但是一般就是左右两个表,多表合并还是concat吧
pd.merge(left,right,how="inner",on=None,left_on=None,right_on=None)
# on 合并的列名
# left_on,right_on 列名在左右两表中的称呼
# how 合并方式 | inner 内连接 | outer 外连接 也就是left+right | left 左连接 以左表为基准,对于左表有的而右表缺失,会填充NaN | right 右连接
交叉表与透视表
Why Cross and Pivot?
探究不同数据可能存在的关系
pd.crosstab(val1,val2)
简单来说,这个API就是将val1的数据作为源,将val2的数据作为规则进行分组,从而探究其中的关系。
栗子 探究星期数据和涨幅数据之间的关系
# 寻找星期⼏跟股票张得的关系
# 1、先把对应的⽇期找到星期⼏
date = pd.to_datetime(data.index).weekday
data['week'] = date
# 2、假如把p_change按照⼤⼩去分个类0为界限
data['posi_neg'] = np.where(data['p_change'] > 0, 1, 0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(data['week'], data['posi_neg'])
# 3. 探究之间的比例关系
sum = count.sum(axis=1).astype(np.float32)
# 进⾏相除操作,得出⽐例
pro = count.div(sum, axis=0)
# 绘图
pro.plot(kind='bar', stacked=True) plt.show()
# 而透视表,可以让上面的过程更加简单
data.pivot_table(['posi_neg'], index='week')
分组和聚合
⛵️ Why Grouping and Merge
在不同的组间,数据往往会表现出差异性,这就是我们想看到的。
1️⃣ The API of Grouping
pd.groupby(key,as_index=False)
# key是分组的列数组,可以多个
2️⃣ The API of Merge
前面说的统计函数就是哦!
栗子 不同颜色不同类型的笔的价格数据
Data
import pandas as pd
col =pd.DataFrame({'color': ['white','red','green','red','green'], \
'object': ['pen','pencil','pencil','ashtray', 'pen'],\
'price1':[5.56,4.20,1.30,0.56,2.75],\
'price2':[4.75,4.12,1.60,0.75,3.15]})
print(col)
'''
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
'''
Process
对颜色分组,然后对价格求平均
col.groupby(['color'])['price1'].mean()
col['price1'].groupby(col['color']).mean()
'''
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
'''
保证索引位置不变
col.groupby(['color'], as_index=False)['price1'].mean()
'''
color price1
0 green 2.025
1 red 2.380
2 white 5.560
'''
注意了,GroupBy对象总是要和聚合函数一起使用的,二者是不可割裂的。
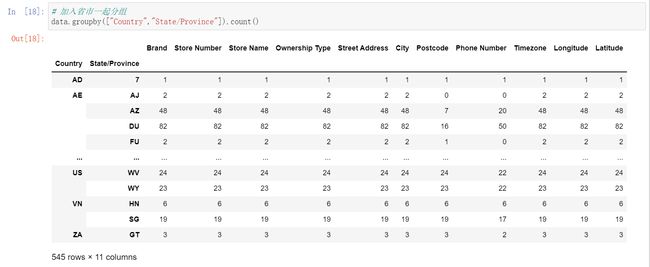
案例 星巴克零售店铺数据
- target 了解美国的星巴克和中国的哪个多,以及中国每个省的星巴克数量


三、读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
1️⃣ 读取
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())
这个to_string()用于返回DataFrame类型的数据啦,如果不加的话,默认返回head(5)啦
2️⃣ 存储
df.to_csv("site.csv")
3️⃣ 数据处理
head()
- 读取前面
n行,如果不填参数,返回默认5行
tail()
- 读取尾部
n行,如果不填,默认返回5行
info()
- 返回基本信息
四、读取JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析。
例如我们的JSON数据:sites.json
[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
import pandas as pd
# 读取文件
df = pd.read_json('sites.json')
# 直接读取
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
# 从url中读取
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df.to_string())
'''
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
'''
对于内嵌的JSON数据,例如
{
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
需要进行展平:
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
# students作为展开项
df_nested_list = pd.json_normalize(data, record_path =['students'])
print(df_nested_list)
五、数据清洗
1️⃣ 删除空字段
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
判断字段是否为空
import pandas as pd
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
当然,有时候我们遇到的空数据可能是这样n/a,可能是这样na,也可能是酱紫--,或者是None酱~
我们在读取数据中,可以设置将哪些值认定为NA值
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
print (df['NUM_BEDROOMS'].notnull())
栗子 移除指定列中的NA行
import pandas as pd
df = pd.read_csv('property-data.csv')
# 去除'ST_NUM'列中的空值
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
2️⃣ 填充空字段
我们可以用fillna()方法来替换一些空字段:
import pandas as pd
df = pd.read_csv('property-data.csv')
# 整个表查询并替换
df.fillna(12345, inplace = True)
# 找PID这行进行替换
df['PID'].fillna(12345, inplace = True)
print(df.to_string())
或者通过统计值的方法进行处理~
import pandas as pd
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean() # 均值
x = df["ST_NUM"].median() # 中位数
x = df["ST_NUM"].mode() # 众数
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
3️⃣ 格式错误
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 在处理时候,我们可以统一将其类型转化
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
4️⃣ 数据错误
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
将age大于120的设置为120
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())
将age大于120的删除
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())
5️⃣ 重复数据
如果要清洗重复数据,可以使用duplicated()和drop_dulicates()方法
如果数据是重复的,duplicated()会返回True否则会返回False
import pandas as pd
person = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
'''
0 False
1 False
2 True
3 False
dtype: bool
'''
删除重复数据,可以直接使用drop_duplicates() 方法。
import pandas as pd
persons = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(persons)
df.drop_duplicates(inplace = True)
print(df)
'''
name age
0 Google 50
1 Runoob 40
3 Taobao 23
'''
六、案例
Case 1
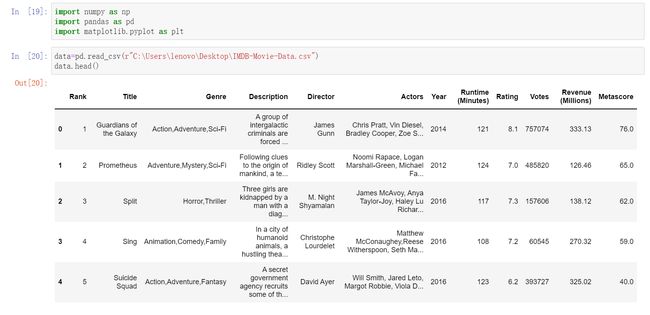

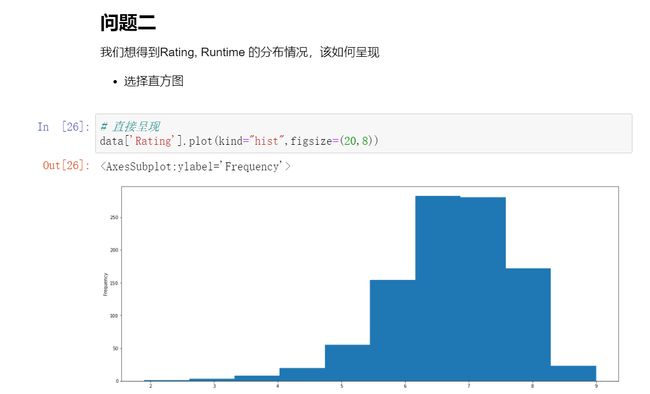


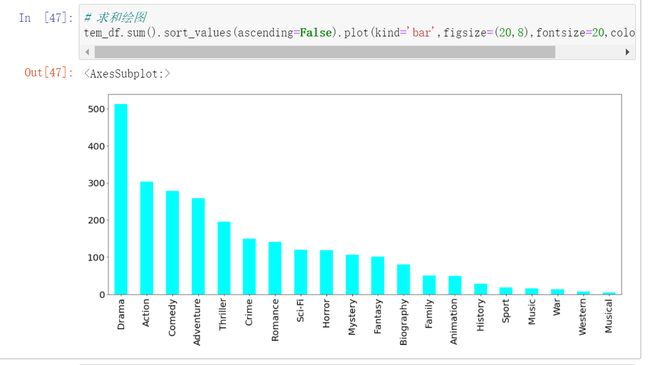
当然了,问题三有更优的解决方案:
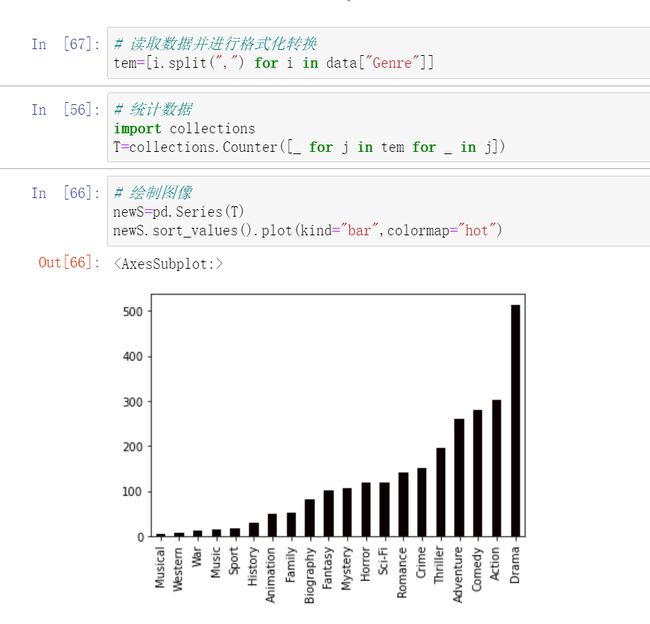
在时间复杂度和空间复杂度上都能优化。