YOLOv5与结构重参数化以及ShuffleNetV2激情碰撞【人脸检测GUI系统】
YOLOv5与结构重参数化以及ShuffleNetV2激情碰撞【人脸检测GUI系统】
一、主干网络替换为 ShuffleNetV2【ECCV2018】
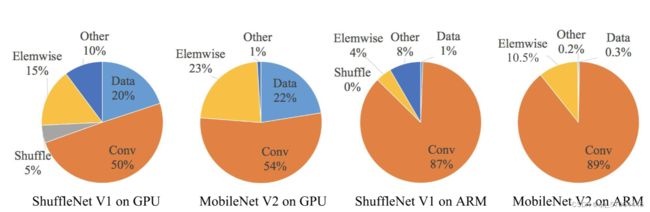
- 1、目前,神经网络架构设计主要由计算复杂度的间接指标(即 FLOPs)指导。然而,直接指标,例如速度,还取决于其他因素,例如内存访问成本和平台特性。因此,这项工作建议评估目标平台上的直接指标,而不仅仅是考虑 FLOPs。下图是性能对比:

- 2、基于一系列受控实验,这项工作得出了四个有效网络设计的实用指南:
- G1:相等的通道宽度可最大限度地降低内存访问成本 (MAC)。
- G2:过多的组卷积增加 MAC。
- G3:网络碎片化降低了并行度。
- G4: 逐元素操作是不可忽略的。
- 3、通道洗牌(Channel shuffle)

ShuffleNet的核心设计理念是对不同的channels进行shuffle来解决group convolution带来的弊端。Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection)。而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。使用group convolution的网络如Xception,MobileNet,ResNeXt等。Xception和MobileNet采用了depthwise convolution,这其实是一种比较特殊的group convolution,因此此时分组数恰好等于通道数,意味着每个组只有一个特征图。但是这些网络存在一个很大的弊端是采用了密集的1x1卷积,或者说是dense pointwise convolution,这里说的密集指的是卷积是在所有通道上进行的。 - 基于以上3个改进点我们重新设计了YOLOv5的主干网络,将其替换为带有Stem模块的ShufflenetV2的主干网络:
# TODO @QQ:1444151069 索要源码
backbone:
[ [ -1, 1, Stem, [ 32 ] ], # 0-P2/4
[ -1, 1, SNV2, [ 116, 2 ] ], # 1-P3/8
[ -1, 3, SNV2, [ 116, 1 ] ], # 2
[ -1, 1, SNV2, [ 232, 2 ] ], # 3-P4/16
[ -1, 7, SNV2, [ 232, 1 ] ], # 4
[ -1, 1, SNV2, [ 464, 2 ] ], # 5-P5/32
[ -1, 1, SNV2, [ 464, 1 ] ], # 6
]
# TODO @QQ:1444151069 索要源码
class Stem(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(Stem, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
# TODO @QQ:1444151069 索要源码
class SNV2(nn.Module):
def __init__(self, inp, oup, stride):
super(SNV2, self).__init__()...
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
二、特征融合网络加入深度可分离卷积加点卷积以及RepVGG结构重参数化
-
性能对比图:



-
RepVGG优势:
- 3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍。
- 单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。
- 单路架构省内存。例如,ResNet的shortcut虽然不占计算量,却增加了一倍的显存占用。
- 单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
- RepVGG主体部分只有一种算子:3x3卷积接ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。单路架构省内存的特性也可以帮我们少做存储单元。
- 在颈部网络添加后结构如下:

2、性能指标
- 对2000多张图片进行数据集划分后,检测精度[email protected]为0.921,[email protected]:.95为0.510,基本于原yolov5s模型指标|[email protected]为0.943mAP|@.5:.95为0.537|持平
- 计算复杂度由14.2Gflops降低至2.7Gflops
- 前向推理速度由28.9ms降低为14.8ms
- 参数量由7.01M降低为0.87M
- 改进YOLOv5s:

- 原YOLOv5s:
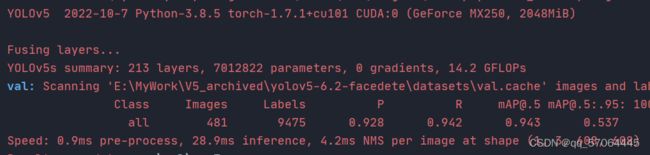
- 改进YOLOv5s:
3、说明
- GUI设计:提供加载图片按钮,可任意选择资源管理器图像检测,私信博主也可扩展视频、摄像头、输出日志等功能
- 以上数据推理端评估依靠低端显卡Nvidia GeForce MX250,不同显卡版本对比 >>> GTX 1080 Vs GTX1660 Vs MX250 显卡对比
- 可提供整个训练日志,pr曲线、混淆矩阵、模型权重等,代码依托于yolov5-6.2版本