【Triton部署目标检测模型】Linux环境 MMRotate+MMDeploy+Triton 目标检测模型训练、部署及推理最全教程
写在前面:Triton镜像加速与生成TensorRT模型所采用的的TensorRT版本需要一致。本实验中,MMDeploy版本为0.8.0,TensorRT版本为8.2.3.0,triton-server版本为22.02-py3,NVIDIA驱动为515,CUDA11.1。
特别注意:TensorRT版本需要与CUDA版本、NVIDIA 驱动版本匹配。
一、MMRotate 模型训练
MMRotate是基于PyTorch的旋转目标检测工具箱,被广泛用在遥感影像的目标检测任务中。官方指路☞:https://github.com/open-mmlab/mmrotate
1. MMRotate安装
MMRotate依赖于PyTorch、MMCV和MMDetection,快速安装如下。具体可参考官方安装教程。
conda create -n open-mmlab python=3.7 pytorch==1.7.0 cudatoolkit=10.1 torchvision -c
## 可替换自己的pytorch和cuda版本
pytorch -y
conda activate open-mmlab
pip install openmim
mim install mmcv-full
mim install mmdet
git clone https://github.com/open-mmlab/mmrotate.git
cd mmrotate
pip install -r requirements/build.txt
pip install -v -e .2. MMRotate训练
(1)数据准备
MMRotate支持多种格式的数据,包括DOTA、SSDD、HRSC、HRSID等,也支持自定义数据格式。最便捷的方式就是将数据按已有的格式类型进行组织整理,比如DOTA数据集的格式为:
mmrotate
├── data
│ ├── DOTA
│ │ ├── train
│ │ │ ├──images
│ │ │ │ ├──P00001.png # 影像文件名与标签文件名一一对应
│ │ │ │ ├──P00002.png
│ │ │ │ ├──...
│ │ │ ├──labelTxt
│ │ │ │ ├──P00001.txt # 标签文件中一行表示一个目标,由四个角点的坐标值和类别(和difficult字段)组成
│ │ │ │ ├──P00002.txt
│ │ │ │ ├──...
│ │ ├── val
│ │ │ ├──images
│ │ │ │ ├──P10001.png
│ │ │ │ ├──P10002.png
│ │ │ │ ├──...
│ │ │ ├──labelTxt
│ │ │ │ ├──P10001.txt
│ │ │ │ ├──P10002.txt
│ │ │ │ ├──...
│ │ ├── test
│ │ │ ├──images
│ │ │ │ ├──P20001.png
│ │ │ │ ├──P20002.png
│ │ │ │ ├──...
│ │ │ ├──labelTxt
│ │ │ │ ├──P20001.txt
│ │ │ │ ├──P20002.txt
│ │ │ │ ├──...(2)config文件准备
config配置文件学习:教程 1: 学习配置文件 — MMDetection 2.25.1 文档
config文件以字典的形式存储模型配置参数,主要包括4个基本组件,即数据集(dataset)、模型(model),训练策略(schedule)和运行时的默认设置(default runtime),可通过修改不同组件实现config文件的设置。
(3)模型训练
## 单卡GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
## 多卡GPU
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
'''
optional arguments 可设置的参数有:
--work-dir ${WORK_DIR} 权重文件保存路径
--resume-from ${CHECKPOINT_FILE} 从指定的权重文件继续训练
'''训练过程中会记录模型在验证集上的召回率recall和mAP,可用于评估模型的效果。训练结束后,设置的work_dirs目录下会生成权重文件.pth及对应的配置文件.py,可用于模型的测试和推理。
3. MMRotate推理
MMRotate在demo文件夹中提供了模型推理脚本image_demo.py,可通过输入待预测影像img、配置文件config(即work_dirs目录下的.py)、训练后的权重文件checkpoint(即work_dirs目录下的.pth)等,实现影像的预测推理。
在遥感影像中,通常会进行大幅影像的预测,MMRotate也贴心的提供了可用于大图推理的huge_image_demo.py,通过滑窗以切片的形式实现大图推理。
在实际应用中,mmcv读取几个G的影像还是有一定压力的,而且也无法获取影像的地理信息,因此可以考虑用gdal读取并滑窗处理。
img = gdal.Open(image)
width = img.RasterXSize
height = img.RasterYSize
channel = img.RasterCount
# prj = img.GetProjection()
# trans = img.GetGeoTransform()
# # img_data=img.ReadAsArray(0,0,width,height)
print('width: ', width, 'height: ', height, 'channel: ', channel)二、MMDeploy将Torch模型转换为TensorRT
MMDeploy 是 OpenMMLab 的模型部署工具箱,可以为各类算法库提供统一的部署体验,包括MMDetection,MMSegmentation,MMClassification,MMRotate等。官方指路:GitHub - open-mmlab/mmdeploy: OpenMMLab Model Deployment Framework

1. MMDeploy安装
MMDeploy的安装教程可参考:mmdeploy/get_started.md at master · open-mmlab/mmdeploy · GitHub
如果只需要实现PyTorch-->ONNX-->TensorRT,安装对应的ONNX和TensorRT部分即可。
重点注意:安装MMDeploy和TensorRT时,MMDeploy的TensorRT、本地安装的TensorRT、Triton Server中的TensorRT需保持一致,且TensorRT与CUDA驱动也有对应关系,务必匹配!
2. 生成TensorRT
在完成MMDeploy的安装后,可以将模型训练时的配置文件和结果权重文件拷贝至MMDeploy中对应文件下来(不拷贝也没关系,设置对应的路径即可)。MMDeploy中config文件夹下的配置文件指定了模型转换时的输入输出、动态参数等,通过调用tools文件夹下的deploy.py就可以实现PyTorch-->ONNX-->TensorRT的转换。
# run the command to start model conversion
python mmdeploy/tools/deploy.py \
mmdeploy/configs/mmrotate/rotated-detection_tensorrt-fp16_dynamic-320x320-1024x1024.py \ ## 部署的配置文件
mmrotate/configs/oriented_rcnn/Oriented_rcnn_r101_fpn_1x_dota.py \ # 模型训练时的配置文件
checkpoints/oriented_rcnn_r101_fpn_1x_dota_epoch_36.pth \ # 模型训练后的权重文件
mmrotate/demo/demo.jpg \ # 一组待推理的输入数据
--work-dir mmdeploy_model/oriented-rcnn \ # 结果保存路径
--device cuda \
--dump-info在模型转换过程中需要指定一组输入的原因: PyTorch 模型到 ONNX 模型本质上就像编译器一样彻底解析原模型的代码,记录所有控制流,但是通常只用 ONNX 记录不考虑控制流的静态图。因此,PyTorch 提供了一种叫做追踪(trace)的模型转换方法:给定一组输入,再实际执行一遍模型,即把这组输入对应的计算图记录下来,保存为 ONNX 格式。export 函数用的就是追踪导出方法,需要给任意一组输入,让模型跑起来。
转换过程部分代码如下:
① TraceWaring:表示在追踪转换的过程中没有记录流信息,大概率是因为该参数不是Tensor类型;
② Successfully created plugins:PyTorch-->ONNX-->TensroRT的转换过程是由一个个算子完成的,当TensorRT工具包中缺少某个算子时,需要进行自定义。这里MMDeploy自定义生成了MMCVMultiLevelRotatedRoiAlign和TRTBatchRotatedNMS两个算子,存储在MMDeploy/build/lib下。
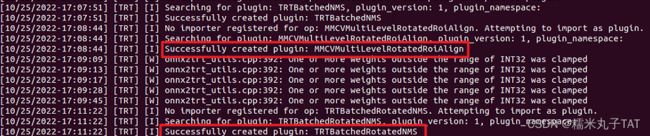
完成TensorRT转换的最终提示信息:
最终,在设置的work_dirs文件夹下,会生成七个文件,其中end2end.onnx和end2end.engine文件分别为转换后的ONNX文件和TensorRT文件。
注:.engine文件和.plan文件完全一样,只是后缀不同。
三、Triton部署及推理
NVIDIA Triton推理服务器在生产中提供快速且可拓展的AI。开源推理服务TritonInferenceServer能够从任何框架(TensorFlow、TensorRT、PyTorch、ONNX、自定义等)、在任何基础设备(GPU、CPU)上部署训练后的AI模型,从而简化AI推理过程。
1. Triton Inference Server安装
官方指路:GitHub - triton-inference-server/server: The Triton Inference Server provides an optimized cloud and edge inferencing solution.
本教程使用的是Triton Docker镜像,因此首先必须安装Nvidia Docker。
(1)拉取镜像
# 为Triton的版本
docker pull nvcr.io/nvidia/tritonserver:-py3
# 例如,拉取 22.02
docker pull nvcr.io/nvidia/tritonserver:22.02-py3
重点注意:不同Triton版本对cuda驱动的版本需求,以及对应的TensorRT版本。具体可参考Frameworks Support Matrix :: NVIDIA Deep Learning Frameworks Documentation
(2)创建模型存储库
将代码克隆到本地并创建示例模型的存储库。
## 克隆代码仓库并创建示例模型存储器
git clone https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh # 下载示例模型(3)运行Triton 的示例服务
利用下载好的示例模型运行Triton服务,这里-v 挂在的就是下载本地的示例模型文件夹。
docker run --gpus all --rm --net=host -p8000:8000 -p8001:8001 -p8002:8002 -v full/path/to/triton_server/model_repository:/models nvcr.io/nvidia/tritonserver:22.02-py3 tritonserver --model-repository=/models
# --rm表示关闭容器时删除容器成功部署的话,会看到模型的运行状态为READY,对外提供服务的端口已开启,如下所示:
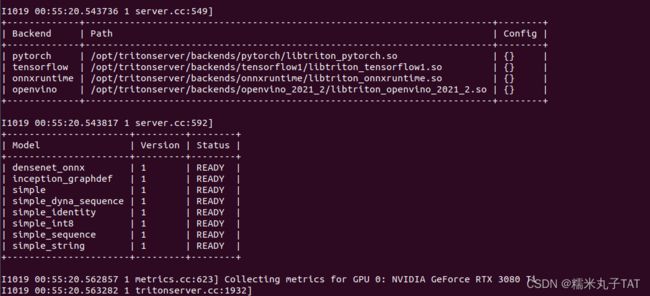

(4)验证Triton 服务
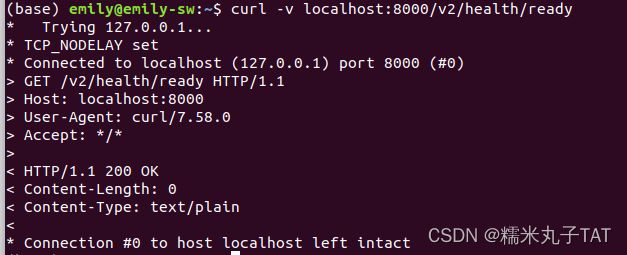
可另起一个终端,通过curl命令验证Triton服务是否正常运行。
curl -v localhost:8000/v2/health/ready
2. 生成自己的模型
上述运行Triton示例服务时,采用的是下载好的预设模型,这里我们需要根据MMDeploy生成的TenorRT配置自己的模型文件。
(1)准备TensorRT文件
新建一个models文件夹用于存储自己的模型,文件夹结构如下,可将MMDeploy生成的engine文件复制到'1'文件夹下并重命名为model.engine。
小Tips:可以在models文件夹外面新建一个plugins文件夹,把MMDeploy新生成的算子.so文件放进去,后面会用上。
/ # 新建的存储模型的文件夹,如../triton_server/models
/ # 模型名称,如OrientedRCNN_trt
config.pbtxt # 模型的配置文件
1/ # 版本号,默认为1
model.engine # MMDeploy生成的Triton文件,即end2ned.engine,可将其重命名为model.engine
(2)模型配置文件
name: "OrientedRCNN_trt" # 模型名,也是文件夹的目录名
platform: "tensorrt_plan" # 模型对应的平台,参考文章下面给出的表格
max_batch_size : 8 # 一次送入模型的最大batch_size。
input [
{
name: "input"
data_type: TYPE_FP32
dims: [ 3,-1,-1 ] # 第一个维度默认是batch size,不用配置,直接从第二个维度开始。如果是可变维度,就用 -1
}
]
output [
{
name: "dets" # 输出目标框的节点名称
data_type: TYPE_FP32
dims: [-1,6]
},
{
name: "labels" # 输出类别的节点名称
data_type: TYPE_INT32
dims: [ -1 ]
}
]
default_model_filename: "model.engine" # TensorRT的文件名其中:
name为模型名,需要与文件夹名称一致;
platform是模型对应的平台,不同模型的存储格式都有对应的值。具体如下表。
input、output包括输入输出的节点名称、数据类型、数据维度。
| 框架 | platform |
| TensorRT | tensorrt_plan |
| TensorFlow SavedModel | tensorflow_savedmodel |
| TensorFlow GraphDef | tensorflow_graphdef |
| ONNX | onnxruntime_onnx |
| Torch | pytorch_libtorch |
(3)启动服务
启动自己的服务时,多了两个参数。一个是-v中的plugins,这个对应的是MMDeploy自定义的算子文件夹,另一个是--env,这个是把自定义的算子文件libmmdeploy_tensorrt_ops.so添加到环境变量中,使容器能够调用这些算子,否则会因为缺失算子而报错。
启动服务命令如下:
docker run --gpus all --rm --net=host -p8000:8000 -p8001:8001 -p8002:8002 -v full/path/to/triton_server/models:/models -v full/path/to/triton_server/plugins:/plugins --env LD_PRELOAD=/plugins/libmmdeploy_tensorrt_ops.so nvcr.io/nvidia/tritonserver:22.02-py3 tritonserver --model-repository=/models
模型正常运行的READY:
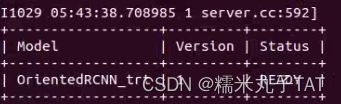
再一次看到服务端口已开启:

3. Triton Client推理
Triton服务启动后,可通过Triton Client来进行模型的推理请求,并且提供了http和grpc两种协议。下面是Python的请求示例。
import os
import time
import gevent.ssl
import numpy as np
import tritonclient.http as httpclient
from PIL import Image
from postprocess import *
def client_init(url="localhost:8000",
ssl=False, key_file=None, cert_file=None, ca_certs=None, insecure=False,
verbose=False):
if ssl:
ssl_options = {}
if key_file is not None:
ssl_options['keyfile'] = key_file
if cert_file is not None:
ssl_options['certfile'] = cert_file
if ca_certs is not None:
ssl_options['ca_certs'] = ca_certs
ssl_context_factory = None
if insecure:
ssl_context_factory = gevent.ssl._create_unverified_context
triton_client = httpclient.InferenceServerClient(
url=url,
verbose=verbose,
ssl=True,
ssl_options=ssl_options,
insecure=insecure,
ssl_context_factory=ssl_context_factory)
else:
triton_client = httpclient.InferenceServerClient(
url=url, verbose=verbose)
return triton_client
def infer(triton_client, model_name='OrientedRCNN_trt',
input='input', output0='dets', output1='labels',
request_compression_algorithm=None,
response_compression_algorithm=None):
"""
:param triton_client:启动的服务
:param model_name:模型名称
:param input:输入节点名
:param output0:输出节点名1
:param output1:输出节点名2
:return:推理结果
"""
inputs = []
outputs = []
# batch_size=8
# 如果batch_size超过配置文件的max_batch_size,infer则会报错
inputs.append(httpclient.InferInput(input, [1, 3, 1024, 1024], "FP32"))
# 给输入的数据赋值
root_dir = os.getcwd()
img_path = os.path.join(root_dir, 'data/test.tif') # 待推理的文件路径
img = np.array(Image.open(img_path))
img = img.astype(np.float32)
img = img.transpose((2, 0, 1))
img = np.expand_dims(img, axis=0) # (1, 3, 1024, 1024)
inputs[0].set_data_from_numpy(img)
outputs.append(httpclient.InferRequestedOutput(output0, binary_data=False))
outputs.append(httpclient.InferRequestedOutput(output1,
binary_data=False))
results = triton_client.infer(
model_name=model_name,
inputs=inputs,
outputs=outputs,
request_compression_algorithm=request_compression_algorithm,
response_compression_algorithm=response_compression_algorithm)
# 将结果转化为numpy格式
result_dets = results.as_numpy(output0)
result_labels = results.as_numpy(output1)
print(result_dets)
print(result_labels)
if __name__ == '__main__':
client = client_init()
infer(triton_client=client, model_name='OrientedRCNN_trt')
输出的result_dets和result_labels分别存储着目标的位置信息和类别信息。至此,即完成了Triton的部署及推理。
四、踩的一些坑
1. 驱动太low
最开始安装MMDeploy的时候采用了8.2.3.0版本的TensorRT,因此本地环境配置也采用了TensorRT 8.2.3.0,triton用的最新22.09(随便装的。。。)。然后发现示例模型可以启动,但自己的模型就怎么都搞不定,广读度娘,终于发现了bug:①我的工作站驱动是450以下,但是Triton-22.09要求驱动高于450,卒!② Triton-22.09对应的TensorRT版本是8.5.0.12,模型文件对应的TensorRT版本是8.2.3.0,Double Kill❗
2. 自定义算子
MMDeploy在生成TensorRT文件时会自定义算子,但是Triton Inference Server并不存在该算子,因此需要将生成的自定义算子作为环境变量导入镜像中,也就是启动服务时--env中的libmmdeploy_tensorrt_ops.so。否则会有如下报错:

小Tips:启动服务时的界面中(如上图所示),I开头的是提示信息,E开头的就是报错信息。
五、总结
MMRotate+MMdeploy+Triton这一套流程前后整了十来天,从安装到部署也踩了不少坑,有的没有记录,还在折腾这么久总算可用了。BUT!!!我的ONNX还没启动成功,继续跳坑中。。。。