【Yolov4训练过程记录】
训练数据准备
训练数据的来源是利用爬虫爬取的图片,这里爬取了戴口罩和不戴口罩的图片。
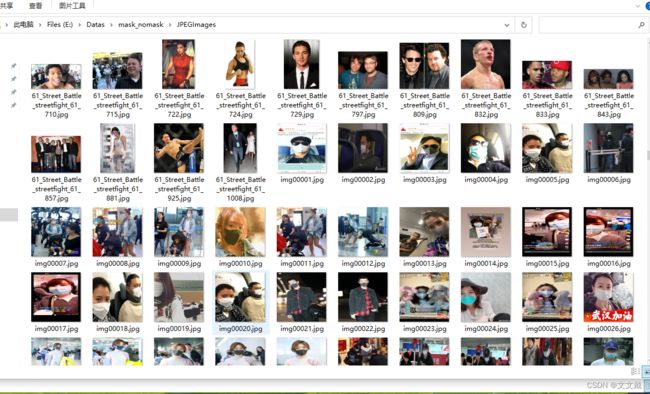
利用LableImg软件,进行类别画框,得到XML文件。怎么使用LableImg软件,上一篇博客已经说明了。
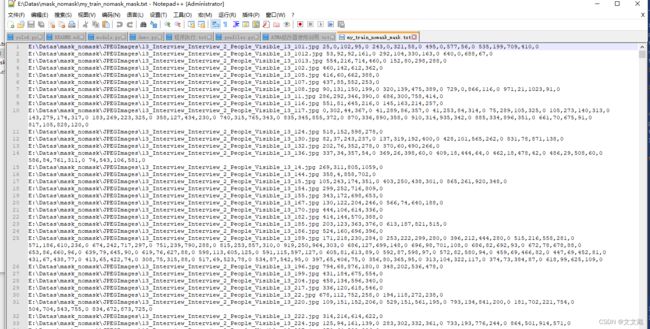
最后需要得到训练数据格式为:
route xmin,ymin,xmax,ymax,cls_id xmin,ymin,xmax,ymax,clsid …
route: 表示图片的绝对路径
xmin: 表示框的左上角横坐标
ymin: 表示框的左上角纵坐标
xmax: 表示框的右下角横坐标
ymax: 表示框的右下角纵坐标
cls_id: 表示类别
利用脚本my_data_make.py可以得到训练数据:
import xml.etree.ElementTree as ET
import os
import cv2
def myDataMake(classes, path_anno, output, path_jpg):
classes = classes # 类别-1
path_anno = path_anno # xml文件目录-2
output = output # 保存文件名-3
list = os.listdir(path_anno)
list_jpg = os.listdir(path_jpg)
line_ends = []
for i in range(0, len(list)):
path = path_anno + '\\' + list[i]
tree = ET.parse(path)
root = tree.getroot()
filename = tree.find('filename').text
if filename.endswith('.xml'): # 里面有脏的.xml,跳过清理掉
continue
if filename not in list_jpg: # 有的图片并没有在图片目录里面
continue
# 1.图片绝对路径
path_jpg = path_jpg # 图片目录-4
filename = path_jpg + '\\' + filename
line_end = [filename]
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
# 2.图片类别
cls_id = str(classes.index(cls))
# 3.xmin ymin xmax ymax
xmlbox = obj.find('bndbox')
xmin = str(xmlbox.find('xmin').text)
ymin = str(xmlbox.find('ymin').text)
xmax = str(xmlbox.find('xmax').text)
ymax = str(xmlbox.find('ymax').text)
# xmin,ymin,xmax,ymax,cls_id
line = ','.join([xmin, ymin, xmax, ymax, cls_id])
line_end.append(line)
line_end = ' '.join(line_end) + '\n'
line_ends.append(line_end)
fw = open(output, 'w')
fw.writelines(line_ends)
fw.close()
if __name__ == '__main__':
classes = ['nomask', 'mask'] # 类别-1
path_anno = r'E:\Datas\mask_nomask\Annotations' # xml文件目录-2
output = r'E:\Datas\mask_nomask\my_train_nomask_mask.txt' # 保存文件名-3
path_jpg = r'E:\Datas\mask_nomask\JPEGImages' # 图片目录-4
myDataMake(classes, path_anno, output, path_jpg)
# img = cv2.imread(filename)
# cv2.imshow('my', img)
# cv2.waitKey(0)
脚本中main函数下的classes、path_anno、output、path_jpg。四个参数需要根据自己的实际情况进行设定。最后得到的数据为以下截图:
训练参数设置与训练
上面是训练数据已经准备好,下面是训练的主函数train_dark_mycode.py:
import os
# import sys
# sys.path.append(r'D:\ubuntu_share\yolov4-pytorch1')
import numpy as np
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader
from utils.dataloader import train_dataset_collate, test_dataset_collate, TrainDataset, TestDataset
from utils.generator import TrainGenerator, TestGenerator
from yolo_loss_mycode import YOLOLoss
from yolo_layer_mycode import YoloLayer
from tqdm import tqdm
from darknet.darknet import *
from easydict import EasyDict
from config_mycode import Cfg # 这里没有错,不管它
from Evaluation.map_eval_pil import compute_map
from tensorboardX import SummaryWriter
from utils.utils import *
Cfg.darknet_cfg = r'E:\Datas\mask_nomask\yolo4_train_nomask_mask.cfg' # 配置文件
Cfg.train_data = r'E:\Datas\mask_nomask\my_train_nomask_mask.txt' # 训练数据
Cfg.anchors_path = r'E:\Datas\mask_nomask\yolo_anchors_nomask_mask.txt' # 锚框大小文件
Cfg.classes_path = r'E:\Datas\mask_nomask\my_classes_nomask_mask.txt' # 类别文件
Cfg.weights_path = 'weights/yolov4.weights' # 就用yolov4的起始权重 # yolov4初始权重
Cfg.pth_path = r'chk_dark/Epoch_053_Loss_9.1503_nomask_mask.pth' # 如果是接着上次训练,要给出接着训练的权重
Cfg.check = 'chk_dark' # 训练的权重保存在这里
Cfg.use_data_loader = True
Cfg.first_train = False
Cfg.cur_epoch = 0
Cfg.total_epoch = 80 # 自己训练的数据集与COCO差异很大,最好设置100或者120
Cfg.freeze_mode = False
# valid
Cfg.valid_mode = False # 是否做验证
Cfg.confidence = 0.3
Cfg.nms_thresh = 0.4
Cfg.draw_box = True # 知否把错检和漏检的框画出保存下来
Cfg.save_error_miss = False
Cfg.input_dir = r'E:\Datas\mask_nomask\JPEGImages' # 训练时图片所在的目录
Cfg.save_err_mis = True # 是否保存保存画错了的框
# 调用Evaluation模块, 进行map计算和类别准召率计算
def make_labels_and_compute_map(infos, classes, input_dir, save_err_miss=False):
out_lines, gt_lines = [], []
out_path = 'Evaluation/out.txt'
gt_path = 'Evaluation/true.txt'
foutw = open(out_path, 'w')
fgtw = open(gt_path, 'w')
for info in infos:
out, gt, shapes = info
for i, images in enumerate(out):
for box in images:
bbx = [box[0] * shapes[i][1], box[1] * shapes[i][0], box[2] * shapes[i][1], box[3] * shapes[i][0]]
bbx = str(bbx)
cls = classes[int(box[6])]
prob = str(box[4])
img_name = os.path.split(shapes[i][2])[-1]
line = '\t'.join([img_name, 'Out:', cls, prob, bbx]) + '\n'
out_lines.append(line)
for i, images in enumerate(gt):
for box in images:
bbx = str(box.tolist()[0:4])
cls = classes[int(box[4])]
img_name = os.path.split(shapes[i][2])[-1]
line = '\t'.join([img_name, 'Out:', cls, '1.0', bbx]) + '\n'
gt_lines.append(line)
foutw.writelines(out_lines)
fgtw.writelines(gt_lines)
foutw.close()
fgtw.close()
args = EasyDict()
args.annotation_file = 'Evaluation/true.txt'
args.detection_file = 'Evaluation/out.txt'
args.detect_subclass = False
args.confidence = 0.3 # 更关注准确度,可以调高它,更注重召回可以降低它
args.iou = 0.2 #
args.record_mistake = True
args.draw_full_img = save_err_miss
args.draw_cut_box = False
args.input_dir = input_dir
args.out_dir = 'out_dir' # 错检和漏检的都放在了这个文件夹里面
Map = compute_map(args)
return Map
# ---------------------------------------------------#
# 获得类和先验框
# ---------------------------------------------------#
def get_classes(classes_path):
'''loads the classes'''
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
'''loads the anchors from a file'''
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape([-1, 3, 2])
# return np.array(anchors).reshape([-1, 3, 2])[::-1, :, :]
def get_lr(optimizer):
for param_group in optimizer.param_groups:
return param_group['lr']
def gen_lr_scheduler(lr, cur_epoch, model):
init_lr = lr * pow(0.9, cur_epoch)
print('init learning rate:', init_lr)
optimizer = optim.Adam(model.parameters(), init_lr, weight_decay=5e-4)
if Cfg.cosine_lr:
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5)
else:
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.9)
return lr_scheduler, optimizer
def gen_burnin_lr_scheduler(lr, cur_batch, model):
# learning rate setup
def burnin_schedule(i):
i = i + 1
if i < Cfg.burn_in:
factor = pow(i / Cfg.burn_in, 4)
elif i < Cfg.steps[0]:
factor = 1.0
elif i < Cfg.steps[1]:
factor = 0.1
else:
factor = 0.01
return factor
if Cfg.TRAIN_OPTIMIZER == 'adam':
optimizer = optim.Adam(
[{'params': model.parameters(), 'initial_lr': lr}],
lr=lr,
betas=(0.9, 0.999),
eps=1e-08,
)
elif Cfg.TRAIN_OPTIMIZER == 'sgd':
optimizer = optim.SGD(
[{'params': model.parameters(), 'initial_lr': lr}],
lr=lr,
momentum=Cfg.momentum,
weight_decay=Cfg.decay,
)
else:
print('optimizer must be adam or sgd...')
return None, None
scheduler = optim.lr_scheduler.LambdaLR(optimizer, burnin_schedule, last_epoch=cur_batch - 1)
print('update learning rate:', scheduler.get_last_lr()[0])
return scheduler, optimizer
def get_train_lines(train_data):
# 0.1用于验证,0.9用于训练
val_split = 0.1
with open(train_data) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines) * val_split)
num_train = len(lines) - num_val
return lines, num_train, num_val
def freeze_training_dark(model, flag=False, layers=137):
for name, param in model.named_parameters():
if int(name.split('.')[1]) <= layers:
print(int(name.split('.')[1]))
param.requires_grad = flag
def print_model(model):
model_dict = model.state_dict()
for key in model_dict:
print('model items:', key, '---->', np.shape(model_dict[key]))
def load_model_pth(model, pth):
print('Loading weights into state dict, name: %s' % (pth))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(pth, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
for key in pretrained_dict:
print('pretrained items:', key)
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
return model
def get_epoch_by_pth():
try:
pth = Cfg.pth_path
epoch = os.path.split(pth)[-1].split('_')[1]
epoch = int(epoch)
except Exception as e:
print(e, 'start epoch: %d' % Cfg.cur_epoch)
return Cfg.cur_epoch
return epoch
def find_pth_by_epoch(epoch, path):
pth_list = os.listdir(path)
for name in pth_list:
curpo = name.split('_')[1]
if curpo == '%03d' % (epoch):
return os.path.join(path, name)
return ''
def valid(epoch_lis, classes, draw=True, cuda=True, anchors=[]):
writer = SummaryWriter(log_dir='valid_logs', flush_secs=60)
epoch_size_val = num_val // gpu_batch
model = Darknet(Darknet_Cfg)
anchor_masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
yolo_decodes = []
anchors = anchors.reshape([-1])
for i in range(3):
head = YoloLayer((Cfg.width, Cfg.height), anchor_masks, len(classes),
anchors, anchors.shape[0] // 2).eval()
yolo_decodes.append(head)
if Use_Data_Loader:
val_dataset = TestDataset(lines[num_train:], (input_shape[0], input_shape[1]))
gen_val = DataLoader(val_dataset, batch_size=gpu_batch, num_workers=8, pin_memory=True,
drop_last=True, collate_fn=test_dataset_collate)
else:
gen_val = TestGenerator(gpu_batch, lines[num_train:],
(input_shape[0], input_shape[1])).generate()
for epo in epoch_lis:
pth_path = find_pth_by_epoch(epo, Cfg.check)
if not pth_path:
print('pth_path is error...')
return False
model = load_model_pth(model, pth_path)
cudnn.benchmark = True
model = model.cuda()
model.eval()
with tqdm(total=epoch_size_val, mininterval=0.3) as pbar:
infos = []
for i, batch in enumerate(gen_val):
images_src, images, targets, shapes = batch[0], batch[1], batch[2], batch[3]
with torch.no_grad():
if cuda:
images_val = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
else:
images_val = Variable(torch.from_numpy(images).type(torch.FloatTensor))
outputs = model(images_val)
output_list = []
for i in range(3):
output_list.append(yolo_decodes[i](outputs[i]))
output = torch.cat(output_list, 1)
batch_detections = non_max_suppression(output, len(classes),
conf_thres=Cfg.confidence,
nms_thres=Cfg.nms_thresh)
# print(batch_detections)
boxs = [box.cpu().numpy() for box in batch_detections if box != None]
# boxs = utils.post_processing(images_val, Cfg.confidence, Cfg.nms_thresh, outputs)
infos.append([boxs, targets, shapes])
if draw: # 会把所有验证图片上画出框并保存在result_%d文件夹下面
for x in range(len(boxs)):
os.makedirs('result_%d' % epo, exist_ok=True)
savename = os.path.join('result_%d' % epo, os.path.split(shapes[x][2])[-1])
plot_boxes_cv2(images_src[x], boxs[x], savename=savename, class_names=class_names)
pbar.update(1)
print()
print(
'===========================================================================================================')
print('++++++++cur valid epoch %d, pth_name: %s++++++++' % (epo, pth_path))
Map = make_labels_and_compute_map(infos, classes, Cfg.input_dir, save_err_miss=Cfg.save_err_mis)
writer.add_scalar('MAP/epoch', Map, epo)
print()
return True
def train(cur_epoch, Epoch, cuda=True, anchors=[]):
# 使用tensorboardX来可视化训练指标
writer = SummaryWriter(log_dir='train_logs', flush_secs=60)
model = Darknet(Darknet_Cfg)
model.print_network()
# 第一次训练直接导入darknet的权重
# 中间训练导入check_point里的权重
# cut:
# 默认: 137, 推荐104(only backbone), 116(backbone+SPP), 126(backbone+SPP+1_concat)
# cut必须 < 138,因为138刚好是76的1X1卷积头部,不同类别数的检测任务,1X1预测卷积的权重参数是不一样的
if Cfg.first_train:
model.load_weights(weights_path, pretrained=True, cut=137)
else:
model = load_model_pth(model, pth_path)
cudnn.benchmark = True
model = model.cuda()
# 建立loss函数
yolo_losses = []
for i in range(3):
yolo_losses.append(YOLOLoss(np.reshape(anchors, [-1, 2]), num_classes,
(input_shape[1], input_shape[0]), smoooth_label))
# lr_scheduler, optimizer = gen_lr_scheduler(lr, cur_epoch, model)
# 使用darknet框架里的burn_in训练方法
lr_scheduler, optimizer = gen_burnin_lr_scheduler(lr, cur_batch, model)
# if Cfg.freeze_mode:
# freeze_training_dark(model, flag=False, layers=137)
# else:
# freeze_training_dark(model, flag=True, layers=137)
if Use_Data_Loader:
train_dataset = TrainDataset(lines[:num_train], (input_shape[0], input_shape[1]), mosaic=mosaic)
gen = DataLoader(train_dataset, batch_size=gpu_batch, num_workers=8, pin_memory=True,
drop_last=True, collate_fn=train_dataset_collate)
else:
gen = TrainGenerator(gpu_batch, lines[:num_train],
(input_shape[0], input_shape[1])).generate(mosaic=mosaic)
epoch_size = max(1, num_train // gpu_batch)
for epoch in range(cur_epoch, Epoch):
total_loss = 0
cur_step = 0
with tqdm(total=epoch_size, desc=f'Epoch {epoch + 1}/{Epoch}', postfix=dict, mininterval=0.3) as pbar:
model.train()
start_time = time.time()
for iteration, batch in enumerate(gen):
if iteration >= epoch_size:
break
images, targets = batch[0], batch[1]
with torch.no_grad():
if cuda:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor)).cuda()
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
else:
images = Variable(torch.from_numpy(images).type(torch.FloatTensor))
targets = [Variable(torch.from_numpy(ann).type(torch.FloatTensor)) for ann in targets]
outputs = model(images)
losses = []
losses_loc = []
losses_conf = []
losses_cls = []
for i in range(3):
loss_item = yolo_losses[i](outputs[i], targets)
losses.append(loss_item[0])
losses_loc.append(loss_item[3])
losses_conf.append(loss_item[1])
losses_cls.append(loss_item[2])
loss = sum(losses) / Cfg.subdivisions
loss_loc = sum(losses_loc)
loss_conf = sum(losses_conf)
loss_cls = sum(losses_cls)
loss.backward()
waste_time = time.time() - start_time
total_loss += loss
cur_step += 1
# 将第五个Epoch开始写入到tensorboard,每一步都写
if epoch > 2:
writer.add_scalar('total_loss/gpu_batch', loss * Cfg.subdivisions, (epoch * epoch_size + iteration))
writer.add_scalar('loss_loc/gpu_batch', loss_loc, (epoch * epoch_size + iteration))
writer.add_scalar('loss_conf/gpu_batch', loss_conf, (epoch * epoch_size + iteration))
writer.add_scalar('loss_cls/gpu_batch', loss_cls, (epoch * epoch_size + iteration))
if cur_step % Cfg.subdivisions == 0:
optimizer.step()
if Cfg.burn_in > 0:
lr_scheduler.step()
model.zero_grad()
pbar.set_postfix(**{'loss_cur': loss.item() * Cfg.subdivisions,
'loss_total': total_loss.item() / (iteration + 1) * Cfg.subdivisions,
'lr': get_lr(optimizer),
'step/s': waste_time})
pbar.update(1)
start_time = time.time()
# if Cfg.burn_in == 0:
# lr_scheduler.step()
print('Epoch:' + str(epoch + 1) + '/' + str(Epoch))
print('Total Loss: %.4f || Last Loss: %.4f ' % (
total_loss / (epoch_size + 1) * Cfg.subdivisions, loss.item() * Cfg.subdivisions))
print('Saving state, iter:', str(epoch + 1))
torch.save(model.state_dict(), '%s/Epoch_%03d_Loss_%.4f_nomask_mask.pth' % (Cfg.check,
(epoch + 1), total_loss / (
epoch_size + 1) * Cfg.subdivisions))
if __name__ == "__main__":
# 一般为608
input_shape = (Cfg.h, Cfg.w)
# 是否使用余弦学习率
Cosine_lr = Cfg.cosine_lr
# 是否使用马赛克数据增强
mosaic = Cfg.mosaic
# 用于设定是否使用cuda
Cuda = True
smoooth_label = Cfg.smoooth_label
# -------------------------------#
# Dataloder的使用
# -------------------------------#
Use_Data_Loader = Cfg.use_data_loader
Darknet_Cfg = Cfg.darknet_cfg
train_data = Cfg.train_data
# -------------------------------#
# 获得先验框和类
# -------------------------------#
class_names = get_classes(Cfg.classes_path)
num_classes = len(class_names)
print('classes:', class_names, num_classes)
lr = Cfg.learning_rate
batch_size = Cfg.batch
# 是否为首次训练
if Cfg.first_train:
cur_epoch = 0
else:
cur_epoch = get_epoch_by_pth()
total_epoch = Cfg.total_epoch
# 一次送入GPU的数据量
gpu_batch = Cfg.batch // Cfg.subdivisions
lines, num_train, num_val = get_train_lines(train_data)
# 当前的训练batch数,用于调节是否burn_in,以及学习率,恢复训练时会使用到
# 首次训练为0
cur_batch = num_train * cur_epoch // batch_size
# 1.需要生成的先验框尺寸,如果用darknet权重和cfg加载,会使用yolov4.cfg里的anchors
# 2.对于计算训练损失,不论是darknet权重加载还是pth加载,都需要使用这个参数
anchors = get_anchors(Cfg.anchors_path)
weights_path = Cfg.weights_path # 如果是第一次训练就从weights\yolov4.weights载入权重
pth_path = Cfg.pth_path # 如果是中断的,就从chk_dark\Epoch_050_Loss_7.7722.pth载入先前训练好的权重
if Cfg.valid_mode:
valid([50], classes={0: 'nomask', 1: 'mask'}, draw=Cfg.draw_box, anchors=anchors) # 50表示验证哪个epoch
else:
train(cur_epoch, total_epoch, cuda=True, anchors=anchors)
上面的主代码,已经在所有的参数旁边给出注释,特别说明下主要关注的几个参数。
Cfg.darknet_cfg = r'E:\Datas\mask_nomask\yolo4_train_nomask_mask.cfg' # 配置文件
Cfg.train_data = r'E:\Datas\mask_nomask\my_train_nomask_mask.txt' # 训练数据
Cfg.anchors_path = r'E:\Datas\mask_nomask\yolo_anchors_nomask_mask.txt' # 锚框大小文件
Cfg.classes_path = r'E:\Datas\mask_nomask\my_classes_nomask_mask.txt' # 类别文件
Cfg.weights_path = 'weights/yolov4.weights' # 就用yolov4的起始权重 # yolov4初始权重
Cfg.pth_path = r'chk_dark/Epoch_053_Loss_9.1503_nomask_mask.pth' # 如果是接着上次训练,要给出接着训练的权重
E:\Datas\mask_nomask\yolo4_train_nomask_mask.cfg:配置文件
E:\Datas\mask_nomask\my_train_nomask_mask.txt:
训练数据
E:\Datas\mask_nomask\yolo_anchors_nomask_mask.txt:锚框大小
E:\Datas\mask_nomask\my_classes_nomask_mask.txt:类别文件
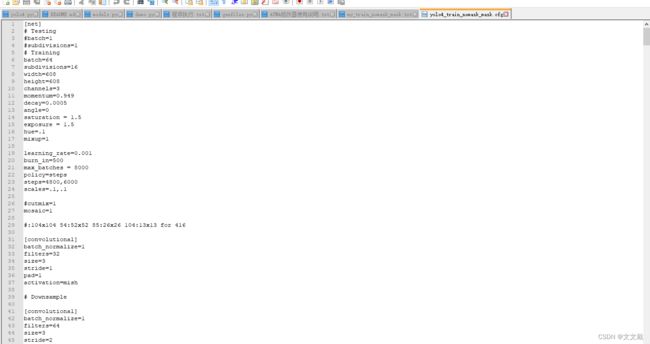
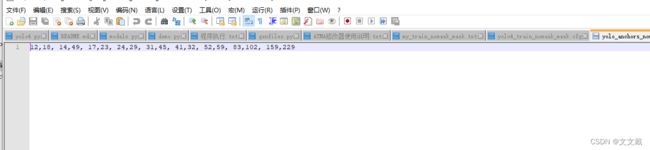
下面为每个文件的截图:
配置文件:
训练数据:
训练数据上面已经截图过
锚框大小:
类别文件:

由于配置文件非常重要,这里把配置文件的全部内容给出:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=16
width=608
height=608
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
mixup=1
learning_rate=0.001
burn_in=500
max_batches = 8000
policy=steps
steps=4800,6000
scales=.1,.1
#cutmix=1
mosaic=1
#:104x104 54:52x52 85:26x26 104:13x13 for 416
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-7
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-10
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-28
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -2
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=mish
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=mish
[route]
layers = -1,-16
[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=1
activation=mish
##########################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
### SPP ###
[maxpool]
stride=1
size=5
[route]
layers=-2
[maxpool]
stride=1
size=9
[route]
layers=-4
[maxpool]
stride=1
size=13
[route]
layers=-1,-3,-5,-6
### End SPP ###
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 85
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = 54
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -1, -3
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
##########################
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 0,1,2
anchors = 12,18, 14,49, 17,23, 24,29, 31,45, 41,32, 52,59, 83,102, 159,229
classes=2
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.2
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=256
activation=leaky
[route]
layers = -1, -16
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 3,4,5
anchors = 12,18, 14,49, 17,23, 24,29, 31,45, 41,32, 52,59, 83,102, 159,229
classes=2
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
size=3
stride=2
pad=1
filters=512
activation=leaky
[route]
layers = -1, -37
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear
[yolo]
mask = 6,7,8
anchors = 12,18, 14,49, 17,23, 24,29, 31,45, 41,32, 52,59, 83,102, 159,229
classes=2
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6

最后三个的[convolution]和[yolo]里面的fiters和classes参数一定改成跟自己情况相同参数大小。
还有两个文件也非常重要:yolo_loss_mycode.py和config_mycode.py,这里也把他们的代码发出来:
yolo_loss_mycode.py:
import cv2
from random import shuffle
import numpy as np
import torch
torch.cuda.current_device()
import torch.nn as nn
import math
import torch.nn.functional as F
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
from PIL import Image
from utils.utils import bbox_iou, merge_bboxes
def iou(_box_a, _box_b):
b1_x1, b1_x2 = _box_a[:, 0] - _box_a[:, 2] / 2, _box_a[:, 0] + _box_a[:, 2] / 2
b1_y1, b1_y2 = _box_a[:, 1] - _box_a[:, 3] / 2, _box_a[:, 1] + _box_a[:, 3] / 2
b2_x1, b2_x2 = _box_b[:, 0] - _box_b[:, 2] / 2, _box_b[:, 0] + _box_b[:, 2] / 2
b2_y1, b2_y2 = _box_b[:, 1] - _box_b[:, 3] / 2, _box_b[:, 1] + _box_b[:, 3] / 2
box_a = torch.zeros_like(_box_a)
box_b = torch.zeros_like(_box_b)
box_a[:, 0], box_a[:, 1], box_a[:, 2], box_a[:, 3] = b1_x1, b1_y1, b1_x2, b1_y2
box_b[:, 0], box_b[:, 1], box_b[:, 2], box_b[:, 3] = b2_x1, b2_y1, b2_x2, b2_y2
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
inter = inter[:, :, 0] * inter[:, :, 1]
# 计算先验框和真实框各自的面积
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2] - box_b[:, 0]) *
(box_b[:, 3] - box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
# 求IOU
union = area_a + area_b - inter
return inter / union # [A,B]
# ---------------------------------------------------#
# 平滑标签
# ---------------------------------------------------#
def smooth_labels(y_true, label_smoothing, num_classes):
return y_true * (1.0 - label_smoothing) + label_smoothing / num_classes
def box_ciou(b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
ciou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
# 求出预测框左上角右下角
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh / 2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# 求出真实框左上角右下角
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh / 2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
# 求真实框和预测框所有的iou
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / torch.clamp(union_area, min=1e-6)
# 计算中心的差距
center_distance = torch.sum(torch.pow((b1_xy - b2_xy), 2), axis=-1)
# 找到包裹两个框的最小框的左上角和右下角
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
# 计算对角线距离
enclose_diagonal = torch.sum(torch.pow(enclose_wh, 2), axis=-1)
ciou = iou - 1.0 * (center_distance) / torch.clamp(enclose_diagonal, min=1e-6)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b1_wh[..., 0] / torch.clamp(b1_wh[..., 1], min=1e-6)) - torch.atan(
b2_wh[..., 0] / torch.clamp(b2_wh[..., 1], min=1e-6))), 2)
alpha = v / torch.clamp((1.0 - iou + v), min=1e-6)
ciou = ciou - alpha * v
return ciou
# 范围切割函数t内的值不能低于t_min, 不能高于t_max
def clip_by_tensor(t, t_min, t_max):
t = t.float()
result = (t >= t_min).float() * t + (t < t_min).float() * t_min
result = (result <= t_max).float() * result + (result > t_max).float() * t_max
return result
# 均值损失
def MSELoss(pred, target):
return (pred - target) ** 2
# 二分类交叉熵损失
def BCELoss(pred, target):
epsilon = 1e-7
pred = clip_by_tensor(pred, epsilon, 1.0 - epsilon)
output = -target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred)
return output
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, img_size, label_smooth=0, cuda=True):
super(YOLOLoss, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.img_size = img_size
self.feature_length = [img_size[0] // 8, img_size[0] // 16, img_size[0] // 32]
self.label_smooth = label_smooth
self.ignore_threshold = 0.7
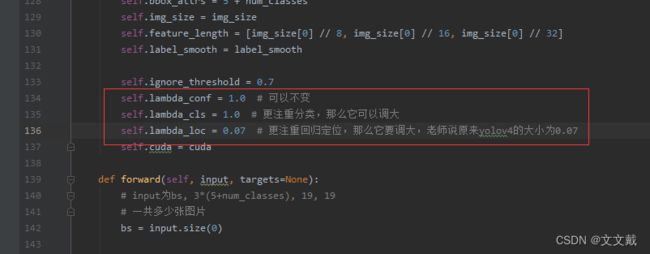
self.lambda_conf = 1.0 # 可以不变
self.lambda_cls = 1.0 # 更注重分类,那么它可以调大
self.lambda_loc = 1.0 # 更注重回归定位,那么它要调大,老师说原来yolov4的大小为0.07
self.cuda = cuda
def forward(self, input, targets=None):
# input为bs, 3*(5+num_classes), 19, 19
# 一共多少张图片
bs = input.size(0)
# 特征图的高和宽
in_h = input.size(2)
in_w = input.size(3)
# 计算歩长,每一个特征点对应原来的图片上多少个像素点,如果特征层为19*19的话,一个特征点就对应原来图片32个像素点
stride_h = self.img_size[1] / in_h
stride_w = self.img_size[0] / in_w
# 把先验框的尺寸调整成特征层大小的形式,计算出先验框在特征层上的对应的宽高
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
prediction = input.view(bs, int(self.num_anchors / 3), self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4,
2).contiguous()
# 对prediction预测进行调整
conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# build_target流程1, 构造各类掩码,填充掩码正样本
mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y = self.get_target(targets, scaled_anchors, in_w, in_h)
# build_target流程2, 筛选负样本,并对头部做DECODE
noobj_mask, pred_boxes_for_ciou = self.get_ignore(prediction, targets, scaled_anchors, in_w, in_h, noobj_mask)
# 开始计算最终想要的loss
if self.cuda:
mask, noobj_mask = mask.cuda(), noobj_mask.cuda()
box_loss_scale_x, box_loss_scale_y = box_loss_scale_x.cuda(), box_loss_scale_y.cuda()
tconf, tcls = tconf.cuda(), tcls.cuda()
pred_boxes_for_ciou = pred_boxes_for_ciou.cuda()
t_box = t_box.cuda()
box_loss_scale = 2 - box_loss_scale_x * box_loss_scale_y
# loss_loc : 位置回归损失
ciou = box_ciou(pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()])
loss_ciou = 1 - ciou
loss_ciou = loss_ciou * box_loss_scale[mask.bool()]
# ciou = (1 - box_ciou( pred_boxes_for_ciou[mask.bool()], t_box[mask.bool()]))* box_loss_scale[mask.bool()]
loss_loc = torch.sum(loss_ciou / bs)
# loss_conf :物体置信度损失。# 这里认为正样本损失和负样本损失都是一样的。当正样本很少时,可以正样本上乘以5如: 5 * torch.sum(BCELoss(conf, mask) * mask / bs)
loss_conf = torch.sum(BCELoss(conf, mask) * mask / bs) + \
torch.sum(BCELoss(conf, mask) * noobj_mask / bs)
# loss_cls :类别交叉熵损失
loss_cls = torch.sum(
BCELoss(pred_cls[mask == 1], smooth_labels(tcls[mask == 1], self.label_smooth, self.num_classes)) / bs)
# 得到最终的loss = loss_loc + loss_conf + loss_cls
loss = loss_loc * self.lambda_loc + loss_conf * self.lambda_conf + loss_cls * self.lambda_cls
return loss, loss_conf.item(), loss_cls.item(), loss_loc.item()
def get_target(self, targets, anchors, in_w, in_h):
# 计算一共有多少张图片
bs = len(targets)
# 获得先验框
anchor_index = [[0, 1, 2], [3, 4, 5], [6, 7, 8]][self.feature_length.index(in_w)]
subtract_index = [0, 3, 6][self.feature_length.index(in_w)]
# 掩码初始化
mask = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
noobj_mask = torch.ones(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
tx = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
ty = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
tw = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
th = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
t_box = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, 4, requires_grad=False)
tconf = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
tcls = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, self.num_classes, requires_grad=False)
box_loss_scale_x = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
box_loss_scale_y = torch.zeros(bs, int(self.num_anchors / 3), in_h, in_w, requires_grad=False)
for b in range(bs):
for t in range(targets[b].shape[0]):
# 将xywh换算成网格为单位的数值
gx = targets[b][t, 0] * in_w
gy = targets[b][t, 1] * in_h
gw = targets[b][t, 2] * in_w
gh = targets[b][t, 3] * in_h
# 计算出属于哪个网格
gi = int(gx)
gj = int(gy)
# 将gt_box挪动到0,0坐标上
gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0)
# 将9个先验框挪到到0,0坐标上
anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((self.num_anchors, 2)), np.array(anchors)), 1))
# 计算重合度
anch_ious = bbox_iou(gt_box, anchor_shapes)
# 找到最匹配的anchor序号,如果序号不再当前对应头部就continue,否则进行掩码正样本填充
best_n = np.argmax(anch_ious)
if best_n not in anchor_index:
continue
# Masks
if (gj < in_h) and (gi < in_w):
best_n = best_n - subtract_index
# 判定哪些先验框内部真实的存在物体
noobj_mask[b, best_n, gj, gi] = 0
mask[b, best_n, gj, gi] = 1
# 计算先验框中心调整参数
tx[b, best_n, gj, gi] = gx
ty[b, best_n, gj, gi] = gy
# 计算先验框宽高调整参数
tw[b, best_n, gj, gi] = gw
th[b, best_n, gj, gi] = gh
# 用于获得xywh的比例
box_loss_scale_x[b, best_n, gj, gi] = targets[b][t, 2]
box_loss_scale_y[b, best_n, gj, gi] = targets[b][t, 3]
# 物体置信度
tconf[b, best_n, gj, gi] = 1
# 种类
tcls[b, best_n, gj, gi, int(targets[b][t, 4])] = 1
else:
print('Step {0} out of bound'.format(b))
print('gj: {0}, height: {1} | gi: {2}, width: {3}'.format(gj, in_h, gi, in_w))
continue
t_box[..., 0] = tx
t_box[..., 1] = ty
t_box[..., 2] = tw
t_box[..., 3] = th
return mask, noobj_mask, t_box, tconf, tcls, box_loss_scale_x, box_loss_scale_y
def get_ignore(self, prediction, target, scaled_anchors, in_w, in_h, noobj_mask):
bs = len(target)
anchor_index = [[0, 1, 2], [3, 4, 5], [6, 7, 8]][self.feature_length.index(in_w)]
scaled_anchors = np.array(scaled_anchors)[anchor_index]
# 先验框的中心位置的调整参数
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
# 先验框的宽高调整参数
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
# 生成网格,先验框中心,网格左上角
grid_x = torch.linspace(0, in_w - 1, in_w).repeat(in_w, 1).repeat(
int(bs * self.num_anchors / 3), 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, in_h - 1, in_h).repeat(in_h, 1).t().repeat(
int(bs * self.num_anchors / 3), 1, 1).view(y.shape).type(FloatTensor)
# 生成先验框的宽高
anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0]))
anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_w = anchor_w.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(w.shape)
anchor_h = anchor_h.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(h.shape)
# 计算调整后的先验框中心与宽高
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x + grid_x
pred_boxes[..., 1] = y + grid_y
pred_boxes[..., 2] = torch.exp(w) * anchor_w
pred_boxes[..., 3] = torch.exp(h) * anchor_h
for i in range(bs):
pred_boxes_for_ignore = pred_boxes[i]
pred_boxes_for_ignore = pred_boxes_for_ignore.view(-1, 4)
if len(target[i]) > 0:
gx = target[i][:, 0:1] * in_w
gy = target[i][:, 1:2] * in_h
gw = target[i][:, 2:3] * in_w
gh = target[i][:, 3:4] * in_h
gt_box = torch.FloatTensor(np.concatenate([gx, gy, gw, gh], -1)).type(FloatTensor)
anch_ious = iou(gt_box, pred_boxes_for_ignore)
for t in range(target[i].shape[0]):
anch_iou = anch_ious[t].view(pred_boxes[i].size()[:3])
noobj_mask[i][anch_iou > self.ignore_threshold] = 0
return noobj_mask, pred_boxes
yolo_loss_mycode.py是构造的自己的损失函数:里面三个参数非常重要
config_mycode.py:
from easydict import EasyDict
Cfg = EasyDict()
Cfg.batch = 64
Cfg.subdivisions = 16 # 11G的gpu可以设置16,如果小于11G,就填32
Cfg.width = 608
Cfg.height = 608
Cfg.momentum = 0.949
Cfg.decay = 0.0005
Cfg.angle = 0
Cfg.saturation = 1.5
Cfg.exposure = 1.5
Cfg.hue = .1
Cfg.jitter = 0.3
Cfg.mosaic = True
Cfg.learning_rate = 0.001
Cfg.burn_in = 500 # batch小于它的时候,学习率是从小到大的直到0.001,建议500
Cfg.max_batches = 8000 # 把max_batches设置为 (classes*2000);但最小为4000。例如如果训练3个目标类别,max_batches=6000
Cfg.steps = [4000, 6000] # 把steps改为max_batches的80% and 90%;例如steps=4800, 5400。
Cfg.policy = Cfg.steps
Cfg.scales = .1, .1
Cfg.classes = 2
Cfg.track = 0
Cfg.w = Cfg.width
Cfg.h = Cfg.height
Cfg.cosine_lr = False
Cfg.smoooth_label = True # 标注的数据,没有时间很好去清洗,建议还是用True
Cfg.TRAIN_OPTIMIZER = 'adam'
config_mycode.py的关键内容已在代码块里面做了注释,这里就不细说了。
最后直接执行程序:train_dark_mycode.py,就可以得到自己的模型权重了,我这里训练了80epoch:
Epoch_080_Loss_9.0762_nomask_mask.pth,loss为9.0762还是挺大的,测试结果还行。
训练结果测试
测试代码用的是:inference_dark_mycode.py
# -------------------------------------#
# 创建YOLO类
# -------------------------------------#
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
import cv2
import numpy as np
import colorsys
import os
import torch
import torch.nn as nn
from darknet.darknet import Darknet
from utils.utils import non_max_suppression
from utils.utils import load_class_names
from utils.utils import plot_boxes_cv2
from yolo_layer_mycode import YoloLayer
'''
面向过程,直接用源码的darknet进行推理
'''
# --------------------------------------------#
# 使用自己训练好的模型预测需要修改3个参数
# cfg_path, model_path和classes_path都需要修改!
# --------------------------------------------#
class Inference(object):
# ---------------------------------------------------#
# 初始化模型和参数,导入已经训练好的权重
# ---------------------------------------------------#
def __init__(self, **kwargs):
self.yolo_cfg = kwargs['cfg_path']
self.model_path = kwargs['model_path']
self.anchors_path = kwargs['anchors_path']
self.classes_path = kwargs['classes_path']
self.model_image_size = kwargs['model_image_size']
self.confidence = kwargs['confidence']
self.cuda = kwargs['cuda']
self.class_names = self.get_class()
self.anchors = self.get_anchors()
print(self.anchors)
# self.net = YoloBody(3, len(self.class_names)).eval()
self.net = Darknet(self.yolo_cfg) # 用源代码darknet做的模型, 不包括头部
self.net.load_weights(self.model_path) # 加载.weights权重
self.load_model_pth(self.net, self.model_path) # 加载.pth权重
if self.cuda:
self.net = self.net.cuda()
self.net.eval()
print('Finished!')
self.yolo_decodes = []
anchor_masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
for i in range(3):
head = YoloLayer(self.model_image_size, anchor_masks, len(self.class_names),
self.anchors, len(self.anchors) // 2).eval()
self.yolo_decodes.append(head)
print('{} model, anchors, and classes loaded.'.format(self.model_path))
def load_model_pth(self, model, pth):
print('Loading weights into state dict, name: %s' % (pth))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_dict = model.state_dict()
pretrained_dict = torch.load(pth, map_location=device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
for key in pretrained_dict:
print('pretrained items:', key)
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
return model
# ---------------------------------------------------#
# 获得所有的分类
# ---------------------------------------------------#
def get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
# ---------------------------------------------------#
# 获得所有的先验框
# ---------------------------------------------------#
def get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return anchors
# return np.array(anchors).reshape([-1, 3, 2])[::-1, :, :]
# ---------------------------------------------------#
# 检测图片
# ---------------------------------------------------#
def detect_image(self, image_src):
h, w, _ = image_src.shape
image = cv2.resize(image_src, (608, 608))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img = np.array(image, dtype=np.float32)
img = np.transpose(img / 255.0, (2, 0, 1))
images = np.asarray([img])
with torch.no_grad():
images = torch.from_numpy(images)
if self.cuda:
images = images.cuda()
outputs = self.net(images)
output_list = []
for i in range(3):
output_list.append(self.yolo_decodes[i](outputs[i]))
output = torch.cat(output_list, 1)
batch_detections = non_max_suppression(output, len(self.class_names),
conf_thres=self.confidence,
nms_thres=0.3)
boxes = [box.cpu().numpy() for box in batch_detections]
return boxes[0]
if __name__ == '__main__':
params = {
'cfg_path': r'E:\Datas\mask_nomask\yolo4_train_nomask_mask.cfg', # 参数配置文件
"model_path": 'chk_dark/Epoch_080_Loss_9.0762_nomask_mask.pth', # 权重文件可以用训练的.pth文件
"anchors_path": r'E:\Datas\mask_nomask\yolo_anchors_nomask_mask.txt', # 锚框文件
"classes_path": r'E:\Datas\mask_nomask\my_classes_nomask_mask.txt', # 类别文件
"model_image_size": (608, 608, 3),
"confidence": 0.3, # 原本0.4
"cuda": True
}
model = Inference(**params)
class_names = load_class_names(params['classes_path'])
image_src = cv2.imread(r'E:\Datas\mask_nomask\testImages\1.jpg')
boxes = model.detect_image(image_src)
plot_boxes_cv2(image_src, boxes, savename='output1.jpg', class_names=class_names)
main函数里面的参数改成自己情况就行了。

最后看下结果:

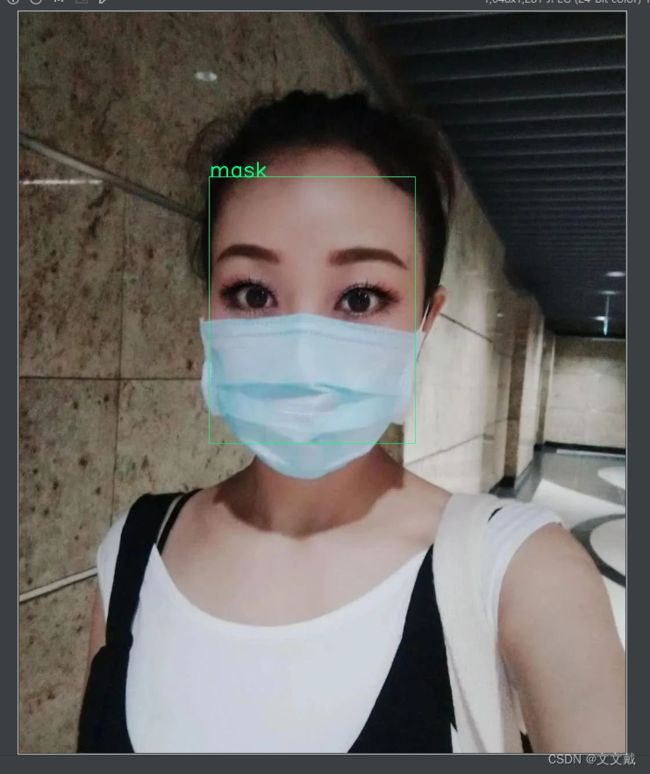
以上为全部训练过程。