VGG网络结构的搭建(pytorch以及百度飞桨)
对应百度飞桨页面
VGG网络是在2014年由牛津大学著名研究组VGG (Visual Geometry Group) 提出。
下载花分类数据集
import requests
import os
import time
import sysclass DownloadZip():
def __init__(self, url):
self.url = url
def download(self):
# 记录文件下载开始时间
start = time.time()
# 获取当前执行文件所在的工作目录
cwd = os.getcwd()
# 文件存放位置
data_root = os.path.join(cwd, 'work')
print(data_root)
if not os.path.exists(data_root):
os.mkdir(data_root)
data_root = os.path.join(data_root, 'flower_data')
if not os.path.exists(data_root):
os.mkdir(data_root)
# 获取文件名
file_name = self.url.split('/')[-1]
temp_size = 0
res = requests.get(self.url, stream=True)
# 每次下载数据大小
chunk_size = 1024
total_size = int(res.headers.get("Content-Length"))
if res.status_code == 200:
# 换算单位并打印
print('[文件大小]:%0.2f MB' % (total_size / chunk_size / 1024))
# 保存下载文件
with open(os.path.join(data_root, file_name), 'wb') as f:
for chunk in res.iter_content(chunk_size=chunk_size):
if chunk:
temp_size += len(chunk)
f.write(chunk)
f.flush()
# 花哨的下载进度部分
done = int(50 * temp_size / total_size)
# 调用标准输出刷新命令行,看到\r 回车符了吧
# 相当于把每一行重新刷新一遍
sys.stdout.write(
"\r[%s%s] %d%%" % ('█' * done, ' ' * (50 - done), 100 * temp_size / total_size))
sys.stdout.flush()
# 避免上面\r 回车符,执行完后需要换行了,不然都在一行显示
print()
# 结束时间
end = time.time()
print('全部下载完成!用时%.2f 秒' % (end - start))
else:
print(res.status_code)if not os.path.exists(os.path.join(os.getcwd(), 'work', 'flower_data', 'flower_photos.tgz')):
zip_url = 'http://download.tensorflow.org/example_images/flower_photos.tgz'
segmentfault = DownloadZip(zip_url)
segmentfault.download()import tarfile
def un_tgz(filename):
tar = tarfile.open(filename)
print(os.path.splitext(filename)[0])
tar.extractall(os.path.join(os.path.splitext(filename)[0], '..'))
tar.close()
if not os.path.exists(os.path.join(os.getcwd(), 'work', 'flower_data', 'flower_photos')):
os.mkdir(os.path.join(os.getcwd(), 'work', 'flower_data', 'flower_photos'))
un_tgz(os.path.join(os.getcwd(), 'work', 'flower_data', 'flower_photos.tgz'))数据集划分成训练集train和验证集val
from shutil import copy, rmtree
import random
from tqdm import tqdmdef mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path) # 创建文件夹
def train_val():
# 创建随机种子,目的为了复现试验
random.seed(0)
# 验证集所占数据集的比重
split_rate = 0.1
cwd = os.getcwd() # 获取当前执行文件所在的工作目录
data_root = os.path.join(cwd, 'work', 'flower_data')
origin_flower_path = os.path.join(data_root, 'flower_photos')
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
# 列表推导式(if是为了除去文件夹中的非文件夹)
flowers_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
print(flowers_class)
# 创建训练集文件夹
train_root = os.path.join(data_root, 'train')
mk_file(train_root)
# 创建测试集文件夹
val_root = os.path.join(data_root, 'val')
mk_file(val_root)
for cla in flowers_class:
mk_file(os.path.join(train_root, cla))
mk_file(os.path.join(val_root, cla))
for cla in flowers_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in tqdm(enumerate(images)):
if image in eval_index:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
else:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print('Processing of data_split done!')if not os.path.exists(os.path.join(os.getcwd(), 'work', 'flower_data', 'train')):
train_val()
print('Data ready!')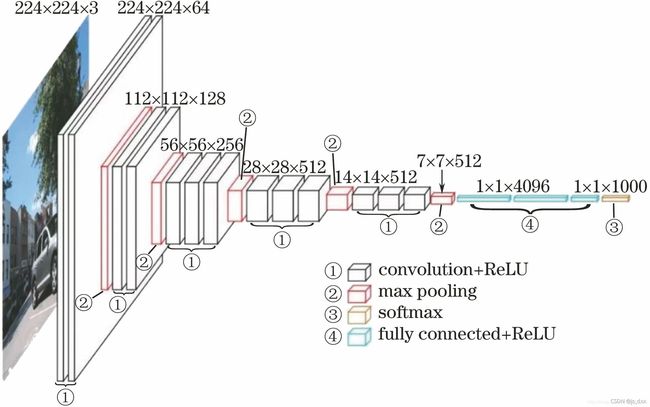
该网络中的亮点: 通过堆叠多个3x3的卷积核来替代大尺度卷积核(在拥有相同感受野的前提下能够减少所需参数)。
论文中提到,可以通过堆叠两层3x3的卷积核替代一层5x5的卷积核,堆叠三层3x3的卷积核替代一层7x7的卷积核。下面给出一个示例:使用7x7卷积核所需参数,与堆叠三个3x3卷积核所需参数(假设输入输出特征矩阵深度channel都为C)
如果使用一层卷积核大小为7的卷积所需参数(第一个C代表输入特征矩阵的channel,第二个C代表卷积核的个数也就是输出特征矩阵的深度):
7∗7∗C∗C=49C27 *7*C*C=49C ^27∗7∗C∗C=49C*C
如果使用三层卷积核大小为3的卷积所需参数:
3∗3∗C∗C+3∗3∗C∗C+3∗3∗C∗C=27C23*3*C*C+3*3*C*C+3*3*C*C=27C*C ^23∗3∗C∗C+3∗3∗C∗C+3∗3∗C∗C=27C*C
经过对比明显使用3层大小为3x3的卷积核比使用一层7x7的卷积核参数更少

Pytorch实现部分代码
model.py
import torch
import torch.nn as nn
# # official pretrain weights
# model_urls = {
# 'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
# 'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
# 'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
# 'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
# }
# 上面这个参数都没有用,数据训练采用的是 1000,我们用的花分类的数据集只有五个类,输出的只有五个类
# predict 还是需要自己先训练一下
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for model in self.modules():
if isinstance(model, nn.Conv2d):
nn.init.xavier_uniform_(model.weight)
if model.bias is not None:
nn.init.constant_(model.bias, 0)
elif isinstance(model, nn.Linear):
nn.init.xavier_uniform_(model.weight)
nn.init.constant_(model.bias, 0)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def make_features(cfg: list):
layer = []
in_channels = 3
for v in cfg:
if v == 'M':
layer += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layer += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layer) # 非关键字参数
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return modeltrain.py
import os
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("using {} device.".format(device))
data_transform = {
'train': transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
),
'val': transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
}
data_root = os.path.abspath(os.path.join(os.getcwd(), '..'))
image_path = os.path.join(data_root, 'AlexNet', 'flower_data')
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 24
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
print(train_dataset[0][0].shape)
print(train_dataset[0])
epochs = 1
best_acc = 0.0
save_path = 'save_pth/{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()predict.py
from model import vgg
def main():
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device = torch.device("cpu")
data_transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
img_path = "./tulip.jpg"
assert os.path.exists(img_path), "file {} does not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
json_path = './class_indices.json'
assert os.path.exists(json_path), "file {} does not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
model = vgg(model_name="vgg16", num_classes=5).to(device)
weights_path = 'save_pth/vgg16Net.pth'
assert os.path.exists(weights_path), "file {} does not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()
with torch.no_grad():
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class : {} prob : {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == "__main__":
main()paddle
import json
import paddle
import paddle.nn as nn
import paddle.vision as torchvision
from paddle.vision import transforms, datasets
import paddle.optimizer as optim
from tqdm import tqdm
import paddle.fluid as fluid
import numpy as npclass VGG(nn.Layer):
def __init__(self, features, num_classes=1000):
super(VGG, self).__init__()
weight_attr = paddle.framework.ParamAttr(initializer=paddle.nn.initializer.XavierNormal())
bias_attr = paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Constant(0))
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096, weight_attr=weight_attr, bias_attr=bias_attr),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096, weight_attr=weight_attr, bias_attr=bias_attr),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes, weight_attr=weight_attr, bias_attr=bias_attr),
)
def forward(self, x):
x = self.features(x)
x = paddle.flatten(x, start_axis=1)
x = self.classifier(x)
return x
def make_features(cfg: list):
layer = []
in_channels = 3
weight_attr = paddle.framework.ParamAttr(initializer=paddle.nn.initializer.XavierNormal())
bias_attr = paddle.framework.ParamAttr(initializer=paddle.nn.initializer.Constant(0))
for v in cfg:
if v == 'M':
layer += [nn.MaxPool2D(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2D(in_channels, v, kernel_size=3, padding=1, weight_attr=weight_attr, bias_attr=bias_attr)
layer += [conv2d, nn.ReLU()]
in_channels = v
return nn.Sequential(*layer) # 非关键字参数
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return modelnet_test = vgg(model_name="vgg16", num_classes=5)
print(net_test)
print("--------------------------------------------------------")
print("named_parameters():")
for name, parameter in net_test.named_parameters():
print(name, type(parameter), parameter.shape,parameter.dtype)
# print(parameter)
# print("--------------------------------------------------------")
# print("sublayers():")
# for m in net_test.sublayers():
# print(m)def train_main():
is_available = len(paddle.static.cuda_places()) > 0
device = 'gpu:0' if is_available else 'cpu'
print("using {} device.".format(device))
data_transform = {
'train': transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
]
),
'val': transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
]
)
}
image_path = os.path.join(os.path.join(os.getcwd(), 'work', 'flower_data'))
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.DatasetFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
# print(flower_list)
cla_dict = dict((val, key) for key, val in flower_list.items())
# print(cla_dict)
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
train_loader = paddle.io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
validate_dataset = datasets.DatasetFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = paddle.io.DataLoader(validate_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(parameters=net.parameters(), learning_rate=0.0001)
epochs = 5 # 训练次数
best_acc = 0.0
save_path = 'save_pth/{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.clear_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
a = loss.numpy()
running_loss += a.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, a.item())
net.eval()
acc = 0.0
with paddle.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
# print(val_labels)
outputs = net(val_images)
# print(outputs)
predict_y = paddle.argmax(outputs, axis=1)
# print(predict_y)
b = paddle.equal(predict_y, val_labels)
b = b.numpy()
b = b.sum()
acc += b
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
paddle.save(net.state_dict(), save_path)
print('Finished Training')# 训练时间过长,不是每次预测都需要重新训练一下
Train_table = True
if Train_table:
use_gpu = True
place = paddle.CUDAPlace(0) if use_gpu else paddle.CPUPlace()
with fluid.dygraph.guard(place):
train_main()
else:
print("train_pth does exist.")from PIL import Image
import matplotlib.pyplot as pltdef predict_main():
dat_transform = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
]
)
img_path = './tulip.jpg'
assert os.path.exists(img_path), "file {} does not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
img = dat_transform(img)
img = paddle.unsqueeze(img, axis=0)
json_path = './class_indices.json'
assert os.path.exists(json_path), "file {} does not exist.".format(json_path)
json_file = open(json_path, 'r')
class_indict = json.load(json_file)
weights_path = "save_pth/vgg16Net.pth"
assert os.path.exists(weights_path),"file {} does not exist.".format(weights_path)
model = vgg(model_name="vgg16", num_classes=5)
model.set_state_dict(paddle.load(weights_path))
model.eval()
with paddle.no_grad():
output = paddle.squeeze(model(img))
# print(output)
predict = paddle.nn.functional.softmax(output)
predict_cla = paddle.argmax(predict).numpy()
print(predict)
# print(int(predict_cla))
# print(class_indict)
# print(class_indict[str(int(predict_cla))])
# print(predict.numpy()[predict_cla].item())
print_res = "class : {} prob : {:.3}".format(class_indict[str(int(predict_cla))],predict.numpy()[predict_cla].item())
plt.title(print_res)
print(print_res)
plt.show()

最后自己选的是个郁金香,说实话自己也看不出来这个像不像玫瑰,但是epochs调大后,VggNet对这幅图更加坚定的认是玫瑰,可能因为它红吧!