基于强化学习的多智能体任务规划(一)

在这篇文章中,相比于传统的AFSIM,作者开发了一种新的人工智能的系统。相比于传统的AI训练器有充分利用先验知识,训练步长更短更快的特点。在此我们不讨论其系统实现的具体细节,我们仅仅讨论其多智能体条件下的强化学习环境搭建问题。这里的问题是二维多智能体博弈对抗问题(MA2D)。
1.实验环境
实验搭建的是红蓝双方2v2环境,如下图所示:

在强化学习训练的每个回合中,初始状态红蓝战机的位置随机,可以出现在图示的任何一个地方(试探性出发假设)。使用传统的强化学习代理训练红方,用混合强化学习代理训练蓝方。文章作者在平台上搭建的实验环境效果图如下:
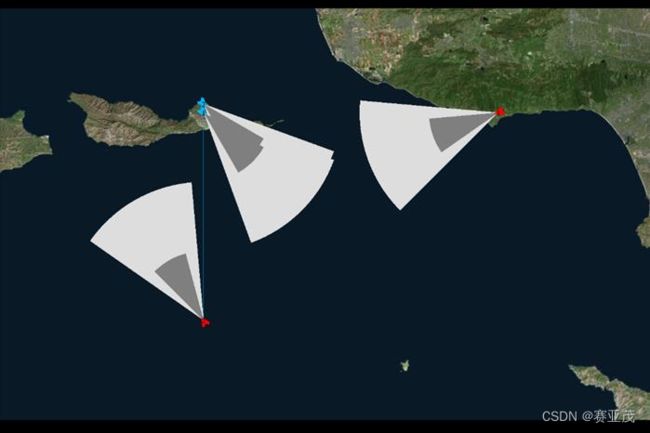
此示例包含两个蓝色战斗机和两个红色战战斗机, 深灰色区域代表每个单位的武器区域。 只要地方战机落在灰色区域一段时间,敌方战机就会被摧毁掉。而事实上,这样的简化可以有效避免对飞行导弹的二次建模过程。
在这里对蓝色战斗机的训练采用强化学习代理进行训练,在这里的红色战机的训练可以采取以下几种方式进行训练:
-
可以直接采用传统的AI脚本进行训练红色战机。
-
可以直接将纯粹的追击蓝色战机作为红色战斗机的行动策略。
-
红色战机单纯直行,为蓝色战机提供截击目标。
2.强化学习环境建模
-
初始位置的随机性:在每个回合epsiode的开始,每个战斗机在地图上的初始位置与初始方向角随机(试探性出发假设),这一点的目的是为了保证战斗机能学到在全局任意一点的最优化策略,而非适用于一个点出发的最优策略。
-
战斗机的参数:包括战斗机每次采取动作的转向角 Δ θ t \Delta \theta_t Δθt,战斗机每次采取动作的加速度 a t a_t at。其范围如下:
Δ θ t ∈ [ − 2. 5 。 , 2. 5 。 ] , a t ∈ [ − 5 , 5 ] m / s 2 \Delta \theta_t \in[-2.5^。,2.5^。],a_t\in[-5,5]\mathbf {m/s^2} Δθt∈[−2.5。,2.5。],at∈[−5,5]m/s2 -
战斗机的灰色火力网为扇形,其扇形视野半径 r = 2 k m r=2km r=2km,扇形角为 α = 3 0 。 \alpha=30^{。} α=30。。
-
杀伤条件:当敌机落入火力网的时间超过 2 s 2s 2s时,敌机即被摧毁。
-
回合截止条件:每个回合最多存在1000个时间步长,若超过这个时间此时存活的蓝色战机将获得奖励。
-
奖励函数:每个战机如果摧毁敌机,其将获得一个大的正奖励;如果其被摧毁,其将获得一个大的负奖励。一般来说,数值上这个大的正奖励是战机互未分胜负时的奖励的10倍。无论蓝色战机与敌机多么接近,只要时间步长超过1000步,回合都会立刻结束,蓝色战机都会返回奖励+1。该奖励函数还有被简化的空间如下:

-
观测空间:蓝色战机的观测值 o t o_t ot是包含地方一系列观测值的状态向量:
o t = ( r e l a t i v e _ d i s t a n c e t b e a r i n g t h e a d i n g t c l o s i n g _ s p e e d t c r o s s _ s p e e d t ) o_t=\begin{pmatrix} \mathbf{relative\_ distance}_t\\\mathbf{bearing}_t\\\mathbf{heading}_t\\\mathbf{closing\_ speed}_t\\ \mathbf{cross\_speed}_t\\ \end{pmatrix} ot=⎝ ⎛relative_distancetbearingtheadingtclosing_speedtcross_speedt⎠ ⎞ -
动作空间:蓝色战机的动作空间是离散的:
a t ∈ { t u r n _ l e f t , t u r n _ r i g h t , s p e e d _ u p , s l o w _ d o w n , h o l d _ c o u r s e } a_t\in\{\mathbf{turn\_ left}, \mathbf{turn\_ right}, \mathbf{speed\_ up}, \mathbf{slow\_ down}, \mathbf{hold \_ course}\} at∈{turn_left,turn_right,speed_up,slow_down,hold_course} -
网络结构:强化学习采用actor-critic的网络架构,其中Actor网络的架构如下:

其中Critic网络的架构如下:
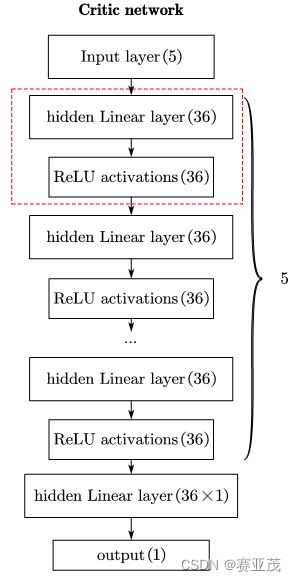
对上述网络初始权重的分配采用基于输入输出的数量的均值作为标准差的正态分布随机数进行分配,而对价值网络仅仅采用TD算法作为更新优势函数的baseline,优势函数采用reinfoce+baseline的方法进行更新以达到减少方差的目的。
- 训练参数:
| Property | Values |
|---|---|
| Optimizer | RMSProp |
| Learning rate | 0.0007(学习率指数下降到 1 × 1 0 − 10 1\times 10^{-10} 1×10−10) |
| Algorithm | A3C( 20 workers) |
| Tricks | adding an entropy term to the objective function |
| Episodes | 200,000 |
|
-
结论:

3.待填坑代码
在这里挖了一个环境代码的坑,等后面填坑:
import numpy as np
class Fighter(object):
def __init__(self,x0=0,y0=0,theta0=np.pi/2,delta_t=1,
L_limits=100,theta_limits=np.pi/180*2.5,
velocity_limits = 2175.0/3600,name="Fighter1",
a_limits=5/1000,fighter_range=2,alpha=np.pi/6,
fighter_aim_time=2,velocity=2175.0/3600/2):
# 单位为km
self.name = name
self.x = x0
self.y = y0
self.theta = theta0
self.delta_t = delta_t
self.L_limits = L_limits
self.theta_limits = theta_limits
self.a_limits = a_limits
self.fighter_range = fighter_range
self.alpha = alpha
self.fighter_aim_time = fighter_aim_time
self.velocity0 = velocity
self.velocity_limits = velocity_limits
self.heading_angle = {'turn_left':-self.theta_limits,
'turn_right':self.theta_limits,
'speed_up':0,
'slow_down':0,
'hold_course':0}
self.acceration_value = {'turn_left':0,
'turn_right':0,
'speed_up':self.a_limits,
'slow_down':-self.a_limits,
'hold_course':0}
self.action_space = ['turn_left','turn_right','speed_up','slow_down','hold_course']
self.action_ndim = 5
self.observation_ndim = 3
self.max_steps_time = 1000*self.delta_t # 超过这段时间游戏自动结束
# 参数初始化
self.dead = False
self.aimed_time = 0 # 战机被锁定的时间
self.total_rewards = 0
self.time = 0 # 从开始到结束的时间
self.acceration = 0
self.velocity = velocity
self.state = np.array([self.x,self.y,self.theta])
self.normal_reward = -1
self.burn_reward = 100*self.normal_reward
self.win_reward = -100*self.normal_reward
self.end_reward = -self.normal_reward
self.count = 0 # 累计击毁数目
self.aiming_time = 0
self.aiming_name = self.name #当前瞄准的敌机姓名
def reset(self,random_Initial_position=True):
if random_Initial_position:
self.x = np.random.random()*self.L_limits
self.y = np.random.random()*self.L_limits
self.theta = -np.pi + np.random.random()*2*np.pi
else:
self.x = 0
self.y = 0
self.theta = np.pi/4
self.dead = False
self.aimed_time = 0 # 战机被锁定的时间
self.total_rewards = 0
self.time = 0 # 从开始到结束的时间
self.acceration = 0
self.velocity = self.velocity0
self.state = np.array([self.x,self.y,self.theta])
self.count = 0 # 累计击毁数目
self.aiming_time = 0 # 固定一个敌机的时间
self.aiming_name = self.name
return self.state
def step(self,action):
if not self.dead:
a_str = self.action_space[action]
delta_a = self.acceration_value[a_str]
delta_theta = self.heading_angle[a_str]
self.acceration += delta_a
if self.acceration <= -self.a_limits:
self.acceration = -self.a_limits
elif self.acceration >= self.a_limits:
self.acceration = self.a_limits
self.theta += delta_theta
if self.theta >= np.pi: # 下面始终将角度限制在[-pi,pi]
self.theta = self.theta - 2*np.pi
elif self.theta <= -np.pi:
self.theta = self.theta + 2*np.pi
# 更新状态
self.x += self.velocity*self.delta_t*np.cos(self.theta) + 0.5*np.cos(self.theta)*self.acceration*(self.delta_t)**2
self.y += self.velocity*self.delta_t*np.sin(self.theta) + 0.5*np.sin(self.theta)*self.acceration*(self.delta_t)**2
self.velocity += self.acceration*self.delta_t
if self.x >= self.L_limits:
self.x = self.L_limits
elif self.x <= 0:
self.x = 0
if self.y >= self.L_limits:
self.y = self.L_limits
elif self.y <= 0:
self.y = 0
if self.velocity <= -self.velocity_limits:
self.velocity = -self.velocity_limits
elif self.velocity >= self.velocity_limits:
self.velocity = self.velocity_limits
self.time += self.delta_t
self.state = np.array([self.x,self.y,self.theta])
# 更新被瞄准时间暂时不考虑
# --------下面的奖励函数需要与外部同时更新--------
if self.aiming_time >= self.fighter_aim_time:
self.count += 1
return self.state,self.win_reward,True # 打赢了,成功击毁一架
# 下面只会考虑三种回合结束的情况,被击毁,游戏结束
if self.time >= self.max_steps_time:
return self.state,self.end_reward,True
if self.aimed_time >= self.fighter_aim_time:
self.dead = True
return self.state, self.burn_reward, True
return self.state,self.normal_reward,False # 回合正常结束
else:
print("{}已经阵亡!".format(self.name))
class CombatEnv(object):
def __init__(self,red_num=2,blue_num=2,delta_t=1,L_limits=100,
radius=2,alpha=np.pi/6,fighter_aim_time=2):
self.red_num = red_num
self.blue_num = blue_num
self.radius = radius
self.alpha = alpha
self.delta_t = delta_t
self.L_limits = L_limits
self.fighter_aim_time = fighter_aim_time
self.red_fighter_list = []
self.blue_fighter_list = []
self.blue_state = []
self.red_state = []
self.red_name_space = {}
self.blue_name_space = {}
self.observation_space_ndim = int(self.blue_num * 3)
self.action_space_ndim = int(self.blue_num * 2)
# 产生不同数量的红方与蓝方战机群
for fighter_blue_index in range(self.blue_num):
bluefighter = Fighter(name="BlueFighter{}".format(fighter_blue_index),
fighter_range=self.radius,
delta_t=self.delta_t,
L_limits=self.L_limits,
fighter_aim_time=self.fighter_aim_time)
self.blue_fighter_list.append(bluefighter)
self.blue_state.append(bluefighter.state)
self.blue_name_space["BlueFighter{}".format(fighter_blue_index)] = fighter_blue_index
for fighter_red_index in range(self.red_num):
redfighter = Fighter(name="RedFighter{}".format(fighter_red_index),
fighter_range=self.radius,
delta_t=self.delta_t,
L_limits=self.L_limits,
fighter_aim_time=self.fighter_aim_time)
self.red_fighter_list.append(redfighter)
self.red_state.append(redfighter.state)
self.red_name_space["RedFighter{}".format(fighter_red_index)] = fighter_red_index
# 下面开始更新参数
self.aimed_matrix = np.zeros((self.red_num,self.blue_num)) # 记录第i个战机被第j个战机瞄准的时间aij
self.aiming_matrix = np.zeros((self.red_num,self.blue_num)) # 记录第i个战机瞄准第j个战机的时间bij
# 下面是重置阶段
def reset(self):
# 各种参数初始化
self.blue_state = []
self.red_state = []
self.aimed_matrix = np.zeros((self.red_num, self.blue_num)) # 记录第i个战机被第j个战机瞄准的时间aij
self.aiming_matrix = np.zeros((self.red_num, self.blue_num)) # 记录第i个战机瞄准第j个战机的时间bij
for fighter_blue_index in range(self.blue_num):
state = self.blue_fighter_list[fighter_blue_index].reset()
self.blue_state.append(state)
for fighter_red_index in range(self.red_num):
state = self.red_fighter_list[fighter_red_index].reset()
self.red_state.append(state)
return self.blue_state,self.red_state
# 下面是动作函数
def step(self,action):
# 输入action是一个列表,其中列表有self.blue_num个数
# 先更新射击矩阵
for fighter_blue_index in range(self.blue_num):
for fighter_red_index in range(self.red_num):
fighter_blue = self.blue_fighter_list[fighter_blue_index]
fighter_red = self.red_fighter_list[fighter_red_index]
blue_flag, red_flag = self.inArea(fighter_blue,fighter_red)
# 一旦红方落入蓝方战机区域,红方战机历经的时间就将被计时
if not blue_flag:
self.aiming_matrix[fighter_red_index,fighter_blue_index] = 0
else:
self.aiming_matrix[fighter_red_index,fighter_blue_index] += self.delta_t
# 一旦蓝方落入红方战机区域,蓝方战机历经的时间就将被记录时
if not red_flag:
self.aimed_matrix[fighter_red_index,fighter_blue_index] = 0
else:
self.aimed_matrix[fighter_red_index,fighter_blue_index] += self.delta_t
r_sum = 0
# 下面从蓝方的角度考虑
for fighter_blue_index in range(self.blue_num):
max_aimed_index = np.argmax(self.aimed_matrix[:,fighter_blue_index])
max_aiming_index = np.argmax(self.aiming_matrix[:,fighter_blue_index])
max_aimed_time = np.max(self.aimed_matrix[:,fighter_blue_index])
max_aiming_time = np.max(self.aiming_matrix[:,fighter_blue_index])
self.blue_fighter_list[fighter_blue_index].aimed_time = max_aimed_time
self.blue_fighter_list[fighter_blue_index].aiming_time = max_aiming_time
self.blue_fighter_list[fighter_blue_index].aiming_name = self.red_fighter_list[max_aiming_index].name
# 下面从红方的角度考虑
for fighter_red_index in range(self.red_num):
max_aimed_index = np.argmax(self.aiming_matrix[fighter_red_index,:])
max_aimed_time = np.max(self.aiming_matrix[fighter_red_index,:])
##-------------下面先不急着写了,吃完饭再写,主要是更新红方状态,看来还是需要点多智能体强化学习的基础!!!!-------------
for fighter_blue_index in range(self.blue_num):
s,r,done = self.blue_fighter_list[fighter_blue_index].step(action[fighter_blue_index])
r_sum += r
def inArea(self,blue_fighter,red_fighter):
distance = np.sqrt((blue_fighter.x - red_fighter.x)**2 + (blue_fighter.y - red_fighter.y)**2) # 两个战机的距离
# 下面是对蓝色战机的
theta_blue = np.arctan2(red_fighter.y - blue_fighter.y,red_fighter.x - blue_fighter.x) # 以blue的视角看
theta_max = blue_fighter.theta + self.alpha/2
theta_min = blue_fighter.theta - self.alpha/2
blue_flag = False
# 对于一种最特殊的情况
if theta_min <= -np.pi and theta_max >= -np.pi:
theta_min = theta_min +2*np.pi
if (distance<=blue_fighter.fighter_range) and \
((theta_min <=theta_blue <= np.pi)or(-np.pi<=theta_blue <=theta_max)):
blue_flag = True
else:
blue_flag = False
else:
if (distance <=blue_fighter.fighter_range) and (theta_min <= theta_blue <=theta_max):
blue_flag = True
else:
blue_flag = False
# 下面是对红色战机的
theta_red = np.arctan2(blue_fighter.y - red_fighter.y, blue_fighter.x - red_fighter.x) # 以red的视角看
theta_max = red_fighter.theta + self.alpha / 2
theta_min = red_fighter.theta - self.alpha / 2
red_flag = False
if theta_min <= -np.pi and theta_max >= -np.pi:
theta_min = theta_min +2*np.pi
if (distance<=red_fighter.fighter_range) and \
((theta_min <=theta_red <= np.pi)or(-np.pi<=theta_red <=theta_max)):
red_flag = True
else:
red_flag = False
else:
if (distance <=red_fighter.fighter_range) and (theta_min <= theta_red <=theta_max):
red_flag = True
else:
red_flag = False
return blue_flag,red_flag