TensorRT(二)TensorRT使用教程(Python版)
原文地址:
https://www.zhoujianguo.ltd/#/fore/article?id=135 https://www.zhoujianguo.ltd/#/fore/article?id=135
https://www.zhoujianguo.ltd/#/fore/article?id=135
一、前言
1.1 本文目标
本文主要是宏观地阐述一下如何使用TensorRT来部署深度学习模型以实现对模型的加速,从而提高深度学习模型运行的效率,根据我自己的实测,确实可以达到官方所说的六倍以上的速度(如下图所示)。

但是本文适合快速入门了解TensorRT使用的宏观流程,具体细节还是建议参考TensorRT的官方文档。
目前,TenorRT已经支持了主流的深度学习框架,并且截至本文发布前,TensorRT已经更新到了8.2的版本,说明TensorRT还是比较成功的
(说实话,英伟达在AI领域的布局已经基本完成了,从硬件到软件的生态几乎已经彻底完善了,按照当前的趋势,盲猜英伟达将会在不远的未来抛弃CPU和运行内存,因为数据从内存拷贝到显存貌似这部分时间开销挺大的)
其实“Tensort支持了主流深度学习框架”这句话的意思是指:TensorRT可以直接从这些深度学习框架中获取深度学习模型的定义和权重。
这句话很好理解,因为不同的深度学习框架自然有自己的模型定义方式,因此TensoRT想要获取深度学习模型的神经网络结构和相关参数权重,那必然是需要先能够“读懂”框架的“语言”。
1.2 TensorRT是什么
TensorRT是英伟达官方针对自己的硬件设备面向AI工作者推出的一种部署方案。TensorRT可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。TensorRT通过combines layers,kernel优化选择,以及根据指定的精度执行归一化和转换成最优的matrix math方法,改善网络的延迟、吞吐量以及效率。
1.3 TensorRT加速原理
加速原理比较复杂,它将会根据显卡来优化算子,以起到加速作用(如下图所示)。简单的来说,就是类似于你出一个公式1+1+1,而你的显卡支持乘法,直接给你把这个公式优化成了1*3,一步算完,所以自然更快。

当然这个加速程度很大程度上取决于你的显卡算力还有模型结构复杂程度,也有可能因为没有优化的地方,从而没有多大的提升,至少我用的是GTX1660S显卡可以把HRNet的运行速度提升6倍以上
1.4 TensorRT安装
安装教程我已经在上一篇文章中给出,有需要的话,可以自行前往查看,点击此处进行跳转
1.5 TensorRT使用流程
TensorRT使用流程如下图所示,分为两个阶段:预处理阶段和推理阶段。其部署大致流程如下:1.导出网络定义以及相关权重;2.解析网络定义以及相关权重;3.根据显卡算子构造出最优执行计划;4.将执行计划序列化存储;5.反序列化执行计划;6.进行推理
可以从步骤3可以得知,tensorrt实际上是和你的硬件绑定的,所以在部署过程中,如果你的硬件(显卡)和软件(驱动、cudatoolkit、cudnn)发生了改变,那么这一步开始就要重新走一遍了。

二、导出onnx模型
2.1 简述
这一步主要是为了将深度学习模型的结构和参数导出来。考虑到实际部署环境的精简性,我这里还是建议大家在使用中先将深度学习模型导出ONNX文件,然后拿着ONNX文件去部署就可以了。
原因很简单,因为ONNX不像Pytorch和TensorFlow那样,还需要安装这些框架运行的依赖包(比如 conda install pytorch,不然你没办法用pytorch的代码),TensorRT可以直接从ONNX文件中读取出网络定义和权重信息。
除此以外,ONNX更像是“通用语言”,ONNX的出现本身就是为了描述网络结构和相关权重,除此以外,还有专门的工具可以对ONNX文件进行解析,查看相关结构,例如网站:https://lutzroeder.github.io/netron/
可以直接将onnx文件拖进去,查看网络结构
2.2 导出ONNX文件(Pytorch为例)
# 构造模型实例
model = HRNet()
# 反序列化权重参数
model.load_state_dict(torch.load(self.weight_path),strict=False)
model.eval()
# 定义输入名称,list结构,可能有多个输入
input_names = ['input']
# 定义输出名称,list结构,可能有多个输出
output_names = ['output']
# 构造输入用以验证onnx模型的正确性
input = torch.rand(1, 3, self.resolution[0], self.resolution[1])
# 导出
torch.onnx.export(model, input, output_path,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=input_names,
output_names=output_names)参数介绍:
- model为pytorch模型实例
- input为测试输入数据(形状必须要和模型输入一致,但是数值可以是随机的)
- output_path为导出路径,xxx.onnx
- export_params为是否导出参数权重,必然是True
- opset_version=11 发行版本,11就可以了
- do_constant_folding是否对常量进行折叠,True就可以了
- input_names是模型输入的名称,list类型,因为模型可能有多个输入
- output_names同上,只不过这是针对输出的
三、TensorRT预推理阶段
3.1 简述
在这一步骤的主要目的是,根据onnx所描述的模型结构和权重数值和当前的软硬件环境生成对应的执行计划,并且序列化为xxx.engine文件持久化保存,这一步时间比较长,所以需要序列化执行文件,这样在推理阶段直接加载此文件构造出Engine
以实现快速推理,这一步可以使用tens
ortrt安装包内自带的trtexec.exe实现,也可以用python代码自行实现。
3.2 trtexec.exe实现预推理(推荐)
使用trtexec.exe实现预推理需要系统安装好cudatoolkit和cudnn,否则无法正常运行
打开tensorrt安装包的子目录bin,如下图所示

搜索运行cmd,并且cd到此目录下,并且将需要部署的onnx文件复制到此目录下
输入以下指令:
trtexec --onnx=xxx.onnx --saveEngine=xxx.engine --fp16参数解释
--fp16开启 float16精度的推理(推荐此模式,一方面能够加速,另一方面精度下降比较小)
--int8 开启 int8精度的推理(不太推荐,虽然更快,但是精度下降太厉害了)
--onnx onnx路径
--saveEngine执行计划(推理引擎)序列化地址
3.3 python代码实现预推理
和3.2一样,也需要cudatoolkit和cudnn
# 导入必用依赖
import tensorrt as trt
# 创建logger:日志记录器
logger = trt.Logger(trt.Logger.WARNING)
# 创建构建器builder
builder = trt.Builder(logger)
# 预创建网络
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
# 加载onnx解析器
parser = trt.OnnxParser(network, logger)
success = parser.parse_from_file(onnx_path)
for idx in range(parser.num_errors):
print(parser.get_error(idx))
if not success:
pass # Error handling code here
# builder配置
config = builder.create_builder_config()
# 分配显存作为工作区间,一般建议为显存一半的大小
config.max_workspace_size = 1 << 30 # 1 Mi
serialized_engine = builder.build_serialized_network(network, config)
# 序列化生成engine文件
with open(engine_path, "wb") as f:
f.write(serialized_engine)
print("generate file success!")四、TensorRT部署阶段
4.1 简述
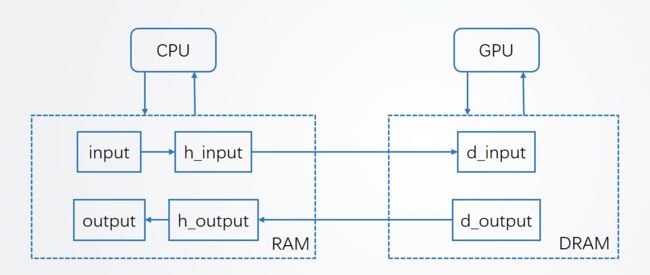
在本阶段,需要使用代码实现加载执行计划文件(xxx.engine),为了更方便的理解工作逻辑,数据的逻辑关系已在下图中给出。
其中input/output为你的输入数据,h_input/h_output为锁页内存(非锁页内存也是可以的,但是建议用锁页内存防止被系统页面置换到外存中),d_input/d_output为显存
同时,在TensorRT官方文档中,CPU+内存被称为host,而GPU+显存被称为device,可以明显地看出host和device实际上是异步工作的,因此需要同步操作。
4.2 代码实现
以下代码主要是用于描述TensorRT的使用逻辑,而对于模型的输入和模型的输出数据的处理需要视具体模型而定,因此这里不过多赘述这两部分数据的处理。
#导入必用依赖
import tensorrt as trt
import pycuda.autoinit #负责数据初始化,内存管理,销毁等
import pycuda.driver as cuda #GPU CPU之间的数据传输
#创建logger:日志记录器
logger = trt.Logger(trt.Logger.WARNING)
#创建runtime并反序列化生成engine
with open(“sample.engine”, “rb”) as f, trt.Runtime(logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
#分配CPU锁页内存和GPU显存
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
#创建cuda流
stream = cuda.Stream()
#创建context并进行推理
with engine.create_execution_context() as context:
# Transfer input data to the GPU.
cuda.memcpy_htod_async(d_input, h_input, stream)
# Run inference.
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# Synchronize the stream
stream.synchronize()
# Return the host output. 该数据等同于原始模型的输出数据
return h_output五、小结
本文主要讲述了一下tensorrt end2end的使用教程,但这是最基本的教程,还有其他高级用法,本文还没有给出,例如支持batch的动态参数等用法。