深度学习实战案例:新闻文本分类
深度学习多分类案例:新闻文本分类
公众号:机器学习杂货店
作者:Peter
编辑:Peter
大家好,我是Peter~
这里是机器学习杂货店 Machine Learning Grocery~
之前介绍过一个单分类的问题。当每个数据点可以划分到多个类别、多个标签下,这就是属于多分类问题了。
本文介绍一个基于深度学习的多分类实战案例:新闻文本分类,最终是有46个不同的类别

数据集
路透社数据集
广泛使用的文本分类数据集:46个不同的主题,即输出有46个类别。某些样本的主题更多,但是训练集中的每个主题至少有10个样本
加载数据集
也是内置的数据集

In [1]:
from keras.datasets import reuters
In [2]:
# 限制前10000个最常见的单词
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
In [3]:
# 查看数据
len(train_data)
Out[3]:
8982
In [4]:
len(test_data)
Out[4]:
2246
In [5]:
train_data.shape
Out[5]:
(8982,)
In [6]:
type(train_data)
Out[6]:
numpy.ndarray
索引解码为单词
In [7]:
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
In [8]:
decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
decoded_newswire
Out[8]:
'? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3'
索引减去3是因为:012分别是为“padding填充”,“start of sequence(序列开始)”,"unknown(未知)"分别保留的索引
样本标签对应的是0-45范围内的整数:
In [9]:
train_labels[10]
Out[9]:
3
数据向量化
In [10]:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension)) # 创建全0矩阵
for i, sequence in enumerate(sequences):
results[i, sequence] = 1. # 指定位置填充1
return results
# 训练数据和测试数据向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
标签向量化-onehot
主要是有两种方法:
- 将标签列表转成整数张量
- one-hot编码,分类编码的一种
In [11]:
import numpy as np
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension)) # 创建全0矩阵
for i, label in enumerate(labels):
results[i, label] = 1. # 指定位置填充1
return results
# 训练标签和测试标签向量化
one_hot_train_label = to_one_hot(train_labels)
one_hot_test_label = to_one_hot(test_labels)
In [12]:
np.zeros((4,5))
Out[12]:
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
Keras内置方法实现one-hot
In [13]:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
建模
模型定义(修改)
In [14]:
import tensorflow as tf # add
from keras import models
from keras import layers
model = models.Sequential()
# 原文model.add(layers.Dense(16, activation="relu", input_shape=(10000, )))
# 统一修改3处内容:layers.Dense 变成 tf.keras.layers.Dense
model.add(tf.keras.layers.Dense(64,
activation="relu",
input_shape=(10000,)
))
model.add(tf.keras.layers.Dense(64,
activation="relu"
))
model.add(tf.keras.layers.Dense(46,
activation="softmax"
))
注意两点:
- 网络的最后一层是大小为46的Dense层。意味着,对于每个输入样本,网络都会输出一个46维的向量,这个向量的每个元素代表不同的输出类型
- 最后一个使用的是softmax激活:网络将输出在46个不同类别上的概率分布,output[i]是样本属于第i个类别的概率,46个概率的总和是1
模型编译
多分类问题最好使用categorical_crossentropy作为损失函数。它用于衡量两个概率分布之间的距离:网络输出的概率分布和标签的真实概率分布
目标:这两个概率分布的距离最小化
In [15]:
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
验证模型-提取验证集
In [16]:
# 取出1000个样本作为验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
训练网络
开始20个轮次epochs训练网络
In [17]:
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data =(x_val, y_val)
)


绘图
损失
In [20]:
# 损失绘图
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1,len(loss_values) + 1)
# 训练
plt.plot(epochs, # 横坐标
loss_values, # 纵坐标
"r", # 颜色和形状,默认是实线
label="Training_Loss" # 标签名
)
# 验证
plt.plot(epochs,
val_loss_values,
"b",
label="Validation_Loss"
)
plt.title("Training and Validation Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()

精度(修改)
多分类问题中得到的是acc的全拼,而不是缩写
In [19]:
# 精度绘图
import matplotlib.pyplot as plt
history_dict = history.history
acc_values = history_dict["accuracy"] # 修改:原文是acc ---> accuracy
val_acc_values = history_dict["val_accuracy"] # val_acc ---> val_accuracy
epochs = range(1,len(loss_values) + 1)
plt.plot(epochs,
acc_values,
"r",
label="Training_ACC"
)
plt.plot(epochs,
val_acc_values,
"b",
label="Validation_ACC"
)
plt.title("Training and Validation ACC")
plt.xlabel("Epochs")
plt.ylabel("acc")
plt.legend()
plt.show()
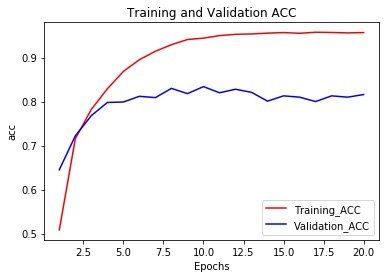
重新训练
网路在训练9轮后开始过拟合,重新训练一个新网络:共9个轮次
In [25]:
import tensorflow as tf # add
from keras import models
from keras import layers
model = models.Sequential()
model.add(tf.keras.layers.Dense(64,
activation="relu",
input_shape=(10000, )
))
model.add(tf.keras.layers.Dense(64,
activation="relu"))
model.add(tf.keras.layers.Dense(46,
activation="softmax"
))
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"]
)
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
results

这个模型的精度到达了78.6%。如果是随机的基准是多少呢?
In [26]:
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
In [28]:
hist_array = np.array(test_labels) == np.array(test_labels_copy)
In [29]:
hist_array # T或者F的元素
Out[29]:
array([False, False, False, ..., False, True, False])
In [30]:
float(np.sum(hist_array)) / len(test_labels)
Out[30]:
0.18744434550311664
测试集验证
使用的是predict函数
In [31]:
predictions = model.predict(x_test)
predictions
Out[31]:
array([[1.35964816e-04, 5.63261092e-05, 1.82070780e-05, ...,
1.30567923e-06, 1.98109021e-07, 6.60357784e-07],
[4.93899640e-03, 4.66015842e-03, 1.14109996e-03, ...,
1.06564505e-04, 3.91121466e-05, 9.38424782e-04],
[1.59738748e-03, 7.79436469e-01, 1.73478038e-03, ...,
1.25069331e-04, 1.86533769e-04, 1.70501284e-04],
...,
[6.38374695e-05, 1.36295348e-04, 4.94179221e-05, ...,
2.28828794e-05, 2.12488590e-06, 5.73998386e-06],
[3.28431278e-03, 6.02599606e-02, 3.11069656e-03, ...,
6.78190409e-05, 8.90388037e-05, 2.43265240e-04],
[1.19820972e-04, 6.49809241e-01, 1.08765960e-02, ...,
7.17515213e-05, 3.85396503e-04, 3.51801835e-04]], dtype=float32)
1、predictions中每个元素都是46维的向量:
In [32]:
# 每个元素都是46维的向量
predictions[0].shape
Out[32]:
(46,)
In [33]:
predictions[1].shape
Out[33]:
(46,)
In [34]:
predictions[50].shape
Out[34]:
(46,)
2、所有元素的和为1:
In [35]:
# 所有元素的和为1
sum(predictions[0])
Out[35]:
1.0000001240543241
3、最大元素就是预测的类别,也就是概率最大的类别:
In [36]:
np.argmax(predictions[0])
Out[36]:
3
In [37]:
np.argmax(predictions[4])
Out[37]:
13
换种方式处理标签和损失
In [38]:
# 方式1:转换为整数张量
y_train = np.array(train_labels)
y_test = np.array(test_labels)
使用的损失函数categorical_crossentropy,标签遵循分类编码。
如果是整数标签,使用sparse_categorical_crossentropy:
In [39]:
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy", # 损失函数
metrics=["accuracy"]
)
中间层维度足够大的重要性
最终输出是46维的,因此中间层的隐藏单个数不应该比46小太多。如果小太多,将会造成信息的丢失:
In [40]:
import tensorflow as tf
from keras import models
from keras import layers
model = models.Sequential()
model.add(tf.keras.layers.Dense(64,
activation="relu",
input_shape=(10000, )
))
model.add(tf.keras.layers.Dense(4, # 中间层从64---->4
activation="relu"))
model.add(tf.keras.layers.Dense(46,
activation="softmax"
))
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"]
)
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))


我们发现最终上升到了69.2%
进一步实验
- 尝试使用更多或者更少的隐藏单元,比如32或者128等
- 改变隐藏层个数,目前是2个;可以改成1个或者3个
小结
- 如果是对N个类别进行分类,最后一层应该是大小为N的Dense层
- 单标签多分类问题,网络的最后一层使用softmax激活,输出在N个输出类别上的概率分布
- 损失函数几乎都是分类交叉熵categorical_crossentropy。它将网络输出的概率分布和目标真实分布之间的距离最小化
- 避免使用太小的中间层,以免在网络中造成信息瓶颈。
- 处理多分类的标签方法:
- 分类编码:one-hot编码,然后使用categorical_crossentropy
- 将标签编码为整数,然后使用sparse_categorical_crossentropy