谣言检测文献阅读一A Review on Rumour Prediction and Veracity Assessment in Online Social Network
系列文章目录
- 谣言检测文献阅读一—A Review on Rumour Prediction and Veracity Assessment in Online Social Network
- 谣言检测文献阅读二—Earlier detection of rumors in online social networks using certainty‑factor‑based convolutional neural networks
- 谣言检测文献阅读三—The Future of False Information Detection on Social Media:New Perspectives and Trends
- 谣言检测文献阅读四—Reply-Aided Detection of Misinformation via Bayesian Deep Learning
- 谣言检测文献阅读五—Leveraging the Implicit Structure within Social Media for Emergent Rumor Detection
- 谣言检测文献阅读六—Tracing Fake-News Footprints: Characterizing Social Media Messages by How They Propagate
- 谣言检测文献阅读七—EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
- 谣言检测文献阅读八—Detecting breaking news rumors of emerging topics in social media
- 谣言检测文献阅读九—人工智能视角下的在线社交网络虚假信息 检测、传播与控制研究综述
- 文献阅读十——Detect Rumors on Twitter by Promoting Information Campaigns with Generative Adversarial Learn
文章目录
- 系列文章目录
- 前言
- 一、介绍
-
- 1.1 谣言的定义
- 1.2 谣言检测的重要性
- 1.3 A General model of Rumor Detection and Veracity Assessment (谣言检测和真实性评估的一般模型)
- 二、从前的工作
- 三、数据收集
-
- 3.1Access to Social Media Data 获取媒体数据的方法
- 3.2 State-of-the-Art Data Collection Approaches 最先进的数据收集方法
- 四、 Features Used for Rumor Analysis 用于谣言分析的特征
- 五、Rumor Analysis Approaches for Multimedia Data (用于多媒体数据的谣言检测方法)
-
- 5.1 谣言检测、谣言真实性评估
- 5.2 基于图像的谣言检测
- 六、Services and tools used for rumor analysis: application perspective
- 七、研究的制约因素
-
- 7.1 Analysis phase: data-collection
- 7.2 Analysis phase: feature engineering
- 八、Conclusion and future directions
-
- 8.1谣言检测
- 8.2 信用评估和真实性评估
前言
综述:A Review on Rumour Prediction and Veracity Assessment in Online Social Network
一、介绍
1.1 谣言的定义
文章中给出了很多谣言的定义,
- The authors of (Liang, He, Xu, Chen, & Zeng, 2015) define rumour as the item of
information that is deemed false(将谣言定义为虚假的言论) - many of them defined rumours as the unverified information at the time of posting (Z. Yang, Wang, Zhang, Zhang, & Zhang, 2015(但是更多的人将谣言定义为在发布时未经证实的言论)
下表给出了具体的一些论文的定义

本文使用的谣言定义如下:
谣言——在发布时未经证实的言论
1.2 谣言检测的重要性
- 目前在全球范围内对于谣言的关注度一直很高
( https://trends.google.com/trends/explore?date=today%205-y&q=%2Fm%2F01lp7x,Fake%20news可以实时检测到相关关键词在谷歌上的搜索热度,我们可以通过“谣言”关键词来实时关注谣言的关注度)
- 网络互联的出现导致了高风险,如谣言,病毒给社会带来有害影响。
- 虚假信息在情感上影响公众的情绪。
…
1.3 A General model of Rumor Detection and Veracity Assessment (谣言检测和真实性评估的一般模型)

二、从前的工作
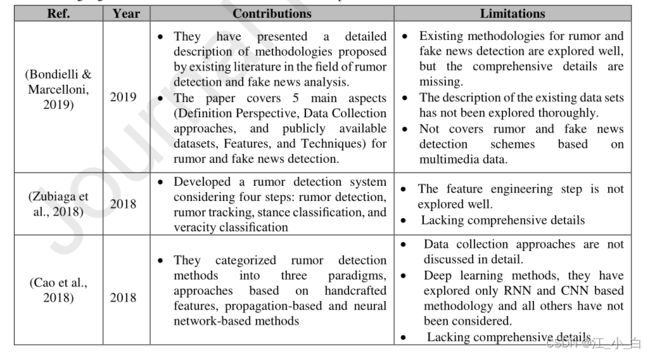 列举了一些之前的review,并标识其优缺点(优点可以参考一下,但是缺点说的比较笼统)
列举了一些之前的review,并标识其优缺点(优点可以参考一下,但是缺点说的比较笼统)
然后列举了自己的一些优势,这里就不在一一详述,但是其中有几点需要注意
- 这项调查的另一个新颖之处是,它包含了来自最新技术的关键发现,这些发现代表了一个主题/帖子可能成为谣言的情况。(Another novelty of this survey is it incorporates crucial findings from the state-of-the-art that represents the possible cases for a topic/post to be a rumor and all the findings are outlined in tabular forms.)不是很懂代表了一个主题/帖子可能成为谣言的情况是什么意思,推测就是包含最新的研究成果,即最新的最好的检测谣言的方法
- 提出了一个主题分类法(检测类型、特征、采用的方法、检测模型)
- 对于多媒体数据的使用(文章强调了之前的review对于多媒体数据的总结较少,这里总结了对多媒体数据的检测方法)
- 确定了公开可用的数据集
三、数据收集
3.1Access to Social Media Data 获取媒体数据的方法
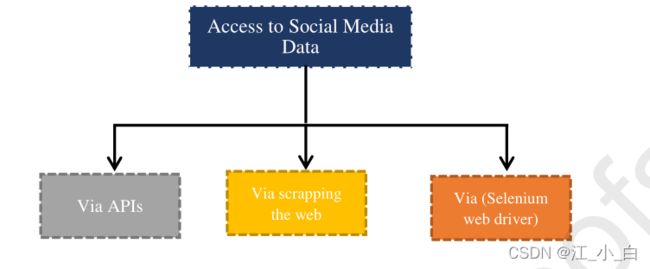
总结了三种主要的数据收集方法,分别是
- 通过API
- https://dev.twitter.com/docs (看介绍应该是有一定的免费额度)
- http://open.weibo.com/wiki/API%E6%96%87%E6%A1%A3/en. (商业接口,需要花钱买数据)
- https://developers.facebook.com/docs(没找到具体的接口在哪)
2.通过报废的网络(python 中的一些库beautiful soap, scrappy,爬虫的框架)
3.通过网络驱动器(Selenium网络驱动器 网络爬虫使用的一种框架)
(抓取应该是原始数据,我们应该是不能使用)
3.2 State-of-the-Art Data Collection Approaches 最先进的数据收集方法
用表格列举了目前最新的优秀论文的数据集的信息

这里只截取了一部分,文章中大概列举了三十篇左右的论文的数据集信息,从这个表中我们可以发现,话题(topic)级的检测多于post级的检测。
并且列举了一些现有的公开数据集,这些数据集大多集中在text领域,而多媒体领域的数据集较少,并且公开数据集也并不多。

下图列举了模型的分类因素(前边提到的主题分类法)——检测模型、检测级别、检测平台、检测事件

四、 Features Used for Rumor Analysis 用于谣言分析的特征
用于谣言分析的特征大体上分为15类(Message-based, User-based, Topic-based,
Propagation-based, Content-based, Network-based, Twitter-based, Linguistic, Temporal, User-
behavioral, Diffusion, Structural, Social, Visual and Statistical Features,基于信息、基于用户、基于主题、基于传播、基于内容、基于网络、基于Twitter、语言、时间、用户行为、扩散、结构、社会、视觉和统计特征)
然后依次列举l了一些论文使用的特征,其中F2是基于内容,F5是基于用户信息,我们可以观察到采用这两个特征的论文较多,并且最新为论文仍在使用这些特征,表明这些特征对于谣言检测任务有效;其次是F8基于语言(Linguistic based),F9基于时间、F10 基于用户行为(这15个特征有些部分是重合的,分的不是很清楚,文中有一个表详细的写出了基于语言都包括什么方面,基于时间是包括什么方面)

五、Rumor Analysis Approaches for Multimedia Data (用于多媒体数据的谣言检测方法)
详细介绍了对于数据集时多媒体数据时的谣言检测方法,主要分为两部分text、image。
 1.Manipulated Images 处理过的图像
1.Manipulated Images 处理过的图像
- copy more 剪切图像的一个或多个部分并粘贴到同一图像的其他部分。
- forgery 伪造 人工合成一些误导性的图片
- splicing 在拼接技术中,剪切图像的某些部分并将其添加到其他图像中
2.Text Additive 文本添加 在图片上填加一些文字或者给图片配上文字,而不去更改原始图像的其他地方
5.1 谣言检测、谣言真实性评估
下表介绍了一些基于文本检测的谣言检测、谣言真实性分析的方法和其具体表现,其中
- Qaz-vinian et al. (2011)使用的特征分别对应着F5(基于内容)F6(基于网络)F7 (基于Twitter),其中的基于网络指的是转发率,根据研究谣言的转发率和非谣言的转发率不同,基于推特指的是谣言推文中使用的标签与其他推文不同,而相信和传播谣言的人使用的标签与否认谣言的人使用的标签不同,文章使用的是传统的机器学习模型,最终在推特平台上达到了95%的平均精确率。
- Xia et al 在紧急情况下使用监督方法(学习贝叶斯网络)预测推文的可信度(这里的紧急情况是通过专家标记紧急级别,然后对于紧急级别较高的进行检测)
- Ma et al 2018 使用树结构递归神经网络在 Twitter 上进行谣言检测,取得了不错的此效果
- Duong et al 2017 结合帖子的出处和文本信息,以提高谣言预测系统的准确性,并且为了解决出处信息缺失的问题,作者提出了基于融合的方法,取得了较好的效果
- Castillo et al. (2011) 采用监督学习(SVM、决策树、决策规则和贝叶斯网络评估信息可信度,所提出的模型达到了 89% 的准确率。
还有很多具体的论文信息都在表格中,表格的信息相对更加清晰明了
 需要注意的是这里有一篇2013年的论文,采用传统的机器学习方法(决策树),使用了图片进行检测,并且达到97%的准确率
需要注意的是这里有一篇2013年的论文,采用传统的机器学习方法(决策树),使用了图片进行检测,并且达到97%的准确率

然后介绍了一些文章的重要发现
这些重要发现和谣言的特征等一些信息相对应,例如发现谣言和转发率有关,正常转发率大概在8.03%,超过这个转发率就有可能是谣言

六、Services and tools used for rumor analysis: application perspective
列举了一些实时评估内容的可信度系统
七、研究的制约因素
7.1 Analysis phase: data-collection
1、平台涵盖面较窄,多数论文使用的是Twitter 其他平台的数据使用较少,而不同的平台有各自的特征,例如人们在微博上发布的帖子倾向于披露更多关于自己的个人信息,并且更积极地回应他人,而在twitter上发布的话题更多地与行业和公司相关
2、数据集不足,缺少公开的大型数据集,多模态数据集尤其如此,统计测试将无法预测数据集中的重要关系,而在更大样本量下进行的研究可能会产生更准确的结果。
7.2 Analysis phase: feature engineering
本研究中考虑的特征基于文本和图像数据。这项研究不包括用于谣言分析的音频和视频方面,可以进一步探讨。
八、Conclusion and future directions
8.1谣言检测
- 对于多媒体数据我们目前没有研究较少,尤其是视频、音频方面的研究。
- 二分类的研究较多,多分类的研究较少
- 数据集较少,数据面较窄
- 为了便于谣言检测,应针对无监督机器学习模型调查未标记的数据,因为数据的标记是劳动密集型的
- 社交媒体(Zannettou等人,2019年)上提供了不同形式的误导性内容,并可在不同的语境下互换使用。在所有不同类别中,有人观察到hoax(恶作剧)是最不受关注的领域,需要进一步关注 (Different prominent forms of misleading content are available on social media (Zannettou et al., 2019) and used interchangeably concerning different contexts. Across all different categories, it has been observed that hoax is the least addressed area, which requires further attention)
- 社交媒体上的可用数据使用不同的语言,因此需要解决多语言内容的谣言检测问题。
8.2 信用评估和真实性评估
- 由于复杂的网络,很难找到研究可信度的有用资源。
- 用户行为、偏好和环境等各种因素持续影响用户的可信度
- 社交网络平台上正在进行大量恶意和垃圾邮件活动,这导致使用一些自动化软件或通过使用第三方服务来提高用户的知名度。
- 识别从Twitter收集的谣言推文的一个挑战是,很难通过输入查询直接检索谣言的内容。
- 由于资源方面的问题,例如缺乏公开可用的数据集,许多研究人员受到限制。
未来发展方向
- 为了检测在线社交网络中的谣言传播者,Castillo等人(2011年)观察到,可以通过将用户属性等信息集成到结构神经模型中来进一步增强工作。
- 未来的工作可以通过探索更关键的因素来扩展(Agichtein等人,2008年),这些因素有助于确定主题是否可信。
- 此前,许多作者利用谣言揭穿网站(关于.com、城市传奇等)有效地检索谣言实例,并且观察到识别新出现的谣言是一项具有挑战性的任务。根据Qazvinian等人(2011年)的研究,可以通过确定给定的趋势话题是否是谣言来进一步加强这项工作。
- 研究发现,除了Twitter,其他社交媒体平台在数据收集方面的探索较少。未来的工作可以通过包括其他社交媒体平台和实验资源来加强。
- 根据Floos(2016),可以通过扩展数据集来增强工作,以获得更精确的结果,并使用不同的配置进行实验。
- Song et al.(2018)中有报道称,对于早期谣言检测,除了微博上的转发信息,还可以包含其他重要信息,如出版商简介和传播结构,这也是未来的发展方向之一。
- 根据Nguyen(2017)的说法,有必要改进基于神经网络的谣言检测方法的质量,利用各种来源,而不仅仅是文本内容。
- 按照Ardizzone等人(2015)的说法,为了恢复一些丢失的匹配,如填充三角形之间的空洞,可以开发一些后处理技术。这也将有助于提高方法的召回率