模型剪枝初级方法
信息源:https://www.bilibili.com/video/BV147411W7am/?spm_id_from=333.788.recommend_more_video.2&vd_source=3969f30b089463e19db0cc5e8fe4583a
1、剪枝的含义
把不重要的参数去掉,计算就更快了,模型的大小就变小了(本文涉及的剪枝方式没有这个功能)。
2、全连接层的剪枝
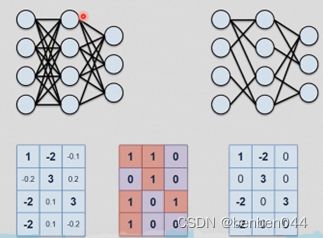
上述剪枝就是把一些weight置为0,这样计算就更快了。
计算掩码矩阵的过程:

接下来要做的:
(1)给每一层增加一个变量,用于存储mask
(2)设计一个函数,用于计算mask
3、卷积层剪枝
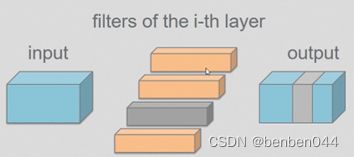
假如有4个卷积核,计算每个卷积核的L2范数,哪个卷积核的范数值最小则对应的mask全部置为0.如上图灰色的部分。
4、代码部分
GitHub - mepeichun/Efficient-Neural-Network-Bilibili: B站Efficient-Neural-Network学习分享的配套代码
5、全连接层剪枝
(1)剪枝思路
假设剪枝的比例为50%。
找到每一个linear的layer,然后取参数的50%分位数,接着构造mask,所有大于50%分位数的mask位置置为1,所有小于等于50%分位数的mask位置置为0。
最后weight * mask得到新的weight。
(2)剪枝代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
import numpy as np
import math
from copy import deepcopy
def to_var(x, requires_grad=False):
if torch.cuda.is_available():
x = x.cuda()
return x.clone().detach().requires_grad_(requires_grad)
class MaskedLinear(nn.Linear):
def __init__(self, in_features, out_features, bias=True):
super(MaskedLinear, self).__init__(in_features, out_features, bias)
self.mask_flag = False
self.mask = None
def set_mask(self, mask):
self.mask = to_var(mask, requires_grad=False)
self.weight.data = self.weight.data * self.mask.data
self.mask_flag = True
def get_mask(self):
print(self.mask_flag)
return self.mask
def forward(self, x):
# 以下代码与set_mask中的self.weight.data = self.weight.data * self.mask.data重复了
# if self.mask_flag:
# weight = self.weight * self.mask
# return F.linear(x, weight, self.bias)
# else:
# return F.linear(x, self.weight, self.bias)
return F.linear(x, self.weight, self.bias)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.linear1 = MaskedLinear(28*28, 200)
self.relu1 = nn.ReLU(inplace=True)
self.linear2 = MaskedLinear(200, 200)
self.relu2 = nn.ReLU(inplace=True)
self.linear3 = MaskedLinear(200, 10)
def forward(self, x):
out = x.view(x.size(0), -1)
out = self.relu1(self.linear1(out))
out = self.relu2(self.linear2(out))
out = self.linear3(out)
return out
def set_masks(self, masks):
self.linear1.set_mask(masks[0])
self.linear2.set_mask(masks[1])
self.linear3.set_mask(masks[2])
def train(model, device, train_loader, optimizer, epoch):
model.train()
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
total += len(data)
progress = math.ceil(batch_idx / len(train_loader) * 50)
print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %
(epoch, total, len(train_loader.dataset),
'-' * progress + '>', progress * 2), end='')
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def weight_prune(model, pruning_perc):
threshold_list = []
for p in model.parameters():
if len(p.data.size()) != 1: # bias
weight = p.cpu().data.abs().numpy().flatten()
threshold = np.percentile(weight, pruning_perc)
threshold_list.append(threshold)
# generate mask
masks = []
idx = 0
for p in model.parameters():
if len(p.data.size()) != 1:
pruned_inds = p.data.abs() > threshold_list[idx]
masks.append(pruned_inds.float())
idx += 1
return masks
def main():
epochs = 2
batch_size = 64
torch.manual_seed(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('D:/ai_data/mnist_dataset', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('D:/ai_data/mnist_dataset', train=False, download=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
model = MLP().to(device)
optimizer = torch.optim.Adadelta(model.parameters())
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
_, acc = test(model, device, test_loader)
print("\n=====Pruning 60%=======\n")
pruned_model = deepcopy(model)
mask = weight_prune(pruned_model, 60)
pruned_model.set_masks(mask)
test(pruned_model, device, test_loader)
return model, pruned_model
model, pruned_model = main()
torch.save(model.state_dict(), ".model.pth")
torch.save(pruned_model.state_dict(), ".pruned_model.pth")
from matplotlib import pyplot as plt
def plot_weights(model):
modules = [module for module in model.modules()]
num_sub_plot = 0
for i, layer in enumerate(modules):
if hasattr(layer, 'weight'):
plt.subplot(131+num_sub_plot)
w = layer.weight.data
w_one_dim = w.cpu().numpy().flatten()
plt.hist(w_one_dim[w_one_dim != 0], bins=50)
num_sub_plot += 1
plt.show()
model = MLP()
pruned_model = MLP()
model.load_state_dict(torch.load('.model.pth'))
pruned_model.load_state_dict(torch.load('.pruned_model.pth'))
plot_weights(model)
plot_weights(pruned_model)(3)剪枝前后精确度信息
Train epoch 1: 60000/60000, [-------------------------------------------------->]
100%
Test: average loss: 0.1391, accuracy: 9562/10000 (96%)
Train epoch 2: 60000/60000, [-------------------------------------------------->]
100%
Test: average loss: 0.0870, accuracy: 9741/10000 (97%)
=====Pruning 60%=======
Test: average loss: 0.0977, accuracy: 9719/10000 (97%)
通过数据,可以发现剪枝前后准确率并未下降太多。
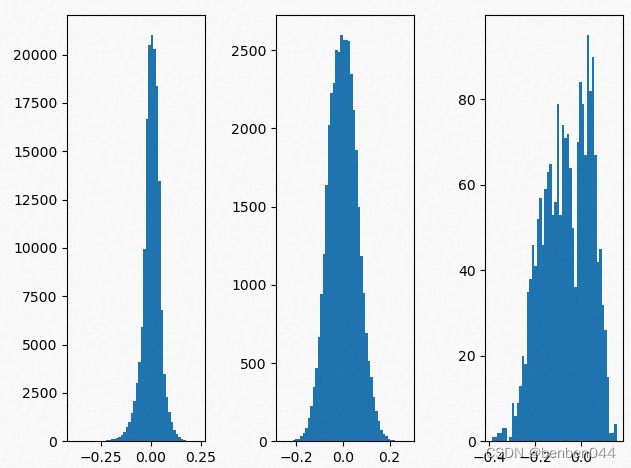
(4)剪枝前后模型参数数据分布
剪枝前的分布:
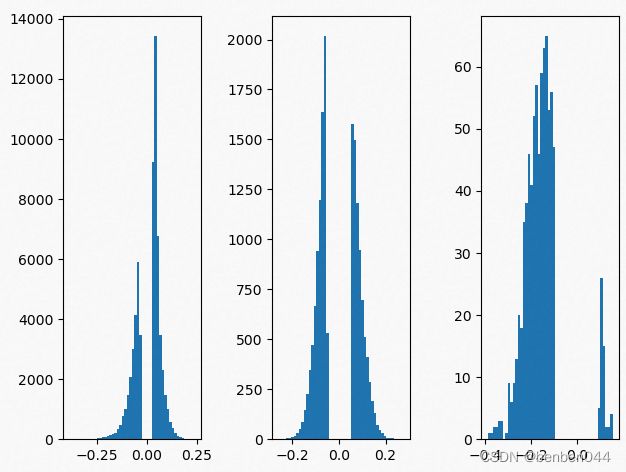
剪枝后的分布:
6、卷积层剪枝
(1)剪枝思路
假设剪枝的比例为50%。
- 对于每一个layer的cnn卷积层,计算其参数的L2范数值,
- 然后将数值通过sum()操作聚合到channel维度上,接着将该值在channel维度上归一化,取非零值中的最小值和对应的channel索引值。
- 多个layer比较各自的最小值,取最小的值及对应的channel索引值对应的mask置为0
- 计算所有参数中零值的比例,一直重复以上3步直到零值的比例达到剪枝的比例。
每一个layer的weight * mask就得到了新的weight。
(2)剪枝代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
import torch.utils.data
import numpy as np
import math
def to_var(x, requires_grad=False):
if torch.cuda.is_available():
x = x.cuda()
return x.clone().detach().requires_grad_(requires_grad)
class MaskedConv2d(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):
super(MaskedConv2d, self).__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.mask_flag = False
def set_mask(self, mask):
self.mask = to_var(mask, requires_grad=False)
self.weight.data = self.weight.data * self.mask.data
self.mask_flag = True
def get_mask(self):
print(self.mask_flag)
return self.mask
def forward(self, x):
# 以下部分与set_mask的self.weight.data = self.weight.data * self.mask.data重合
# if self.mask_flag == True:
# weight = self.weight * self.mask
# return F.conv2d(x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
# else:
# return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = MaskedConv2d(1, 32, kernel_size=3, padding=1, stride=1)
self.relu1 = nn.ReLU(inplace=True)
self.maxpool1 = nn.MaxPool2d(2)
self.conv2 = MaskedConv2d(32, 64, kernel_size=3, padding=1, stride=1)
self.relu2 = nn.ReLU(inplace=True)
self.maxpool2 = nn.MaxPool2d(2)
self.conv3 = MaskedConv2d(64, 64, kernel_size=3, padding=1, stride=1)
self.relu3 = nn.ReLU(inplace=True)
self.linear1 = nn.Linear(7*7*64, 10)
def forward(self, x):
out = self.maxpool1(self.relu1(self.conv1(x)))
out = self.maxpool2(self.relu2(self.conv2(out)))
out = self.relu3(self.conv3(out))
out = out.view(out.size(0), -1)
out = self.linear1(out)
return out
def set_masks(self, masks):
self.conv1.set_mask(torch.from_numpy(masks[0]))
self.conv2.set_mask(torch.from_numpy(masks[1]))
self.conv3.set_mask(torch.from_numpy(masks[2]))
def train(model, device, train_loader, optimizer, epoch):
model.train()
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
total += len(data)
progress = math.ceil(batch_idx / len(train_loader) * 50)
print("\rTrain epoch %d: %d/%d, [%-51s] %d%%" %
(epoch, total, len(train_loader.dataset),
'-' * progress + '>', progress * 2), end='')
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest: average loss: {:.4f}, accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return test_loss, correct / len(test_loader.dataset)
def prune_rate(model, verbose=False):
"""
计算模型的裁剪比例
:param model:
:param verbose:
:return:
"""
total_nb_param = 0
nb_zero_param = 0
layer_id = 0
for parameter in model.parameters():
param_this_layer = 1
for dim in parameter.data.size():
param_this_layer *= dim
total_nb_param += param_this_layer
# only pruning linear and conv layers
if len(parameter.data.size()) != 1:
layer_id += 1
zero_param_this_layer = np.count_nonzero(parameter.cpu().data.numpy() == 0)
nb_zero_param += zero_param_this_layer
if verbose:
print("Layer {} | {} layer | {:.2f}% parameters pruned" \
.format(
layer_id,
'Conv' if len(parameter.data.size()) == 4 \
else 'Linear',
100. * zero_param_this_layer / param_this_layer,
))
pruning_perc = 100. * nb_zero_param / total_nb_param
if verbose:
print("Final pruning rate: {:.2f}%".format(pruning_perc))
return pruning_perc
def arg_nonzero_min(a):
"""
获取非零值中的最小值及其下标值
:param a:
:return:
"""
if not a:
return
min_ix, min_v = None, None
# 查看是否所有值都为0
for i, e in enumerate(a):
if e != 0:
min_ix = i
min_v = e
break
if min_ix is None:
print('Warning: all zero')
return np.inf, np.inf
# search for the smallest nonzero
for i, e in enumerate(a):
if e < min_v and e != 0:
min_v = e
min_ix = i
return min_v, min_ix
def prune_one_filter(model, masks):
"""
pruning one least import feature map by the scaled l2norm of kernel weights
用缩放的核权重l2范数修剪最小输入特征图
:param model:
:param masks:
:return:
"""
NO_MASKS = False
# construct masks if there is not yet
if not masks:
masks = []
NO_MASKS = True
values = []
for p in model.parameters():
if len(p.data.size()) == 4:
p_np = p.data.cpu().numpy()
# construct masks if there is not
if NO_MASKS:
masks.append(np.ones(p_np.shape).astype('float32'))
# find the scaled l2 norm for each filter this layer
value_this_layer = np.square(p_np).sum(axis=1).sum(axis=1).sum(axis=1) / (p_np.shape[1] * p_np.shape[2] * p_np.shape[3])
# normalization(important)
value_this_layer = value_this_layer / np.sqrt(np.square(value_this_layer).sum())
min_value, min_ind = arg_nonzero_min(list(value_this_layer))
values.append([min_value, min_ind])
assert len(masks) == len(values), "something wrong here"
values = np.array(values) # [[min_value, min_ind], [min_value, min_ind], [min_value, min_ind]]
# set mask corresponding to the filter to prune
to_prune_layer_ind = np.argmin(values[:, 0])
to_prune_filter_ind = int(values[to_prune_layer_ind, 1])
masks[to_prune_layer_ind][to_prune_filter_ind] = 0.
return masks
def filter_prune(model, pruning_perc):
"""
剪枝主流程,不停剪枝直到裁剪比例达到要求
:param model:
:param pruning_perc:
:return:
"""
masks = []
current_pruning_perc = 0
while current_pruning_perc < pruning_perc:
masks = prune_one_filter(model, masks)
model.set_masks(masks)
current_pruning_perc = prune_rate(model, verbose=False)
print('{:.2f} pruned'.format(current_pruning_perc))
return masks
def main():
epochs = 2
batch_size = 64
torch.manual_seed(0)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('D:/ai_data/mnist_dataset', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('D:/ai_data/mnist_dataset', train=False, download=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=1000, shuffle=True)
model = ConvNet().to(device)
optimizer = torch.optim.Adadelta(model.parameters())
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
_, acc = test(model, device, test_loader)
print('\npruning 50%')
mask = filter_prune(model, 50)
model.set_masks(mask)
_, acc = test(model, device, test_loader)
# finetune
print('\nfinetune')
train(model, device, train_loader, optimizer, epoch)
_, acc = test(model, device, test_loader)
main()(3)精确度及剪枝比例信息:
Train epoch 1: 60000/60000, [-------------------------------------------------->] 100%
Test: average loss: 0.0505, accuracy: 9833/10000 (98%)
Train epoch 2: 60000/60000, [-------------------------------------------------->] 100%
Test: average loss: 0.0311, accuracy: 9893/10000 (99%)
pruning 50%
0.66 pruned
1.32 pruned
1.65 pruned
1.98 pruned
2.31 pruned
2.64 pruned
2.98 pruned
3.64 pruned
3.97 pruned
4.63 pruned
4.64 pruned
4.65 pruned
4.98 pruned
5.31 pruned
5.32 pruned
5.65 pruned
6.31 pruned
6.97 pruned
7.30 pruned
7.63 pruned
8.30 pruned
8.31 pruned
8.97 pruned
9.30 pruned
9.96 pruned
10.29 pruned
10.95 pruned
11.61 pruned
11.94 pruned
12.60 pruned
13.27 pruned
13.93 pruned
14.26 pruned
14.92 pruned
15.25 pruned
15.26 pruned
15.59 pruned
16.25 pruned
16.91 pruned
17.57 pruned
17.90 pruned
18.23 pruned
18.90 pruned
19.56 pruned
19.89 pruned
20.55 pruned
20.88 pruned
21.54 pruned
21.87 pruned
21.88 pruned
22.54 pruned
22.87 pruned
23.53 pruned
24.20 pruned
24.21 pruned
24.87 pruned
25.20 pruned
25.86 pruned
26.19 pruned
26.20 pruned
26.86 pruned
27.19 pruned
27.52 pruned
28.18 pruned
28.51 pruned
29.18 pruned
29.51 pruned
29.52 pruned
29.85 pruned
29.86 pruned
30.52 pruned
30.85 pruned
31.51 pruned
32.17 pruned
32.83 pruned
33.16 pruned
33.82 pruned
34.16 pruned
34.82 pruned
35.15 pruned
35.48 pruned
36.14 pruned
36.47 pruned
37.13 pruned
37.79 pruned
37.80 pruned
38.13 pruned
38.79 pruned
38.80 pruned
39.13 pruned
39.15 pruned
39.81 pruned
40.14 pruned
40.47 pruned
40.48 pruned
41.14 pruned
41.47 pruned
41.80 pruned
41.81 pruned
42.47 pruned
43.13 pruned
43.46 pruned
43.79 pruned
44.46 pruned
44.79 pruned
44.80 pruned
45.46 pruned
45.79 pruned
45.80 pruned
46.46 pruned
46.79 pruned
47.12 pruned
47.78 pruned
47.79 pruned
47.80 pruned
48.13 pruned
48.79 pruned
49.13 pruned
49.79 pruned
49.80 pruned
50.46 pruned
Test: average loss: 1.6824, accuracy: 6513/10000 (65%)
finetune
Train epoch 2: 60000/60000, [-------------------------------------------------->] 100%
Test: average loss: 0.0324, accuracy: 9889/10000 (99%)可以看到,剪枝完成后直接测试准确率只有65%非常低,重新对weight中的非零参数训练一次后立马接近之前的准确率。