基于目标识别的区域入侵检测——详细实现从获取区域到检测入侵目标
前言
1.区域入侵检测是通过识别目标之后获取目标坐标位置,判断目标是否在所标定的区域内出现,常常被用在电子围栏,不安全区域入侵检测,智慧城市,安防监控等领域。具体使用场景有,在标定的区域内不能抽烟,进入工地区域必须佩戴安全帽,加上人脸识别或者步态识别可以用于安防的陌生人入侵,规定时间内闯进人行道的人或车等。
实现的效果:
2.这里的编译环境是Win 10, vs2019,OpenCV4.5, 目标检测算法用的yolov5,实现语言使用的语言是C++。
一、目标识别
1.模型下载
使用的模型是官方公开的模型,下载地址:https://github.com/ultralytics/yolov5/releases,为了检测速度这里选择了s模型。
2.模型转换
模型下载好之后,要把.pt的模型转成onnx模型,转onnx模型要有yolov5的环境,关于yolov5的环境可以参考我之前的博客:深度学习目标检测(YoloV5)项目——从0开始到项目落地部署。转成onnx之后也可以使用opencv dnn进行推理,也可以从使用别人转好的onnx模型。
如果要使用到移动端上,可以选择使用NCNN库。
模型转换:
python models/export.py --weights yolov5s.pt
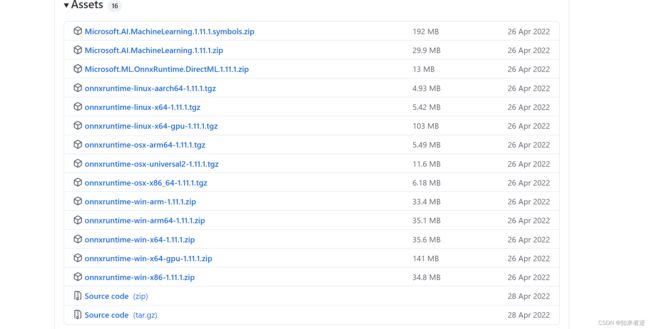
3.onnxruntime推理库
推理库下载地址:https://github.com/microsoft/onnxruntime/releases ,直接下载编译的releases库就行了。想使用GPU则要下载GPU的版本,和安装CUDA库。
4.实现推理检测
onnx推理实现代码:
#include "YoloOnnx.h"
size_t utils::vectorProduct(const std::vector<int64_t>& vector)
{
if (vector.empty())
return 0;
size_t product = 1;
for (const auto& element : vector)
product *= element;
return product;
}
std::wstring utils::charToWstring(const char* str)
{
typedef std::codecvt_utf8<wchar_t> convert_type;
std::wstring_convert<convert_type, wchar_t> converter;
return converter.from_bytes(str);
}
std::vector<std::string> utils::loadNames(const std::string& path)
{
// load class names
std::vector<std::string> classNames;
std::ifstream infile(path);
if (infile.good())
{
std::string line;
while (getline(infile, line))
{
if (line.back() == '\r')
line.pop_back();
classNames.emplace_back(line);
}
infile.close();
}
else
{
std::cerr << "ERROR: Failed to access class name path: " << path << std::endl;
}
return classNames;
}
void utils::visualizeDetection(cv::Mat& image, std::vector<Detection>& detections,
const std::vector<std::string>& classNames)
{
for (const Detection& detection : detections)
{
cv::rectangle(image, detection.box, cv::Scalar(229, 160, 21), 1);
int x = detection.box.x;
int y = detection.box.y;
int conf = (int)std::round(detection.conf * 100);
int classId = detection.classId;
std::string label = classNames[classId];
int baseline = 0;
cv::Size size = cv::getTextSize(label, cv::FONT_ITALIC, 0.8, 1, &baseline);
cv::rectangle(image,
cv::Point(x, y - 25), cv::Point(x + size.width, y),
cv::Scalar(229, 160, 21), -1);
cv::putText(image, label,
cv::Point(x, y - 3), cv::FONT_ITALIC,
0.8, cv::Scalar(255, 255, 255), 1);
}
}
void utils::letterbox(const cv::Mat& image, cv::Mat& outImage,
const cv::Size& newShape = cv::Size(640, 640),
const cv::Scalar& color = cv::Scalar(114, 114, 114),
bool auto_ = true,
bool scaleFill = false,
bool scaleUp = true,
int stride = 32)
{
cv::Size shape = image.size();
float r = std::min((float)newShape.height / (float)shape.height,
(float)newShape.width / (float)shape.width);
if (!scaleUp)
r = std::min(r, 1.0f);
float ratio[2]{ r, r };
int newUnpad[2]{ (int)std::round((float)shape.width * r),
(int)std::round((float)shape.height * r) };
auto dw = (float)(newShape.width - newUnpad[0]);
auto dh = (float)(newShape.height - newUnpad[1]);
if (auto_)
{
dw = (float)((int)dw % stride);
dh = (float)((int)dh % stride);
}
else if (scaleFill)
{
dw = 0.0f;
dh = 0.0f;
newUnpad[0] = newShape.width;
newUnpad[1] = newShape.height;
ratio[0] = (float)newShape.width / (float)shape.width;
ratio[1] = (float)newShape.height / (float)shape.height;
}
dw /= 2.0f;
dh /= 2.0f;
if (shape.width != newUnpad[0] && shape.height != newUnpad[1])
{
cv::resize(image, outImage, cv::Size(newUnpad[0], newUnpad[1]));
}
int top = int(std::round(dh - 0.1f));
int bottom = int(std::round(dh + 0.1f));
int left = int(std::round(dw - 0.1f));
int right = int(std::round(dw + 0.1f));
cv::copyMakeBorder(outImage, outImage, top, bottom, left, right, cv::BORDER_CONSTANT, color);
}
void utils::scaleCoords(const cv::Size& imageShape, cv::Rect& coords, const cv::Size& imageOriginalShape)
{
float gain = std::min((float)imageShape.height / (float)imageOriginalShape.height,
(float)imageShape.width / (float)imageOriginalShape.width);
int pad[2] = { (int)(((float)imageShape.width - (float)imageOriginalShape.width * gain) / 2.0f),
(int)(((float)imageShape.height - (float)imageOriginalShape.height * gain) / 2.0f) };
coords.x = (int)std::round(((float)(coords.x - pad[0]) / gain));
coords.y = (int)std::round(((float)(coords.y - pad[1]) / gain));
coords.width = (int)std::round(((float)coords.width / gain));
coords.height = (int)std::round(((float)coords.height / gain));
}
template <typename T>
T utils::clip(const T& n, const T& lower, const T& upper)
{
return std::max(lower, std::min(n, upper));
}
YoloOnnx::YoloOnnx(const std::string& modelPath,
const bool& isGPU = true,
const cv::Size& inputSize = cv::Size(640, 640))
{
env = Ort::Env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING, "ONNX_DETECTION");
sessionOptions = Ort::SessionOptions();
std::vector<std::string> availableProviders = Ort::GetAvailableProviders();
auto cudaAvailable = std::find(availableProviders.begin(), availableProviders.end(), "CUDAExecutionProvider");
OrtCUDAProviderOptions cudaOption;
if (isGPU && (cudaAvailable == availableProviders.end()))
{
std::cout << "GPU is not supported by your ONNXRuntime build. Fallback to CPU." << std::endl;
std::cout << "Inference device: CPU" << std::endl;
}
else if (isGPU && (cudaAvailable != availableProviders.end()))
{
std::cout << "Inference device: GPU" << std::endl;
sessionOptions.AppendExecutionProvider_CUDA(cudaOption);
}
else
{
std::cout << "Inference device: CPU" << std::endl;
}
#ifdef _WIN32
std::wstring w_modelPath = utils::charToWstring(modelPath.c_str());
session = Ort::Session(env, w_modelPath.c_str(), sessionOptions);
#else
session = Ort::Session(env, modelPath.c_str(), sessionOptions);
#endif
Ort::AllocatorWithDefaultOptions allocator;
Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(0);
std::vector<int64_t> inputTensorShape = inputTypeInfo.GetTensorTypeAndShapeInfo().GetShape();
this->isDynamicInputShape = false;
// checking if width and height are dynamic
if (inputTensorShape[2] == -1 && inputTensorShape[3] == -1)
{
std::cout << "Dynamic input shape" << std::endl;
this->isDynamicInputShape = true;
}
for (auto shape : inputTensorShape)
std::cout << "Input shape: " << shape << std::endl;
inputNames.push_back(session.GetInputName(0, allocator));
outputNames.push_back(session.GetOutputName(0, allocator));
std::cout << "Input name: " << inputNames[0] << std::endl;
std::cout << "Output name: " << outputNames[0] << std::endl;
this->inputImageShape = cv::Size2f(inputSize);
}
void YoloOnnx::getBestClassInfo(std::vector<float>::iterator it, const int& numClasses,
float& bestConf, int& bestClassId)
{
// first 5 element are box and obj confidence
bestClassId = 5;
bestConf = 0;
for (int i = 5; i < numClasses + 5; i++)
{
if (it[i] > bestConf)
{
bestConf = it[i];
bestClassId = i - 5;
}
}
}
void YoloOnnx::preprocessing(cv::Mat &image, float*& blob, std::vector<int64_t>& inputTensorShape)
{
cv::Mat resizedImage, floatImage;
cv::cvtColor(image, resizedImage, cv::COLOR_BGR2RGB);
utils::letterbox(resizedImage, resizedImage, this->inputImageShape,
cv::Scalar(114, 114, 114), this->isDynamicInputShape,
false, true, 32);
inputTensorShape[2] = resizedImage.rows;
inputTensorShape[3] = resizedImage.cols;
resizedImage.convertTo(floatImage, CV_32FC3, 1 / 255.0);
blob = new float[floatImage.cols * floatImage.rows * floatImage.channels()];
cv::Size floatImageSize {floatImage.cols, floatImage.rows};
// hwc -> chw
std::vector<cv::Mat> chw(floatImage.channels());
for (int i = 0; i < floatImage.channels(); ++i)
{
chw[i] = cv::Mat(floatImageSize, CV_32FC1, blob + i * floatImageSize.width * floatImageSize.height);
}
cv::split(floatImage, chw);
}
std::vector<Detection> YoloOnnx::postprocessing(const cv::Size& resizedImageShape,
const cv::Size& originalImageShape,
std::vector<Ort::Value>& outputTensors,
const float& confThreshold, const float& iouThreshold)
{
std::vector<cv::Rect> boxes;
std::vector<float> confs;
std::vector<int> classIds;
auto* rawOutput = outputTensors[0].GetTensorData<float>();
std::vector<int64_t> outputShape = outputTensors[0].GetTensorTypeAndShapeInfo().GetShape();
size_t count = outputTensors[0].GetTensorTypeAndShapeInfo().GetElementCount();
std::vector<float> output(rawOutput, rawOutput + count);
// for (const int64_t& shape : outputShape)
// std::cout << "Output Shape: " << shape << std::endl;
// first 5 elements are box[4] and obj confidence
int numClasses = (int)outputShape[2] - 5;
int elementsInBatch = (int)(outputShape[1] * outputShape[2]);
// only for batch size = 1
for (auto it = output.begin(); it != output.begin() + elementsInBatch; it += outputShape[2])
{
float clsConf = it[4];
if (clsConf > confThreshold)
{
int centerX = (int) (it[0]);
int centerY = (int) (it[1]);
int width = (int) (it[2]);
int height = (int) (it[3]);
int left = centerX - width / 2;
int top = centerY - height / 2;
float objConf;
int classId;
this->getBestClassInfo(it, numClasses, objConf, classId);
float confidence = clsConf * objConf;
boxes.emplace_back(left, top, width, height);
confs.emplace_back(confidence);
classIds.emplace_back(classId);
}
}
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confs, confThreshold, iouThreshold, indices);
std::vector<Detection> detections;
for (int idx : indices)
{
Detection det;
det.box = cv::Rect(boxes[idx]);
utils::scaleCoords(resizedImageShape, det.box, originalImageShape);
det.conf = confs[idx];
det.classId = classIds[idx];
detections.emplace_back(det);
}
return detections;
}
std::vector<Detection> YoloOnnx::detect(cv::Mat &image, const float& confThreshold = 0.4,
const float& iouThreshold = 0.45)
{
float *blob = nullptr;
std::vector<int64_t> inputTensorShape {1, 3, -1, -1};
this->preprocessing(image, blob, inputTensorShape);
size_t inputTensorSize = utils::vectorProduct(inputTensorShape);
std::vector<float> inputTensorValues(blob, blob + inputTensorSize);
std::vector<Ort::Value> inputTensors;
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(
OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize,
inputTensorShape.data(), inputTensorShape.size()
));
std::vector<Ort::Value> outputTensors = this->session.Run(Ort::RunOptions{nullptr},
inputNames.data(),
inputTensors.data(),
1,
outputNames.data(),
1);
cv::Size resizedShape = cv::Size((int)inputTensorShape[3], (int)inputTensorShape[2]);
std::vector<Detection> result = this->postprocessing(resizedShape,
image.size(),
outputTensors,
confThreshold, iouThreshold);
delete[] blob;
return result;
}
5.运行检测
二、获取区域
1.绘制直线
要获取区域首要就是在视频画面上先绘制一条条直线开始,这里要用到opencv 鼠标回调函数。绘制直接的逻辑是,视频流一进来,就要画好直线,画完之后保存在一个容器里面,如果是上线项目,则可以保存到数据库上去,每次重启摄像头就去读出数据,而不是每次都要标定。
绘制直线:
cv::Mat cv_src;
cv::Mat cv_dst;
struct Line
{
cv::Point p1;
cv::Point p2;
};
std::vector<Line> lines;
void on_mouse(int event, int x, int y, int flags, void* ustc)
{
static cv::Point pre_pt = { -1, -1 };
static cv::Point cur_pt = { -1, -1 };
char temp[16];
if (event == cv::EVENT_LBUTTONDOWN)
{
cv_dst.copyTo(cv_src);
sprintf(temp, "(%d,%d)", x, y);
pre_pt = cv::Point(x, y);
putText(cv_src, temp, pre_pt, cv::FONT_HERSHEY_PLAIN, 1, cv::Scalar(0, 0, 255), 1, 8, 0);
circle(cv_src, pre_pt, 3, cv::Scalar(255, 0, 0, 0), cv::FILLED, cv::LINE_AA, 0);
cv::imshow("src", cv_src);
cv_src.copyTo(cv_dst);
}
else if (event == cv::EVENT_MOUSEMOVE && (flags & cv::EVENT_FLAG_LBUTTON))
{
sprintf(temp, "(%d,%d)", x, y);
cv_dst.copyTo(cv_src);
cur_pt = cv::Point(x, y);
putText(cv_src, temp, cur_pt, cv::FONT_HERSHEY_PLAIN, 1, cv::Scalar(0, 0, 255), 1, 8, 0);
line(cv_src, pre_pt, cur_pt, cv::Scalar(0, 255, 0, 0), 1, cv::LINE_AA, 0);
cv::imshow("src", cv_src);
}
else if (event == cv::EVENT_LBUTTONUP)
{
sprintf(temp, "(%d,%d)", x, y);
cv_dst.copyTo(cv_src);
cur_pt = cv::Point(x, y);
putText(cv_src, temp, cur_pt, cv::FONT_HERSHEY_PLAIN, 1, cv::Scalar(0, 0, 255), 1, 8, 0);
circle(cv_src, cur_pt, 3, cv::Scalar(255, 0, 0, 0), cv::FILLED, cv::LINE_AA, 0);
line(cv_src, pre_pt, cur_pt, cv::Scalar(0, 255, 0, 0), 1, cv::LINE_AA, 0);
lines.push_back({ pre_pt, cur_pt });
cv::imshow("src", cv_src);
cv_src.copyTo(cv_dst);
}
}
2.在视频流里面绘制区域
读入摄像头之后,第一帧往往是空的,去掉,截取第二帧图像,在图像上绘制区域,绘制完成之后,按任意键退出绘制,绘制的时候视频是卡在当前界面的。
调用代码:
cv::VideoCapture video("3.mp4");
if (!video.isOpened())
{
return 0;
}
cv::Mat cv_src;
cv::Mat cv_temp;
video >> cv_temp;
video >> cv_src;
//开始绘制区域
cv::namedWindow("src", 0);
cv_src.copyTo(cv_dst);
cv::setMouseCallback("src", on_mouse, 0);
cv::imshow("src", cv_src);
//按任意键退出绘制
cv::waitKey();
while (1)
{
video >> cv_src;
if (cv_src.empty())
{
continue;
}
for (auto l : lines)
{
line(cv_src, l.p1, l.p2, cv::Scalar(0, 255, 0, 0), 1, cv::LINE_AA, 0);
}
cv::imshow("src", cv_src);
if (cv::waitKey(24) == 'q')
{
break;
}
}
3.绘制效果
三、检测入侵目标
1.入侵检测算法
首先目标位置的坐标在目标检测的代码中已经有拿到,目标整体区域是一个外接矩形(如果对精度有要未求,这里可以加入实例分割),现在假设所标定的区域是一个多边形,可以是规则的,也可是不规则的,但必须是封闭,如果不是封闭的区域,算法会产生歧义,如果使用场景是不封闭区域,可以参考越线检测。检测有两种实现方法,一种要判断目标的外接矩形任何点是否被这个多边形所包含,或者是否有重叠的部分,这种办法会有很多坐标之间的计算。另一种比较简单粗暴,就是直接把标定区域剪切下来,然后只对标定区域做检测。为对演示方便,我这里使用第二方法。
代码实现:
void getRoi(const cv::Mat& cv_src, cv::Mat& cv_dst, std::vector<Line> &lines)
{
cv::Mat cv_temp = cv::Mat::zeros(cv_src.size(), CV_8UC3);
for (auto l : lines)
{
line(cv_temp, l.p1, l.p2, cv::Scalar(0, 255, 0, 0), 1, cv::LINE_AA, 0);
}
cv::cvtColor(cv_temp, cv_temp, cv::COLOR_BGR2GRAY);
cv::Mat cv_binarry, cv_gary;
threshold(cv_temp, cv_binarry, 10, 255, cv::THRESH_BINARY);
cv::Mat cv_dilate;
cv::Mat element_d = getStructuringElement(cv::MORPH_RECT, cv::Size(11, 11), cv::Point(-1, -1));
cv::dilate(cv_binarry, cv_dilate, element_d);
cv::Mat cv_erode;
cv::Mat element_e = getStructuringElement(cv::MORPH_RECT, cv::Size(11, 11), cv::Point(-1, -1));
cv::erode(cv_dilate, cv_erode, element_e);
std::vector<std::vector<cv::Point>>contours;
findContours(cv_erode, contours, 0, 2, cv::Point());
cv::Rect rect;
for (int n = 0; n < contours.size(); n++)
{
rect = boundingRect(contours[n]);
}
rectangle(cv_src, rect, cv::Scalar(0, 0, 255), 1);
cv::Point p = getCenterPoint(rect);
cv::floodFill(cv_erode, p, cv::Scalar(255));
cv_dst = cv::Mat(cv_src.size(), CV_8UC3, cv::Scalar(255, 255, 255));
cv_src.copyTo(cv_dst, cv_erode);
}
效果,右的区域就是所标定的区域,现在只对这个区域做检测。
2.区域标定与入侵检测
int main()
{
std::string classNamesPath = "models/coco.names";
std::string onnx_model = "models/yolov5s.onnx";
const float confThreshold = 0.3f;
const float iouThreshold = 0.4f;
const std::vector<std::string> class_names = utils::loadNames(classNamesPath);
YoloOnnx onnx_detector{ nullptr };
onnx_detector = YoloOnnx(onnx_model, false, cv::Size(640, 640));
cv::VideoCapture video("video.mp4");
if (!video.isOpened())
{
return 0;
}
cv::Mat cv_src;
cv::Mat cv_temp;
video >> cv_temp;
video >> cv_src;
//开始绘制区域
cv::namedWindow("src", 0);
cv_src.copyTo(cv_dst);
cv::setMouseCallback("src", on_mouse, 0);
cv::imshow("src", cv_src);
//按任意键退出绘制
cv::waitKey();
while (1)
{
video >> cv_src;
if (cv_src.empty())
{
continue;
}
cv::Mat cv_roi;
getRoi(cv_src, cv_roi, lines);
std::vector<Detection> onnx_result;
onnx_result = onnx_detector.detect(cv_roi, confThreshold, iouThreshold);
utils::visualizeDetection(cv_src, onnx_result, class_names);
for (auto l : lines)
{
line(cv_src, l.p1, l.p2, cv::Scalar(0, 255, 0, 0), 1, cv::LINE_AA, 0);
}
cv::imshow("src", cv_src);
if (cv::waitKey(24) == 'q')
{
break;
}
}
return 0;
}
3.检测效果,可以看到只检测了标定区域内的目标,当目标离开标定区域或者在标定区域之外,不做任何处理。
四、源码配置
1.源码地址:https://download.csdn.net/download/matt45m/86009846 。
2.编译环境配置
下载源码后用vs2019打开
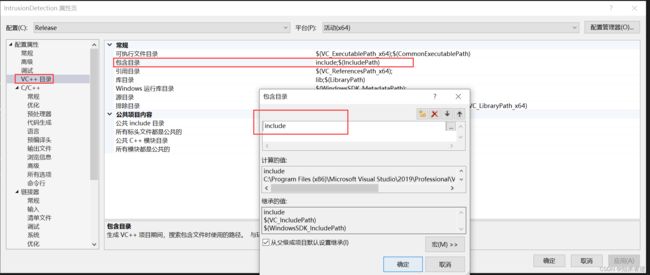
2.1 配置include
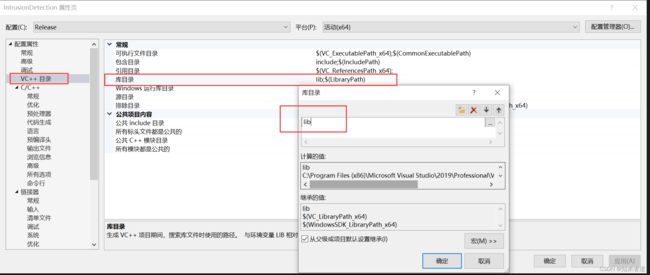
2.2 配置lib
2.3 配置链接库

2.4 运行项目
