SemanticStyleGAN: Learning Compositional Generative Priorsfor Controllable Image Synthesis and Edit
1.SemanticStyleGAN:学习构成性的生成先验可控制的图像合成和编辑
机构:字节跳动 USA
2.github 地址 SemanticStyleGAN - Project Page
3.介绍会:
SemanticStyleGAN根据语义区域分解其潜在空间。在这里,我们通过交换局部潜在代码来显示样式混合的结果。请注意,我们的模型也会混淆形状和纹理,但我们同时在这里改变两者 。
4.摘要;
最近的研究表明,StyleGANs为图像合成和编辑的下游任务提供了有希望的先验模型。但是,由于stylegans的潜在代码旨在控制全局样式,因此很难实现对合成图像的细粒度控制。我们介绍了SemanticStyleGAN,其中对生成器进行了训练,以分别对局部语义部分进行建模,并以合成方式合成图像。不同局部部分的结构和纹理由相应的潜码控制。实验结果表明,我们的模型在不同空间区域之间提供了强大的解纠缠。当与为StyleGANs设计的编辑方法结合使用时,它可以实现更细粒度的控制来编辑合成或真实图像。该模型还可以通过转移学习扩展到其他领域。因此,作为具有内置解纠缠的通用先验模型,它可以促进基于GAN的应用程序的开发并实现更多潜在的下游任务
5.贡献 The contributions of this work can be summarized as follows:
1.一种组合生成器体系结构,可将潜在空间分解为不同的语义区域,以控制局部部分的结构和纹理
2.学习图像和语义分割掩模联合建模的 GAN 训练框架
3.实验表明,我们的生成器可以与现有的潜在操作方法相结合,以更可控的方式编辑图像
4.实验表明,我们的生成器可以仅用有限的图像适应其他域,同时保留空间解纠缠
6.method 方法
典型的GAN框架学习将向量z〜Z映射到图像的生成器,其中Z通常是标准正态分布。在StyleGANs 中,为了处理数据分布的非线性,首先通过MLP将z映射为具有的潜码w〜W。然后将这个W空间扩展为W空间,该空间以不同的分辨率控制输出样式 [36]。但是,这些潜在代码没有严格定义的含义,并且几乎不能单独使用。
我们提出一个生成器,其W空间针对不同的语义区域进行解纠缠。形式上,给定一个带标签的数据集D = {(x1,y1),(x2,y2)...,(xn,yn)},其中yi ∈ ![]() 是图像xi的语义分割掩码,K是语义类的个数,我们的生成器给出了一个因式分解的
是图像xi的语义分割掩码,K是语义类的个数,我们的生成器给出了一个因式分解的![]() ,使得.
,使得.
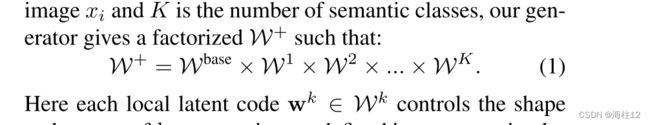
在这里,每个本地潜在代码![]() ∈
∈ ![]() 控制在分段标签中定义的第k个语义区域的形状和纹理,而
控制在分段标签中定义的第k个语义区域的形状和纹理,而![]() ∈
∈ ![]() 是控制粗糙结构 (例如姿势) 的共享代码。每个
是控制粗糙结构 (例如姿势) 的共享代码。每个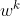 进一步分解为形状代码
进一步分解为形状代码![]() 和纹理代码
和纹理代码![]() 。生成器G:
。生成器G: ![]() → X × Y将潜在代码映射到RGB图像和语义分割蒙版。为此,我们确定了两个主要挑战:
→ X × Y将潜在代码映射到RGB图像和语义分割蒙版。为此,我们确定了两个主要挑战:
(一)如何将不同的地方解耦?
(二)如何保证这些区域的语义含义?
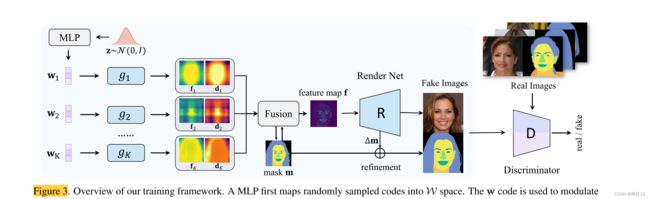
如何将不同的地方解耦?如何保证这些区域的语义含义?图3。我们的培训框架概述。MLP首先将随机采样的代码映射到W空间中。w代码用于调制本地生成器的权重。每个本地生成器gk输出一个特征图fk和一个伪深度图dk,它们融合成一个粗分割掩模m和一个全局特征图f,用于图像合成。仅基于特征图的渲染网络R通过学习残差 ∆ m将上采样的m细化为高分辨率分割蒙版,并生成假图像。双分支鉴别器对RGB图像和语义分割掩模的联合分布进行建模 。
生成器
我们的Generator的整体结构如图3所示。与styletan2 类似,8层MLP首先将z映射到中间代码w。然后,引入K个局部生成器,使用w对不同的语义部分进行建模。渲染网络R从本地生成器获取融合的结果,并输出RGB图像和相应的语义分割掩码。
Local Generator
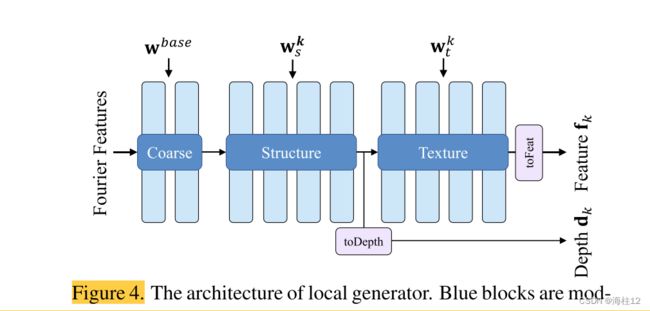
本地生成器的架构。蓝色块是经过调制的 1×1 卷积层,其权重以输入潜在代码为条件。紫色块是线性变换层

Fusion
融合在融合步骤中,我们首先从伪深度图生成粗分割掩模m。在先前有关成分生成的工作之后 ,伪深度图用作softmax函数的logit:


这里  表示逐元素乘法。聚合特征图f包含关于输出图像的所有信息,并被发送到R中进行渲染
表示逐元素乘法。聚合特征图f包含关于输出图像的所有信息,并被发送到R中进行渲染
render net
render net R类似于原始StyleGAN2生成器,但进行了一些修改。首先,它不使用调制卷积层,并且输出仅取决于输入特征图。其次,我们以16 × 16和64 × 64分辨率输入特征图,其中特征串联以64 × 64进行。低分辨率特征图的附加输入允许不同部分之间更好的混合。最后,我们发现,由于softmax输出与实际分段掩码之间的内在差距,很难直接使用m进行训练。因此,除了每个卷积层之后的torRGB分支之外,我们还有一个额外的ToSeg分支,如SemanticGAN 中输出残差,以将粗分割掩码m细化为最终掩码,y = 上采样 (m) ∆ m具有与输出图像相同的大小。这里需要正则化损失,以使最终掩码不会偏离粗掩码太多.
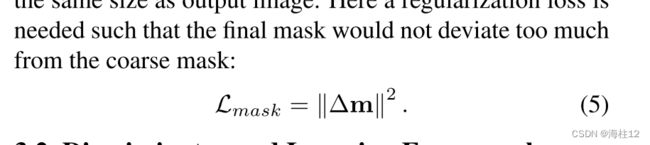
Discriminator and Learning Framework
鉴别器和学习框架为了对联合分布p(x,y) 进行建模,鉴别器需要同时将RGB图像和分割掩模作为输入。我们发现,由于分割掩模上的梯度幅度较大,因此简单的连系不起作用。因此,我们建议使用双分支鉴别器D(x,y),它分别具有两个用于x和y的卷积分支。然后将输出求和为完全连接的层。这样的设计使我们能够以额外的R1正则化损耗LR1seg分别对分段分支的梯度范数进行正则化。生成的训练框架类似于styletan2,其损失函数为:
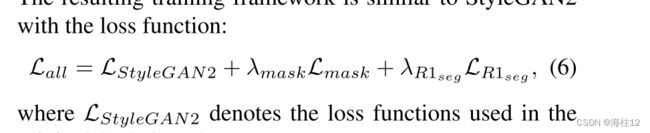
7. Experiments
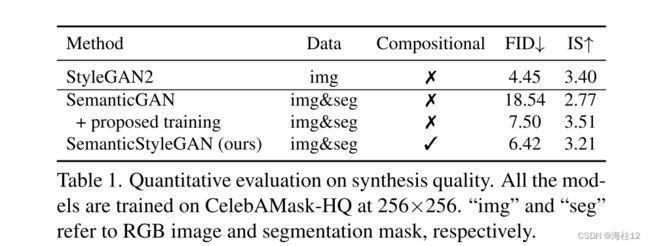
实验所有模型都在CelebAMask-HQ的前28,000图像上进行了训练,尺寸调整为256 × 256。 (FID) 和起始分数 (IS) 用于测量合成质量

8 结果

9.结论
在本文中,我们提出了一种新型的GAN方法,该方法以可控的方式合成图像。通过局部生成器的设计,掩蔽特征聚合以及图像和分割蒙版的联合建模,我们能够分别对不同语义区域的结构和纹理进行建模。实验表明,我们的方法能够合成高质量的图像,同时解开不同的局部部分。通过将我们的模型与其他编辑方法相结合,我们可以以更细粒度的控制来编辑合成图像。实验还表明,我们的模型可以适应仅图像数据集,同时保留解纠缠能力。我们相信所提出的方法为可控图像合成提供了GAN先验的新的有趣方向,可以为许多潜在的下游任务提供启示