Numpy全系列笔记
目录
0.导引
1.AI前导课
2.Jupyter
3.Ipython
3.1 运行外部的python命令
3.2 运行计时
3.3 查看当前会话中所有变量与函数
3.4 执行Linux指令
3.5 更多魔法指令
3.6 Ipython输入输出历史
4.numpy数组基本概念
5.numpy数组的构造与属性
5.1 numpy的一般构造
5.2 numpy的常规函数构造
5.3 numpy必记属性
6.numpy的基本操作
6.1 索引
6.2 切片
6.3 变形
6.4 级联
6.5 切分
7.numpy的聚合操作
7.1 常见的聚合操作
7.2 广播运算
8.矩阵运算
9.numpy排序
9.1 快速排序
9.2 部分排序
0.导引

1.AI前导课
1.数据阶段 要使用的编译器:jupyter notebook
2.数据阶段:
AI 初级
AI体系: google alphago 深度学习阶段
商业阶段:推荐系统,人脸识别,验证码识别,BI(数据分析)(偏运维)
工业领域:智能驾驶,语义分析,情感分析,目标检测(偏重算法开发)
数学基础:高等数学,概率论,线性代数
python 基本库: numpy pandas ==> 数据分析+人工智能的基础
sklearn ==> 数据挖掘+人工智能的基础(也可以用于建模)
tensorflow ==> 深度学习的框架
可视化工具:Matplotlib seaborn Excel POWERBI Tableau SPSS
python是综合学科:python-web 爬虫 数据分析
数据分析岗 监控数据 给出一些决策建议(商业数据分析模式)
2.Jupyter
shift+tab ==> 查看帮助文档 { help(len) 获取 ? len }
shift+enter ==> 运行 { 或者:ctrl+enter }
3.Ipython
3.1 运行外部的python命令
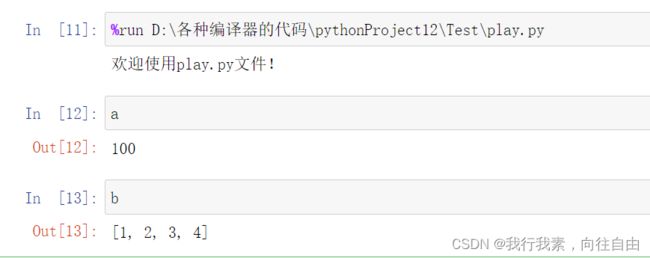
使用下面的命令运行外部的python文件(默认是当前目录,最好加上绝对路径):
%run *.py 注意:路径不用加双引号
运行外部的python,相当于把整个文件的资源都加载到jupyter notebook中了,所以py文件里面的所有变量。函数都可以直接使用。
如下所示:
3.2 运行计时
% 表示检测一行代码
%% 表示检测多行代码
time 代码运行一次
timeit 代码运行多次,求平均时间
%time 表示检测一行代码运行一次时间
%timeit 表示检测一行代码运行的平均时间
%%time 表示多行代码运行时间
%%timeit 表示多行代码平均运行时间
短代码建议用第二种,长代码用第一种,因为第二种运行多次耗时太长。




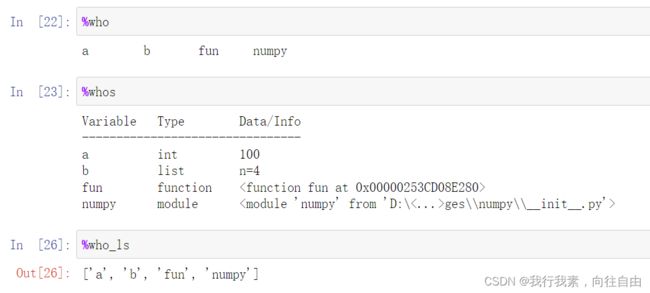
3.3 查看当前会话中所有变量与函数
%who ==> 快速查看当前会话的所有变量与函数名称
%whos ==> 查看当前会话的所有变量与函数名称的详细信息
%who_ls ==> 返回一个字符串列表,里面元素是当前会话的所有变量与函数名称
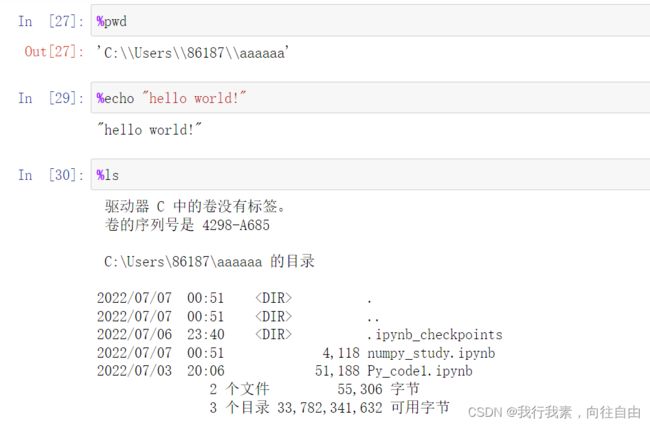
3.4 执行Linux指令
mac Linux ==> 使用!
windows ==> 使用%
注意:%与指令之间无空格
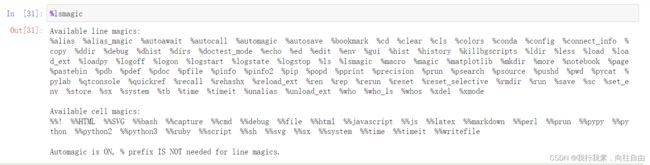
3.5 更多魔法指令
列出所有的魔法指令:%lsmagic
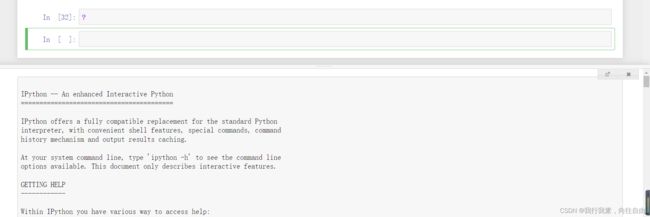
查看魔法指令的文档:使用?
3.6 Ipython输入输出历史
- 可使用In/Out调用输入输出历史:
In返回一个字符串列表,里面是所有输入命令的字符串;
Out返回一个含有输出的命令的序号及其输出组成的字典;
两者皆可以通过索引获取元素。
- 使用下划线表示输出:
"_"表示上一个输出
"_2"表示Out[2]

4.numpy数组基本概念
numpy提供了一种数组类型,高维数组,提供了数据分析的运算基础(业务表一般就是二维)

c ==> 数组的概念:数据类型一致的一个连续的内存空间
python ==> list列表(C语言说:列表其实就是一个指针数组),列表不要求数据类型一致
numpy ==> 同样是一个【有序】的,【相同数据类型】的集合
numpy设计初衷是用于运算的,所以对数据类型进行统一优化。
注意︰
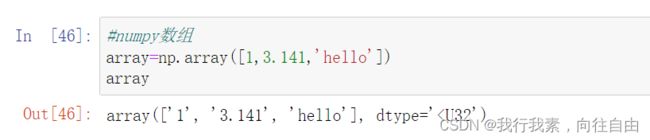
- numpy默认ndarray的所有元素的类型是相同的
- 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
5.numpy数组的构造与属性
5.1 numpy的一般构造
- array(object,dtype=None,copy=True,order='K', subok=False,ndmin=0)




5.2 numpy的常规函数构造
包含以下常见创建方法︰
1) np.ones(shape, dtype=None, order='C')
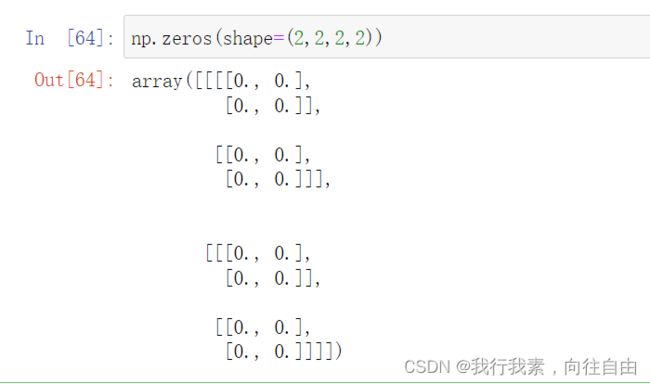
2) np.zeros(shape, dtype=float, order='C')
3) np.full(shape, fill_value, dtype=None, order='C')
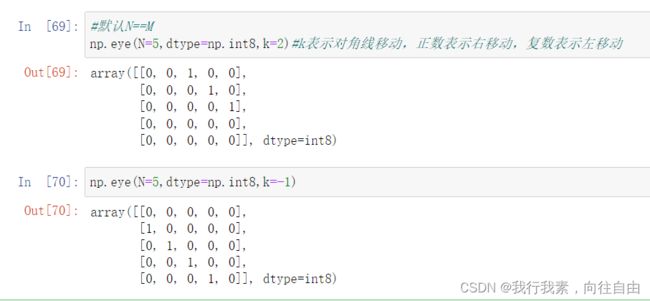
4) np.eye(N, M=None,k=0, dtype=float) 对角线为1其他的位置为0
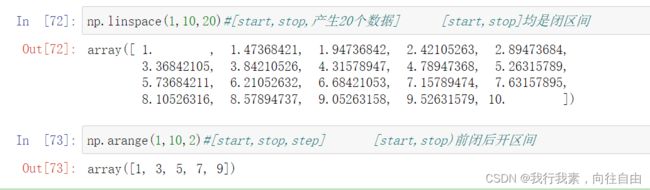
5) np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)6) np.arange([start, ]stop, [step, ]dtype=None)
7) np.random.randint(low, high=None, size=None, dtype=')
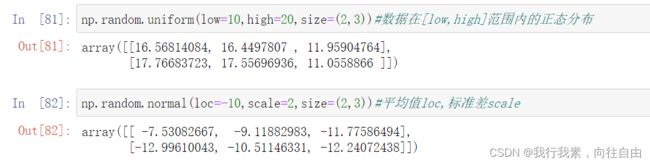
8)正态分布函数
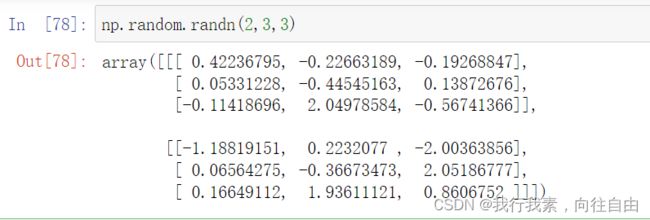
. np.random.randn(d0, d1,..., dn) 标准正态分布. np.random.normal() 普通正态分布
9) np.random.random(size=None) 生成0到1的随机数,左闭右开10)np.random.permutation(n) 生成n个无重复的整数,用于随即生成索引
shape的几种情况:
shape=(m,n) m行n列 二维数组
shape=(m) m个元素的一维数组
shape(m,) m个元素的一维数组
shape(m,1) m行1列 二维数组 [[1],[3],[5]]shape(1,m) 1行m列 二维数组 [[1,2,3]]
1) np.ones(shape, dtype=None, order='C')


2) np.zeros(shape, dtype=float, order='C')

3) np.full(shape, fill_value, dtype=None, order='C')

4) np.eye(N, M=None,k=0, dtype=float) 对角线为1其他的位置为0

5) np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
等差数列 关注生成多少个数据 [start,stop]6) np.arange([start, ]stop, [step, ]dtype=None)
等差数列 关注步长 [start,stop)
7) np.random.randint(low, high=None, size=None, dtype=')
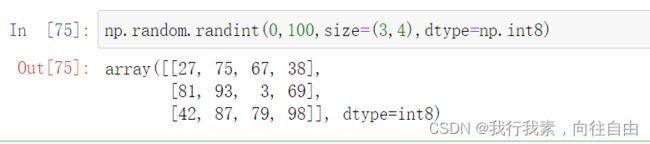
8)正态分布函数
. np.random.randn(d0, d1,..., dn) 标准正态分布. np.random.normal() 普通正态分布
9) np.random.random(size=None) 生成0到1的随机数,[0,1)

10)np.random.permutation(n) 生成n个无重复的整数,用于随即生成索引

5.3 numpy必记属性
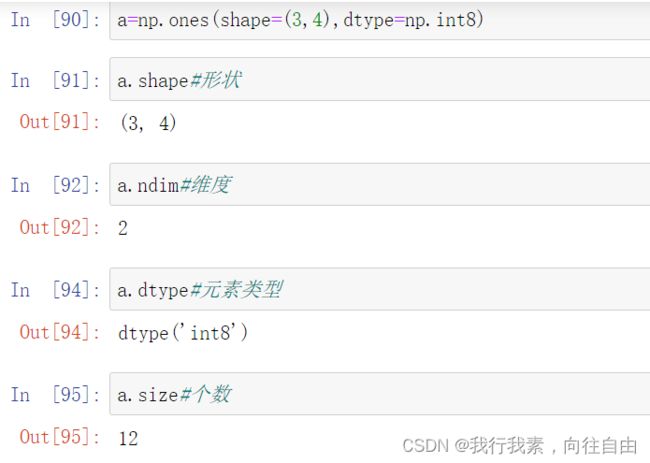
4个必记参数:
- ndim:维度
- shape :形状(各维度的长度)
- size:总长度
- dtype :元素类型
6.numpy的基本操作
6.1 索引
一维与列表完全一致,多维时同理。
二维数组:
num[0] ==>第0行
num[1][2] ==>1行2列(兼容)
num[1,2] ==>1行2列(特有方式)
一维数组:
num[2]
num[[0,1,2] ==>同时访问多个
高级用法:
使用列表下标访问;
使用bool类型访问。
数据翻转:arr[::-1]



6.2 切片
一维与列表完全一致,多维时同理。
所有的切片都是左闭右开区间 [start,end)
不论多少维,每一个维度的切片范围都是用冒号表示,使用逗号分割,最后一个维度可以省略,但是被切片的维度之前的维度不能省。


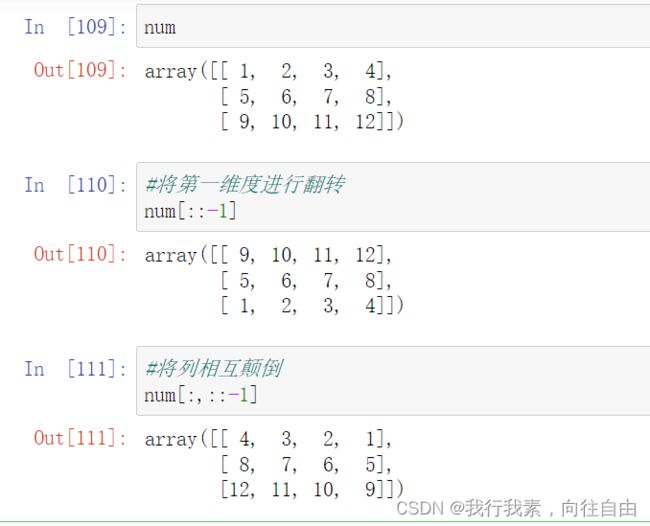
6.3 变形
使用reshape函数,reshape返回的是一个新数组,原数组不变。
注意:参数是一个tuple,但不写成元组也可以;不可以将参数写成shape=(m,n),报错。

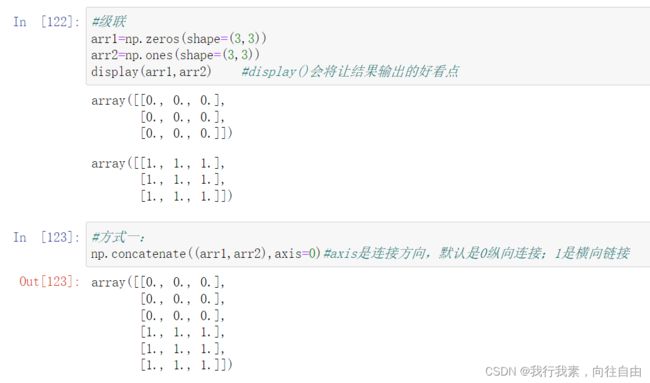
6.4 级联
级联:就是将两个数组连接。
np.concatenate()级联需要注意的点:
1.级联的参数是列表:一定要加中括号或小括号2.维度必须相同
3.形状相符
4.【重点】级联的方向默认是shape这个tuple的第一个值所代表的维度方向5.可通过axis参数改变级联的方向
np.hstack与np.vstack:
水平级联与垂直级联,处理自己,进行维度的变更

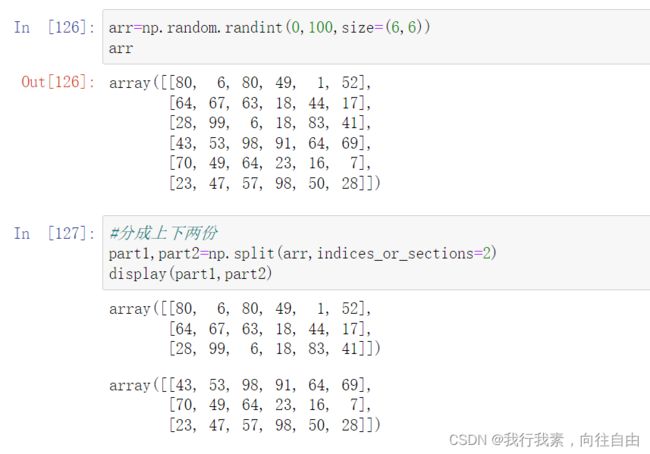
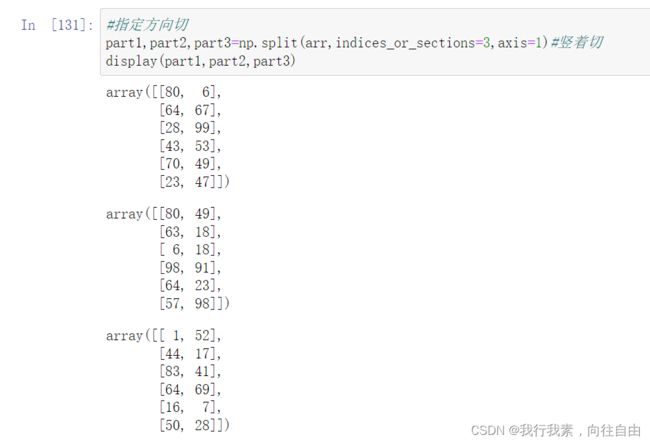
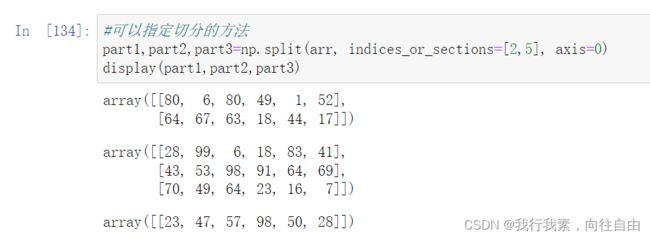
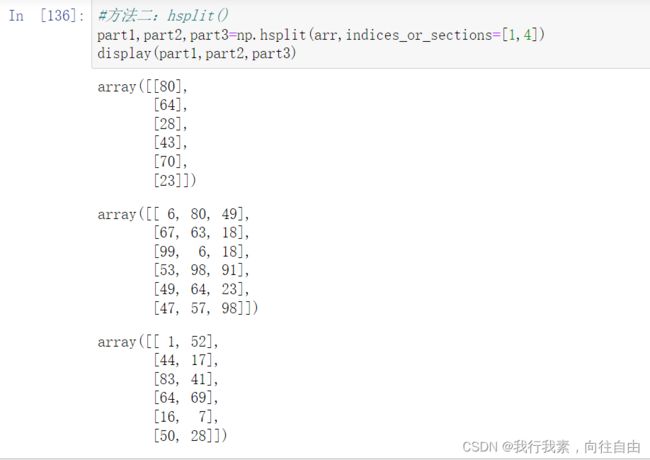
6.5 切分
与级联类似,三个函数完成切分工作:
- np.split(ary, indices_or_sections, axis=0)
- np.vsplit(ary, indices_or_sections)
- np.hsplit(ary, indices_or_sections)
indices_or_sections=[n1,n2,...]可以指定切的方法, n1,n2相当于刀,切一刀。
7.numpy的聚合操作
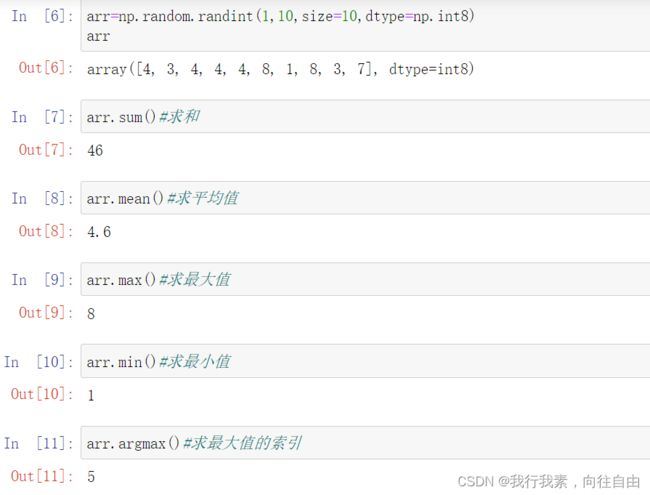
7.1 常见的聚合操作
arr.sum() ==> 求和 arr.max() ==> 求最大
arr.min() ==> 求最小 arr.argmin() ==> 求最小值下标
arr.mean() ==> 求平均值 np.median(arr) ==> 求中位数(注意:不一样)
arr.std() ==> 求标准差 arr.var() ==>求方差
np.percentile(arr,[0.25,0.5,0.75]) ==> 求分位数
arr.all() ==> bool列表里所有值都是True 或者 all(arr)
arr.any() ==> bool列表里有值是True 或者 any(arr)


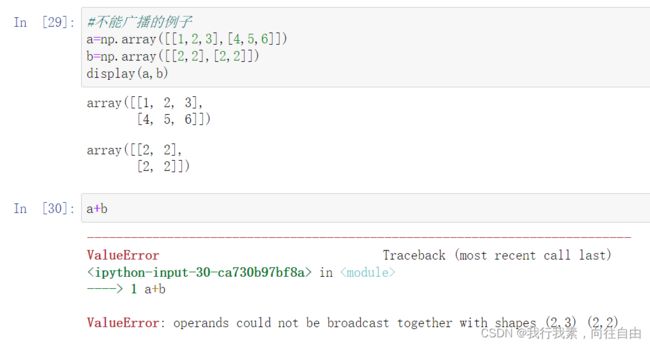
7.2 广播运算
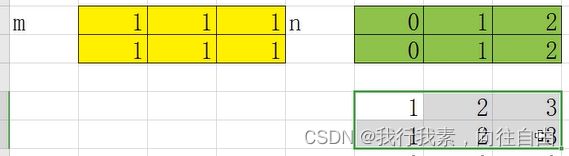
广播运算,数组中的每一个数都和一个数字进行运算。
【重要】 nd.array广播机制的两条规则:
- 规则一︰为缺失的维度补
- 规则二︰假定缺失元素用已有值填充(填充是拿整体填充,不可以只拿一部分,比如2行2列不可以扩充到2行3列只能2行4列或其他)


8.矩阵运算
a*b ==> 对应位置相乘
a.dot(b) ==> 矩阵相乘(一行乘以一列) 或者np.dot(a,b)

9.numpy排序
9.1 快速排序
np.sort()与ndarray.sort()都可以,但有区别:
- np.sort()不改变输入
- arr.sort()本地处理,不占用空间,但改变输入
 9.2 部分排序
9.2 部分排序
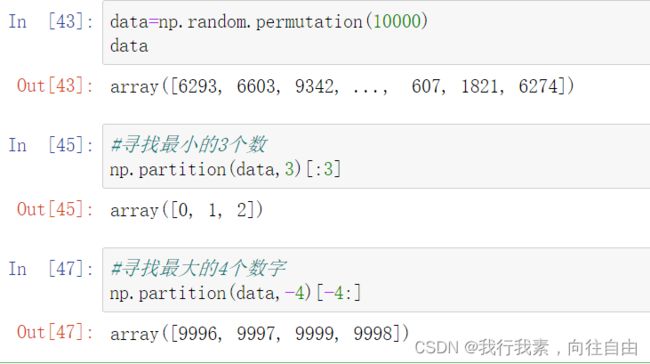
np.partition(a,k)
有的时候我们不是对全部数据感兴趣,我们可能只对最小或最大的一部分感兴趣。
- 当k为正时,我们想要得到最小的k个数
- 当k为负时,我们想要得到最大的k个数