谈谈softmax中常出现的温度系数 T (τ)
2022-4-1, 今天再回首来看这篇文章,发现自己写的非常局限,并且基本是在拾人牙慧,缺乏自己的思考与提炼。在阅读了更多文章和做实验进行一些思考之后,重写了这篇博客,主要从对比学习、知识蒸馏、分类训练来谈谈自己对于温度系数的理解。
前因
许多计算机视觉任务中,我们都看到作者会在原始的softmax损失基础上额外增加一个温度系数T,但很少做相关的解释,并且任务不同,取值的范围也不同。这篇博客,浅谈一下我遇到过的应用温度系数T的情况与原理。
实操
首先直接从softmax本身出发,温度系数T主要是用来调整logits-softmax曲线的平滑程度。假设目前有一个3分类任务,网络输出的logits为[1,2,3],groundtruth为[0,0,1]也就是类别2。
① 如果不使用τ,或者说τ=1,那么softmax的结果为:
import torch
import torch.nn as nn
import torch.nn.functional as F
criterion = nn.CrossEntropyLoss()
x = torch.Tensor([[1,2,3]])
y = torch.Tensor([2]).type(torch.long)
t = 1
out = F.softmax(x/t, dim=1)
print(out)
loss = criterion(x,y)
print(loss)
# 输出
tensor([[0.0900, 0.2447, 0.6652]])
tensor(0.4076)
那么此时计算出来的softmax概率为[0.0900, 0.2447, 0.6652],loss为0.4076 (-log(0.6652))。
② 而τ=0.5时:
# 输出
tensor([[0.0159, 0.1173, 0.8668]]) # softmax概率
tensor(0.1429) # loss
③ τ=0.1:
# 输出
tensor([[2.0611e-09, 4.5398e-05, 9.9995e-01]]) # softmax概率
tensor(4.5418e-05) # loss
观察:随着T的减小,softmax输出各类别之间的概率差距越大(陡峭),从而导致loss变小;同样,当增大T,softmax输出的各类别概率差距会越来越小(平滑),导致loss变大。
理解
在不同任务场景中,温度系数往往起着不同的作用。
先谈谈知识蒸馏,在进行知识蒸馏时,会对teacher网络的softmax输出除以一个T得到soft target,然后student网络的softmax输出同样会除以一个T得到logits,计算交叉熵,而这个T的取值通常大于1。为什么需要除以一个温度系数T呢?
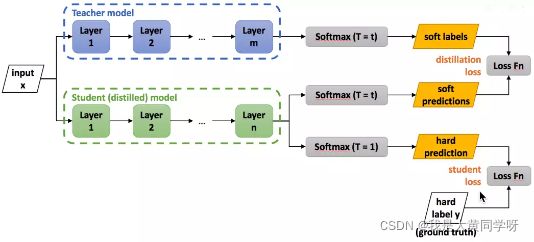
当然,这么做肯定是在实验上取得了更好的性能,但其背后的原因怎么理解呢?首先,蒸馏的本质是让学生网络去学习教师网络的泛化能力(通过soft target传递),由于训练好的模型本身会出现过度自信的问题(softmax输出的概率分布熵很小),所以除以一个大于1的T,让分布变得平滑,来放大这种类别相似信息。
具体可以参考这篇文章:https://zhuanlan.zhihu.com/p/102038521
接下来,我们再谈谈对比学习(用于自监督学习)中的温度系数,对比学习中最常用的一个loss莫过于NCE损失(跟softmax损失很像):
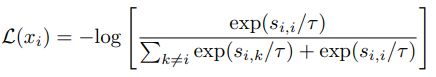
简单地理解,就是 s i , i s_{i,i} si,i就是anchor与正样本之间的相似度, s i , k s_{i,k} si,k就是anchor与负样本之间的相似度,优化目标就是让正样本之间的相似度越大越好,负样本之间的相似度越小越好(拉近正样本,推远负样本)。相似度最后都会除以一个温度系数T,这个T通常小于1。
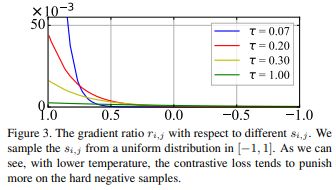
为什么在这里T又要小于1呢?首先对比学习应用这种损失形式本身就可以挖掘hard负样本,因为经过一个softmax操作后,会给距离更近的负样本更多的惩罚(可以从梯度分析)。而T可以控制对困难样本的惩罚程度,如下图所示:当T越小,softmax输出差异被放得越大,对困难负样本的惩罚更大(loss更大)。
但属于无监督学习的对比学习本身会遇到一种Uniformity-Tolerance Dilemma均匀性-容忍性困境,我们既希望得到一个分布均匀的表征空间(有文献说明这是对比学习效果好的关键),这期望我们将困难负样本推离地更远一些(T变小);但这些困难样本本身又可能属于潜在的"正样本"(拥有同样的前景),过度推远会起到反作用(T不能太小)。

所以在对比学习中,需要折中地选择温度系数的取值,这是一个非常重要的超参数。
来自Understanding the Behaviour of Contrastive Loss(CVPR21),
知乎解读:https://zhuanlan.zhihu.com/p/357071960
最后,我再谈谈我在实践过程中遇到的一些问题,比如我现在得到了一些伪标签或者一些噪声标签去进行一个分类任务。我对这批标签的信心不是很高,但又想通过它去学习一些知识 / 训练一个模型,这样也可以用到温度系数T。比如我把温度系数调低(T<1),拉大softmax的输出分布,降低loss,不过度优化模型。当然,相反的情况下,比如我们想增加模型的判别能力,也把温度系数提高(T>1)。
但是这些情况都可以通过其他更显示的策略来完成,所以这里也是仅供参考。