机器学习经典算法、如何选择最佳机器学习算法、超参数调优
经典算法
所谓“工欲善其事必先利其器”,要解决问题,就要有好的算法。
Scikit-Learn库中的几种经典机器学习算法:
一、K最近邻(KNN)
这个算法思路特别简单,就是随大流。对于需要贴标签的数据样本,他总是会找几个和自己离得最近的样本,也就是邻居,看看邻居是什么标签。如果他的邻居中的大多数样本都是某一类样本,他就认为自己也是这样一类样本。参数k,就是邻居的个数,通常是3,5,7,等不超过20的数字。
在机器学习算法中,常用的距离计算公式包括欧式距离和曼哈顿距离
所以,KNN算法的结果和K值的取值有关系,要注意的是,KNN要找的邻居都已经是“站好队的人”,也就是已经正确分类的对象。
下面进行实战:对心脏病数据的进行推断客户是否有心脏病:
1.导入数据:
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
df_heart = pd.read_csv("heart.csv") # 读取文件
df_heart.head() # 显示前5行数据

2.查看患病个数:
import matplotlib.pyplot as plt
import seaborn as sns #导入seaborn画图工具箱
sns.countplot(x="target", data=df_heart, palette="bwr")
plt.show()

3.对某些特征转换为数值类型的哑变量:
a = pd.get_dummies(df_heart['cp'], prefix = "cp")
b = pd.get_dummies(df_heart['thal'], prefix = "thal")
c = pd.get_dummies(df_heart['slope'], prefix = "slope")
frames = [df_heart, a, b, c]
df_heart = pd.concat(frames, axis = 1)
df_heart.head()
df_heart = df_heart.drop(columns = ['cp', 'thal', 'slope'])
df_heart.head()

4.划分训练集和测试集:
# 构建特征和标签集
y = df_heart.target.values
X = df_heart.drop(['target'], axis = 1)
from sklearn.model_selection import train_test_split # 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2,random_state=0)
5.进行特征缩放:
# 进行特征缩放
from sklearn import preprocessing
scaler = preprocessing.MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
6.模型训练:
from sklearn.neighbors import KNeighborsClassifier # 导入kNN算法
k = 5 # 设定初始K值为5
kNN = KNeighborsClassifier(n_neighbors = k) # kNN模型
kNN.fit(X_train, y_train) # 拟合kNN模型
y_pred = kNN.predict(X_test) # 预测心脏病结果
from sklearn.metrics import (accuracy_score, f1_score, average_precision_score, confusion_matrix) # 导入评估标准
print("{}NN 预测准确率: {:.2f}%".format(k, kNN.score(X_test, y_test)*100))
print("{}NN 预测F1分数: {:.2f}%".format(k, f1_score(y_test, y_pred)*100))
print('kNN 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

7.寻找最佳K值
# 寻找最佳K值
f1_score_list = []
acc_score_list = []
for i in range(1,15):
kNN = KNeighborsClassifier(n_neighbors = i) # n_neighbors means k
kNN.fit(X_train, y_train)
acc_score_list.append(kNN.score(X_test, y_test))
y_pred = kNN.predict(X_test) # 预测心脏病结果
f1_score_list.append(f1_score(y_test, y_pred))
index = np.arange(1,15,1)
plt.plot(index,acc_score_list,c='blue',linestyle='solid')
plt.plot(index,f1_score_list,c='red',linestyle='dashed')
plt.legend(["Accuracy", "F1 Score"])
plt.xlabel("K value")
plt.ylabel("Score")
plt.grid('false')
plt.show()
kNN_acc = max(f1_score_list)*100
print("Maximum kNN Score is {:.2f}%".format(kNN_acc))

8.结论
当K=3时,F1分数达到89.86%,虽然K=7、8时也能达到88%,但是此时的F1分数不如k=3高。
KNN算法在寻找最佳邻居时,要将余下所有的样本都遍历一遍,以确定谁和她最近,因此,如果数据量特别大,他的计算成本还是比较高的。
二、支持向量机(SVM)
支持向量机有良好的数学模型做支撑,因此收到学术界和工程界人士的共同喜爱。
超平面:就是用于特征空间根据数据的类别切分出来的分界平面。
支持向量:就是离当前超平面最近的数据点。
目前的特征空间中以下3条线:
这三条线,由线性函数和其权重、偏置的值所确定:
H0=w·x+b=0
H1=w·x+b=1
H2=w·x+b=-1
然后计算支持向量到超平面的垂直距离,并通过机器学习算法参数w和b,将距离最大化。这和线性回归寻找最有函数的斜率和截距的过程很相似。
下面用SVM算法来解决同样的问题:
from sklearn.svm import SVC # 导入SVM分类器
svm = SVC(random_state = 1)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test) # 预测心脏病结果
svm_acc = svm.score(X_test,y_test)*100
print("SVM 预测准确率:: {:.2f}%".format(svm.score(X_test,y_test)*100))
print("SVM 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('SVM 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

普通的SVM分类超平面只能应对线性可分的情况,对于非线性的分类,SVM要通过核方法解决。他的思路是:首先通过某种非线性映射(核函数)对特征粒度进行细化,将原始数据的特征嵌入合适的更高维度特征空间,然后,利用通用的线性模型在这个新的空间中分析和处理模式,这样,将在二维上线性不可分的问题在多维上变得线性可分,那么SVM就可以在此基础上找到最优分割超平面。
三、朴素贝叶斯(NB)
它是一个通过条件概率及逆行分类的算法 。基本原理:它会假设每个特征都是相互独立的,然后计算每个类别下的各个特征的条件概率。
下面用朴素贝叶斯来解决心脏病的预测问题:
from sklearn.naive_bayes import GaussianNB # 导入朴素贝叶斯模型
nb = GaussianNB()
nb.fit(X_train, y_train)
y_pred = nb.predict(X_test) # 预测心脏病结果
nb_acc = nb.score(X_test,y_test)*100
print("NB 预测准确率:: {:.2f}%".format(svm.score(X_test,y_test)*100))
print("NB 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('NB 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

效果还不粗。基本上,朴素贝叶斯是基于现有特征的概率对输入进行分类的,它的速度相当快,当没有太多数据并且需要快速得到结果时,朴素贝叶斯算法可以说是解决分类问题的良好选择。
四、决策树(DT)
决策树:可以应用于回归或分类问题,所以有时候也叫分类与回归树。这个算法简单直观,很容易理解,它有点像是将一大堆的if……else语句进行连接,直到最后得到想要的结果。算法中的各个节点是根据训练数据集中的特征形成的,特征节点的选择不同时,可以生成很多不一样的决策树。
1.熵和特征节点的选择
熵:度量者信息的不确定性,信息的不确定性越大,熵越大,信息熵和事件发生的概率成反比。
- 信息熵代表随机变量的复杂度,也就是不确定性。
- 条件熵代表某一个条件下,随机变量的复杂度。
- 信息增益等于信息熵减去条件熵,它代表了在某个条件下,信息复杂度减少的程度。
如果一个特征从不确定性到确定,这个过程对结果影响比较大的话,就可以认为特征的分类能力比较强。那么先根据这个特征进行决策之后,对于整个数据集而言,熵减少的多,也就是信息增益最大。
2.决策树的深度和剪枝
决策树以下特点:
- 由于if……else可以无限制地写下去,因此,针对任何训练集,只要树的的深度足够,决策树肯定能够达到100%的准确率
- 决策树非常容易过拟合,也就是说,在训练集上,只要分的足够细,就能的到100%的正确结果,然而在测试集上,准确率会显著下降。
解决的方法是为决策树进行剪枝,有以下方式:
- 先剪枝:分支的过程中,熵减少的量小于某一个阈值时,就停止分支的创建。
- 后剪枝:先创建出完整的决策树,然后尝试消除多余的节点。
决策树可以直接处理非数值型数据,不需要及逆行哑变量的转换,甚至可以直接处理含缺失值的数据。
缺点:对于多特征的复杂分类问题效率很一般,而且容易过拟合,节点很深的树学习到高度不规则的模式,造成较大的方差,泛化能力弱,决策树算法处理连续变量问题时效果也不太好。
下面用决策树算法解决心脏病的预测问题:、
from sklearn.tree import DecisionTreeClassifier # 导入决策树分类器
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
dtc_acc = dtc.score(X_test, y_test)*100
y_pred = dtc.predict(X_test) # 预测心脏病结果
print("Decision Tree Test Accuracy {:.2f}%".format(dtc_acc))
print("决策树 预测准确率:: {:.2f}%".format(dtc.score(X_test, y_test)*100))
print("决策树 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('决策树 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

单纯的使用决策树算法时的预测准确率和F1分数相对于其他的算法偏低。
五、随机森林
随机森林是一种强壮 且是用的机器学习算法,它是在决策树的基础上衍生而成的。决策树和随机森林的关系就是树和森林的关系。通过对原始训练样本的抽样,以及对特征节点的选择,我们可以得到很多课不同的树。
随机森林的核心:或许每棵树都是一个非常糟糕的预测器,但是当我们将很多棵树的预测值集中在一起考量时,很有可能会得到一个好的模型。
在Sklearn的随机森林分类器中,可以设定一些的参数如下:
- n_estimators:要生成的树的数量
- criterion:信息增益指标,可选择gini或者entropy。
- bootstrap:可选择是否使用bootstrao方法取样,True或者False。如果选择了False,则所有的树都基于原始数据集生成。
- max_features:通常由算法默认确定,对于分类问题,默认值是总特征数的平方根,即如果一共有9个特征,分类器会随机选取其中3个。
下面使用随机森林算法解决心脏病的预测问题:
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
rf = RandomForestClassifier(n_estimators = 1000, random_state = 1)
rf.fit(X_train, y_train)
rf_acc = rf.score(X_test,y_test)*100
y_pred = rf.predict(X_test) # 预测心脏病结果
print("随机森林 预测准确率:: {:.2f}%".format(rf.score(X_test, y_test)*100))
print("随机森林 预测F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('随机森林 混淆矩阵:\n', confusion_matrix(y_pred, y_test))

随机森林算法广泛适用于各种问题,尤其是针对浅层的机器学习任务,随机森林算法很受欢迎。
六、如何选择最佳机器学习算法
没有任何一种机器学习算法,能够做到针对任何数据集都是最佳的。
通常,拿到一个数据集后,会根据一系列的考量因素进行评估。这些因素包括:要解决的问题的性质、数据集的大小、数据集特征、有无标签等,有了这些信息后,再来寻找适合的算法。
下面是逻辑回归算法解决心脏病的预测问题的代码:
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train,y_train)
y_pred = lr.predict(X_test) # 预测心脏病结果
lr_acc = lr.score(X_test,y_test)*100
lr_f1 = f1_score(y_test, y_pred)*100
print("逻辑回归测试集准确率: {:.2f}%".format(lr_acc))
print("逻辑回归测试集F1分数: {:.2f}%".format(lr_f1))
print('逻辑回归测试集混淆矩阵:\n', confusion_matrix(y_test,y_pred))

下面输出所有这些算法针对心脏病预测的准确率直方图:
methods = ["Logistic Regression", "kNN", "SVM",
"Naive Bayes", "Decision Tree", "Random Forest"]
accuracy = [lr_acc, kNN_acc, svm_acc, nb_acc, dtc_acc, rf_acc]
colors = ["orange","red","purple", "magenta", "green","blue"]
sns.set_style("whitegrid")
plt.figure(figsize=(16,5))
plt.yticks(np.arange(0,100,10))
plt.ylabel("Accuracy %")
plt.xlabel("Algorithms")
sns.barplot(x=methods, y=accuracy, palette=colors)
plt.grid(b=None)
plt.show()

再绘制各种算法的混淆矩阵:
# 绘制各算法的混淆矩阵
from sklearn.metrics import confusion_matrix
y_pred_lr = lr.predict(X_test)
kNN3 = KNeighborsClassifier(n_neighbors = 3)
kNN3.fit(X_train, y_train)
y_pred_kNN = kNN3.predict(X_test)
y_pred_svm = svm.predict(X_test)
y_pred_nb = nb.predict(X_test)
y_pred_dtc = dtc.predict(X_test)
y_pred_rf = rf.predict(X_test)
cm_lr = confusion_matrix(y_test,y_pred_lr)
cm_kNN = confusion_matrix(y_test,y_pred_kNN)
cm_svm = confusion_matrix(y_test,y_pred_svm)
cm_nb = confusion_matrix(y_test,y_pred_nb)
cm_dtc = confusion_matrix(y_test,y_pred_dtc)
cm_rf = confusion_matrix(y_test,y_pred_rf)
plt.figure(figsize=(24,12))
plt.suptitle("Confusion Matrixes",fontsize=24)
plt.subplots_adjust(wspace = 0.4, hspace= 0.4)
plt.subplot(2,3,1)
plt.title("Logistic Regression Confusion Matrix")
sns.heatmap(cm_lr,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.subplot(2,3,2)
plt.title("K Nearest Neighbors Confusion Matrix")
sns.heatmap(cm_kNN,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.subplot(2,3,3)
plt.title("Support Vector Machine Confusion Matrix")
sns.heatmap(cm_svm,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.subplot(2,3,4)
plt.title("Naive Bayes Confusion Matrix")
sns.heatmap(cm_nb,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.subplot(2,3,5)
plt.title("Decision Tree Classifier Confusion Matrix")
sns.heatmap(cm_dtc,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.subplot(2,3,6)
plt.title("Random Forest Confusion Matrix")
sns.heatmap(cm_rf,annot=True,cmap="Blues",fmt="d",cbar=False)
plt.show()
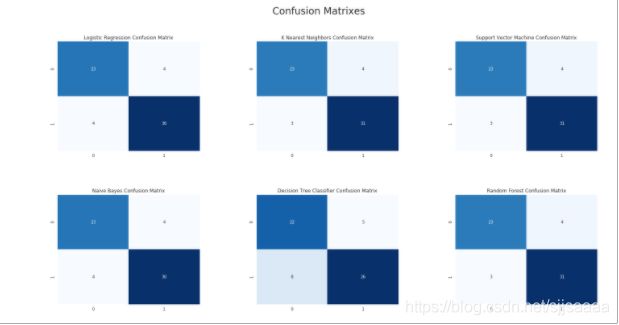
从图中可以看出,KNN和随机森林这两种算法中“假负”的数目为3,也就是说本来灭有心脏病,却判定为有心脏病的客户有3人;而假正的数目为4,也就是说本来有心脏病,判定为没有的心脏病的客户有4人。
七、用网格搜索超参数调优
内部参数是算法内部的权重和偏置,而超参数是算法的参数,例如逻辑回归中的C值、神经网络的层数和优化器、KNN中的K值,都是超参数。
算法的内部参数,是通过梯度下降自动优化,而超参数通常是依据经验手工调整。
利用Sklearn的网格搜索功能,可以为特定机器学习算法找到每一个超参数指定范围内的最佳值。
下面使用网格搜索功能进一步优化随机森林算法的超参数,看看预测准确率有没有能进一步提升的空间:
from sklearn.model_selection import StratifiedKFold # 导入K折验证工具
from sklearn.model_selection import GridSearchCV # 导入网格搜索工具
kfold = StratifiedKFold(n_splits=10) # 10折验证
rf = RandomForestClassifier() # 随机森林
# 对随机森林算法进行参数优化
rf_param_grid = {"max_depth": [None],
"max_features": [3, 5, 12],
"min_samples_split": [2, 5, 10],
"min_samples_leaf": [3, 5, 10],
"bootstrap": [False],
"n_estimators" :[100,300],
"criterion": ["gini"]}
rf_gs = GridSearchCV(rf,param_grid = rf_param_grid, cv=kfold,
scoring="accuracy", n_jobs= 10, verbose = 1)
rf_gs.fit(X_train, y_train) # 用优化后的参数拟合训练数据集

在GPU的加持之下,整个540次拟合只用了1.3分钟。
下面使用找到的最佳参数进行预测:
from sklearn.metrics import (accuracy_score, confusion_matrix)
y_hat_rfgs = rf_gs.predict(X_test) # 用随机森林算法的最佳参数进行预测
print("参数优化后随机森林测试准确率:", accuracy_score(y_test.T, y_hat_rfgs))
![]()
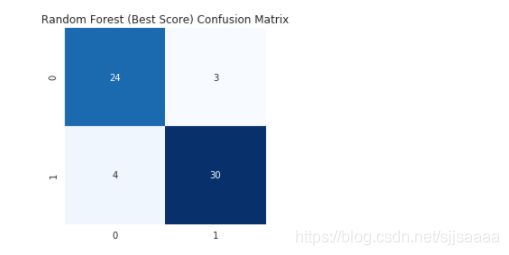
参数优化后随机森林的混淆矩阵:
cm_rfgs = confusion_matrix(y_test,y_hat_rfgs) # 显示混淆矩阵
plt.figure(figsize=(4,4))
plt.title("Random Forest (Best Score) Confusion Matrix")
sns.heatmap(cm_rfgs,annot=True,cmap="Blues",fmt="d",cbar=False)
如果得到了好的结果,就能把参数输出来,输出最优模型的属性就行:
print("最佳参数组合:",rf_gs.best_params_)

这就是网格搜索帮我们找到的随机森林算法的最佳参数组合。
小结
- KNN——通过向量在空间中的距离来为数据样本分类。
- SVM——一种使用核函数扩展向量空间维度,并力图最大化分割超平面的算法。
- 朴素贝叶斯——这种算法应用概率建模原理,假设数据集的特征都是彼此独立的。
- 决策树——类似于20个问题的游戏,个人能力虽弱,却能够被继承出多种更优秀的算法。
- 随机森林——通过Bootstrap取样形成不同的训练集,并进行特征的随机抽取,生成多颗数,然后通过结果集成,来进行分类预测。
通过网格搜索,还可以在大量参数的相互结合中找到最适合当前数据及的最佳参数组合。