sift算法原理,按步骤记录
sitf算法是一种描述图像特征的,重要的,基础的方法。主要由以下几个步骤构成:
0.尺度空间理论
尺度空间理论认为,人眼在认知画面时,在不同的尺度上使用的是不同特征,例如观察树叶时使用的是小尺度特征,观察大树时则是一个整体,因此sitf算法使用高斯模糊来构造大尺度特征。
提取的特征可能是某些角点、某些边缘,相似的图片或能检测出大量相同特征,可以用于物体的识别,图像的匹配等。
1.构造尺度空间——高斯金字塔
sift的第一步便是构建图像在每个尺度上的画面,具体为对图像做不同程度的高斯模糊,然后降采样,构建一组从大到小的高斯金字塔,如图所示:
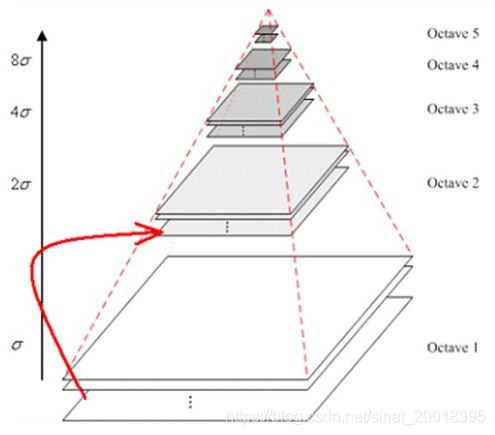
具体为:每一组金字塔都对应着相同的缩放比例,以及高斯模糊标准差 σ \sigma σ。
步骤如下:
- 定义高斯金字塔的组数:
O = [ l o g 2 ( m i n ( W , H ) ) ] − t O=[log_{2}(min(W,H))]-t O=[log2(min(W,H))]−t
W , H W,H W,H是图像宽高, t t t是最小尺度的图像尺寸,如设置3x3为最小尺寸, t = 3 t=3 t=3,相同尺寸图像视为一组
- 计算每一组,组内每一层的标准差(后面统称为“尺度”):
σ ( o , s ) = σ 0 ∗ 2 o + S s \sigma (o,s)=\sigma _{0}*2^{o+\frac{S}{s}} σ(o,s)=σ0∗2o+sS o 全 是 小 写 o全是小写 o全是小写
s是层的序号,S是每组的层数, σ 0 \sigma _{0} σ0是初始尺度,根据lowe的论文, σ 0 = 1.6 \sigma _{0}=1.6 σ0=1.6
当前组的每一层 σ \sigma σ是上一组对应层 σ \sigma σ的两倍
- 对原图使用第0组高斯模糊,生成第0组图像
- 对第0组图像的倒数第二层隔点降采样生成第1组的底层图像(也可以使用倒数第三层)
“这样可以保持图像的尺度连续性”??
- 对第1组的底层图像使用第1组的高斯模糊,生成第1组图像
- 同样依次生成每一组图像
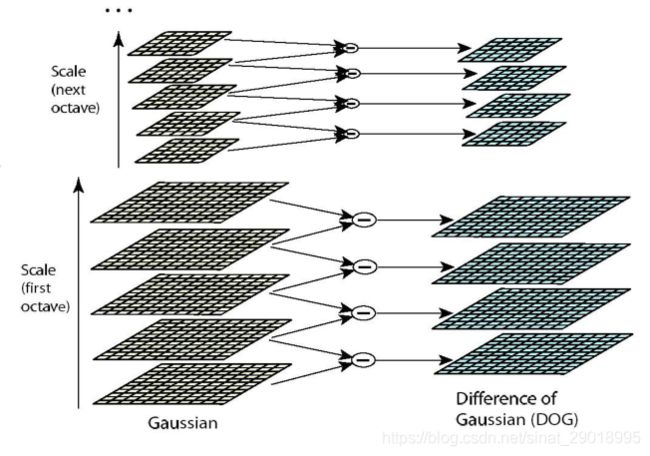
2.更好的DOG金字塔
sift点是由DOG空间的局部极值点组成的,关键点的初步探查是通过同一组内各DoG相邻两层图像之间比较完成的,DOG空间实际上就是两层高斯模糊相减,这个操作使得sift有尺度不变性质。
继续步骤:
- 计算-1组图像——将原图放大2倍,同样计算 σ \sigma σ和高斯模糊
lowe认为第0层做了高斯之后损失了细节,需要对图像做2倍扩展,增加信息。
放大方式可以使用任意算法,如bilinear
- 将相邻两层的高斯金字塔相减,生成DOG金字塔
后面会提到,1层特征点需要3层DOG图像,也就是需要4层高斯图像
n层特征点需要n+2层DOG,n+3层高斯
3.获取局部极值点
- 在三层DOG结构中,用3x3x3的窗搜索出中心点大于所有其它点,或小于所有其它点的点作为极值点。

通过尺度来提取特征点,可使特征具有缩放的不变性
-
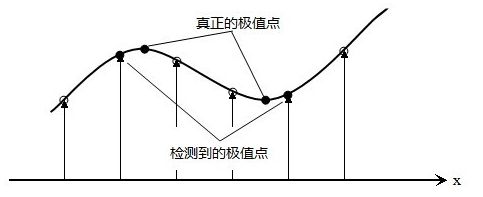
获取精确极值点
图像中的点是离散点,而真正的特征点可能不在图像的某个像素位置,lowe通过对DOG图像做曲线拟合,修正极值点 x , y , σ x,y,\sigma x,y,σ的值,找到最佳的极值点。
这一步的做法是:对极值点处的图像做泰勒展开,然后求导,导数等于0的地方就是真正的极值点
极值点求解公式:
X ^ = − ∂ 2 D − 1 ∂ x 2 ∂ D ∂ x \widehat{X} = - \frac{\partial^2 D^{-1}}{\partial x^2}\frac{\partial D}{\partial x} X =−∂x2∂2D−1∂x∂D 拟合公式为:
D ( X ^ ) = D + 1 2 ∗ ∂ D T ∂ X ∗ X ^ , X = ( x , y , σ ) T D(\widehat{X}) = D + \frac{1}{2} * \frac{\partial D^{T}}{\partial X}*\widehat{X} , X = (x,y,\sigma)^{T} D(X )=D+21∗∂X∂DT∗X ,X=(x,y,σ)T
研究表明所有结果小于0.04的点都可忽视(像素范围[0,1])
其中D是该层的DOG图像, X ^ \widehat{X} X 是修正值,是相对于真正极值点的偏移量
Lowe在拟合修正的结果上再做拟合修正,一共做了五次
感觉很难说清楚,详细可见 :关键步骤的说明、极值点的精确定位
4.去除边缘效应
DOG算子在图像边缘处有比较强的边缘效应

- 去除边缘效应产生的多余点
T r ( H ) 2 D e t ( H ) < ( r + 1 ) 2 r \frac{Tr(H)^{2}}{Det(H)}<\frac{(r+1)^{2}}{r} Det(H)Tr(H)2<r(r+1)2
T r ( H ) = D x x + D y y Tr(H) = D_{xx}+D_{yy} Tr(H)=Dxx+Dyy
D e t ( H ) = D x x D y y − D x y 2 Det(H)=D_{xx}D_{yy}-D_{xy}^{2} Det(H)=DxxDyy−Dxy2
满足该不等式的点保留,不满足的丢弃,建议 r = 10 r = 10 r=10
主要是去除边缘点,保留角点,认为边缘点对噪声有较差的鲁棒性
数学推导:SIFT算法原理(2)-极值点的精确定位
图像的二阶导数计算
5.特征点构造
-
计算邻域内每个像素的梯度
我们通过极值点的邻域总方向,来确定极值点的梯度方向,邻域半径为 3 ∗ 1.5 ∗ σ 3*1.5*\sigma 3∗1.5∗σ
首先,对邻域中的每个点计算梯度幅值和方向:
m ( x , y ) = ( L ( x + 1 , y ) − L ( x − 1 , y ) ) 2 + ( L ( x , y + 1 ) − L ( x , y − 1 ) ) 2 m(x,y)=\sqrt {(L(x+1,y)-L(x-1,y))^2 + (L(x,y+1)-L(x,y-1))^2} m(x,y)=(L(x+1,y)−L(x−1,y))2+(L(x,y+1)−L(x,y−1))2
θ ( x , y ) = t a n − 1 ( ( L ( x + 1 , y ) − L ( x − 1 , y ) ) / ( L ( x , y + 1 ) − L ( x , y − 1 ) ) ) \theta (x,y)=tan^{-1} ((L(x+1,y)-L(x-1,y))/(L(x,y+1)-L(x,y-1))) θ(x,y)=tan−1((L(x+1,y)−L(x−1,y))/(L(x,y+1)−L(x,y−1)))
这些步骤应该在对应高斯层进行
-
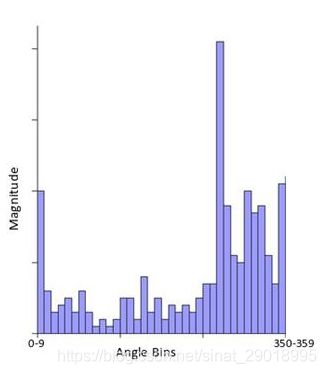
计算梯度直方图
梯度直方图将360度的角度范围平均分成36个方向,统计极值点邻域内,每个梯度方向的点的个数,直方图最大值的索引方向为主方向,保留峰值大于主方向峰值80%的方向作为该关键点的辅方向。
-
计算(4x4)x8=128维描述子
(1)根据主方向旋转8x8邻域,坐标变换矩阵为:
( x ^ y ^ ) = ( c o s θ − s i n θ s i m θ c o s θ ) ( x y ) \begin{pmatrix} \widehat{x} \\ \widehat{y} \end{pmatrix} = \begin{pmatrix} cos\theta & -sin\theta \\ sim\theta & cos\theta \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix} (x y )=(cosθsimθ−sinθcosθ)(xy) 由此,我们可以获得旋转后采样点落在子区域的下标:
( x n y n ) = 1 3 σ o ( x ′ y ′ ) + d 2 \begin{pmatrix} x^{n}\\ y^{n} \end{pmatrix} = \frac{1}{3\sigma _{o}}\begin{pmatrix} x' \\ y' \end{pmatrix} + \frac{d}{2} (xnyn)=3σo1(x′y′)+2d 其中 σ o \sigma_{o} σo为所在层的尺度,d=4是区域数, x n , y n x^n,y^n xn,yn是区域下标。
注意:由于图像旋转后,像素坐标基本不在整数像素点上,因此必须使用 【双线性插值】 重新获得旋转后区域中的像素。
(2)重新获取邻域,半径为:
r a d i u s = 3 σ o ∗ 2 ∗ 5 + 1 2 radius=\frac{3\sigma_{o}*\sqrt{2}*5 + 1}{2} radius=23σo∗2∗5+1
(3)计算像素梯度,乘以高斯权重,统计子区域直方图
其中a,b为极值点在高斯金字塔图像中的位置坐标,也就是图像坐标,x,y则是当前点与极值点的坐标差,m是该点梯度值,w是该像素经过权重处理后的梯度
邻域被划分为8x8个子区域,每个区域统计出8个方向的梯度直方图,所有梯度直方图结合成为128维特征向量,但并不是计算区域内每个点的梯度就足够了,为了获得更精确的结果,作者还将周围区域的像素点通过插值的方式纳入当前子区域的直方图统计中,这个下面会讲。
高斯权重的是为了防止位置微小的变化给特征向量带来很大的改变,并且给远离特征点的点赋予较小的权重,以防止错误的匹配
下方的蓝色圆就是高斯函数的覆盖范围,在圈外的像素梯度的权重基本为0
为了减少一个梯度幅值从一个格子漂移(shift)到另一个格子引起的描述子突变,需要对梯度值做三线性插值。也就是根据三维坐标计算距离周围格子的距离,按距离的倒数计算权重,将梯度幅值按权重分配到临近的格子里。
(4)梯度三线性插值
图像梯度需要经过三线性插值算出,比双线性插值多了一个角度维度。其中的原理很难说清除,这里我找到一张图

蓝色框是实际的像素点,我们需要比实际的半径范围还要大的区域来统计。
上图中红色圆圈标识出了目标子区域,该区域的8方向梯度直方图是由周围的四个蓝色的实际像素区域内的像素通过三线性插值统计得出,不论远近。
图中红点对红圈处某个方向的插值公式为:
其中dr,dc分别为周围某一点距离绿色区域中心的横向和纵向距离,do则是这个点的实际梯度方向与直方图中最近方向的角度(8方向直方图每个方向相隔45度,这里取最近的那个方向,这里的1指的是实际蓝色框的长度,但是对于角度,这个1指的是啥?是360?)
最后,还要把这个weight加到最绿框中邻近的那根直方图上。
因此,经过三线性插值后,得到的是它对相邻两个方向的贡献值,直方图是由这所有贡献值相加得到的
全部计算完成之后,我们就得到了4x4x8=128个方向H=(h1,h2,…,h128),最后对128维向量归一化。
非线性光照,相机饱和度变化对造成某些方向的梯度值过大,而对方向的影响微弱。因此设置门限值(向量归一化后,一般取0.2)截断较大的梯度值(大于0.2的则就令它等于0.2,小于0.2的则保持不变)。然后再进行一次归一化处理,提高特征的鉴别性。
至此,完成了对一个特征点的描述!
6.特征点匹配
由于穷举法匹配太慢,所以特征点使用的是kd树匹配,概括的说就是根据sift算子在128维空间的点,将空间一分为二、二分为四……,每次分割都将子空间分为两个更小的子空间,然后根据查询点的sift128维坐标,依次判断这个点在哪一个子空间中,是一种巧妙而快速的匹配点查找方法。
实际上kd树也很慢,在其基础上还发展出了很多快速算法。
- kd树的构造
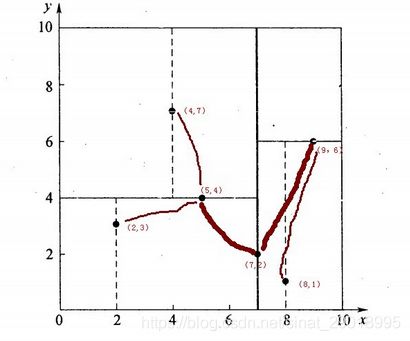
这里先在二维空间中演示,根据上图, 6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
-
确定:split域=x(初始分割方向)。具体是:6个数据点在x,y维度上的数据方差分别为39,28.63,所以在x轴上方差更大,故split域值为x;
-
确定:Node-data = (7,2)。具体是:根据x维上的值将数据排序,6个数据的横坐标中值(所谓中值,即中间大小的值)为7(也可以是5),所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7;
-
确定:左子空间和右子空间。具体是:分割平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
-
重复分割
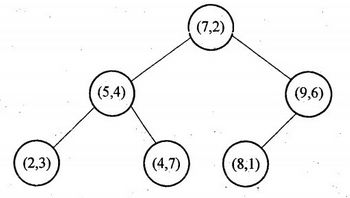
形成的kd树如图:
-
kd树匹配sift
现在,我们有一个sift特征点,如何在图中找到与它最接近的点呢?kd数匹配有正向和反向两个操作,先正向搜索到最末端的节点,这个节点不等于最终结果
- 假如我们有一个二维的点(2,4.5),发现它落在节点(7,2)的分割线左侧
- 是查询(5,4),发现它位于分割线的上侧
- 查询(4,7),发现它位于分割线的左侧,第一步查询完毕
- 计算与(4,7)的距离,发现大于和(5,4)的距离,于是以(2,4.5)为圆心,画一个过(5,4)的圆,发现圆接触到了(5,4)的另一个子区域
- 检查(2,3),发现(2,3)的距离更近,再画一个过(2,3)的圆,发现没有新的子区域与圆相交,因此确定了查找结果为(2,3)

有可能画的圆包含了非常多的子区域,这时候计算就很复杂了
实际上,我们计算的是128为空间,用于分割的是超平面和超圆,算法变得更加难以理解和复杂,在此不多深究,下次研究surf算子的时候再学习一下有什么改进算法。

详细理论:从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
一篇很详细的参考文档SIFT算法原理详解