【联邦学习安全综述】A Comprehensive Survey of Privacy-preserving Federated Learning: A Taxonomy, Review, and F
作为综述,本文提供了很多写作素材。
原文标题:A Comprehensive Survey of Privacy-preserving Federated Learning: A Taxonomy, Review, and Future Directions
索引
本文不局限于介绍了以下内容:
- 举例了机器学习的大规模应用;数据隐私泄漏的危机事件;数据保护法规
- 很多别的FL privacy-preserving综述 1.2节
- 主流隐私保护技术;隐私度量
- 联邦学习的优势
这里写目录标题
- 索引
- 2 联邦学习
-
- 主要研究方向
- 完整流程
- 分类
-
- 联邦迁移学习
- 用什么聚合
- 相关概念的区分
- 3 主要的 隐私保护 机制
-
- Encryption Techniques
-
- homomorphic encryption
- secret sharing
- secure multi-party computation
- Perturbation Techniques
-
- differential privacy
- Additive perturbation
- Multiplicative perturbation
- Anonymization Techniques
- Privacy-preserving Metrics
- 4 联邦学习的隐私保护
-
- Privacy Risks in FL
-
- 1 攻击者是谁?
- 2 被动or主动?
- 3 攻击发生阶段
- 4 什么形式的泄露
- 5 要窃取什么信息
- 防御措施
-
- Homomorphic encryption-based PPFL
- Secret sharing–based PPFL
- SMC-based PPFL
- Perturbation-based PPFL
- Hybrid PPFL
2 联邦学习
主要研究方向
(1) 高效学习:improving the efficiency and effectiveness of FL [24, 68, 87, 100, 120, 211, 213], (2) 抵御攻击 improving the security of FL to attacks that aim to undermine the integrity of FL models and degrade the model performance [9, 13, 185, 198], and (3) 保护训练集隐私 improving the privacy preservation of FL on private user data and avoiding privacy leakages [116, 137, 144, 193, 199].
完整流程
包括server初始化、client本地训练、global aggregation
分类
根据 data partitioning,可以分为 纵向FL、横向FL、混合FL(这一种对应的是联邦迁移学习)
这篇文章用符号表示的不错。
联邦迁移学习
分类
Based on the categorization of transfer learning [136], FTL methods can be divided into three categories [205]: instance-based FTL, feature-based FTL, and parameter-based FTL.
用什么聚合
聚合 gradient or weight? 优劣分析
gradient:更加容易收敛
weight:不需要每一轮都聚合一次,稍微安全一些
相关概念的区分
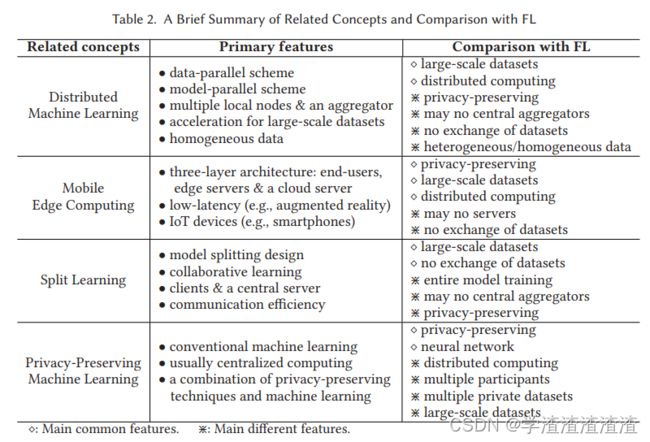
3 主要的 隐私保护 机制
介绍了主流的保护机制,并进行了优劣比较。
Encryption Techniques
主要有:homomorphic encryption, secret sharing, and secure multi-party computation.
homomorphic encryption
homomorphic encryption 还可以分为 partially homomorphic encryption (支持 additively homomorphic encryption [88] 或 multiplicative homomorphic encryption,不可以兼得) [134] and fully homomorphic encryption (supports both additive and multiplicative operations ).
比较:Compared with partially homomorphic encryption, fully homomorphic encryption provides stronger encryption but suffers from computation costs.
secret sharing
Secret sharing [156] is a cryptographic scheme where a secret key consisting of n shares can be reconstructed only if a sufficient number of shares are combined.
缺点:
However, these methods are vulnerable to the dishonest dealer or malicious participants.
secure multi-party computation
优劣:
As its advantages, (1) there is no requirement of trusted third-parties, (2) the tradeoff between data utility and data privacy is eliminated, and (3) a high accuracy is achieved.
The disadvantages are computational overhead and high communication costs.
Perturbation Techniques
In summary, perturbation techniques are simple, efficient, and usually do not require knowledge of the data distribution. However, perturbed data may be vulnerable to probabilistic attacks, and it is difficult to mitigate such risk without reducing the data utility.
differential privacy
分为:global differential and local differential privacy
Additive perturbation
This technique is simple and can preserve the statistical properties [86]. However, it may degrade the data utility and may be vulnerable to a noise reduction.
Multiplicative perturbation
Compared with the additive perturbation, multiplicative perturbation is more effective, because reconstructing the original data from the perturbed data of the multiplicative perturbation is more difficult [50].
Anonymization Techniques
主要有 k-anonymity, l-diversity, and t-closeness。
Privacy-preserving Metrics
分为: (1) privacy metrics for measuring the loss of privacy of a dataset.
(2) utility metrics for measuring the data utility of the protected data for data analysis purposes.
4 联邦学习的隐私保护
主要的保护方法有:encryption-based, perturbation-based, anonymization-based, and hybrid PPFL.
本章先分析 risks, 再提出解决方案。
Privacy Risks in FL
从5个角度分析面临的威胁
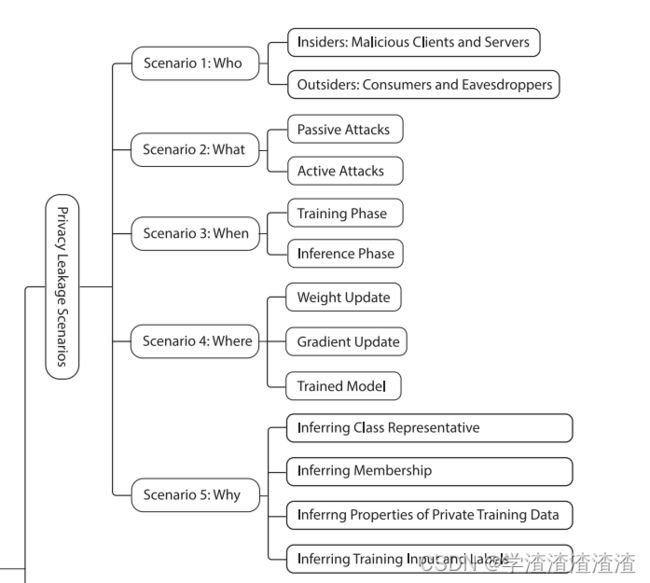
1 攻击者是谁?
internal actors (participating clients and the central server) and external actors (model consumers and eavesdroppers).
2 被动or主动?
With FL, passive attackers only observe computations (e.g., the weights, gradients, and final model) during the training and inference phases [123, 228], whereas active attackers can influence the FL system by manipulating the model parameters to achieve adversarial goals [129, 165].
3 攻击发生阶段
Training phase and inference phase
4 什么形式的泄露
Weight update, gradient update, and the final model
model-parameter-based attacks leak much more sensitive information than the query-based attacks.
5 要窃取什么信息
Inference attacks, including inference of class representatives, memberships , properties of training data, and training samples and labels.
然后他把每一类攻击都讲了一遍。
防御措施
有点类似第三章,但是是针对 FL 场景下做的。
Homomorphic encryption-based PPFL
一般而言, each participant calculates its local gradient using its local dataset, and then encrypts the local gradient, and sends the encrypted gradient to the server for aggregation.
但是具体方法还是有不同的改进
However, the homomorphic encryption utilized in these studies brings about a large communication and
computational overhead.
Secret sharing–based PPFL
SMC-based PPFL
However, the secure aggregation protocol used in this approach incurs significant communication costs. A challenge of SMC-based FL methods is to improve the computational efficiency, because significant computational resources are required to complete a training round in FL frameworks [147].
Perturbation-based PPFL
(1) global differential privacy-based, (2) local differential privacy-based, (3) additive perturbation-based, and (4) multiplicative perturbation-based PPFL methods.
本文对上述四种方法都做了介绍。
Hybrid PPFL
混合了上述几种方法,提出的一个完整的框架。