操作系统笔记——Linux系统实例分析、Windows系统实例分析(持续更新)
文章目录
- Linux进程管理
-
- Linux进程组成
- Linux进程链表
- Linux进程控制
-
- 用户进程创建与撤销
- 0,1,2号进程
- Linux进程切换
- Linux进程调度
- 内核同步
- Linux储存器管理
-
- 进程地址空间的管理
-
- 内核虚空间
- 用户空间进程管理
-
- vm_area_struct
- mm_struct
- 物理内存管理
-
- struct page
- 内存管理区
- 分区页框分配器与伙伴系统
- slab小内存分配器
- 虚拟地址转换
- 盘交换区与页面置换
- Linux文件系统
-
- Ext2磁盘数据结构
-
- 文件卷整体布局
- 超级块与块组描述符
- 位示图
- 数据区与目录文件,间接索引表
- 索引节点区与inode
-
- 硬链接计数
- 文件索引表
- 再论文件类型与索引节点
- Ext2主存数据结构
- 磁盘空间管理
- Linux虚拟文件系统
-
- VFS数据结构
-
- 超级块对象
- 索引节点对象inode
- 文件对象file
- 目录项对象dentry
- 进程相关结构
- 文件系统的注册与安装
- VFS系统调用
- Windows系统模型
-
- Windows体系结构
-
- 整体架构
- 核心态组件
- 硬件抽象层HAL
- Windows系统特点
- Windows系统机制
-
- 陷阱调度
-
- 中断优先级IRQL
- 延迟调用DPC
- 异步过程调用APC
- 执行体——对象管理器
-
- 对象结构
- 类型对象
- 在进程中管理对象
- 对象同步
-
- 内核同步——自旋锁
- 执行体同步
- Windows 2000/XP进程线程管理
-
- 进程和线程
-
- 进程对象
-
- 内核进程对象
- 执行体进程对象
- 整体结构
- 进程对象的服务
- 线程对象
-
- 线程对象结构
- 线程对象服务
- 线程调度
-
- 进程优先级
- 线程优先级
- 线程的状态
- 对称多处理机上的线程调度
- 线程优先级提升
- 线程同步
Linux进程管理
Linux内核基于Minix编写,现在的都是Linux发行版,是内核的自定义。
现代操作系统允许一个进程有多个执行流,即在相同的地址空间中可执行多个指令序列。每个执行流用一个线程表示,一个进程可以有多个线程。
Linux具体实现比较特别,Linux中严格来说是没有线程的,而是使用轻量级进程实现对多线程应用程序的支持,一个轻量级进程就是一个线程。
本章内容:

Linux进程组成
进程有两种状态,用户态和核心态。
这两种状态的根本区别在于切换了段地址。用户态的时候用的是用户栈,而核心态用的是核心栈。
状态的切换以及进程的切换都需要保存信息,其中就用到进程描述符

task_struct结构如下,图中仅列出关键的几个部分,实际上有更多:
- thread_info是进程的关键信息,又叫小描述符
- 略

每个进程都在内存中有一个进程核心栈,其和thread_info是放在一起的,总共占2页空间,核心栈在一端,thread_info在另一端。
task_struct通过thread_info指针访问核心栈,核心栈通过thread_info反向访问task_struct,是双向的。
具体到操作系统,操作系统通过esp获取thread_info地址,然后通过thread_info获取task_struct(PCB),即操作系统通过esp获取PCB信息。尤其是进程刚从用户态切换到核心态时,其核心栈为空,只要将栈顶指针减去8k,就能得到thread_info结构的地址。

- 可运行状态=运行态+就绪态
- 阻塞态分的比较细,下面逐一列出:
- 可中断的等待状态:进程睡眠等待系统资源可用或收到一个信号后,进程被唤醒。
- 不可中断的等待状态:进程睡眠等待一个不能被中断的事件发生。如进程等待设备驱动程序探测设备的状态。
- 暂停状态;
- 跟踪状态 ;
- 僵死状态 ;
- 死亡状态
Linux进程链表
Linux的链表都是list_head类型列表
全局的链表有:
- 所有进程链表tasks:链表头是0号进程,双向链表
- 可运行进程(TASK_RUNNING)链表run_list:按照它们的优先级可构建140个可运行进程队列(系统有140个优先级,非常细致)
- 等待进程链表。互斥等待访问临界资源的进程;非互斥等待的进程,所有进程都被唤醒wait_queue_t
这两个链表,每一个PCB都有:
- 子进程链表children
- 兄弟进程链表sibling
pid实际上是一种哈希(TODO)
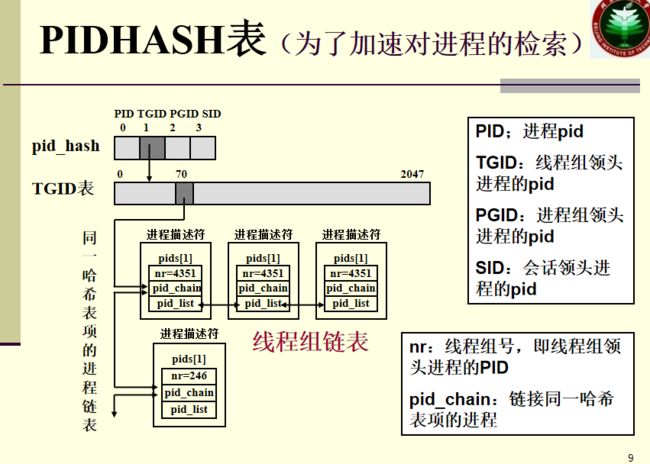
Linux进程控制
用户进程创建与撤销
Linux有三个创建进程的函数:
- fork。采用写时复制技术,复制全部资源,根据返回pid判断是否是子进程,不阻塞。
- vfork。共享资源,且阻塞父进程。
- clone。轻量级进程函数,用于实现Linux线程,可以选择共享哪些数据。
要想实现共享+并行,需要用fork+共享内存区+PV操作实现。
进程撤销:
- exit()系统调用只终止某一个进程/线程。
- exit_group()系统调用能终止整个线程组。
如果只将主进程exit,子进程保留,子进程就会变成孤儿进程。
此时会给孤儿分配养父,即init进程(1号,监控用户态进程),init进程定期会处理僵死的子进程。
0,1,2号进程
前面是用户空间进程的创建,内核有另一套函数。
内核空间的线程创建create_ kthread () / kthread_run()。内核里只有线程,因为内核本身就是root权限,不需要进行数据隔离。出于好听的原因,人们又喜欢把内核线程称作进程。
内核线程的任务一般是执行周期性执行的任务,如刷新磁盘高速缓存;交换出不用的页;维护网络连接等任务。相对的,用户线程高度自定义,不具有周期性。
- 0号进程是一切进程的根。0号进程就是一个内核线程,0号进程是所有进程的祖先进程,又叫idle进程或叫做swapper进程。每个CPU都有一个0号进程。
- 1号进程(init)是用户态进程的根。是由0号进程创建的内核线程init,负责完成内核的初始化工作。在系统关闭之前,init进程一直存在,它负责创建和监控在操作系统外层执行的所有用户态进程。
- 2号进程(kthreadd)负责创建内核线程。
使用ps查看进程信息。-eo自定义显示信息,显示pid,ppid,command信息。
可以看到,没有显示0号进程,而1号进程负责init任务与用户态进程创建,其父进程是0号进程,2号进程负责内核线程创建。这里显示的其他进程都是内核线程,任务各不相同,其父进程都是2号进程。

Linux进程切换
用户态进程之间可以切换。用户态进程到核心态也需要切换。这两种切换执行的思路类似:
这里需要注意,进程切换只能发生在核心态,毕竟用户怎么能掌握计算机运行的调度权呢?那问题来了,从核心态切到用户态很自然,那用户态怎么切到核心态呢?这就需要触发中断,发送一个信号给核心,然后核心再进行切换。
所以一个切换操作分如下流程:
- 需要先将用户态寄存器信息保存,送到核心栈
- 还有一些寄存器值被送到PCB的thread_struct 的 thread字段中(硬件上下文)
- 最后通过核心态进行进程切换,先切页目录表(换一个页目录段,换一个页表TODO),再切核心栈与硬件上下文(恢复寄存器)
Linux进程调度
Linux,无论是用户态还是核心态,都是可抢占的。
为了保证抢占的合理,需要搭配动态优先级。
进程调度类型:
- 先进先出的实时进程,时间片轮转的实时进程。基本优先数为1~99,优先级较高,费时较少
- 普通的分时进程。分时进程和批处理进程的基本优先数为100~139
实时进程调度时机:
- 被抢占了。出现了更高优先级的实时进程
- 走不动了。进程执行了阻塞操作,或者干脆停止运行或被杀死
- 自愿放弃。进程调用了sched_yield()自愿放弃处理机
- 轮转的实时系统中,时间片用完。
进程调度需要用到特殊的数据结构,其实就是前面的进程链表,是一维数组runqueues(TODO,TODO到底是一维数组还是链表?)。
一个CPU有140级全局可运行进程链表。
在时间片轮转系统中,还可以再分两类,一类是活动进程链表,一类是过期进程链表,各有140个队列。当活动进程都过期后,过期进程才可运行。避免低优先级进程没有机会运行(进程饥饿)
刚开始优先级动态计算复杂度比较高,所以引入了公平调度算法。

内核同步
不同内核线程使用一个内核,所以对于互斥资源就需要进行同步控制。核心思路就是保证临界区的同一时间只对应一个内核控制路径(?TODO)
同步方法很多,不止有信号量。

Linux储存器管理

进程地址空间的管理
内核虚空间
32位机器的进程寻址空间为4G。
进程的私有空间是3G,剩下1G是内核虚空间。
1G虚拟空间的前896M对应物理内存的前896M。前896MB的物理地址等于内核虚地址减去0xc0000000(3G)后128MB的虚拟空间比较特殊,是固定的分区,与用户。

用户空间进程管理
注意,这里针对的是3G的内存空间,是进程管理。而核心都是线程,不存在下面的管理机制。
针对3G的用户空间,Linux的管理机制如下图:
看着比较庞大,我们大致捋一下,你可能现在看不懂,但是看完后面两个结构的具体描述再回来看也是OK的:
- 从右往左看:实际上,一个进程的虚拟内存逻辑上是连续的,分为若干个区域。每一个区域都有一个vm_area_struct对应,这些vm_area_struct是以链表结构+红黑树结构组织的。
- 从左往右看:一个进程PCB通过一个mm_struct对虚拟空间进行宏观管理
- mm_struct和vm_area_struct就像是总分的关系一样,具体有什么联系?mm_struct指向vm_area_struct链表的头结点,指向其红黑树的根节点。而每一个vm_area_struct里面都有一个指针指向同一个mm_struct,用于快速返回mm_struct。

vm_area_struct
struct vm_area_struct {
struct mm_struct * vm_mm; 虚拟内存描述符,指向其对应的mm_struct
unsigned long vm_start; /*起始地址*/
unsigned long vm_end; /*结束地址*/
struct vm_area_struct *vm_next; /*单链表*/
struct rb_node vm_rb; /*红-黑树*/
struct file * vm_file; 映射文件时指向文件对象
……
}
结构里同时有红黑树指针和链表指针,说明vm area struct是同时具有两种组织方式。
红黑树是一种特殊的平衡二叉树,满足红黑树规则的n节点树,高度最多为 2 × l o g ( n + 1 ) 2\times log(n+1) 2×log(n+1)

mm_struct
内核线程不拥有mm_struct(本身就是线程,mm struct是针对进程的) 。
struct task_struct
{ // PCB
…
struct mm_struct *mm;
…
}
struct mm_struct {
struct vm_area_struct *mmap; /*单向链*/
struct rb_root mm_rb; /*指向红-黑树的根*/
pgd_t *pgd; /*指向页目录表*/
atomic_t mm_users; /*次使用计数器*/
atomic_t mm_count; /*主使用计数器*/
struct list_head mmlist; //双向链表
unsigned long start_code, end_code; /*可执行代码所占用的地址区间*/
……};
结构里有指向vm area struct链表的头指针,也有指向红黑树结构的指针。
说一下mm_users mm_count这两个计数器。
- mm_users记录共享mm_struct的轻量级进程数。初值为1(主线程),增加一个线程就+1(TODO)
- mm_count记录内核线程使用数。初值为0,mm若把mm_struct暂时借给一个内核线程使用,则mm_count值增1。
进程结束,mm_users和mm_count都为0时,这个mm_struct才能被释放。
物理内存管理
物理内存是连续的(假设4G)
页框0给bios用,从0x000a0000到0x000fffff(1M空间)给BIOS例程用。
Linux管理页框的时候,会跳过前1M的空间(BIOS空间,对应RAM)。剩下的页框,大小为4KB,每一个页框都有一个页框描述符,struct page。这些struct page以结构数组的形式放在mem_map数组中。
struct page
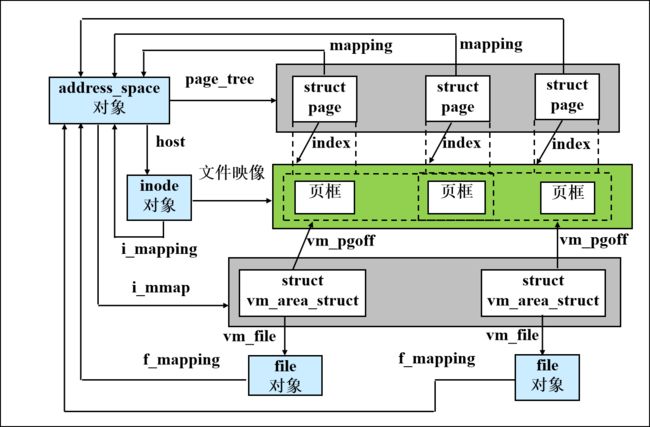
这个结构,mapcount是页框号。其余的字段,要注意private字段,和伙伴系统有关(后面)。还有mapping字段,和页高速缓存的核心数据结构,与文件的inode有关。
struct page {
unsigned long flags; /*页框状态标志P175*/
atomic_t _count; /*页框的引用计数*/
atomic_t _mapcount; /*页框号,可以索引到物理页框*/
unsigned long private; /*空闲时由伙伴系统使用*/
struct address_space *mapping;用于页高速缓存
pgoff_t index; 在页高速缓存中以页为单位偏移
struct list_head lru; 链入活动页框链表或非活动..
void *virtual; /*页框所映射的内核虚地址*/
};
内存管理区
整个4G内存被分成3块zone:
- ZONE_DMA:包含低于16MB的常规内存页框。用于对老式的基于ISA设备的DMA支持。0~15MB
- ZONE_NORMAL:包含高于16MB且低于896MB的常规内存页框。16MB~895MB,内核可以直接访问,用虚拟地址-3G即可得到物理内存。
- ZONE_HIGHMEM:包含从896MB-4G的高端物理页框。内核不能直接访问,后128+3G需要通过页管理机制寻址。
也就是说,大部分内存区域仅仅被一个zone结构管理:
这个结构里又出现了伙伴系统。
struct zone {
unsigned long free_pages; 空闲页框数
struct per_cpu_pageset pageset[NR_CPUS];
/*每CPU页框高速缓存,以满足CPU对单个页框的请求p177*/
struct free_area free_area[11];
/*伙伴系统中的11个空闲页框链表*/
struct list_head active_list; /*活动页框链表,存放最近正被访问的页框*/
struct list_head inactive_list; /*非活动页框链表,存放最近未被访问的页框*/
…….};
分区页框分配器与伙伴系统
free_area是11个长度的数组。对应 2 0 − 2 10 2^0-2^{10} 20−210长度。有的程序会需要连续的物理空间,而这个数组就负责统计整个zone里的连续物理空间,记录在数组中。
具体来说,比如数组中的8号位,实际上是一个链表头指针。指向一个链表,每一个链表节点都是起始页框描述符,这意味着这个链表对应着n段长度为8的连续物理空间。
而这里也揭示了private有什么用,private表示的是2的幂,如果是4就是16长度,3就是8长度。

伙伴系统就是基于分区页框分配器的。
假设要请求一个具有8个连续页框的块,该算法先在8个连续页框块的链表中检查是否有,如果没有,就在16个连续页框块的链表中找,如果找到,就把这16个连续页框分成两等份,一份用来满足请求,另一份插入到具有8个连续页框块的链表中;
如果在16个连续页框块的链表中没有找到,就在更大的块链表中查找,比如32找到了,就先切16,插入到16链表中,然后再把剩下的再切,把8插入到8链表中,最后剩下的8个连续页框就分配出去。
回收的时候,会检查长度,如果长度从8变成16,就合并,插入16中。
slab小内存分配器
伙伴系统以页框为单位,分配大块内存。有一些file对象或者各种描述符需要大量的小内存,这就是slab分配器的作用。
slab分配器先批发一些连续页框,常驻内存,构成高速缓冲区,缓冲区内部进行细粒度分配。常驻内存以空间换时间,减少了内存分配初始化销毁释放的代价。
slab分配器生成的每个高速缓存存储一种类型的对象。高速缓存由一连串的slab构成,每个slab包含了若干个同类型的对象。这种细粒度的切分也是slab的特点。

虚拟地址转换
从一个虚拟地址到最后的物理地址,要经过多级转换。
首先,通过段基址+段偏移,获得32位线性地址,然后将32位线性地址通过分页部件转换成物理地址。

无论是页目录表项还是页表项,结构都是一样的。一个页表项,不仅仅包含地址,还有很多字段:
传统的页表项字段且不说,虚拟内存的页表项增加了一些字段:
- 物理地址20位。
- Present。标志页表是否在内存中。
- Accessed访问位,用于页面置换算法。
- Dirty位,写操作标记位,用于交换。

盘交换区与页面置换
Linux中,有一个磁盘交换区。可以理解为内存与磁盘之间的一种缓存。交换区可以直接作为一个磁盘分区,这种交换区就只有一个子区(swap分区),也可以以文件形式存在,但是这种就会被切分为多个物理块(文件会被离散储存)。
盘交换区由若干页槽组成,页槽大小和内存的页大小对应,为4K。盘交换区的第一个页槽存放交换区的整体信息,其他页槽用于交换。发生交换的时候,内核尽量把换出去的页放在相邻页槽中,减少后续磁道寻道时间。
缺页中断发生在这些情况下:
- 没访问过。该页从未被进程访问过,且没有相应的内存映射。
- 访问过,但被交换到交换区了。该页已被进程访问过,但其内容被临时保存到磁盘交换区上。
- 休眠中。该页在非活动页框链表中。
- 被锁了。该页正在由其它进程进行I/O传输过程中,这种只能阻塞。
发生缺页中断时,会先去交换区找,交换区找不到就会去磁盘去调。
页面置换策略是LFU(Least Frequently Used)。注意这和LRU不同,R是Recently,而这个是Friquently,这个算法会统计最近调用一页的频数,频数最少的就被交换出去。
Linux文件系统
Ext2磁盘数据结构
最开始是Minix文件系统,之后用Ext FS(Extended FileSystem),现在是Ext2,广泛运用。
文件卷整体布局
Linux的物理结构是索引文件结构。
Ext2把磁盘块分组。这是因为一个物理块上的位示图无法描述所有的空间。描述一个块组要用到下面这些元数据,总的来说,两个描述块,两个位图块,剩下的就是两类文件块。
- 超级块。描述磁盘整体信息,每个块组的超级块都一样。
- 块组描述符。有k块,其实只需要1块就可以描述本块组。其他的有数据冗余,用于备份
- 数据块位图,索引节点位图。位示图描述索引节点和数据块的占用情况。
- 索引节点区,数据块区。这是真正存索引和数据的区域。

这是整体的架构图,磁盘分区下有块组,块组下有6个区,索引区有一系列索引节点inode,inode本身具有复杂的数据结构,描述了一个文件。
同时,为了描述大文件,inode中设有15个索引,分为0-3级索引。但是需要注意的是,多级索引使用一些储存索引值的物理块存索引,与inode不一样,储存索引值的块没有复杂的数据结构(本身是物理块,里面全是物理块号,每个块号长4B,仅此而已)
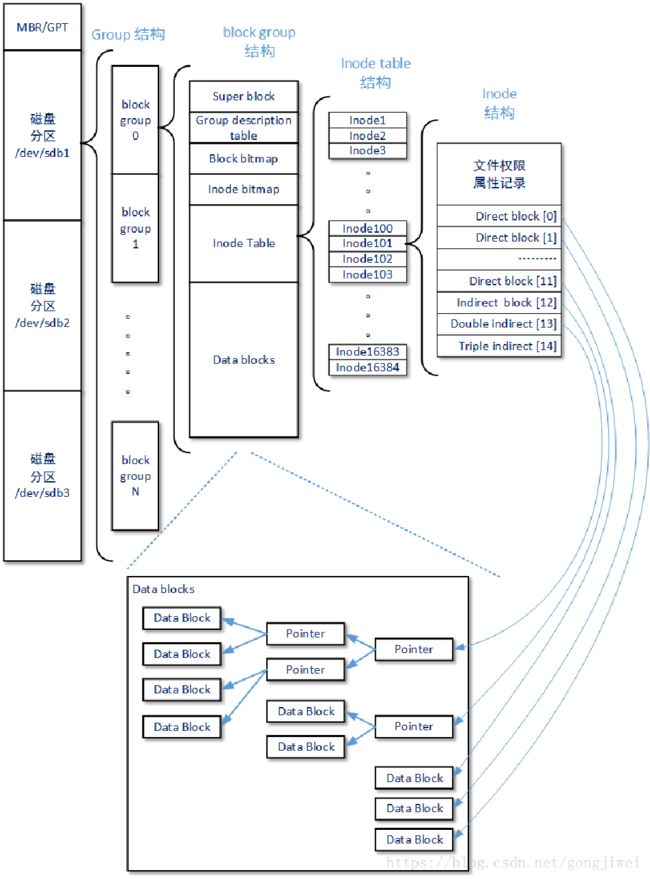
超级块与块组描述符
超级块描述文件系统整体信息,所有块组的超级块都是一模一样的。
块组描述符描述一个块组的信息。
//超级块
struct ext2_super_block {
__le32 s_inodes_count; 索引节点的总数
__le32 s_blocks_count; 盘块的总数
__le32 s_free_blocks_count; 空闲块计数
__le32 s_free_inodes_count; 空闲索引节点数
__le32 s_log_block_size; 盘块的大小
__le32 s_blocks_per_group; 每组中的盘块数
__le32 s_inodes_per_group; 每组索引节点数
__le16 s_inode_size; 磁盘上索引节点结构的大小
……
};
//一个块组描述符
struct ext2_group_desc {
__le32 bg_block_bitmap; 盘块位图的块号
__le32 bg_inode_bitmap; 索引节点位图的块号
__le32 bg_inode_table; 索引节点区的第一个盘块块号
__le16 bg_free_blocks_count;组中空闲块的个数
__le16 bg_free_inodes_count;组中空闲索引节点的个数
__le16 bg_used_dirs_count; 组中目录的个数
……};
位示图
一个物理块用一个bit对应,与内存中的位示图一致。
数据区与目录文件,间接索引表
储存数据本身。
其中需要注意的是,目录文件也是存在这里的,一个目录文件就是一张文件目录表:
文件目录项描述一个文件,一个简单的文件目录项包含文件名以及索引节点号结构。
间接索引表也在数据区。
通过索引节点号就可以锁定一个inode索引节点,就可以找到文件的所有物理块。
struct ext2_dir_entry_2{
__le32 inode; 索引节点号
__le16 rec_len; 目录项长度
__u8 name_len; 实际文件名长度
__u8 file_type; 文件类型
char name[255]; 文件名是4B的整数倍,变长数组
}

目录项长度,固定长度为4(inode)+2(rec_len)+1(name_len)+1(file_type)=8
变化的长度为名字,为4n个长度。

如果要删除文件,就把索引节点号置零,前一个文件的rec_len就会变长,这使得我们在扫描文件目录项的时候,可以跳过那个被删除的文件。

索引节点区与inode
m个索引节点块共同构成一个大表,叫inode table。
inode table中是一个一个的inode,一个inode有128B长,所以一个索引节点块可以存放 4 K 128 B = 32 \dfrac{4K}{128B}=32 128B4K=32个inode。
一个索引节点inode,对应一个实体的文件,有如下重要信息:
- 描述文件的各种信息,尤其是权限信息。
- 可以放15个物理块的索引,分0-3级,可以对应一个超大文件。
- 硬链接计数。

硬链接计数
inode与文件一一对应,但是n个文件目录项可以对应一个inode,此时inode的硬链接计数为n,每删除一个文件目录项,硬链接计数就减一,当n=0的时候也就可以删除inode了。
宏观来说,inode是文件系统角度的文件,而文件目录项是用户角度的文件,用户角度看到的多个硬链接文件,指向的是同一个inode。
文件索引表
15个元素的数组,其实就是索引表。我们捋一下多级索引,假设一个盘块的大小为b,则满打满算,只储存块索引,可以存 b 4 \dfrac{b}{4} 4b个索引。
- 0-11索引号是直接索引。数值本身就是物理块号,对应逻辑上0-11的块
- 12号是一次索引。经过一次索引,一个索引块可以储存 b 4 \dfrac{b}{4} 4b个索引,所以一次索引的区间长度就是 b 4 \dfrac{b}{4} 4b,所以其对应逻辑块区间为:12到 b 4 \dfrac{b}{4} 4b+11
- 13号是二次索引。二次索引,可以储存的区间长度为 ( b 4 ) 2 (\dfrac{b}{4})^2 (4b)2,所以其对应逻辑块区间为: b 4 \dfrac{b}{4} 4b+12到 b 4 \dfrac{b}{4} 4b+ ( b 4 ) 2 (\dfrac{b}{4})^2 (4b)2+11
- 14号是三次索引。以此类推,区间长度为 ( b 4 ) 3 (\dfrac{b}{4})^3 (4b)3,所以逻辑块号区间为 b 4 \dfrac{b}{4} 4b+ ( b 4 ) 2 (\dfrac{b}{4})^2 (4b)2+12到 b 4 \dfrac{b}{4} 4b+ ( b 4 ) 2 (\dfrac{b}{4})^2 (4b)2+ ( b 4 ) 3 (\dfrac{b}{4})^3 (4b)3+11
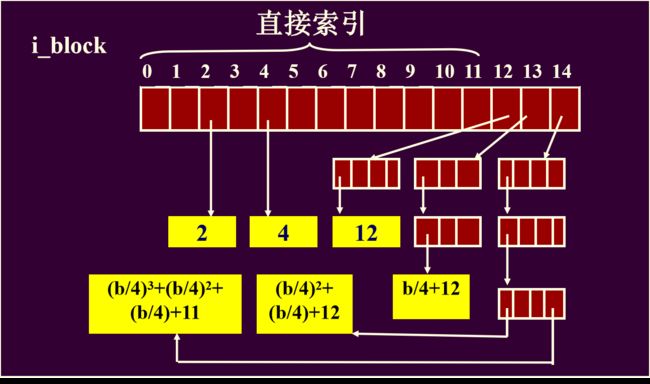
有趣的是,这三级索引对应的区间是连续的,所以三级索引可以表示出小文件以及很大的文件,大小可以连续变化,这里计算一下,假设b=4KB:
- 直接索引。 ( 12 ) × 4 K B = 48 K B (12)\times 4KB=48KB (12)×4KB=48KB
- 一级索引。 ( 4 K 4 + 12 ) × 4 K B = 4 M + 48 K B (\dfrac{4K}{4}+12)\times 4KB=4M+48KB (44K+12)×4KB=4M+48KB
- 二级索引。 ( 4 K 4 + ( 4 K 4 ) 2 + 12 ) × 4 K B = 4 G + 4 M + 48 K B (\dfrac{4K}{4}+(\dfrac{4K}{4})^2+12)\times 4KB=4G+4M+48KB (44K+(44K)2+12)×4KB=4G+4M+48KB
- 三级索引。4T+4G+4M+48KB
物理块号是32位的,对应 4 G × 4 K = 16 T 4G\times4K=16T 4G×4K=16T的磁盘寻块空间,如果使用四级索引,文件大小的上限(4P+4T+4G+4M+48KB)就会超出物理磁盘寻址空间。
所以三级索引与物理块号位数是匹配的。
再论文件类型与索引节点
一个普通文件,是通过inode索引的标准模式,但是其他特殊类型的文件并不如此。
符号链接文件,本身就是一个文件,理论上应该配n个物理块+1个inode+1个文件目录项。不过这么做成本可能是有点大,更简洁的方式是只用inode即可。
如果路径名小于60B,那么可以直接存i_block数组里,如果超出,那就只能用额外的物理块了,i_block也回归了最初的作用——物理块索引。
至于其他的文件,因为路径不会太长(比如设备端口长度是很短的),所以一定可以直接存inode。

Ext2主存数据结构
与磁盘是一一对应的,有超级块和inode。
至于其他的块组成分,不做考虑。

struct ext2_inode_info { /*内存索引节点*/
……
struct inode vfs_inode; /*索引节点对象*/
……
}; //P196
磁盘空间管理
磁盘空间管理负责 磁盘块和索引节点的分配和回收,让文件放置遵循一定原则,使得寻道成本降低。
都是尽量,不能保证在一个组块中。
- 文件的数据块和其索引节点尽量在同一个块组中。
- 文件和它的目录项尽量在同一个块组中。
- 父目录和子目录尽量在同一个块组中。
- 每个文件的数据块尽量连续存放。
Linux虚拟文件系统

Linux内置Ext2文件系统,但是文件系统有很多,Minix,Ext2,FAT,NTFS,各种设备等等,要兼容这些设备,需要建立一个接口。对用户来说,接口提供统一的操作方式,之后将操作转换到各自的文件系统中。
这个接口就是VFS(virtual file system)
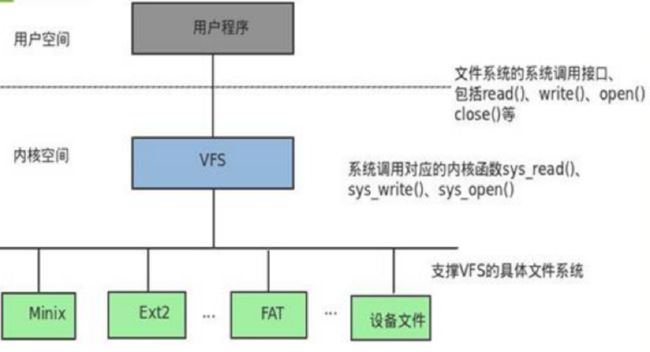
这种机制如何实现呢?磁盘已经是Ext2了,不能改了,所以使用灵活性较强的内存来在运行时生成虚拟文件数据结构。
VFS数据结构
注意,除了磁盘上存的数据以外,这些VFS数据结构都在内存(Ext2的实际的文件系统,这些数据结构存在磁盘)。
- 对于一个文件系统,建立一个超级块对象。和上一章学到一个超级块是一样的级别(只不过在内存中)
- 索引节点对象。对应inode,与文件一一对应。
- 目录项对象(dentry)。对应磁盘目录项,可以多个目录硬链接到一个inode
- 文件对象。一个进程可以打开一个文件对象,可以多个文件对像对应一个目录项对象。
总的来说,从索引节点到目录项对象到文件对象,是一个树结构。
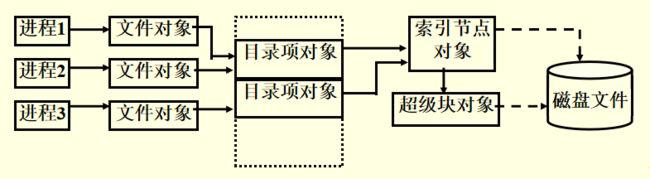
当进程打开文件的时候,下面的对象全部是在内存中动态生成的。这里宏观地总结一下,要具体说还得从下面仔细看。
- task_struct:PCB
- files_struct:进程打开的所有文件
- files:进程打开的一个文件结构
- dentry:文件结构指向的文件目录项
- inode:文件目录项硬链接到的inode
- ext2_inode_info:内存中的inode信息
其实还用到ext2_inode,只不过这个是在磁盘中。
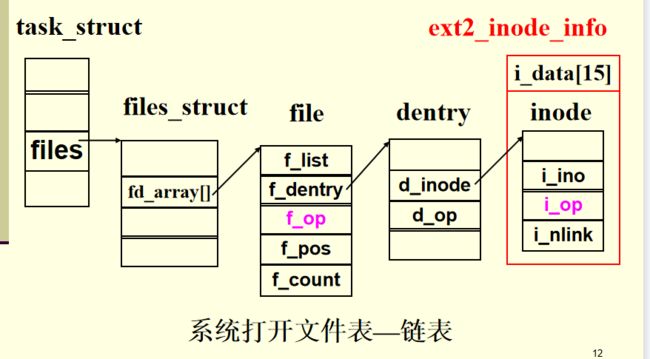
超级块对象
struct super_block { //P205
struct list_head s_list; 系统超级块双向链
struct file_system_type *s_type;
struct super_operations *s_op;
struct dentry *s_root 根目录的目录项对象
struct list_head s_inode; 索引节点链表
struct list_head s_files; 文件对象链表
void *s_fs_info; 指向一个具体文件系统的超级块结构
……
}
super_blok在磁盘上有映像,s_fs_info指向磁盘中具体的超级块,对应磁盘中具体的一个文件系统。
一个超级块对应一个文件系统,file_system_type描述了文件系统类型,超级块之间通过双向链表链接。
在把一个虚拟文件系统载入到Linux中的时候,可以指定其根目录,使用dentry字段描述。
索引节点对象inode
struct inode { //P207
unsigned long i_ino; 磁盘索引节点号
atomic_t i_count; 该对象的引用计数
nlink_t i_nlink; 硬链接计数
struct inode_operations *i_op; //P209
struct address_space *i_mapping;
…
}
struct ext2_inode_info { /*内存索引节点*/
……;
struct inode vfs_inode;
……
}; // P196
inode对象在磁盘上有映像,其i_ino字段储存了磁盘上的索引号。
注意区分:
- 索引节点ext_inode(文件系统+磁盘)
- 内存索引节点ext_inode_info(文件系统+内存)
- 索引节点对象inode(虚拟文件系统+内存)。
文件对象file
struct file { //P212
struct list_head f_list; 文件对象链表
struct dentry *f_dentry; 指向目录项对象
atomic_t f_count; 该对象的引用计数
loff_t f_pos; 文件的当前读写位置
struct file_operations *f_op; 操作类型
struct address_space *f_mapping; 内存映射
……
}
仅在内存中,没有磁盘映像。
目录项对象dentry
struct dentry { //P212
atomic_t d_count; 文件对象的引用计数
struct inode *d_inode; 指向inode对象
struct dentry *d_parent; 指向父目录项对象
struct list_head d_alias; 属于同一inode的dentry链表(同目标的硬链接链表)
struct dentry_operations *d_op; 方法
……}
进程相关结构
Struct tast_struct{
……
struct fs_struct *fs; //指向文件系统
struct files_struct *files; 指向进程打开文件信息
…}
在PCB中,有指向文件系统的指针,有指向files_struct的指针,这个结构储存了当前进程打开的所有文件的信息。
struct files_struct { P213
struct file **fd; 指向文件对象指针数组
struct file *fd_array[ ]; 文件对象指针数组
……}
一般情况下,只需要fd_array,这个指针数组长一般为32,也可以扩展64。如果打开的文件超出64,就会在内存中新开一个指针数组,其地址用fd表示。这个指针数组能存的比较多,加起来够1024。
一个进程最多开1024个文件。
这个时候你再回来看下面这个图:
文件系统的注册与安装
注册:register_filesystem(),可以理解为在VFS中把一种文件系统对应的超级块写入物理块。
安装:mount
- -t与ntfs对应文件系统
- /mnt/ntfs是当前文件系统中的挂载点
- /dev/hda2,块特别文件路径名:是物理层面的路径,与分区设备有关。
mount –t ntfs /dev/hda2 /mnt/ntfs
在挂载了文件系统后,会在安装表里添加一个描述符。这个描述符分别指向被安装的根目录对象(来源)与安装点目录对象(去向)
struct vfsmount {
struct dentry *mnt_mountpoint;
/*指向安装点的目录项对象*/
struct dentry *mnt_root;
/*指向被安装文件系统的根目录*/
……
}
VFS系统调用
文件打开与关闭:open(), close()
文件的读写:read(), write()
Windows系统模型
Windows与Linux最大的区别在于,Windows是私有的,Linux内核是开源的。


Windows体系结构
整体架构
看到这种图不必害怕,从上往下读即可:
- 用户态是最表层的,运行在用户态的应用程序,进程,都会通过Ntdll.dll文件,转换成核心态中统一的描述。Ntdll就是用户态和核心态之间的接口
- 执行体。核心态中最上层不是内核,而是执行体。执行体相当于对内核进行功能上的划分,封装。
- 内核。执行体下面才是内核,封装了最核心的功能。
- 硬件抽象层。内核不直接与硬件打交道,而是通过硬件抽象层,这使得Windows的跨平台能力较强。
- 前面四个,从上往下基本是逐层封装调用的,至于驱动,win32k.sys,NTFS.sys,这几个东西暂时略过。

这个图更加细节,红色的大圈为执行体,其功能是分块的,而下面的kernel是一整块,kernel下面是HAL,HAL下面是硬件。
至于侧面的东西,略过即可。
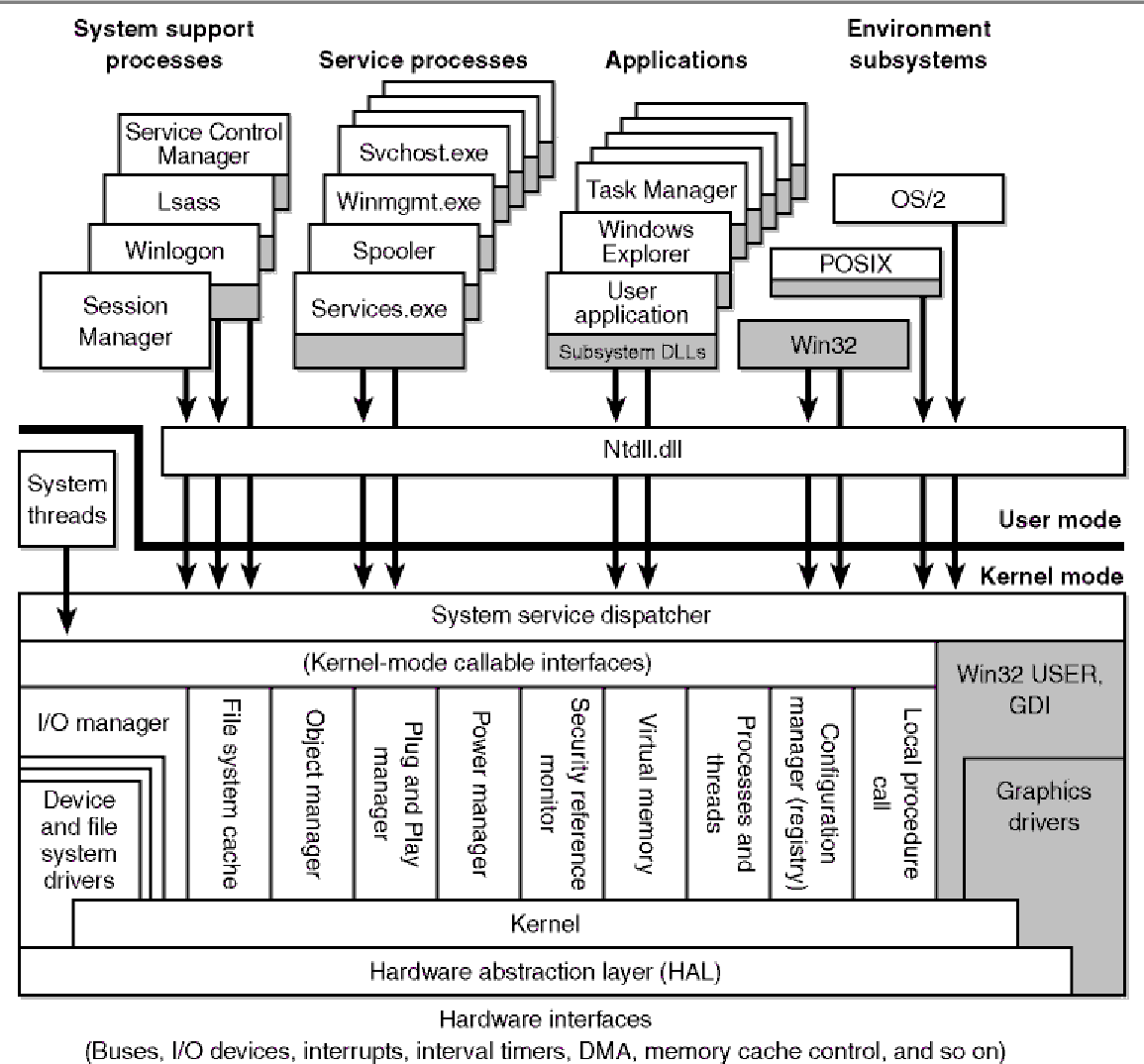

核心态组件

核心态的组件就这两个东西,上层是执行体,下面是内核。
- 执行体:不同的执行体,负责不同类型的任务
- 内核:只有一个,提供一组基本例程(例程类似于函数),基本对象。
执行体和内核是概念上的东西,具体在操作系统中实现是以对象的形式存在的:
- 内核对象:若干对象构成一个集合,提供基本的功能,仅供执行体使用。内核对象分为两类:
- 控制对象。仅仅控制内核,不改变进程调度。包括内核进程对象,APC,DPC,中断对象等
- 调度程序对象,又名分发器对象 dispatcher object,改变进程调度。包括内核线程,事件对象,互斥体,信号量,定时器等等。之所以调度程序对象又名分发器对象,是因为这些对象都有一个共通的数据结构头:DISPATCHER_HEADER结构。
- 执行体对象:封装了内核对象的一部分,执行一些特定类别的功能,比如内存管理,进程调度。
硬件抽象层HAL
HAL是一个可加载的核心态模块hal.dll,为Windows运行在硬件平台上提供低级接口。
设备驱动程序和执行体的其他部分隐藏各种与硬件有关的细节,HAL使上层免受特殊硬件平台的影响, 系统可移植性好。
Windows系统特点
总的来说,这是个分层模型,同时也是客户/服务机模型。
客户进程和服务器进程通过执行体中的消息传递工具进行通信。
核心态组件中使用了面向对象的设计原则,但是整体来说,Windows不能说是一个面向对象的操作系统。
Windows系统机制
- 陷阱调度。Windows内核大量使用的中断就是陷阱调度的一种,这是内核的功能。具体包括中断、DPC 、APC 、异常调度、系统服务调度。
- 执行体对象管理器。执行体里面有一个对象管理器,负责管理各种核心态中的对象。
- 同步。比如多个CPU之间的同步。使用的技术为自旋锁、内核调度程序对象。
- 本地过程调用LPC。服务器进程创建一个LPC连接端口对象,然后在该端口上监听客户连接请求。类似socket编程。消息传递。
陷阱调度
中断有两种:
- 硬件中断。这是真正的中断,比如缺页
- 软件中断,并不是真正的中断信号,但是和中断起到类似的作用(优先级比较低)比如系统调用,检测程序检测到错误等等
中断只是陷阱调度的一部分,陷阱调度整体上就是通过各种信号来实现异步。

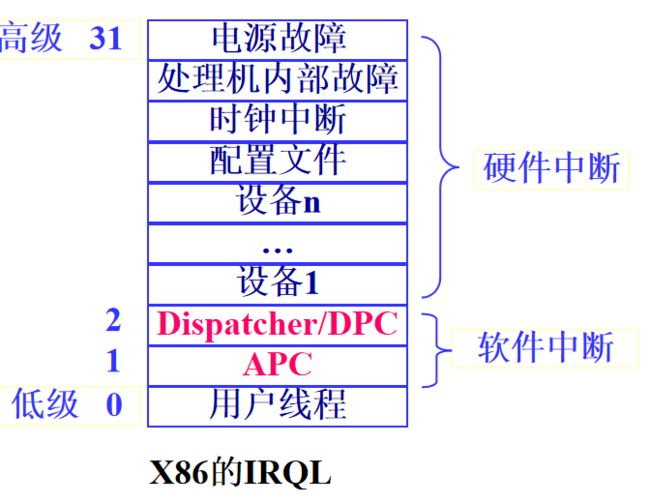
中断优先级IRQL
中断的执行是有优先级的,如何在硬件层面维持优先级呢?或者说,对于一个CPU来说,当你运行的过程中收到一个中断,你会不会响应?
响不响应取决于CPU优先级和中断优先级哪个更高。
CPU哪来的优先级?CPU在执行一个中断的时候,CPU的优先级就是正在执行的中断的优先级,执行完中断以后优先级会恢复。
如果CPU优先级高于新来的中断,那么就屏蔽,如果新来的中断优先级更高,就去处理更重要的中断。这就是所谓的中断屏蔽,这是很自然的思路。从这张优先级表来说,用户线程最低,软件中断其次,硬件中断最重要。硬件中断内部也有高下之分,电源是最重要的,处理器次重要。
TODO,如果一个中断被打断,回来以后是否还会处理
延迟调用DPC
DPC软件中断中,优先级最高的。
通常,一个任务会有重要的部分和不重要的部分,重要的部分会产生硬件中断,优先执行。耗时的,不那么重要的(但是仍然很重要),会产生DPC软件中断,等硬件中断都处理完了,再处理DPC任务。这就是延迟调用。
具体怎么实现呢?
- 一个任务对应一个DPC对象,里面包含了各种操作(系统函数地址)。
- 若干DPC对象形成DPC队列,这是系统全局队列
- 当CPU的优先级降低到DPC级别的时候,DPC中断产生,就开始处理DPC队列中的例程,直到清空或者被硬件中断抢占。
异步过程调用APC
Asyncroneus Procedure Call。每个线程都有自己的APC队列,对应一些线程要处理的信息,就好比你微信里的红点一样。
APC队列优先级高于用户线程,所以当一个线程被调度时,它的APC过程会首先被执行。这种机制使得APC很适合实现异步IO通知(回顾操作系统的进程间消息传递)
举例:文件操作有“同步”和“异步”之分。如一个进程调用写文件,同步,阻塞直到写完,该进程被唤醒;异步,调用写之后可以去干别的事,写完之后产生一个通知用APC放到该进程中
下图给出IO请求的中断处理,分为同步IO和异步IO两种方式。
- 首先产生一个高优先级中断ISR,ISR用很短的时间捕获一些关键信息(执行关键任务)后会生成一个DPC
- 其次处理中优先级DPC,完成文件的IO
- 完成IO有两种方式
- 同步IO。发出者阻塞,等待IO线程结束后唤醒发出者线程
- 异步IO。发出者该干啥干啥,如果IO线程结束,就会丢给发出者一个APC,因为APC优先级高于用户线程,所以会打断当前做的事情去处理APC。

执行体——对象管理器
对象管理器是执行体的一个部分,负责从上而下地管理操作系统核心态的各种对象,所谓对象,就是一种数据结构,任何一个有结构的系统都可以看做一个对象,不论大小:
- 内核对象。内核对象对应操作系统中核心的公用模块,仅供执行体使用,分为控制对象和调度程序对象。
- 执行体对象。执行体对象与操作系统中宏观的模块有关,用户态可见,比如进程,线程对象,文件映射对象,文件对象。
对象结构
对象由两部分组成:
- 对象头。记录了对象的元数据。对象管理器控制的就是对象头
- 对象体。存放对象的数据本身。执行体组件具体执行要用到对象体。

类型对象
需要注意的是,对象头里面的对象类型实际上是一个指针,指向一个类型对象。之所以这么干,是因为个一字段难以完美地描述一类对象,所以干脆就整个类型对象出来。
类型对象描述了一类对象,有哪些公共的属性,公共的方法。

每一个具体的对象都会指向其所属的类型对象。
TODO对于特殊的进程对象,还有一些额外的链接:对象之间通过链表链接,而其类型对象指向链表的头结点。

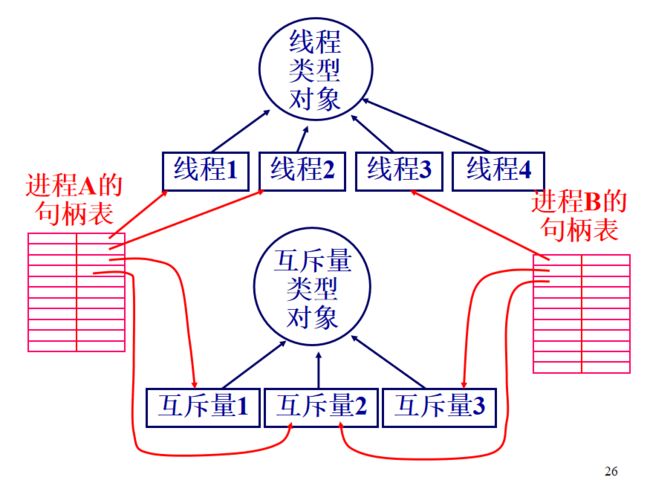
在进程中管理对象
前面只是说了,对象与其类型对象的关系,还没涉及到进程。一个进程是如何管理其创建的对象的呢?
- 对象名,用来标识对象
- 对象句柄,是打开一个对象后,用来操作对象的
- 对象句柄表,一个进程打开的所有对象的地址(其实就对应句柄)都存在这个表里,这个表在EPROCESS中,总之对应一个进程。
从这个图整体看,进程句柄表指向已经打开的对象,打开的对象又指向其类型对象。
有一些特殊的对象,可以被多个进程同时打开,比如信号量对象。
对象同步
系统组件的对象分两种,所以同步也分两种
内核同步——自旋锁
内核引入自旋锁实现多CPU互斥访问内核临界区
自旋锁的实现是testset,这是硬件层面的指令实现,因此自旋锁线程具有绝对优先级,不可能被剥夺,所以要十分小心,不要占用太久,更不要卡死锁。
执行体同步
执行体之间要同步,执行体还提供了用户层面的同步。而且这个同步机制是统一的:等待调度程序对象为有信号状态,WaitForSingleObject( ) 。
回忆一下调度程序对象,核心组件对象分为执行体对象和内核对象,内核对象分为控制对象和调度程序对象,调度程序对象会影响进程调度。调度程序对象有:进程、线程、事件、信号量、互斥体、可等待的定时器、I/O完成端口或文件等同步对象
每个同步对象有两种状态:“有信号”,“无信号”,线程、进程终止时有信号。所以当一个进程终止时,就会产生一个信号。
Windows 2000/XP进程线程管理

进程和线程
进程的特点:
- 对应一个可执行程序。
- 具有一个独立的地址空间。
- 可有多个线程。
线程是进程内的执行实体。一个进程有一个主线程,以线程为单位调度执行。核心级线程。
进程对象
内核进程对象
KPROCESS
struct KPROCESS{
DISPATCHER_Header; 调度头
DirectoryTablebase; 页目录表的基地址
BasePriority; 基本优先级
…… }
执行体进程对象
E:execute,对应执行体。
其中有一个KPROCESS,K对应内核,PCB是内核进程块。
struct EPROCESS{ P285
KPROCESS Pcb; 内核进程块,位于内核层
ObjectTable; 进程的句柄表
PageDirectoryPte; 页目录表项
ImageFileName; 进程的可执行映像文件名
UniqueProcessId ; 进程的ID
SectionObject;指向可执行映像文件的区域对象
SectionBaseAddress; 该区域的基地址
VadRoot; 平衡二叉树的根,代表虚拟地址空间
WorkingSetPage; 进程工作集页面
Peb;位于进程私有地址空间的环境块
Win32Process; 指向由Windows子系统管理的进程区域,此值不为空,说明是GUI进程。
PriorityClass;进程的优先级
ThreadListHead; 线程链表
ActiveProcessLinks; 所有活动进程连接在一起
……
}
整体结构
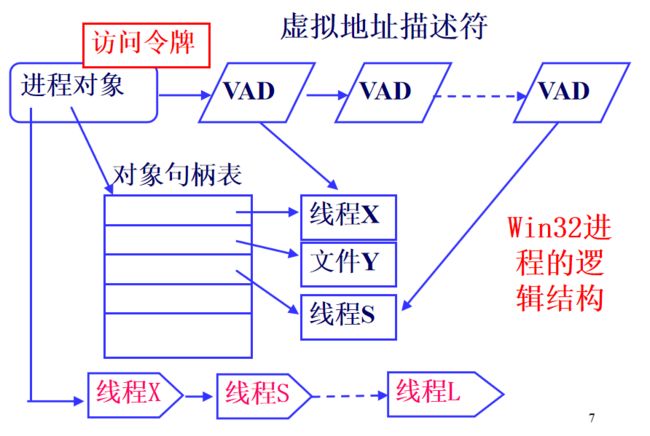
一个进程对象,核心的数据字段就是:
- VadRoot,对应进程虚拟地址
- ThreadListHead,对应线程列表
- ObjectTable,对应句柄表
进程对象的服务
操作系统通过给出函数接口,提供进程对象的服务。

- 关联可执行文件。打开可执行文件(.exe),创建一个区域对象,建立可执行文件与虚拟内存之间的映射关系。
- 进程建立。创建执行体进程对象EPROCESS,初始化。
- 主线程建立。创建一个主线程。
- 进程与线程初始化。把新建的进程句柄及线程句柄通知Win32子系统,对新进程和线程进行一系列初始化。完成地址空间的初始化,开始执行程序。
线程对象
线程对象结构
类似于EPROCESS,也有ETHREAD和KTHREAD,同样是ETHREAD指向KTHREAD。
每一个KTHREAD都指向自己的核心栈,虽然说线程共用数据,但只是公用数据而已,执行信息还是要保存的,所以核心栈是万万不可公用的。
注意,APC队列是一个线程就有一个。

线程对象服务
- CreateThread创建线程
- ExitThread线程退出
- TerminateThread终止某个线程
- SetThreadPriority 改变线程优先级
线程调度
大致上和Linux一样,但是Windows更多地考虑了多处理器系统。Windows采用,基于优先级的抢先式的多处理器调度系统,优先级相同时按时间片轮转
Windows调度以线程为单位,线程调度时,不考虑线程属于哪个进程,但是还是会考虑其进程的优先级。
进程优先级

线程优先级
线程属于进程,所以其优先级继承了进程基本优先级。而线程本身有当前优先级,代表相对的优先级。
系统调度的调度要考虑基本优先级和当前优先级,具体比较略过,结果就是会有32个优先级队列:
- 16个实时线程优先级(16~31)
- 15个可变线程优先级(1~15)
- 空闲优先级(0)用于系统零页线程
相比起来,Linux有140个优先级队列,控制的更加细节(这就是windows容易卡的原因吗?)
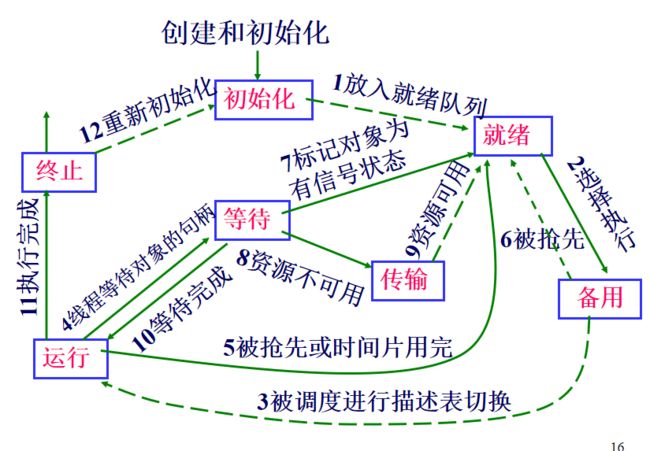
线程的状态
就绪态,运行态,阻塞态是进程的基本状态。对于线程,增加了4个更加细化的状态:备用态。
- 就绪状态(ready)。此时还不可以马上调度(还要进入备用态)
- 备用状态(standby)。就绪态与运行态之间加入备用态,代表已选好处理机,正等待描述表切换,以便进入运行状态。
- 运行状态(Running)。
- 等待状态(waiting)。等待资源,如果资源等到了就继续去运行。
- 传输状态(transition)。如果等待的对象资源因为在外存而不可用的时候,尤其是核心栈在外存的情况下,需要先把外存的资源交换到内存,这个等待传输的状态就是传输态。当传输完毕后,就可以继续运行了,即进入就绪态。
- 终止状态(terminated)
- 初始化状态(Initialized)。正在创建过程中。
对称多处理机上的线程调度
一个电脑上,处理器可能是不同种类的,因为线程对不同的处理器有不同的适应性,所以线程和处理器有亲和关系(Affinity)
当线程对处理器有偏好的时候,高优先级的就绪态线程可能不能变成运行状态,比如线程1喜欢A处理器,但是有个更高优先级的线程2占用A处理器,即使B处理器没线程用,线程1还是会因为偏好而不去选择B处理器。
在有亲和关系的情况下,线程调度使用了更多的数据结构:
- 32个就绪队列。每个优先级对应一个。
- 32位掩码的就绪位图。每一位指示一个优先级就绪队列中是否有线程等待运行。
- 32位掩码的空闲位图。每一位指示一个处理机是否处于空闲状态。
对于前面说的偏好情况,在就绪位图中,高优先级的线程1所属队列位图是1,表示正在等待,此时,处理器空闲位图也有空闲,这种情况下就会采取一些行动防止线程1饥饿。

线程优先级提升
线程优先级提升,用于防止线程饥饿问题。本质上来说,优先级提升就是三种情况:
- 线程的工作有重要的部分和不重要的部分,当不重要的部分执行完毕,要执行重要部分的时候,就应该提升优先级。
- 用户要处理某个GUI窗口,操作系统应当尽力满足用户需求。
- 线程饥饿了,不得不提升了。
具体分为如下情况:
- I/O操作完成后的线程。IO耗时,但是IO完成以后,就是不耗时的重要任务了。
- 信号量或事件等待结束的线程。2,3,4都是等待完毕后,就可以执行了,也应该提升优先级了。
- 前台进程中的线程完成一个等待操作。
- 由于窗口活动而唤醒GUI线程。长时间不点击窗口是会休眠的,比如我点击一个窗口,
- 线程处于就绪状态超过一定时间,仍未能进入运行状态(处理器饥饿)。
线程同步
前面说的执行体同步和内核同步,都是核心态级别的同步,这里的线程同步是用户空间的同步。
- 事件对象:相当于一个“触发器”,用于通知线程某个事件是否出现。有信号和无信号两个状态。
- 互斥体对象:互斥访问共享资源
- 信号量对象:就是资源信号量,初始值可在0到指定最大值之间设置。