神经网络(深度学习)(笔记)
最近在自学图灵教材《Python机器学习基础教程》,在csdn以博客的形式做些笔记。
一类被称为神经网络的算法最近以“深度学习”的名字再度流行。虽然深度学习在许多机 器学习应用中都有巨大的潜力,但深度学习算法往往经过精确调整,只适用于特定的使 用场景。这里只讨论一些相对简单的方法,即用于分类和回归的多层感知机(multilayer perceptron,MLP),它可以作为研究更复杂的深度学习方法的起点。MLP 也被称为(普 通)前馈神经网络,有时也简称为神经网络。(摘于书中)
神经网路模型
MLP 可以被视为广义的线性模型,执行多层处理后得到结论。 还记得线性回归的预测公式为: ŷ = w[0] * x[0] + w[1] * x[1] + … + w[p] * x[p] + b 简单来说,ŷ 是输入特征 x[0] 到 x[p] 的加权求和,权重为学到的系数 w[0] 到 w[p]。我们可 以将这个公式可视化
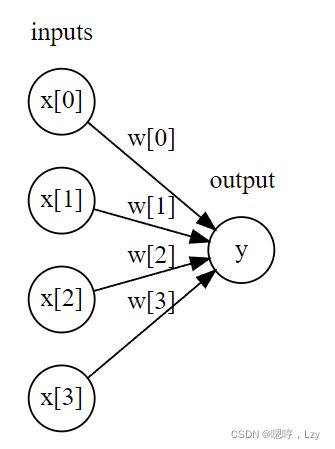
图中,左边的每个结点代表一个输入特征,连线代表学到的系数,右边的结点代表输出, 是输入的加权求和。 在 MLP 中,多次重复这个计算加权求和的过程,首先计算代表中间过程的隐单元(hidden unit),然后再计算这些隐单元的加权求和并得到最终结果
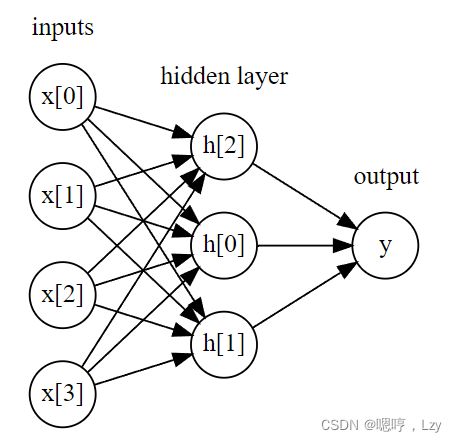
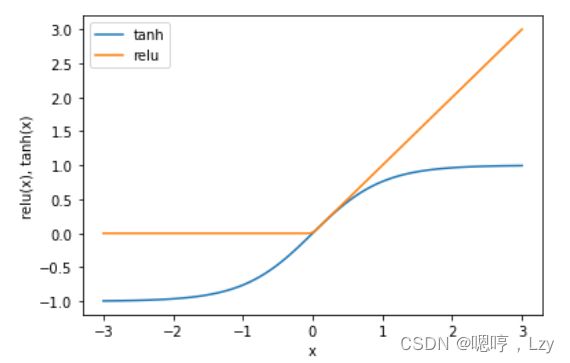
这个模型需要学习更多的系数(也叫作权重):在每个输入与每个隐单元(隐单元组成了 隐层)之间有一个系数,在每个隐单元与输出之间也有一个系数。 从数学的角度看,计算一系列加权求和与只计算一个加权求和是完全相同的,因此,为了 让这个模型真正比线性模型更为强大,我们还需要一个技巧。在计算完每个隐单元的加权 求和之后,对结果再应用一个非线性函数——通常是校正非线性(rectifying nonlinearity, 也叫校正线性单元或 relu)或正切双曲线(tangens hyperbolicus,tanh)。然后将这个函数 的结果用于加权求和,计算得到输出 y
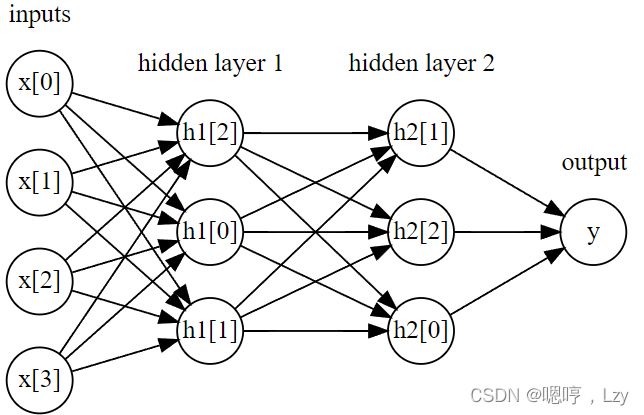
对于上图所示的小型神经网络,计算回归问题的 ŷ 的完整公式如下(使用 tanh 非线性):
h[0] = tanh(w[0, 0] * x[0] + w[1, 0] * x[1] + w[2, 0] * x[2] + w[3, 0] * x[3] + b[0])
h[1] = tanh(w[0, 0] * x[0] + w[1, 0] * x[1] + w[2, 0] * x[2] + w[3, 0] * x[3] + b[1])
h[2] = tanh(w[0, 0] * x[0] + w[1, 0] * x[1] + w[2, 0] * x[2] + w[3, 0] * x[3] + b[2])
ŷ = v[0] * h[0] + v[1] * h[1] + v[2] * h[2] + b
其中,w 是输入 x 与隐层 h 之间的权重,v 是隐层 h 与输出 ŷ 之间的权重。权重 w 和 v 要 从数据中学习得到,x 是输入特征,ŷ 是计算得到的输出,h 是计算的中间结果。需要用户 设置的一个重要参数是隐层中的结点个数。对于非常小或非常简单的数据集,这个值可以 小到 10;对于非常复杂的数据,这个值可以大到 10 000。也可以添加多个隐层。
神经网络调参
我们将 MLPClassifier 应用到two_moons 数据集上
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,random_state=42)
mlp = MLPClassifier(solver='lbfgs', random_state=0).fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")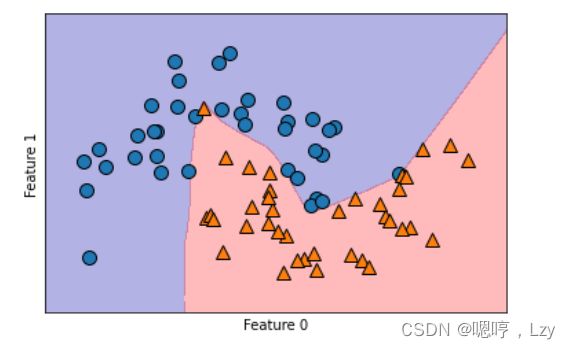
默认情况下,MLP 使用 100 个隐结点,这对于这个小型数据集来说已经相当多了。我们可 以减少其数量(从而降低了模型复杂度),但仍然得到很好的结果。
mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_sizes=[10])
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")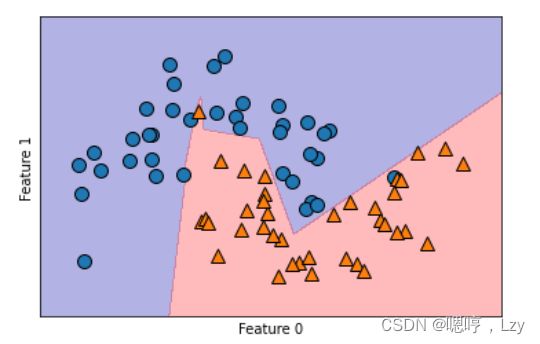
只有 10 个隐单元时,决策边界看起来更加参差不齐。默认的非线性是 relu。如果使用单隐层,那么决策函数将由 10 个直线段组成。如果想得到更加平滑的决策边界,可以添加更多的隐单元、添加第二个隐层或者使用 tanh 非线性.
我们还可以利用 L2 惩罚使权重趋向于 0,从而控制神经网络的复杂度,正如我们在岭回归和lasso回归中所做的那样。MLPClassifier 中调节 L2 惩罚的参数是 alpha(与线 性回归模型中的相同),它的默认值很小(弱正则化)。图 2-52 显示了不同 alpha 值对 two_ moons 数据集的影响,用的是 2 个隐层的神经网络,每层包含 10 个或 100 个单元。
fig, axes = plt.subplots(2, 4, figsize=(20, 8))
for axx, n_hidden_nodes in zip(axes, [10, 100]):
for ax, alpha in zip(axx, [0.0001, 0.01, 0.1, 1]):
mlp = MLPClassifier(solver='lbfgs', random_state=0,
hidden_layer_sizes=[n_hidden_nodes, n_hidden_nodes],
alpha=alpha)
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3, ax=ax)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train, ax=ax)
ax.set_title("n_hidden=[{}, {}]\nalpha={:.4f}".format(
n_hidden_nodes, n_hidden_nodes, alpha))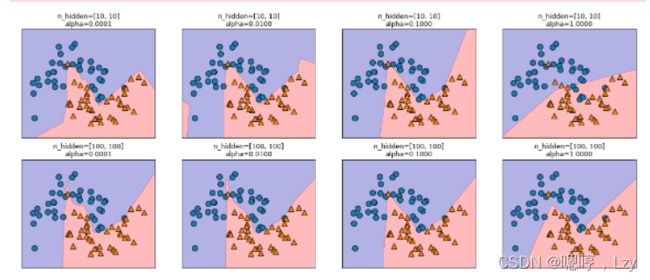
神经网络的一个重要性质是,在开始学习之前其权重是随机设置的,这种随机初始化会影响学到的模型。也就是说,即使使用完全相同的参数,如果随机种子不同的话,我们也可能得到非常不一样的模型。如果网络很大,并且复杂度选择合理的话,那么这应该不会对精度有太大影响,但应该记住这一点(特别是对于较小的网络) 。
实战
接下来我们来看看将神经网络运用到乳腺癌数据集上是怎样的效果
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
mlp = MLPClassifier(random_state=42)
mlp.fit(X_train, y_train)
print("Accuracy on training set: {:.2f}".format(mlp.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(mlp.score(X_test, y_test)))
MLP 的精度相当好,但没有其他模型好。与较早的 SVC 例子相同(具体见支持向量机),原因可能在于数据的缩放。神经网络也要求所有输入特征的变化范围相似,最理想的情况是均值为 0、方差为 1。我们必须对数据进行缩放以满足这些要求。
# 计算训练集中每个特征的平均值
mean_on_train = X_train.mean(axis=0)
# 计算训练集中每个特征的标准差
std_on_train = X_train.std(axis=0)
# 减去平均值,然后乘以标准差的倒数
# 如此运算之后,mean=0,std=1
X_train_scaled = (X_train - mean_on_train) / std_on_train
# 对测试集做相同的变换(使用训练集的平均值和标准差)
X_test_scaled = (X_test - mean_on_train) / std_on_train
mlp = MLPClassifier(random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(
mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
我们可以看到缩放之后的结果要好很多,但是系统却给了我们一个警告 ,告诉我们已经达到了最大的迭代次数这是用于学习模型的 adam 算法的一部分,告诉我们应该增加迭代次数:
mlp = MLPClassifier(max_iter=1000, random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(
mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
增加迭代次数仅提高了训练集性能,同时也提高了泛化性能(这是一项惊喜收获,因为一般而言增加迭代次数并不会提高泛化性能或者说提高不多)。模型的表现相当不错。由于训练性能和测试性能之间仍有一些差距,所以我们可以尝试降低模型复杂度来得到更好的泛化性能。这里我们选择增大 alpha 参数(变化范围相当大,从 0.0001 到 1),以此向 权重添加更强的正则化:
mlp = MLPClassifier(max_iter=1000, alpha=1, random_state=0)
mlp.fit(X_train_scaled, y_train)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
遗憾的是对于这个数据集增大alpha参数并没有用,但是在大多数情况下,都是有用的。
接下来分析一下这个神经网络学到了什么
想要看模型学到了什么,一种普遍的方法就是查看模型的权重。下图显示了连接输入和第一个隐层之间的权重。图中的行对应 30 个输入特征,列对应 100 个隐单元。 浅色代表较大的正值,而深色代表负值。
plt.figure(figsize=(20, 5))
plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis')
plt.yticks(range(30), cancer.feature_names)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature")
plt.colorbar()
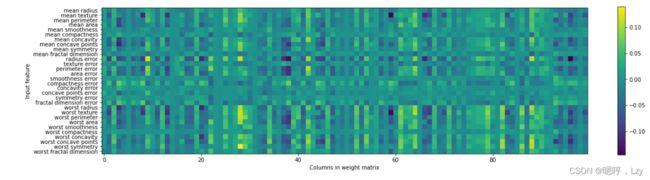 我们可以推断,如果某个特征对所有隐单元的权重都很小,那么这个特征对模型来说就 “不太重要”。可以看到,与其他特征相比,“mean smoothness”“mean compactness”以及 “smoothness error”和“fractal dimension error”之间的特征的权重都相对较小。这可能说 明这些特征不太重要,也可能是我们没有用神经网络可以使用的方式来表示这些特征。
我们可以推断,如果某个特征对所有隐单元的权重都很小,那么这个特征对模型来说就 “不太重要”。可以看到,与其他特征相比,“mean smoothness”“mean compactness”以及 “smoothness error”和“fractal dimension error”之间的特征的权重都相对较小。这可能说 明这些特征不太重要,也可能是我们没有用神经网络可以使用的方式来表示这些特征。
总结
使用神经网络,主要关注模型的定义:层数、每层的结点个数、正则化和非线性。这些内容定义了我们想要学习的模型。还有一个问题是,如何学习模型或用来学习参数的算法,这一点由 solver 参数设定。solver 有两个好用的选项。默认选项是 'adam',在大多 数情况下效果都很好,但对数据的缩放相当敏感(因此,始终将数据缩放为均值为 0、方差为 1 是很重要的)。另一个选项是 'lbfgs',其鲁棒性相当好,但在大型模型或大型数据 集上的时间会比较长。还有更高级的 'sgd' 选项,许多深度学习研究人员都会用到。'sgd' 选项还有许多其他参数需要调节,以便获得最佳结果。当你开始使用 MLP 时,建议使用 'adam' 和 'lbfgs'。