知识图谱入门必看!
来源:知乎 作者:gaojing
著作权归属原作者,本文仅作学术分享,侵删
知识图谱
针对于知识图谱基础知识,领域应用和学术前沿趋势进行介绍。
知识图谱介绍
知识图谱(Knowledge Graph)以结构化的形式描述客观世界中概念、实体及其关系。是融合了认知计算、知识表示与推理、信息检索与抽取、自然语言处理、Web技术、机器学习与大数据挖掘等等方向的交叉学科。人工智能是以传统符号派与目前流行的深度神经网路为主,如下图所示,知识图谱发展史。
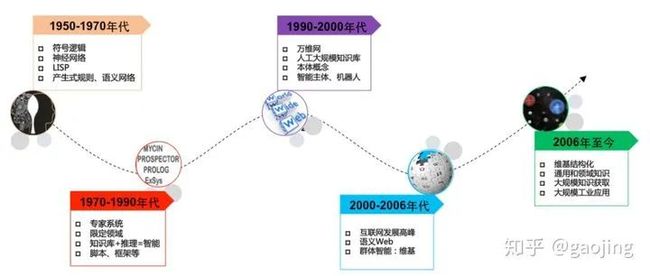
知识图谱发展史
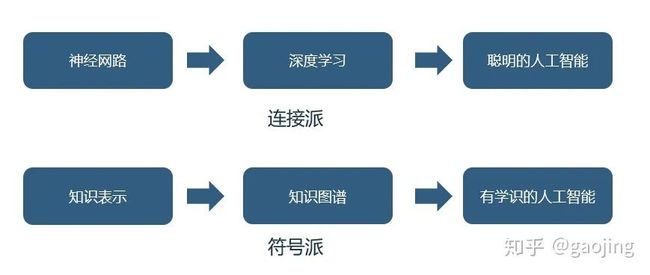
知识表示与深度学习表示
各大公司布局知识图谱
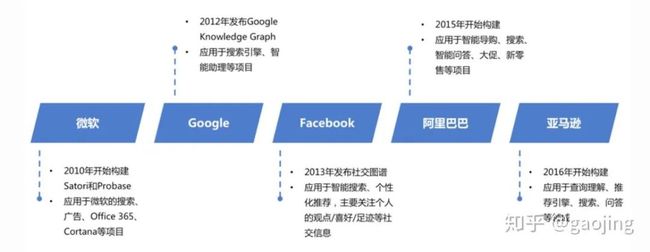
补充其中还包括国内的京东与美团(美团的AI大脑,数十亿知识图谱构建)
知识图谱应用模式(来之美团的Ai大会报告)
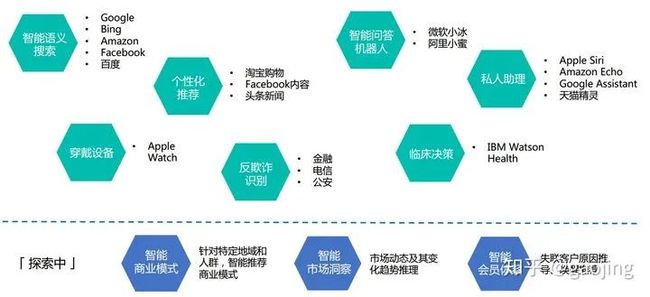
知识图谱技术链
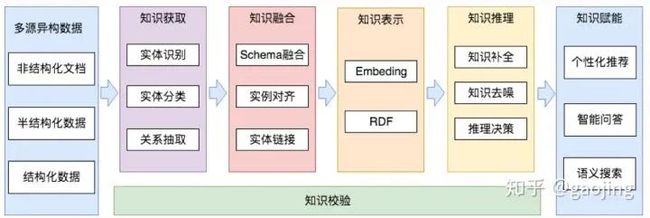
知识图谱赋能
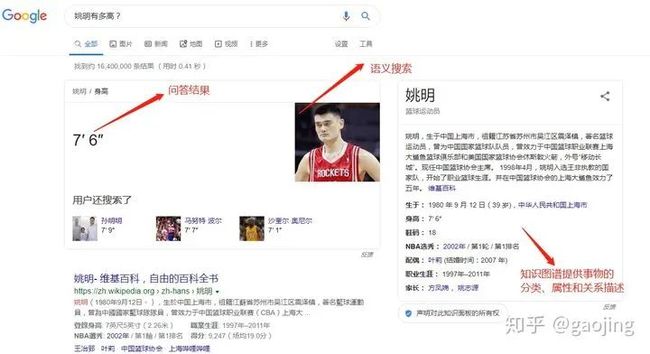
知识图谱应用非常广泛,目前主要应用到搜索引擎、智能问答、大数据分析、语言翻译和语言理解及辅助设备互联(Iot领域),如下图所示,知识图谱在搜索引擎的应用。
通用知识图谱与垂直领域知识图谱对比
相比较DBpedia、Yago、Wikidata、百度和谷歌等通用知识图谱,+特定领域内的知识图谱在知识表示、知识结构、知识质量及知识应用更高的要求(关于领域知识图谱与通用知识图谱之间的问题可以查看复旦肖仰华)。

国内外知识图谱项目
国外:早期的常识知识库Cyc、WordNet、ConceptNet等;互联网知识图谱,主要有FreeBase、DBpedia、Schema、Wikidata 、BableNet、Microsofot ConceptGraph,医疗领域Linked Life Data等
国内:中文知识图谱OpenKG,CN-DBpedia,中医药知识图谱,阿里电商知识图谱、美团知识图谱、XLore(清华大学)、Belief-Eigen(中科院)、PKUPie(北京大学),开放类的中文百科知识图谱,zhishi.me
知识图谱技术模块
知识表示
如何利用计算符号运算来表示人脑中的知识和推理过程,知识表示主要有两种,基于离散符号的知识表示法和基于连续向量的知识表示。
基于离散符号的知识表示法
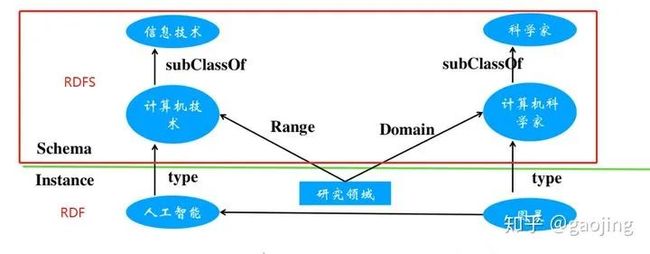
RDF(Triple-based Assertion Model) 三元组模型,构建方式主要是主-谓-宾有向标记图和RDFS(simple Vocabularty and schema)
OWL(Web Ontology language):是一种W3C开发的网路本体语言,用于对本体进行语义描述。
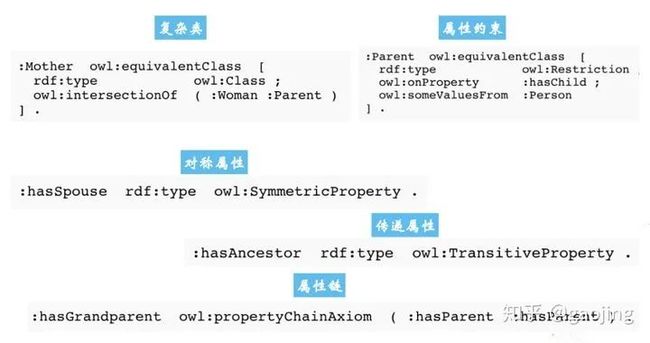
SPARQL(Protocol and RDF Query Language) :RDF的查询语言,支持主流图形数据库。下图URI/IRI为主要网络协议,主要数据存储格式是RDF与XML
基于连续向量的知识表示
KG embedding 主要是KG中实体与关系映射到一个低维的向量空间,主要的方法有张量分解、NN、距离模型(现有的词向量模型基于连续向量空间来表示)(Embedding projector)
两种方法对比

知识抽取
KG中知识抽取主要从结构化、半结构化、结构化数据中转为三元组表示的标准知识形态。
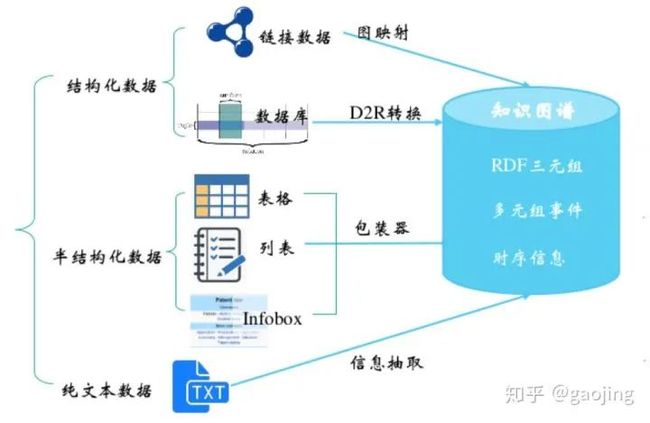
主要处理流程
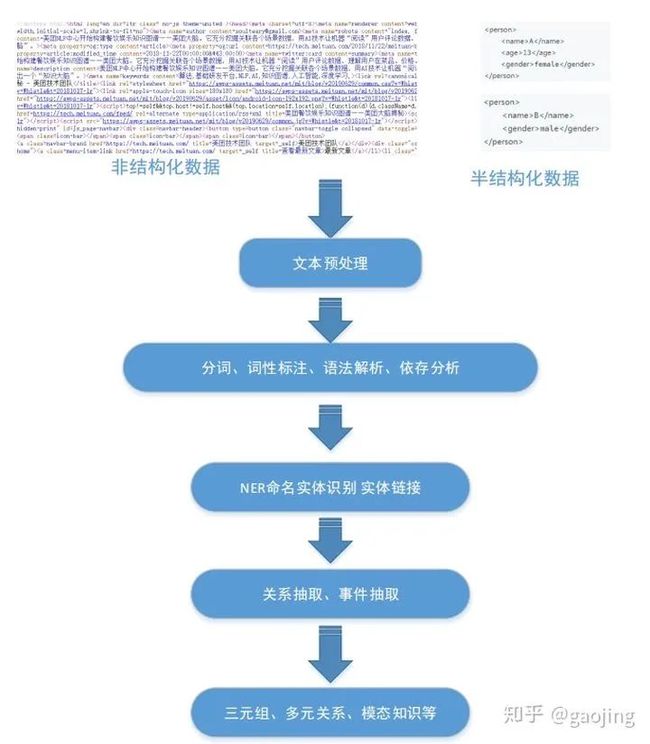
实体抽取(NER命名实体识别)
目的是识别文本中指定类别的实体,主要包括人 名、 地名、 机构名、 专有名词等的任务“ 姚明(Yao Ming),1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理“。如下图所示,命名实体识别主要包含两个部分:实体边界识别与实体分类。传统方法(HMM(隐马尔科夫模型) CRF(条件随机场) SVM、最大熵分类模型等方法进行处理。现在能采用深度学习,比如CNN\RNN\LSTM及LSTM-CRF。采用的工具可以有Jiagu、jieba、Stanford CoreNLP等。

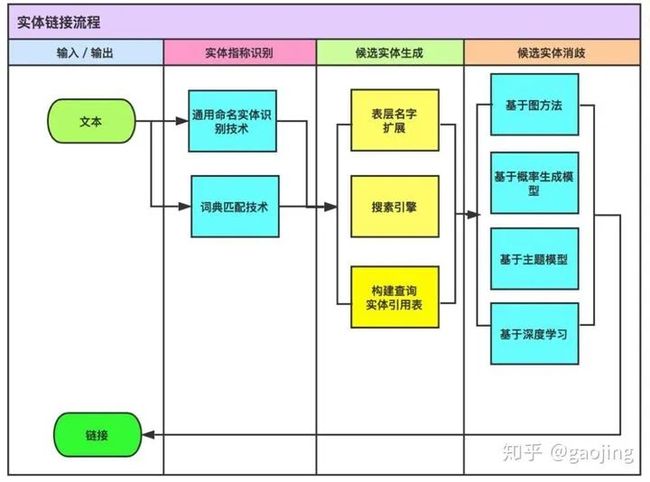
实体链接
目的是将实体提及与知识库中对应实体进行链接 ,主要解决实体名的歧义性与多样性问题,是文本中实体名指向真实世界实体的任务。传统模型是计算实体提及与知识库中实体的相似度,并选取特定的实体提及的目标实体,比如“苹果发布新的手机‘IphoneX11’”,[苹果(水果)、苹果(电影)、苹果(公司)等候选实体],主要使用包括实体统计信息、名字统计信息、上下文词语分布、实体关联度、文章主题等信息,同时,考虑到一段文本中实体之间的相互关联,相关的全局推理算法也被提出来寻找全局最优决策。目前深度学习方法,构建多类型多模态上下文及知识的统一表示,并建模不同信息、不同证据之间的相互交互 通过将不同类型的信息映射到相同的特征空间,并提供高效的端到端训练算法。包括多源异构证据的向量表示学习、以及不同证据之间相似度的学习等工作[Ganea & Hofmann, 2017] [Gupta et al., 2017] [Sil et al 2018] 。开源工具dexter2
实体关系抽取
实体关系抽取是知识图谱构建与信息提取的关键环节,主要提取两个或者多个实体之间的某种联系。格式,三元组(实体1,关系,实体2),"北京是中国的首都、政治中心和文化中心 "中实体关系可以表示为(中国、首都、北京)(中国 政治中心 北京)(中国 文化中心 北京)。
限定关系抽取:采用弱监督/监督机器学习进行预定义的实体关系知识抽取,一般为多分类问题,可以直接抽取三元组关系。一般会采用基于特征向量的方法、基于核函数的方法和基于神经网络的方法 。
开发域关系抽取:预先不进行预定义,系统本身自动抽取实体之间的关系,一般采用无监督学习方法进行自动提取实体之间的关系(三元组)。缺点是抽取的知识缺乏语义化、很难做归一化处理,弱监督学习可以自动生成大规模的训练医疗库,但是会产生噪音数据。
关于NER与实体链接可以查看另一篇文章https://zhuanlan.zhihu.com/p/85567106
事件关系抽取
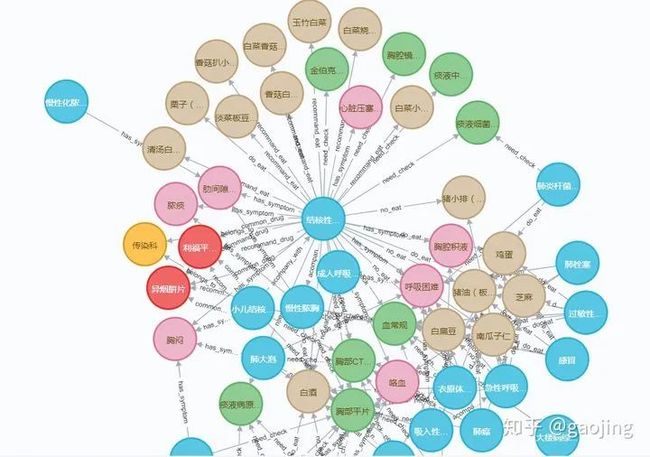
识别文本中关于事件的信息,并以结构化的形式呈现,核心概念包括:事件描述、事件触发词(动词或者名词)、事件元素(实体、时间和属性等表达语义的细粒度单位组成)、元素角色(角色在某件事情上面的语义关系)、事件类型(事件元素和触发词决定事件的类别),如下图所示
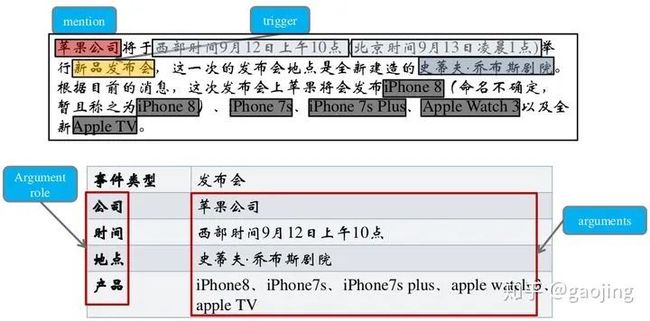
基于模式匹配的方法:对于某一个事件的识别与抽取是在一些模式的指导下进行的,主要有两个步骤:模式获取和模式匹配,有可分为基于人工标注语料和弱监督学习
基于机器学习的方法:把事件建模成多分类问题,可以分为基于特征、基于结构和基于神经网路。
基于特征:该方法多用管道式事件抽取
基于结构预测:将事件结构看做是依存树结构预测。基于结构感知机的联合模型可同时完成触发词与事件元素识别的两个子任务。
基于神经网路:利用RNN进行事件检测及联合模型与RNN相结合进行预测触发词和事件元素
基于弱监督:在学术上,[Chen and Ji, 2009] [Liao and Grishman, 2011a; 2011b] [Liu et.al., 2016b] 等,但是由于该方法无法直接映射到结构化数据中,无法直接构建三元组。
中文事件抽取
中文与英文事件抽取区别较大,主要是缺乏统一、公认的事件语料库及公开评测系统(上海大学CEC(Chinese Event Corpus))
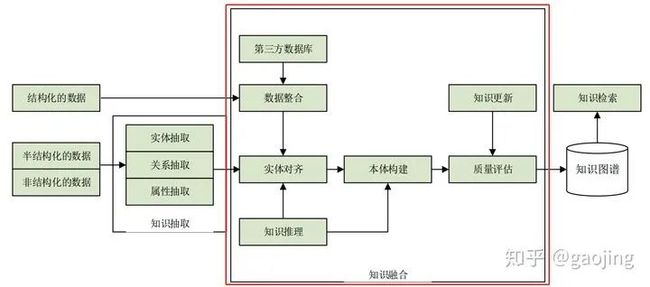
知识融合
知识融合是指合并两个知识图谱,本体可以让用户非常方便和灵活的根据自己的业务建立或者修改数据模型。通过数据映射技术建立本体中术语和不同数据源抽取知识中词汇的映射关系,进而将不同数据源的数据融合在一起。同时不同源的实体可能会指向现实世界的同一个客体,这时需要使用实体匹配将不同数据源相同客体的数据进行融合。不同本体间也会存在某些术语描述同一类数据,那么对这些本体间则需要本体融合技术把不同的本体融合。
知识融合-异构问题
语言层不匹配:RDF OWL OWL2等本体语言之间不兼容。
实体对齐问题:由于多源、异构、跨语言知识图谱差异性较大,比如结构化不可比、实体名称表述差别较大、外部工具不稳定等,可训练数据较少。方法:可以基于图神经网路的实体结构语义表示及匹配(关于知识融合中实体对齐在学术上有很多研究)
知识存储
知识图谱的知识存储一般是采用图形数据库进行存储,主要有两种图数据模型:RDF图和属性图
查询语言:RDF图---SPARQL;属性图:Cypher 和 Gremlin
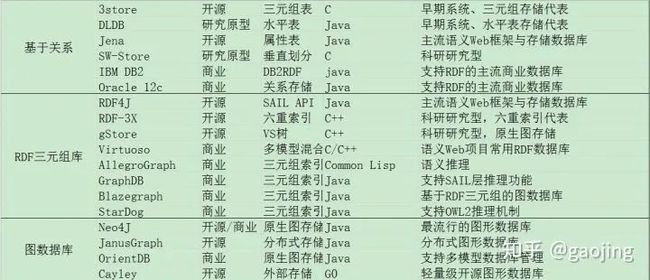
常见知识图谱存储方式
-
基于关系数据库的存储方案
-
主要是三元组表(3store)、水平表(DLDB)、属性表(JENA)、垂直划分(SW-Store)、DB2RDF和六重索引(RDFX-3X、Hexastore)
面向RDF的三元组数据库
-
Jena RDF4J RDF-3X gStore
原生图数据库
-
Neo4j
分布式图形数据库 JanusGraph
OrientDB
Cayley
图形数据库对比
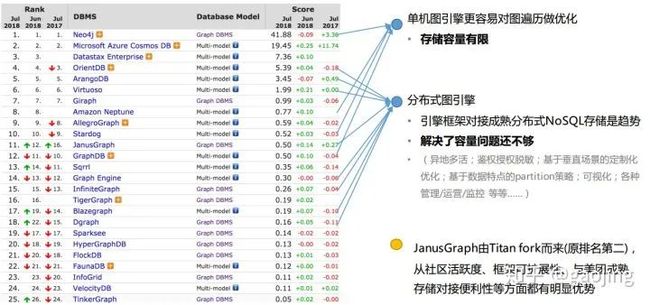
来之DB-Engiens图引擎和美团知识图谱报告,美团采用JanusGraph分布式图形引擎
知识推理
根据已有的知识图谱中的事实或者关系推断出新的事实与关系,一般是考察实体、关系和图谱结构三个方面的信息特征
基于演绎的知识图谱推理
基于归纳的知识图谱推理
基于图结构
基于规则学习
基于表示学习
新的方法
-
时序法
基于强化学习
基于图神经网路
开源工具
Jena和Drools
知识图谱构建流程
主要介绍主流的知识图谱构建流程,实体图谱的构建主要有自底向上、自顶向下和二则混合的方法,如下图所示,分别为自底向上和自顶向下
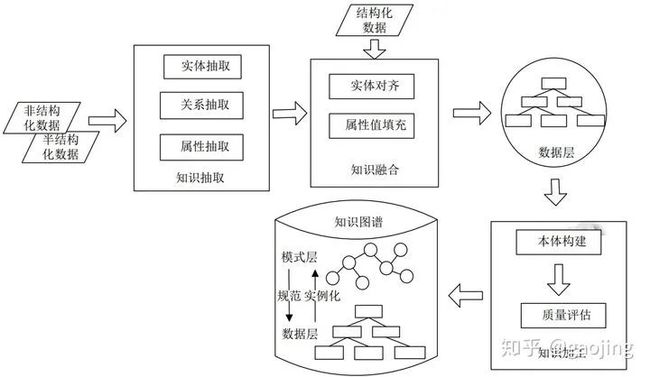
自底向上
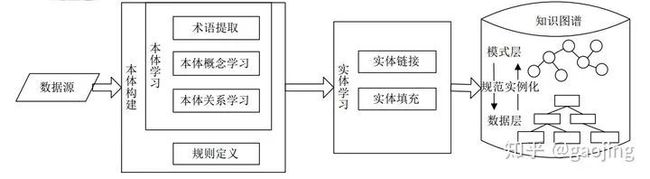
自顶向下
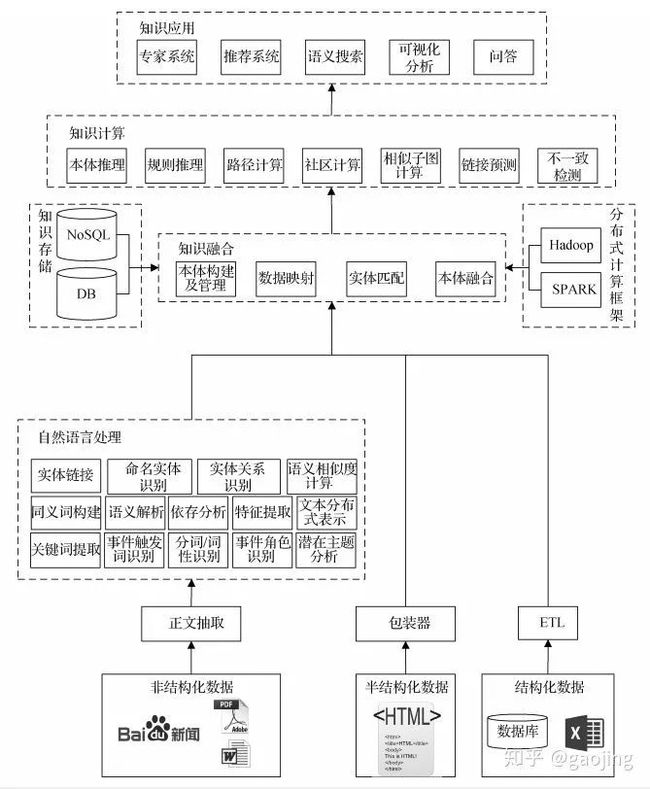
知识图谱整体构建流程
参考文献(略)