案例:PCA对手写数字数据集的降维
文章目录
- 前言
- PCA对手写数字数据集的降维
-
- 1. 导入需要的模块和库
- 2.导入数据,探索数据
- 3.画累计方差贡献率曲线,找最佳降维后维度的范围
- 4.降维后维度的学习曲线,继续缩小最佳维度的范围
- 5. 细化学习曲线,找出降维后的最佳维度
- 6. 导入找出的最佳维度进行降维,查看模型效果
- 7.特征数量已经不足原来的3%,换模型怎么样?
- 8. KNN的k值学习曲线
- 9.定下超参数后,模型效果如何
- 总结
前言
使用手写数字集来进行降维,进行对比
PCA对手写数字数据集的降维
在特征选择时用的此数据集,数据集结构为(42000, 784),用KNN跑一次半小时,用随机森林跑一次12秒,虽然KNN效果好,但由于数据量太大,KNN计算太缓慢,所以我们不得不选用随机森林。我们使用了各种技术对手写数据集进行特征选择,最后使用嵌入法SelectFromModel选出了324个特征,将随机森林的效果也调到了96%以上。但是,因为数据量依然巨大,还是有300多个特征,具体情况请看特征选择,在下面使用PCA来处理数据
1. 导入需要的模块和库
from sklearn.decomposition import PCA #PCA算法
from sklearn.ensemble import RandomForestClassifier as RFC #随机森林分类模型
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.neighbors import KNeighborsClassifier as KNN #KNN算法
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
2.导入数据,探索数据
data = pd.read_csv('digit recognizor.csv')
data.head()

x = data.iloc[:,1:]
y = data.iloc[:,0]
x.shape
>(42000, 784)
y.shape
>(42000,)
3.画累计方差贡献率曲线,找最佳降维后维度的范围
在降维算法PCA和SVD的3.1.6提到,通过不添加n_components,画出累计可解释方差贡献率曲线,以此选择最好的n_components的整数取值。
pca_line = PCA().fit(x)
plt.figure(figsize=[20,5])
#cumsum是累加函数
plt.plot(np.cumsum(pca_line.explained_variance_ratio_))
plt.xlabel("number of components after dimension reduction")
plt.ylabel("cumulative explained variance ratio")
plt.show()

同样在3.1.6提到选择经过拐点的之后线就变得平滑的这个拐点,作为我们所要的特征数量
4.降维后维度的学习曲线,继续缩小最佳维度的范围
score = []
for i in range(1,101,10):
x_dr = PCA(i).fit_transform(x)
once = cross_val_score(RFC(n_estimators=10,random_state=0)
,x_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,101,10),score)
plt.show()

5. 细化学习曲线,找出降维后的最佳维度
score = []
for i in range(10,30):
x_dr = PCA(i).fit_transform(x)
once = cross_val_score(RFC(n_estimators=10,random_state=0)
,x_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(10,30),score)
plt.show()

6. 导入找出的最佳维度进行降维,查看模型效果
x_dr = PCA(25).fit_transform(x)
cross_val_score(RFC(n_estimators=10,random_state=0)
,x_dr,y,cv=5).mean()
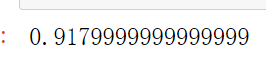
模型效果还好,跑出了91.79%的水平,但还是没有我们使用嵌入法特征选择过后的高,有没有什么办法能够提高模型的表现呢?
7.特征数量已经不足原来的3%,换模型怎么样?
在之前的建模过程中,因为计算量太大,所以我们一直使用随机森林,但事实上,我们知道KNN的效果比随机森林更好,KNN在未调参的状况下已经达到96%的准确率,而随机森林在未调参前只能达93%,这是模型本身的限制带来的,这个数据使用KNN效果就是会更好。现在我们的特征数量已经降到不足原来的3%,可以来试试KNN
#KNN参数不填默认值是5
cross_val_score(KNN(),x_dr,y,cv=5).mean()
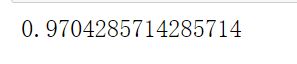
可以看出,评分一下子就提升了特别多,接下来通过学习曲线来寻找一个更好的k值
8. KNN的k值学习曲线
score = []
for i in range(10):
once = cross_val_score(KNN(i+1),x_dr,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(10),score)
plt.show()

9.定下超参数后,模型效果如何
#因为上面的图片下标是在0开始的,所以参数应该是下标+1
cross_val_score(KNN(3),x_dr,y,cv=5).mean()
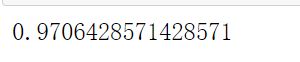
总结
可以发现,原本785列的特征被我们缩减到23列之后,用KNN跑出了目前位置这个数据集上最好的结果。再进行更细致的调整,我们也许可以将KNN的效果调整到98%以上。
PCA为我们提供了无限的可能,有了PCA,不用再因为数据量太庞大而被迫选择更加复杂的模型了
- PCA学习笔记在降维算法PCA和SVD