论文阅读|TransPose
TransPose: Keypoint Localization via Transformer
目录
Abstract
Introduction
Related Work
Human pose estimation
Explainability
Transformer
Method
Architecture
Backbone
Transformer
Head
Resolution Settings
Attentions are the Dependencies of Localized Keypoints
Self-Attention mechanism
The activation maximum positions are the keypoints’locations激活的最大位置是关键点的位置
Experiments
Results on COCO keypoint detection task
Transfer to MPII benchmark
Ablations
The importance of position embedding
Scaling the Size of Transformer Encoder
Position embedding helps to generalize better on unseen input resolutions
Discussion
Qualitative Analysis定性分析
Dependencies and influences vary for different types of keypoints
Attentions gradually focus on more fine-grained de-pendencies with the depth increasing
Image-specific dependencies and statistical commonalities for a single model
Conclusion
Abstract
- 引入transformer进行人体姿态估计,transformer中的注意力层可以使我们捕捉到长程关系并揭示预测的关键点依赖于什么,揭示的依赖关系是特定于图像的,并且是细粒度的,这也可以提供模型如何处理特殊情况(例如遮挡)的证据
- 为了预测关键点热图,最后一个注意力层充当聚合器,它从图像线索中收集贡献并形成关键点的最大位置,符合激活最大化原则
- 实验表明,TransPose算法在COCO验证和测试开发集上实现了75.8 AP和75.0 AP,比主流CNN架构更加轻量级和快速。TransPose模型在MPII基准测试上的迁移也非常好,当用较小的训练成本进行微调时,在测试集上实现了优异的性能。
Introduction
深卷积神经网络在人体姿态估计领域取得了令人印象深刻的性能。DeepPose[56]是早期的经典方法,直接回归关键点的数值坐标位置,之后通过预测关键点热图,隐含地学习身体各部位之间的空间相关性,像[60,36,38,63,12,40,61,51]这样的全卷积网络成为主流。然而,大多数先前的工作都将CNN作为一个强大的黑匣子预测器,并将重点放在改善网络结构上,模型内部到底发生了什么,或者它们如何捕捉身体部位之间的空间关系仍不清楚。
然而,从科学和实践的角度来看,模型的可解释性可以帮助从业者理解模型如何关联结构变量以达到最终预测以及姿态估计器如何处理各种输入图像的能力。 它还可以帮助模型开发人员进行调试、决策和进一步改进设计。
对于现有的姿态估计器,一些问题使得弄清楚他们的决策过程变得具有挑战性。
- Deepness:基于 CNN 的模型,例如 [60, 38, 61, 51],通常是非常深的非线性模型,阻碍了对每一层功能的解释。
- Implicit relationships 隐式关系 :身体部位之间的全局空间关系隐含在神经元激活和 CNN 的权重中。 将这种关系与神经网络中的大量权重和激活分开并不容易。并且单独可视化具有大量通道的中间特征(例如,SimpleBaseline 架构中的 256、512 [61])几乎无法提供有意义的解释。
- Limited working memory in inferrinf various images: 模型预测的所需解释应该是图像特定的和细粒度的。 然而,在推断图像时,由于工作内存有限[23,24,27],静态卷积核在表示变量的能力方面受到限制。 因为它们的参数与内容无关,但输入图像内容却是可变的,因此CNNs 很难捕获特定于图像的依赖关系,。
- Lack of tools:虽然已经有很多基于梯度或属性的可视化技术[19,64,49,48,21,39,69,2],但它们大多侧重于图像分类而不是定位。它们旨在揭示特定类别的输入模式或显著图,而不是解释结构变量之间的关系(例如,关键点的位置)。
到目前为止,如何开发可解释的姿态估计器仍然具有挑战性。
在这项工作中,我们的目标是建立一个人体姿态估计器,它可以显式地捕捉和揭示关键点之间特定于图像的空间相关性,如图1所示。由于卷积[45]的较差的尺度特性,我们认为卷积在提取低级特征方面具有优势,但是在高层深度堆积卷积以扩大感知范围并不能有效地捕获全局相关性。并且这种深度增加了解释 CNN 预测的难度。 Transformer 架构 [58] 在绘制成对或高阶交互方面比 CNN 具有天然的优势。 如图 2 所示,注意力层使模型能够捕获任意成对位置之间的交互,其注意力图充当中间存储器来存储这些依赖关系。
基于这些考虑,我们提出了一种称为Transpose的新模型,该模型在低层使用卷积来提取特征,在高层使用Transformer来捕获全局依赖性。详细地说,我们将特征图平面化作为Transformer的输入,并将其输出恢复到2D结构热图中。在这样的设计中,Transformer 中的最后一个注意力层专门充当聚合器,通过注意力分数收集所有图像位置的不同贡献,最终形成热图中的最大位置。
这种通过 Transformer 进行的关键点定位方法与激活最大化 [19, 49] 的可解释性建立了联系,并将其扩展到定位任务。 由此产生的注意力分数可以表明哪些具体的图像线索对预测位置有显着贡献。 有了这些证据,我们可以通过检验不同实验变量的影响来进一步分析模型的行为。 总结,我们的贡献如下:
- 提出了一种基于热图的人体姿态估计方法,该方法能够有效地捕捉人体各部位之间的空间关系,基于热图预测关键点位置
- 我们证明了我们基于 Transformer 的关键点定位方法符合激活最大化的可解释性 [19, 49]。 定性分析揭示了超出直觉的依赖关系,这些依赖关系是图像特定的和细粒度的
- TransPose 模型通过更少的参数和更快的速度实现了与基于 CNN 的最先进模型的竞争性能。 TransPose 在 COCO 验证集和测试开发集上达到 75.8AP 和 75.0 AP,参数减少 73%,比 HRNet-W48 快 1.4 倍。 此外,我们的模型在 MPII 基准上的迁移非常好。

Figure1: TransPose 的示意图。 下图:推理pipeline。 上图:每个预测关键点位置的依赖区域。 在这个例子中,人的左脚踝被狗挡住了。 模型使用哪些确切的图像线索来推断闭塞关节? 注意力图(红色框)给出了超出直觉的细粒度证据:这样的姿势估计器高度依赖左脚踝、左大腿和右腿关节周围的图像线索来估计被遮挡的左脚踝的位置。

图 2. CNN vs. Attention。 左:感受野在更深的卷积层中扩大。 右:一个自注意力层可以捕获任何一对位置之间的成对关系。
Related Work
Human pose estimation
Explainability
Transformer
Method
我们的目标是建立一个能够显式捕获人体各部分之间的全局依赖关系的模型。我们首先描述模型体系结构。然后,我们展示了它如何利用自我注意来捕捉全局交互,并在我们的方法和激活最大化原则之间建立了联系。
Architecture
如图 3 所示,TransPose 模型由三个部分组成:一个 CNN 主干,用于提取低级图像特征; 一个 Transformer 编码器,用于捕获跨位置的特征向量之间的远程空间交互; 预测关键点热图的head
Backbone
许多常见的 CNN 可以作为主干。 为了更好的比较,我们选择了两种典型的 CNN 架构:ResNet [25] 和 HRNet [51]。 我们只保留原始 ImageNet 预训练 CNN 的最初几个部分,以从图像中提取特征。 我们将它们命名为 ResNet-S 和 HRNet-S,其参数数量仅为原始 CNN 的 5.5% 和 25% 左右。
Transformer
我们尽可能地遵循标准的Transformer架构。 并且只使用了编码器,因为我们认为纯热图预测任务只是一个编码任务,它将原始图像信息压缩成关键点的紧凑位置表示。 给定一个输入图像![]() ,我们假设CNN主干输出一个二维空间结构图像特征
,我们假设CNN主干输出一个二维空间结构图像特征![]() ,其特征维度已经通过1×1卷积转换为d。 然后,将图像特征图展平为序列
,其特征维度已经通过1×1卷积转换为d。 然后,将图像特征图展平为序列![]() ,即 L个d 维特征向量,其中 L = H ×W。 它经过 N 个注意力层和前馈网络 (FFN)。
,即 L个d 维特征向量,其中 L = H ×W。 它经过 N 个注意力层和前馈网络 (FFN)。
Head
一个头附加到Transformer Encoder 的输出![]() ,以预测 K 类型的关键点 heatmaps
,以预测 K 类型的关键点 heatmaps ![]() ,其中在默认情况下
,其中在默认情况下![]() 。 我们首先将 E 重新整形为
。 我们首先将 E 重新整形为![]() 形状,然后我们主要使用1×1卷积将E的通道维度从d减少到K。如果H,W不等于
形状,然后我们主要使用1×1卷积将E的通道维度从d减少到K。如果H,W不等于![]() ,则使用额外的双线性插值或4×4转置卷积进行上采样。在 1×1 卷积之前。 请注意,1×1 卷积完全等效于位置线性变换层。
,则使用额外的双线性插值或4×4转置卷积进行上采样。在 1×1 卷积之前。 请注意,1×1 卷积完全等效于位置线性变换层。
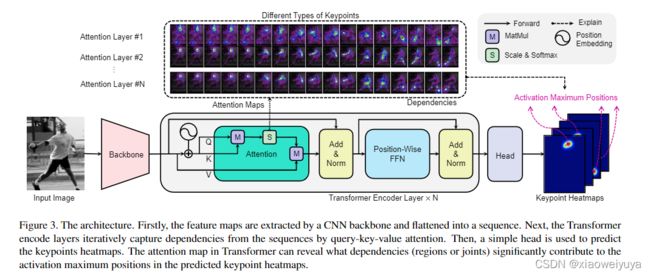
Figure3:架构。 首先,特征图由 CNN 主干提取并展平为序列。 接下来,Transformer encoder层通过 query-key-value attention 迭代地从序列中捕获依赖关系。 然后,使用一个简单的头部来预测关键点热图。 Transformer 中的注意力图可以揭示哪些依赖项(区域或关节)对预测的关键点热图中的激活最大位置有显着贡献。
Resolution Settings
由于每个自注意力层的计算复杂度为![]() ,我们限制注意力层以 r倍于原始输入的分辨率运行,即
,我们限制注意力层以 r倍于原始输入的分辨率运行,即 ![]() 。 在常见的人体姿态估计架构 [60, 38,61, 51] 中,通常采用 32 倍下采样作为标准设置,以获得包含全局信息的低分辨率图。 相比之下,我们对 ResNet-S 和 HRNet-S 采用 r = 8 和 r = 4 设置,这有利于在注意力层的内存占用和详细信息的损失之间进行权衡。因此我们的模型在保持细粒度局部特征信息的同时,以更高的分辨率直接捕捉远程交互作用。
。 在常见的人体姿态估计架构 [60, 38,61, 51] 中,通常采用 32 倍下采样作为标准设置,以获得包含全局信息的低分辨率图。 相比之下,我们对 ResNet-S 和 HRNet-S 采用 r = 8 和 r = 4 设置,这有利于在注意力层的内存占用和详细信息的损失之间进行权衡。因此我们的模型在保持细粒度局部特征信息的同时,以更高的分辨率直接捕捉远程交互作用。
Attentions are the Dependencies of Localized Keypoints
Self-Attention mechanism
multi-head self-attention是transformer的核心点。它首先将输入的序列![]() 通过三个矩阵
通过三个矩阵![]() 映射到
映射到![]() ,然后通过以下公式计算注意力得分矩阵
,然后通过以下公式计算注意力得分矩阵![]()
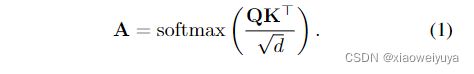
每个token的 xi ∈Rd(即位置 i 处的特征向量)的每个查询 qi ∈Rd 计算与所有key的相似度以获得权重向量 wi = Ai,: ∈ R1×L,这决定了需要多少依赖来自前一个序列中的每个token。然后通过将值矩阵 V 中的所有元素与 wi 中的相应权重进行线性求和并添加到 xi 来实现增量。 通过这样做,注意力图可以被视为由特定图像内容确定的动态权重,在前向传播中重新加权信息流。
Self-attention捕获并揭示从每个图像位置预测的贡献。来自不同图像位置的这种贡献可以通过梯度[49、2、48]来反映。 因此,我们具体分析图像/序列位置 j 处的 xj如何影响预测关键点热图中位置 i 处的激活 hi,通过计算![]() (K种关键点)对 xj 在位置 j 处的导数(最后一个注意力层的输入序列xj)。然后我们进一步假设函数
(K种关键点)对 xj 在位置 j 处的导数(最后一个注意力层的输入序列xj)。然后我们进一步假设函数![]() ,在给定注意力分数
,在给定注意力分数![]() 下可以获得:
下可以获得:

![]() 是静态权重(推断时固定)并且在所有图像位置之间共享。公式2的推导显示在补充中。 我们可以看到函数 G 与 Ai,j 近似线性,即对预测hi的贡献程度直接取决于其在图像位置的注意力分数。
是静态权重(推断时固定)并且在所有图像位置之间共享。公式2的推导显示在补充中。 我们可以看到函数 G 与 Ai,j 近似线性,即对预测hi的贡献程度直接取决于其在图像位置的注意力分数。
特别是,最后一个注意力层充当聚合器,它根据注意力收集所有图像位置的贡献,并在预测的关键点热图中形成最大激活。 尽管 FFN 和 head 中的层不能忽略,但它们是位置相关(position-wise)的,这意味着它们通过相同的变换近似线性地变换来自所有位置的贡献,而不改变它们的相对比例。
The activation maximum positions are the keypoints’locations激活的最大位置是关键点的位置
激活最大化(AM)的可解释性在于:能够最大化给定神经元激活的输入区域可以解释这个被激活的神经元在寻找什么。(输入区域可以解释被激活的神经元在寻找什么,而给定神经元激活最大化的位置就是寻找的内容)
TransPose 的学习目标是期望热图的位置 i* 处的神经元激活 hi* 被最大程度地激活,其中 i* 表示关键点的 groundtruth位置:

假设模型已经使用参数 θ∗ 进行了优化,并且它预测特定关键点的位置为 i(热图中的最大位置),那么为什么模型预测这样的预测可以通过以下事实来解释:那些位置 J,其元素j对i具有的较高注意力分数 (≥δ) 是对预测有显着贡献的依赖项。 可以通过以下方式找到依赖项:
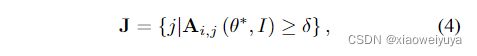
![]() 是最后一个注意力层的注意力图,也是一个关于 θ∗和I的函数。给定一张输入图像I和查询位置i,Ai:可以揭示预测位置i高度依赖于什么,将其定义为依赖区域
是最后一个注意力层的注意力图,也是一个关于 θ∗和I的函数。给定一张输入图像I和查询位置i,Ai:可以揭示预测位置i高度依赖于什么,将其定义为依赖区域![]() (dependency area),依赖区域可以揭示j主要影响的区域,定义为受影响区域(affected area)。
(dependency area),依赖区域可以揭示j主要影响的区域,定义为受影响区域(affected area)。
对于传统的基于 CNN 的方法,他们也使用热图激活作为关键点位置,但由于深度 CNN 的深度和高度非线性,人们无法直接找到预测的可解释模式。基于 AM 的方法 [19、32、64、49] 可以提供洞察力,但它们需要额外的优化成本来学习卷积核更喜欢寻找的可解释模式。 与他们不同的是,我们通过 Transformer 将 AM 扩展到基于热图的定位,并且我们不需要额外的优化成本,因为优化已经在我们的训练中隐式完成,即 A = A(θ∗,I)。定义的依赖区域是我们寻找的模式,它可以显示特定于图像和关键点的依赖关系。
Experiments
数据集:COCO和MPII
细节:遵循top-down的范例,输入图像调整为256×192,使用了与HRNet相同的训练策略、数据增强和人员检测结果。采用了DARK提出的坐标译码策略来减小从降维的热图译码的误差。前馈层设置随机失活dropout为0.1并且采用RELU激活函数,TransPose-R(TP-R)基于ResNet-s,TransPose-H(TP-H)基于ResNet-H,详细信息如表1所示。d是Transformer中的token维度,h是the number of hidden units of FFN(Table 7中有说明) 参数量:ResNet输入的尺寸更小,因此可以使用更大的d和h; HRNet输入尺寸更大,所以用了小一些的d和h

考虑到与骨干网的兼容性和内存消耗,我们调整了 Transformer 编码器的超参数,使模型容量不是很大。 此外,我们使用 2D 正弦位置嵌入作为默认位置嵌入。 我们在补充中对其进行了描述。
Results on COCO keypoint detection task


Transfer to MPII benchmark
典型的姿态估计方法通常在 COCO 和 MPII [1] 上分别训练和评估他们的模型。 受到 NLP 预训练和最近的 ViT [18] 成功的激励,我们尝试将我们的预训练模型迁移到 MPII。 我们将预训练的 TransPose 模型的最后一层替换为 MPII 的统一初始化的 d ×16 线性层。 微调时,预训练层和最终层的学习率分别为 1e-5 和 1e-4,有衰减。
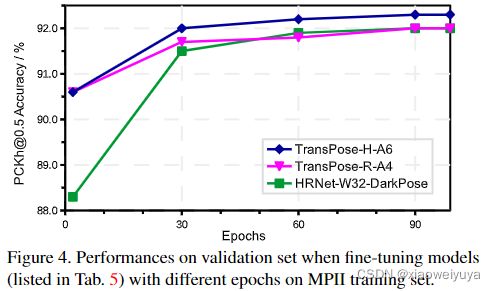
为了进行比较,我们使用相同的设置在 MPII 上微调预训练的 DARK-HRNet,并通过标准的全训练设置在 MPII 上训练这些模型。 如图所示。 从figure 5和table 4 可以看出,结果很有趣:即使经过更长的全训练时期,模型的表现也比微调过的更差; 即使模型容量很大(28.5M),预训练 DARK-HRNet 带来的提升(+1.4 AP)也小于预训练 TransPose(+2.0 AP)。在 MPII train 和 val 集上使用 256×256 输入分辨率和微调,TransPose-H-A6 在 MPII 测试集上产生的最佳结果是 93.5% 的准确率,如图 6 所示。这些结果表明,预训练和微调可以显着降低训练成本并提高性能,特别是对于预训练的 TransPose 模型。
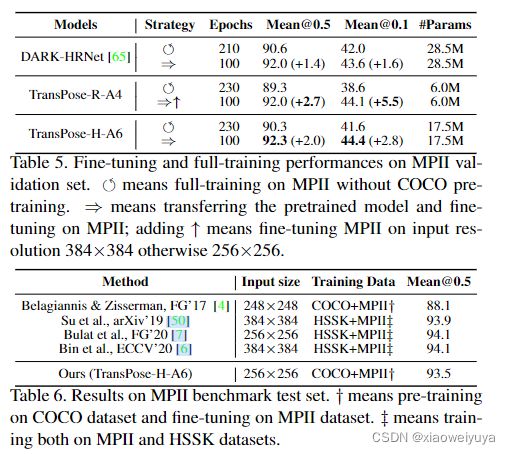
基于 Transformer 的模型的预训练和微调在 NLP [17, 44] 和最近的视觉模型 [18, 11, 16] 中显示出良好的结果。 我们在 MPII 上的初步结果还表明,在大规模姿势相关数据上训练基于 Transformer 的模型可能是学习用于人体姿势估计及其下游任务的强大且稳健的表示的有前途的方法。
Ablations
The importance of position embedding
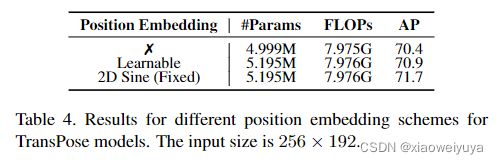
在没有位置嵌入的情况下,2D 空间结构信息会在 Transformer 中丢失。 为了探索其重要性,我们对具有三种位置嵌入策略的 TransPose-R-A3 模型进行了实验:2D 正弦位置嵌入、可学习位置嵌入和无位置嵌入。 正如预期的那样,具有位置嵌入的模型表现更好,特别是对于 2D 正弦位置嵌入,如表 4 所示。但有趣的是,没有任何位置嵌入的 TransPose 仅损失 1.3 AP,这表明 2D 结构变得不那么重要了。
Scaling the Size of Transformer Encoder
我们研究了性能如何随着 Transformer Encoder 的大小而变化,如表 7 所示。对于 TransPose-R 模型,随着层数增加到 6,性能改进逐渐趋于饱和或退化。 但我们还没有在 TransPose-H 模型上观察到这种现象。 缩放 Transformer 明显提高了 TransPose-H 的性能。

Position embedding helps to generalize better on unseen input resolutions
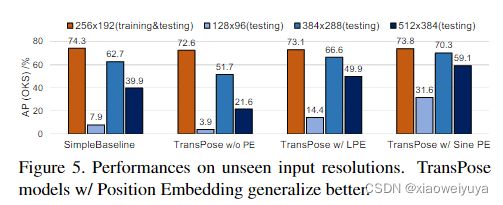
自上而下的范例将所有裁剪的图像缩放到固定大小。 但在某些情况下,即使输入大小固定或自下而上范式,输入中的主体大小也会有所不同; 对不同尺度的鲁棒性变得很重要。 所以我们设计了一个极端的实验来测试泛化性:我们在看不见的 128×96,384×288、512×388 输入分辨率上测试 SimpleBaseline-ResN50-Dark 和 TransPose-R-A3 模型,所有这些都只用 256×192 训练过 尺寸。 有趣的是,图 5 中的结果表明 SimpleBaseline 和 TransPose-R w/o position embedding 在不可见的分辨率上具有明显的性能崩溃,尤其是在 128×96 上; 但是具有可学习或 2D Sine 位置嵌入的 TransPose-R 具有明显更好的泛化能力,尤其是对于 2D Sine 位置嵌入。
Discussion
对于输入分辨率,我们主要在 256×192 大小上训练我们的模型,因此 TP-R 和 TP-H 模型中的 Transformer 的序列长度为 768 和 3072。 由于二次复杂性,我们当前模型的更高输入分辨率(例如 384×288)将在自注意力层中带来非常昂贵的计算成本。
Qualitative Analysis定性分析
TransPose 模型的超参数配置可能会以未知的方式影响其行为。 在本节中,我们选择训练好的模型、预测关键点的类型、注意力层的深度和输入图像作为控制变量来观察模型的行为。
Dependencies and influences vary for different types of keypoints
对于头部的关键点,定位主要依靠头部的视觉线索,但TP-H-A4也将它们与肩膀和手臂的关节联系起来。 值得注意的是,两个模型预测手腕、肘部、膝盖或脚踝的依赖关系有明显差异,其中TP-R-A4依赖于同侧的局部线索,而TP-H-A4则利用了更多来自对称关节的线索 边。 如图 6(b)、图 6(d) 和图 7 所示,我们可以进一步观察到,姿势估计器可能会从更多部分收集强线索来预测目标关键点。这可以解释为什么模型仍然可以准确预测被遮挡关键点的位置,位置不明确的被遮挡关键点对其他预测的影响较小或依赖较大的不确定区域(例如被遮挡的左脚踝-图6(c)或图6的最后一张图。 6(d))。
Attentions gradually focus on more fine-grained de-pendencies with the depth increasing
观察所有的注意力层(图 7 的第 1、2、3 行),我们惊奇地发现,即使没有中间 GT 位置监督,TP-H-A4 仍然可以关注关节的准确位置,而且还有更多 早期注意层中的全局线索。对于这两个模型,随着深度的增加,预测逐渐依赖于局部部分或关键点位置周围更细粒度的图像线索(图 7)。
Image-specific dependencies and statistical commonalities for a single model
与训练后编码在 CNN 权重中的静态关系不同,注意力图对输入是动态的。 如图所示。 在图 6(a) 和图 6(c) 中,我们可以观察到,尽管预测关键点的依赖关系具有统计共性(大多数常见图像的行为相似),但细粒度的依赖关系会根据 图像上下文。 由于输入B等给定图像中存在遮挡或不可见(图6(c)),该模型仍然可以通过寻找更重要的图像线索来定位部分遮挡的关键点的位置,并减少对不可见关键点的依赖来预测 其他的。 未来的工作很可能可以利用这种注意力模式进行部分到整体的关联,并为 3D 姿势估计或动作识别聚合相关特征。
Conclusion
我们通过引入用于人体姿态估计的Transformer 探索了一个模型——TransPose。 注意力层使模型能够有效且明确地捕获全局空间依赖性。 我们展示了 Transformer 实现的这种基于热图的定位使我们的模型与 Activation Maximization激活最大化共享这个想法。通过轻量级的架构,Transspose在CoCo上与基于CNN的同类产品相媲美,并且在以较小的培训成本进行微调时,在MPII上获得了显著的改进。 此外,我们验证了位置嵌入的重要性。 我们的定性分析揭示了模型随层深、关键点类型、训练模型和输入图像的不同而变化,这也让我们深入了解模型如何处理特殊情况,例如遮挡。