PaddleHub实战篇{ERNIE实现文新闻本分类、ERNIE3.0 实现序列标注}【四】
相关文章:
基础知识介绍:
【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?_汀、的博客-CSDN博客_ernie模型
百度飞桨:ERNIE 3.0 、通用信息抽取 UIE、paddleNLP的安装使用[一]_汀、的博客-CSDN博客_paddlenlp 安装
项目实战:
PaddleHub--飞桨预训练模型应用工具{风格迁移模型、词法分析情感分析、Fine-tune API微调}【一】_汀、的博客-CSDN博客
PaddleHub--{超参优化AutoDL Finetuner}【二】_汀、的博客-CSDN博客
PaddleHub实战篇{词法分析模型LAC、情感分类ERNIE Tiny}训练、部署【三】_汀、的博客-CSDN博客
PaddleHub实战篇{ERNIE实现文新闻本分类、ERNIE3.0 实现序列标注}【四】_汀、的博客-CSDN博客
通过前面几篇文章大家都有一定了解,下面直接上代码讲解
1.ERNIE实现文新闻本分类
用最新版本paddlenlp和paddle!
项目链接:ERNIE实现新闻文本分类 -
!pip install --upgrade paddlenlp
!pip install -U paddlehub
#安装import paddlehub as hub
import paddle
model = hub.Module(name="ernie", task='seq-cls', num_classes=14) # 在多分类任务中,num_classes需要显式地指定类别数,此处根据数据集设置为14hub.Module的参数用法如下:
name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased,bert-base-chinese,roberta-wwm-ext,roberta-wwm-ext-large等。task:fine-tune任务。此处为seq-cls,表示文本分类任务。num_classes:表示当前文本分类任务的类别数,根据具体使用的数据集确定,默认为2。
NOTE: 文本多分类的任务中,num_classes需要用户指定,具体的类别数根据选用的数据集确定,本教程中为14。


PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name='ernie') |
| ERNIE tiny, Chinese | hub.Module(name='ernie_tiny') |
| ERNIE 2.0 Base, English | hub.Module(name='ernie_v2_eng_base') |
| ERNIE 2.0 Large, English | hub.Module(name='ernie_v2_eng_large') |
| BERT-Base, English Cased | hub.Module(name='bert-base-cased') |
| BERT-Base, English Uncased | hub.Module(name='bert-base-uncased') |
| BERT-Large, English Cased | hub.Module(name='bert-large-cased') |
| BERT-Large, English Uncased | hub.Module(name='bert-large-uncased') |
| BERT-Base, Multilingual Cased | hub.Module(nane='bert-base-multilingual-cased') |
| BERT-Base, Multilingual Uncased | hub.Module(nane='bert-base-multilingual-uncased') |
| BERT-Base, Chinese | hub.Module(name='bert-base-chinese') |
| BERT-wwm, Chinese | hub.Module(name='chinese-bert-wwm') |
| BERT-wwm-ext, Chinese | hub.Module(name='chinese-bert-wwm-ext') |
| RoBERTa-wwm-ext, Chinese | hub.Module(name='roberta-wwm-ext') |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name='roberta-wwm-ext-large') |
| RBT3, Chinese | hub.Module(name='rbt3') |
| RBTL3, Chinese | hub.Module(name='rbtl3') |
| ELECTRA-Small, English | hub.Module(name='electra-small') |
| ELECTRA-Base, English | hub.Module(name='electra-base') |
| ELECTRA-Large, English | hub.Module(name='electra-large') |
| ELECTRA-Base, Chinese | hub.Module(name='chinese-electra-base') |
| ELECTRA-Small, Chinese | hub.Module(name='chinese-electra-small') |
通过以上的一行代码,model初始化为一个适用于文本分类任务的模型,为ERNIE的预训练模型后拼接上一个全连接网络(Full Connected
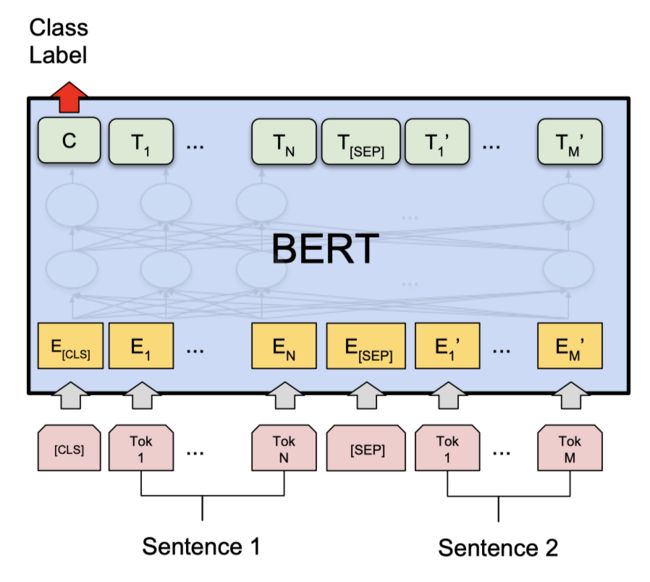
1.1: 加载自定义数据集
本示例数据集是由清华大学提供的新闻文本数据集THUCNews。THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。为了快速展示如何使用PaddleHub完成文本分类任务,该示例数据集从THUCNews训练集中随机抽取了9000条文本数据集作为本示例的训练集,从验证集中14个类别每个类别随机抽取100条数据作为本示例的验证集,测试集抽取方式和验证集相同。
数据集:https://aistudio.baidu.com/aistudio/projectdetail/4153654
首先解压数据集。
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory. This directory will be recovered automatically after resetting environment.
%cd /home/aistudio/data/data16287/
!tar -zxvf thu_news.tar.gz
!ls -hl thu_news
!head -n 3 thu_news/train.txt加载自定义数据集,用户仅需要继承TextClassificationDataset类。 下面代码示例展示如何将自定义数据集加载进PaddleHub使用。
具体详情可参考 加载自定义数据集
import os, io, csv
from paddlehub.datasets.base_nlp_dataset import InputExample, TextClassificationDataset
# 数据集存放位置
DATA_DIR="/home/aistudio/data/data16287/thu_news"class ThuNews(TextClassificationDataset):
def __init__(self, tokenizer, mode='train', max_seq_len=128):
if mode == 'train':
data_file = 'train.txt'
elif mode == 'test':
data_file = 'test.txt'
else:
data_file = 'valid.txt'
super(ThuNews, self).__init__(
base_path=DATA_DIR,
data_file=data_file,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
is_file_with_header=True,
label_list=['体育', '科技', '社会', '娱乐', '股票', '房产', '教育', '时政', '财经', '星座', '游戏', '家居', '彩票', '时尚'])
# 解析文本文件里的样本
def _read_file(self, input_file, is_file_with_header: bool = False):
if not os.path.exists(input_file):
raise RuntimeError("The file {} is not found.".format(input_file))
else:
with io.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\t", quotechar=None)
examples = []
seq_id = 0
header = next(reader) if is_file_with_header else None
for line in reader:
example = InputExample(guid=seq_id, text_a=line[0], label=line[1])
seq_id += 1
examples.append(example)
return examples
train_dataset = ThuNews(model.get_tokenizer(), mode='train', max_seq_len=128)
dev_dataset = ThuNews(model.get_tokenizer(), mode='dev', max_seq_len=128)
test_dataset = ThuNews(model.get_tokenizer(), mode='test', max_seq_len=128)
for e in train_dataset.examples[:3]:
print(e)NOTE: 最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但最大不超过512。
1.2: 选择优化策略和运行配置
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters()) # 优化器的选择和参数配置
trainer = hub.Trainer(model, optimizer, checkpoint_dir='./ckpt', use_gpu=True) # fine-tune任务的执行者优化策略
Paddle2.0-rc提供了多种优化器选择,如SGD, Adam, Adamax等,详细参见策略。
在本教程中选择了Adam优化器,其的参数用法:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
运行配置
Trainer 主要控制Fine-tune任务的训练,是任务的发起者,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_gpu: 是否使用gpu训练;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
1.3: 执行fine-tune并评估模型
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset, save_interval=1) # 配置训练参数,启动训练,并指定验证集[2022-01-19 15:02:20,462] [ TRAIN] - Epoch=3/3, Step=170/282 loss=0.0352 acc=0.9875 lr=0.000050 step/sec=4.33 | ETA 00:04:31
[2022-01-19 15:02:22,777] [ TRAIN] - Epoch=3/3, Step=180/282 loss=0.1361 acc=0.9656 lr=0.000050 step/sec=4.32 | ETA 00:04:30
[2022-01-19 15:02:25,096] [ TRAIN] - Epoch=3/3, Step=190/282 loss=0.0730 acc=0.9844 lr=0.000050 step/sec=4.31 | ETA 00:04:29
[2022-01-19 15:02:27,415] [ TRAIN] - Epoch=3/3, Step=200/282 loss=0.0645 acc=0.9875 lr=0.000050 step/sec=4.31 | ETA 00:04:28
[2022-01-19 15:02:29,729] [ TRAIN] - Epoch=3/3, Step=210/282 loss=0.0652 acc=0.9844 lr=0.000050 step/sec=4.32 | ETA 00:04:27
[2022-01-19 15:02:32,048] [ TRAIN] - Epoch=3/3, Step=220/282 loss=0.1083 acc=0.9594 lr=0.000050 step/sec=4.31 | ETA 00:04:26
[2022-01-19 15:02:34,362] [ TRAIN] - Epoch=3/3, Step=230/282 loss=0.1116 acc=0.9656 lr=0.000050 step/sec=4.32 | ETA 00:04:25
[2022-01-19 15:02:36,673] [ TRAIN] - Epoch=3/3, Step=240/282 loss=0.1040 acc=0.9656 lr=0.000050 step/sec=4.33 | ETA 00:04:24
[2022-01-19 15:02:38,976] [ TRAIN] - Epoch=3/3, Step=250/282 loss=0.0556 acc=0.9844 lr=0.000050 step/sec=4.34 | ETA 00:04:23
[2022-01-19 15:02:41,289] [ TRAIN] - Epoch=3/3, Step=260/282 loss=0.0755 acc=0.9750 lr=0.000050 step/sec=4.32 | ETA 00:04:22
[2022-01-19 15:02:43,607] [ TRAIN] - Epoch=3/3, Step=270/282 loss=0.1749 acc=0.9563 lr=0.000050 step/sec=4.31 | ETA 00:04:22
[2022-01-19 15:02:45,918] [ TRAIN] - Epoch=3/3, Step=280/282 loss=0.1602 acc=0.9594 lr=0.000050 step/sec=4.33 | ETA 00:04:21result = trainer.evaluate(test_dataset, batch_size=32) # 在测试集上评估当前训练模型1.4、使用模型进行预测
当Finetune完成后,我们加载训练后保存的最佳模型来进行预测,完整预测代码如下:
# Data to be prdicted
data = [
# 房产
["昌平京基鹭府10月29日推别墅1200万套起享97折 新浪房产讯(编辑郭彪)京基鹭府(论坛相册户型样板间点评地图搜索)售楼处位于昌平区京承高速北七家出口向西南公里路南。项目预计10月29日开盘,总价1200万元/套起,2012年年底入住。待售户型为联排户型面积为410-522平方米,独栋户型面积为938平方米,双拼户型面积为522平方米。 京基鹭府项目位于昌平定泗路与东北路交界处。项目周边配套齐全,幼儿园:伊顿双语幼儿园、温莎双语幼儿园;中学:北师大亚太实验学校、潞河中学(北京市重点);大学:王府语言学校、北京邮电大学、现代音乐学院;医院:王府中西医结合医院(三级甲等)、潞河医院、解放军263医院、安贞医院昌平分院;购物:龙德广场、中联万家商厦、世纪华联超市、瑰宝购物中心、家乐福超市;酒店:拉斐特城堡、鲍鱼岛;休闲娱乐设施:九华山庄、温都温泉度假村、小汤山疗养院、龙脉温泉度假村、小汤山文化广场、皇港高尔夫、高地高尔夫、北鸿高尔夫球场;银行:工商银行、建设银行、中国银行、北京农村商业银行;邮局:中国邮政储蓄;其它:北七家建材城、百安居建材超市、北七家镇武装部、北京宏翔鸿企业孵化基地等,享受便捷生活。"],
# 游戏
["尽管官方到今天也没有公布《使命召唤:现代战争2》的游戏详情,但《使命召唤:现代战争2》首部包含游戏画面的影片终于现身。虽然影片仅有短短不到20秒,但影片最后承诺大家将于美国时间5月24日NBA职业篮球东区决赛时将会揭露更多的游戏内容。 这部只有18秒的广告片闪现了9个镜头,能够辨识的场景有直升机飞向海岛军事工事,有飞机场争夺战,有潜艇和水下工兵,有冰上乘具,以及其他的一些镜头。整体来看《现代战争2》很大可能仍旧与俄罗斯有关。 片尾有一则预告:“May24th,EasternConferenceFinals”,这是什么?这是说当前美国NBA联赛东部总决赛的日期。原来这部视频是NBA季后赛奥兰多魔术对波士顿凯尔特人队时,TNT电视台播放的广告。"],
# 体育
["罗马锋王竟公然挑战两大旗帜拉涅利的球队到底错在哪 记者张恺报道主场一球小胜副班长巴里无可吹捧,罗马占优也纯属正常,倒是托蒂罚失点球和前两号门将先后受伤(多尼以三号身份出场)更让人揪心。阵容规模扩大,反而表现不如上赛季,缺乏一流强队的色彩,这是所有球迷对罗马的印象。 拉涅利说:“去年我们带着嫉妒之心看国米,今年我们也有了和国米同等的超级阵容,许多教练都想有罗马的球员。阵容广了,寻找队内平衡就难了,某些时段球员的互相排斥和跟从前相比的落差都正常。有好的一面,也有不好的一面,所幸,我们一直在说一支伟大的罗马,必胜的信念和够级别的阵容,我们有了。”拉涅利的总结由近一阶段困扰罗马的队内摩擦、个别球员闹意见要走人而发,本赛季技术层面强化的罗马一直没有上赛季反扑的面貌,内部变化值得球迷关注。"],
# 教育
["新总督致力提高加拿大公立教育质量 滑铁卢大学校长约翰斯顿先生于10月1日担任加拿大总督职务。约翰斯顿先生还曾任麦吉尔大学长,并曾在多伦多大学、女王大学和西安大略大学担任教学职位。 约翰斯顿先生在就职演说中表示,要将加拿大建设成为一个“聪明与关爱的国度”。为实现这一目标,他提出三个支柱:支持并关爱家庭、儿童;鼓励学习与创造;提倡慈善和志愿者精神。他尤其强调要关爱并尊重教师,并通过公立教育使每个人的才智得到充分发展。"]
]
label_list=['体育', '科技', '社会', '娱乐', '股票', '房产', '教育', '时政', '财经', '星座', '游戏', '家居', '彩票', '时尚']
label_map = {
idx: label_text for idx, label_text in enumerate(label_list)
}
model = hub.Module(
name='ernie',
task='seq-cls',
load_checkpoint='./ckpt/best_model/model.pdparams',
label_map=label_map)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))Data: 昌平京基鹭府10月29日推别墅1200万套起享97折 新浪房产讯(编辑郭彪)京基鹭府(论坛相册户型样板间点评地图搜索)售楼处位于昌平区京承高速北七家出口向西南公里路南。项目预计10月29日开盘,总价1200万元/套起,2012年年底入住。待售户型为联排户型面积为410-522平方米,独栋户型面积为938平方米,双拼户型面积为522平方米。 京基鹭府项目位于昌平定泗路与东北路交界处。项目周边配套齐全,幼儿园:伊顿双语幼儿园、温莎双语幼儿园;中学:北师大亚太实验学校、潞河中学(北京市重点);大学:王府语言学校、北京邮电大学、现代音乐学院;医院:王府中西医结合医院(三级甲等)、潞河医院、解放军263医院、安贞医院昌平分院;购物:龙德广场、中联万家商厦、世纪华联超市、瑰宝购物中心、家乐福超市;酒店:拉斐特城堡、鲍鱼岛;休闲娱乐设施:九华山庄、温都温泉度假村、小汤山疗养院、龙脉温泉度假村、小汤山文化广场、皇港高尔夫、高地高尔夫、北鸿高尔夫球场;银行:工商银行、建设银行、中国银行、北京农村商业银行;邮局:中国邮政储蓄;其它:北七家建材城、百安居建材超市、北七家镇武装部、北京宏翔鸿企业孵化基地等,享受便捷生活。 Lable: 房产
Data: 尽管官方到今天也没有公布《使命召唤:现代战争2》的游戏详情,但《使命召唤:现代战争2》首部包含游戏画面的影片终于现身。虽然影片仅有短短不到20秒,但影片最后承诺大家将于美国时间5月24日NBA职业篮球东区决赛时将会揭露更多的游戏内容。 这部只有18秒的广告片闪现了9个镜头,能够辨识的场景有直升机飞向海岛军事工事,有飞机场争夺战,有潜艇和水下工兵,有冰上乘具,以及其他的一些镜头。整体来看《现代战争2》很大可能仍旧与俄罗斯有关。 片尾有一则预告:“May24th,EasternConferenceFinals”,这是什么?这是说当前美国NBA联赛东部总决赛的日期。原来这部视频是NBA季后赛奥兰多魔术对波士顿凯尔特人队时,TNT电视台播放的广告。 Lable: 游戏
Data: 罗马锋王竟公然挑战两大旗帜拉涅利的球队到底错在哪 记者张恺报道主场一球小胜副班长巴里无可吹捧,罗马占优也纯属正常,倒是托蒂罚失点球和前两号门将先后受伤(多尼以三号身份出场)更让人揪心。阵容规模扩大,反而表现不如上赛季,缺乏一流强队的色彩,这是所有球迷对罗马的印象。 拉涅利说:“去年我们带着嫉妒之心看国米,今年我们也有了和国米同等的超级阵容,许多教练都想有罗马的球员。阵容广了,寻找队内平衡就难了,某些时段球员的互相排斥和跟从前相比的落差都正常。有好的一面,也有不好的一面,所幸,我们一直在说一支伟大的罗马,必胜的信念和够级别的阵容,我们有了。”拉涅利的总结由近一阶段困扰罗马的队内摩擦、个别球员闹意见要走人而发,本赛季技术层面强化的罗马一直没有上赛季反扑的面貌,内部变化值得球迷关注。 Lable: 体育
Data: 新总督致力提高加拿大公立教育质量 滑铁卢大学校长约翰斯顿先生于10月1日担任加拿大总督职务。约翰斯顿先生还曾任麦吉尔大学长,并曾在多伦多大学、女王大学和西安大略大学担任教学职位。 约翰斯顿先生在就职演说中表示,要将加拿大建设成为一个“聪明与关爱的国度”。为实现这一目标,他提出三个支柱:支持并关爱家庭、儿童;鼓励学习与创造;提倡慈善和志愿者精神。他尤其强调要关爱并尊重教师,并通过公立教育使每个人的才智得到充分发展。 Lable: 教育ERNIE实现新闻文本分类 - 项目链接
2.ERNIE 3.0--MSRA序列标注实战
!pip install --upgrade paddlenlp
!pip install -U paddlehubPaddleHub2.0——使用动态图版预训练模型ERNIE实现序列标注
2.1. 什么是序列标注
序列标注(Sequence Tagging)是经典的自然语言处理问题,可以用于解决一系列字符分类问题,例如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)。在现实场景中,序列标注技术可以帮助完成简历、快递单、病例医疗实体信息抽取等。
在序列标注任务中,一般会定义一个标签集合来表示所有预测结果。对于输入的序列,任务目标是对序列中所有字符进行标记。在深度学习中,通常将序列标注问题视为分类问题,对输入序列的每一个token进行一次多分类任务进行训练预测。
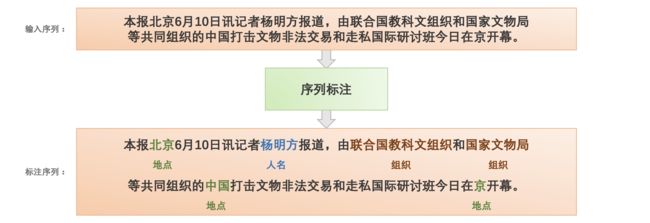
ERNIE 3.0框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。
2.3. ERNIE 3.0中文预训练模型进行MSRA序列标注
2.3.1 环境准备
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。使用如下命令确保安装最新版PaddleNLP:
import os
import paddle
import paddlenlp2.3.2 加载MSRA-NER数据集
MSRA-NER 数据集由微软亚研院发布,其目标是识别文本中具有特定意义的实体,主要包括人名、地名、机构名等。PaddleNLP已经内置该数据集,一键即可加载。PaddleNLP集成的数据集MSRA-NER数据集对文件格式做了调整:每一行文本、标签以特殊字符"\t"进行分隔,每个字之间以特殊字符"\002"分隔。示例如下:
不\002久\002前\002,\002中\002国\002共\002产\002党\002召\002开\002了\002举\002世\002瞩\002目\002的\002第\002十\002五\002次\002全\002国\002代\002表\002大\002会\002。O\002O\002O\002O\002B-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002O\002O\002O\002O\002O\002O\002O\002O\002B-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002I-ORG\002O
这\002次\002代\002表\002大\002会\002是\002在\002中\002国\002改\002革\002开\002放\002和\002社\002会\002主\002义\002现\002代\002化\002建\002设\002发\002展\002的\002关\002键\002时\002刻\002召\002开\002的\002历\002史\002性\002会\002议\002。O\002O\002O\002O\002O\002O\002O\002O\002B-LOC\002I-LOC\002O\002O\002O\002O\002O\002O\002O\002O\002O\002O\002O\002O加载MSRA_NER数据集为BIO标注集:
- B-PER、I-PER代表人名首字、人名非首字。
- B-LOC、I-LOC代表地名首字、地名非首字。
- B-ORG、I-ORG代表组织机构名首字、组织机构名非首字。
- O代表该字不属于命名实体的一部分。
# 加载MSRA_NER数据集
from paddlenlp.datasets import load_dataset
train_ds, test_ds = load_dataset('msra_ner', splits=('train', 'test'), lazy=False)
label_vocab = {label:label_id for label_id, label in enumerate(train_ds.label_list)}
# 数据集返回类型为MapDataset
print("数据类型:", type(train_ds))
print("数据标签:", label_vocab)
# 每条数据包含一句文本和这个文本中每个汉字以及数字对应的label标签
print("训练集样例:", train_ds[0])
print("测试集样例:", test_ds[0])数据类型:
数据标签: {'B-PER': 0, 'I-PER': 1, 'B-ORG': 2, 'I-ORG': 3, 'B-LOC': 4, 'I-LOC': 5, 'O': 6}
训练集样例: {'tokens': ['当', '希', '望', '工', '程', '救', '助', '的', '百', '万', '儿', '童', '成', '长', '起', '来', ',', '科', '教', '兴', '国', '蔚', '然', '成', '风', '时', ',', '今', '天', '有', '收', '藏', '价', '值', '的', '书', '你', '没', '买', ',', '明', '日', '就', '叫', '你', '悔', '不', '当', '初', '!'], 'labels': [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]}
测试集样例: {'tokens': ['中', '共', '中', '央', '致', '中', '国', '致', '公', '党', '十', '一', '大', '的', '贺', '词', '各', '位', '代', '表', '、', '各', '位', '同', '志', ':', '在', '中', '国', '致', '公', '党', '第', '十', '一', '次', '全', '国', '代', '表', '大', '会', '隆', '重', '召', '开', '之', '际', ',', '中', '国', '共', '产', '党', '中', '央', '委', '员', '会', '谨', '向', '大', '会', '表', '示', '热', '烈', '的', '祝', '贺', ',', '向', '致', '公', '党', '的', '同', '志', '们', '致', '以', '亲', '切', '的', '问', '候', '!'], 'labels': [2, 3, 3, 3, 6, 2, 3, 3, 3, 3, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 2, 3, 3, 3, 3, 3, 3, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 2, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]} 2.3.3 加载中文ERNIE 3.0预训练模型和分词器¶¶
PaddleNLP中Auto模块(包括AutoModel, AutoTokenizer及各种下游任务类)提供了方便易用的接口,无需指定模型类别,即可调用不同网络结构的预训练模型。PaddleNLP的预训练模型可以很容易地通过from_pretrained()方法加载,Transformer预训练模型汇总包含了40多个主流预训练模型,500多个模型权重。
AutoForTokenClassification可用于序列标注,通过预训练模型获取输入文本每个token的表示,之后将token表示进行分类。PaddleNLP已经实现了ERNIE 3.0预训练模型,可以通过一行代码实现ERNIE 3.0预训练模型和分词器的加载。
本项目开源 ERNIE 3.0 Base 、ERNIE 3.0 Medium 、 ERNIE 3.0 Mini 、 ERNIE 3.0 Micro 、 ERNIE 3.0 Nano 五个模型:
- ERNIE 3.0-Base (12-layer, 768-hidden, 12-heads)
- ERNIE 3.0-Medium (6-layer, 768-hidden, 12-heads)
- ERNIE 3.0-Mini (6-layer, 384-hidden, 12-heads)
- ERNIE 3.0-Micro (4-layer, 384-hidden, 12-heads)
- ERNIE 3.0-Nano (4-layer, 312-hidden, 12-heads)
from paddlenlp.transformers import AutoModelForTokenClassification
from paddlenlp.transformers import AutoTokenizer
model_name = "ernie-3.0-base-zh"
model = AutoModelForTokenClassification.from_pretrained(model_name, num_classes=len(train_ds.label_list))
tokenizer = AutoTokenizer.from_pretrained(model_name)2.3.4 基于预训练模型的数据处理¶¶
Dataset中通常为原始数据,需要经过一定的数据处理转成可输入模型的数据并进行采样组batch。
- 通过
Dataset的map函数,使用分词器将数据集从原始文本处理成模型的输入。 - 定义
paddle.io.BatchSampler和collate_fn构建paddle.io.DataLoader。
实际训练中,根据显存大小调整批大小batch_size和文本最大长度max_seq_length。
import functools
import numpy as np
from paddle.io import DataLoader, BatchSampler
from paddlenlp.data import DataCollatorForTokenClassification
# 数据预处理函数,利用分词器将文本转化为整数序列
def preprocess_function(example, tokenizer, label_vocab, max_seq_length=128):
labels = example['labels']
tokens = example['tokens']
no_entity_id = label_vocab['O']
tokenized_input = tokenizer(tokens, return_length=True, is_split_into_words=True, max_seq_len=max_seq_length)
# 保证label与input_ids长度一致
# -2 for [CLS] and [SEP]
if len(tokenized_input['input_ids']) - 2 < len(labels):
labels = labels[:len(tokenized_input['input_ids']) - 2]
tokenized_input['labels'] = [no_entity_id] + labels + [no_entity_id]
tokenized_input['labels'] += [no_entity_id] * (len(tokenized_input['input_ids']) - len(tokenized_input['labels']))
return tokenized_input
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, label_vocab=label_vocab, max_seq_length=128)
train_ds = train_ds.map(trans_func)
test_ds = test_ds.map(trans_func)
# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠
collate_fn = DataCollatorForTokenClassification(tokenizer=tokenizer, label_pad_token_id=-1)
# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader
train_batch_sampler = BatchSampler(train_ds, batch_size=32, shuffle=True)
test_batch_sampler = BatchSampler(test_ds, batch_size=32, shuffle=False)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
test_data_loader = DataLoader(dataset=test_ds, batch_sampler=test_batch_sampler, collate_fn=collate_fn)2.3.5 数据训练和评估
定义训练所需的优化器、损失函数、评价指标等,就可以开始进行预模型微调任务。
from paddlenlp.metrics import ChunkEvaluator
# Adam优化器、交叉熵损失函数、ChunkEvaluator评价指标
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss(ignore_index=-1)
metric = ChunkEvaluator(label_list=train_ds.label_list)10个epoch预计训练时间60分钟。
# 开始训练
import time
import paddle.nn.functional as F
from utils import evaluate
epochs = 10 # 训练轮次
ckpt_dir = "ernie_ckpt" #训练过程中保存模型参数的文件夹
best_f1_score = 0
best_step = 0
global_step = 0 #迭代次数
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels']
# 计算模型输出、损失函数值
logits = model(input_ids, token_type_ids)
loss = paddle.mean(criterion(logits, labels))
# 每迭代10次,打印损失函数值、计算速度
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, 10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 每迭代200次,评估当前训练的模型、保存当前最佳模型参数和分词器的词表等
if global_step % 200 == 0:
save_dir = ckpt_dir
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print('global_step', global_step, end=' ')
f1_score_eval = evaluate(model, metric, test_data_loader)
if f1_score_eval > best_f1_score:
best_f1_score = f1_score_eval
best_step = global_step
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)global step 13960, epoch: 10, batch: 1297, loss: 0.00087, speed: 5.29 step/s
global step 13970, epoch: 10, batch: 1307, loss: 0.01934, speed: 5.31 step/s
global step 13980, epoch: 10, batch: 1317, loss: 0.00257, speed: 5.27 step/s
global step 13990, epoch: 10, batch: 1327, loss: 0.00045, speed: 4.94 step/s
global step 14000, epoch: 10, batch: 1337, loss: 0.00306, speed: 5.04 step/s
global_step 14000 eval precision: 0.946141 - recall: 0.956587 - f1: 0.951335
global step 14010, epoch: 10, batch: 1347, loss: 0.00233, speed: 0.93 step/s
global step 14020, epoch: 10, batch: 1357, loss: 0.00579, speed: 5.05 step/s
global step 14030, epoch: 10, batch: 1367, loss: 0.00169, speed: 5.24 step/s
global step 14040, epoch: 10, batch: 1377, loss: 0.00024, speed: 4.86 step/s
global step 14050, epoch: 10, batch: 1387, loss: 0.00112, speed: 5.44 step/s
global step 14060, epoch: 10, batch: 1397, loss: 0.00163, speed: 5.10 step/s
global step 14070, epoch: 10, batch: 1407, loss: 0.00009, speed: 5.55 step/s
运行时长:3460.397秒结束时间:2022-06-01 16:52:00utils:文件需要下载:
链接:ERNIE3.0中文预训练模型进行MSRA序列标注-自然语言处理文档类资源-
2.3.6 序列标注结果预测与保存
加载微调好的模型参数进行情感分析预测,并保存预测结果
# 测试集结果评估
from utils import parse_decodes
# 加载最佳模型参数
model.set_dict(paddle.load('ernie_ckpt/model_state.pdparams'))
# 可以加载预先训练好的模型参数结果查看模型训练结果
# model.set_dict(paddle.load('ernie_ckpt_trained/model_state.pdparams'))
model.eval()
metric.reset()
pred_list = []
len_list = []
for step, batch in enumerate(test_data_loader, start=1):
input_ids, token_type_ids, labels, lens = batch['input_ids'], batch['token_type_ids'], batch['labels'], batch['seq_len']
logits = model(input_ids, token_type_ids)
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
pred_list.append(preds.numpy())
len_list.append(lens.numpy())
precision, recall, f1_score = metric.accumulate()
print("ERNIE 3.0 在msra_ner的test集表现 -precision: %f - recall: %f - f1: %f" %(precision, recall, f1_score))结果:
ERNIE 3.0 在msra_ner的test集表现 -precision: 0.948490 - recall: 0.957897 - f1: 0.953170我们根据模型预测结果对文本进行后处理,对文本序列进行标注,具体的标签含义如下:
- ‘O’: no special entity(其他不属于任何实体的字符,包括标点等)
- ‘PER’: person(人名)
- ‘ORG’: organization(组织机构)
- ‘LOC’: location(地点)
# 根据预测结果对文本进行后处理
test_ds = load_dataset('msra_ner', splits=('test'))
preds = parse_decodes(test_ds, pred_list, len_list, label_vocab)
# 查看预测结果
print("查看结果")
print("\n".join(preds[:2]))
# 保存预测结果
with open("results.txt", "w", encoding="utf-8") as f:
f.write("\n".join(preds))结果:
查看结果
('中共中央', 'ORG')('致', 'O')('中国致公党十一大', 'ORG')('的', 'O')('贺', 'O')('词', 'O')('各', 'O')('位', 'O')('代', 'O')('表', 'O')('、', 'O')('各', 'O')('位', 'O')('同', 'O')('志', 'O')(':', 'O')('在', 'O')('中国致公党第十一次全国代表大会', 'ORG')('隆', 'O')('重', 'O')('召', 'O')('开', 'O')('之', 'O')('际', 'O')(',', 'O')('中国共产党中央委员会', 'ORG')('谨', 'O')('向', 'O')('大', 'O')('会', 'O')('表', 'O')('示', 'O')('热', 'O')('烈', 'O')('的', 'O')('祝', 'O')('贺', 'O')(',', 'O')('向', 'O')('致公党', 'ORG')('的', 'O')('同', 'O')('志', 'O')('们', 'O')('致', 'O')('以', 'O')('亲', 'O')('切', 'O')('的', 'O')('问', 'O')('候', 'O')('!', 'O')
('在', 'O')('过', 'O')('去', 'O')('的', 'O')('五', 'O')('年', 'O')('中', 'O')(',', 'O')('致公党', 'ORG')('在', 'O')('邓小平', 'PER')('理', 'O')('论', 'O')('指', 'O')('引', 'O')('下', 'O')(',', 'O')('遵', 'O')('循', 'O')('社', 'O')('会', 'O')('主', 'O')('义', 'O')('初', 'O')('级', 'O')('阶', 'O')('段', 'O')('的', 'O')('基', 'O')('本', 'O')('路', 'O')('线', 'O')(',', 'O')('努', 'O')('力', 'O')('实', 'O')('践', 'O')('致公党十大', 'ORG')('提', 'O')('出', 'O')('的', 'O')('发', 'O')('挥', 'O')('参', 'O')('政', 'O')('党', 'O')('职', 'O')('能', 'O')('、', 'O')('加', 'O')('强', 'O')('自', 'O')('身', 'O')('建', 'O')('设', 'O')('的', 'O')('基', 'O')('本', 'O')('任', 'O')('务', 'O')('。', 'O')欢迎一键三联!