Transformer(三)搞懂Swin Transformer
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
论文链接:https://arxiv.org/abs/2103.14030
目录
一、论文信息
二、总体结构
三、window attention 和 shift window attention
四、实验
五、存在的问题
一、论文信息
之前transformer主要用于NLP领域,现在也应用到了CV领域。Swin transformer是微软2021年3月月25日公布的一篇利用transformer架构处理计算机视觉任务的论文,它可以作为计算机视觉的通用backbone。源码仅仅公布两天就在github上收获了2.2k个stars,在图像分割、目标检测各个领域已经霸榜,让很多人看到了transformer完全替代卷积的可能。而且它的设计思想吸取了resnet的精华,从局部到全局,将transformer设计成逐步扩大感受野的工具,它的成功背后绝不是偶然,而是厚厚的积累与沉淀。
将Transformer从语言调整到视觉的挑战来自两个领域之间的差异:
1.视觉实体的大小差异很大,NLP对象的大小是标准固定的。
2.图像中的像素与文本中的单词相比具有很高的分辨率,而CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。
为了解决这两个问题,这篇文章提出了a hierarchical Transformer ,其表示是用滑窗操作计算的。滑窗操作方案通过将注意力计算限制到不重叠的局部窗口,同时还允许跨窗口连接,带来了更高的效率。(滑窗操作包括不重叠的local window,和重叠的cross-window。)
这种分层体系结构可以灵活地在各种尺度上建模,并且在图像大小方面具有线性计算复杂性。Swin Transformer的这些品质使其能够兼容广泛的视觉任务。
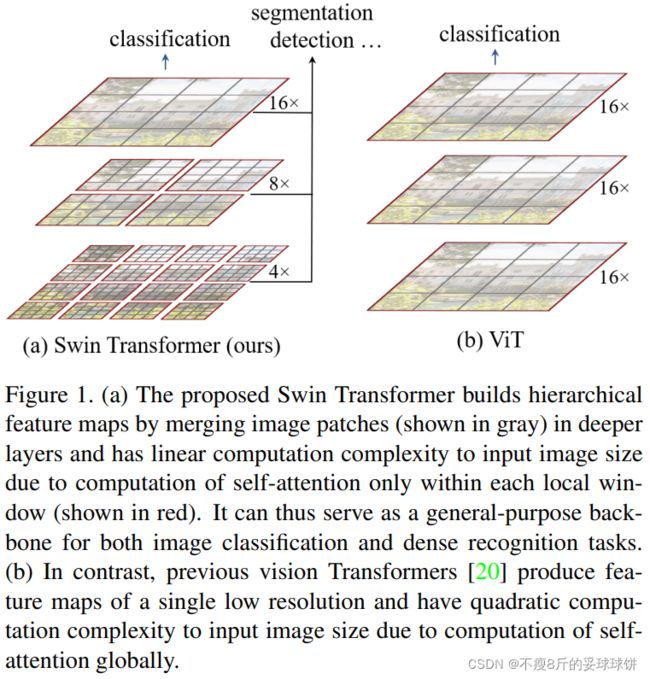
(a) 提出的Swin Transformer通过合并更深层的图像块(以灰色显示)来构建分层特征图,并且由于只在每个局部窗口(以红色显示)内计算注意力,因此对于输入图像大小具有线性计算复杂度。因此,它可以作为图像分类和密集识别任务的通用backbone。
(b) 相比之下,以前的Vison transformer产生单一低分辨率的特征图,并且由于计算全局的自我注意,对于输入图像大小具有二次计算复杂度。
二、总体结构
构建了4个stage,每个stage中都是类似的重复单元。
- 和ViT类似,通过patch partition将输入图片 HxWx3 划分为不重合的patch集合,其中每个patch尺寸为 4x4,那么每个patch的特征维度为 4x4x3=48 ,patch块的数量为H/4 x W/4。以swin-s为例,输入的224 × 224图像经过这一步操作就变成了56 × 56的特征图。
Swin Transformer和ViT划分patch的方式类似,Swin Transformer也是先确定每个patch的大小,然后计算确定patch数量。不同的是,随着网络深度加深ViT的patch数量不会变化,而Swin Transformer随着网络深度的加深数量会逐渐减少并且每个patch的感知范围会扩大,这个设计是为了方便Swin Transformer的层级构建,并且能够适应视觉任务的多尺度。
- stage1:一个patch的特征维度为4x4x3=48的特征图一开始输入到stage1的Embedding,经过一层线性层投影到C维度,这样就得到了H/4 × W/4 × C作为第一个Swin Transformer Block的输入。stage1由两层transformer block组成,这两层transformer block的核心一个是普通的window attention MSA, 另一个是shift window attention MSA。可以将window attention 和shift window attention视为两个模块,在每一个stage内部就是直接堆积这两个模块。在每个MSA模块和每个MLP之前使用LayerNorm(LN)层,并在每个MSA和MLP之后使用残差连接。
- stage2-stage4操作相同,先通过一个patch merging来降低要处理的数据的尺寸,也就是为了从一开始的局部信息搜索到全局信息的提取。将输入按照2 x 2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,再跟stage1一样使用linear embedding将4C压缩成2C(通过一个全连接层再调整通道维度为原来的两倍),也就是说每经过一个stage,总的数据量变为原来的1/2。然后送入Swin Transformer Block。
stage1:【H/4 x W/4,C】
stage2:【H/8 x W/8,2C】
stage2:【H/16 x W/16,4C】
stage2:【H/32 x W/32,8C】
此时可以很容易的看出,swin transformer和resnet一样设计的是一个层次结果很明显的网络,底部的结构处理的数据更多也更局部,顶部的网络处理的数据更少但是语义信息是更加丰富的。不同的是swin主要提取信息的方式是采用transformer,而ResNet是卷积核。

三、window attention 和 shift window attention
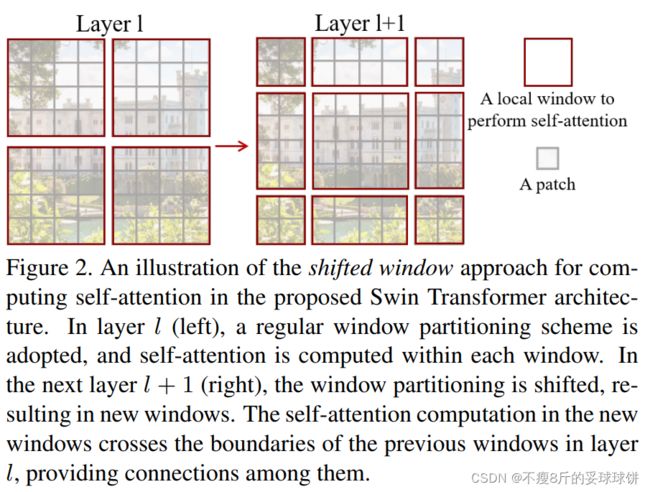
如图,window attention就是按照一定的尺寸将图像划分为不同的window,每次transformer的attention只在window内部进行计算。那么如果只有window attention就会带来每一个像素点的感受野得不到提升的问题,所以它又设计了一个shift window attention的方法,就是换一下window划分的方式,让每一个像素点做attention计算的window块处于变化之中。那么就起到了提升感受野的作用。
在所提出的Swin transformer体系结构中计算注意力的滑窗操作的示例。在l层(左)中,采用规则的窗口划分方案,在每个窗口内计算自注意。在下一层l + 1(右)中,窗口分区被移动,产生了新的窗口。新窗口中的自注意计算跨越了层l中以前窗口的边界,提供了它们之间的连接。
普通的MSA和W-MSA的计算量对比:
见【论文阅读】Swin transformer解读_向上的毛毛的博客-CSDN博客

W-MSA虽然降低了计算复杂度,但是不重合的window之间缺乏信息交流,于是作者进一步引入shifted window partition来解决不同window的信息交流问题,该方法在连续的Swin Transformer块中的两个Swin Transformer Block之间交替进行。
第一个模块W-MSA: 使用从左上角像素开始的常规窗口划分策略,将8 × 8特征图均匀划分为大小为4 × 4 (M = 4)的2 × 2窗口。
下一个模块SW-MSA: 采用与前一层不同的窗口配置,将下一层Swin Transformer Block的window位置进行移动,通过将窗口从规则划分的窗口中移位(M/2,M/2)个像素,然后得到3 x 3个不重合的patch。移动window的划分方式使上一层相邻的不重合window之间引入连接,大大的增加了感受野。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。

在实际代码里,通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
特征图移位操作见: 图解Swin Transformer - 知乎
Swin Transformer详解_蓝翔技校的码农的博客-CSDN博客_swin transformer详解
四、实验
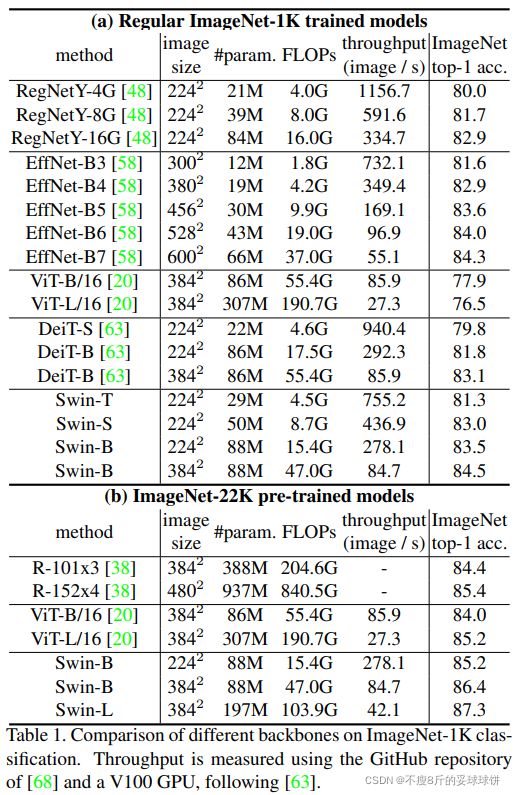
图像分类效果超过了ViT、DeiT等Transformer类型的网络,接近CNN类型的EfficientNet。
目标检测

语义分割

消融实验
表4,移位窗口操作和添加相对位置偏差的有效性。
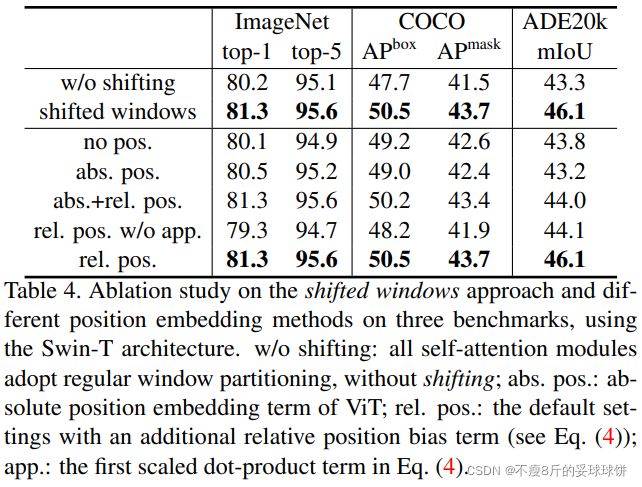
表5,移位窗口和cyclic带的高效性。

表6,使用不同的self-attention比较。

五、存在的问题
在同尺寸通计算量的前提下,swin确实效果远好于resnet。但是有几个问题:
1. 受缚于shift操作,对不同尺寸的输入要设计不同的网络,而且也要重新开始训练,这是很难接受的。
2. 和Detr一样训练的时候收敛的太慢。
参考链接:
https://blog.csdn.net/weixin_41317766/article/details/118677560
https://blog.csdn.net/qq_41111734/article/details/116353615
https://blog.csdn.net/qq_43349542/article/details/118585880