牛顿法总结
1. 牛顿法用于求方程解
牛顿法解方程是用切线来逐渐逼近方程的解如下图所示:
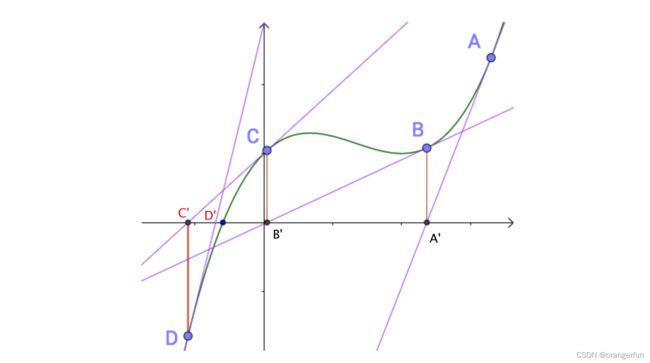
假如随机初始化的点为A点,做A点的切线与x轴相交于A’点,在A’点做垂线于函数曲线相交于B点,然后以B点做切线,如此循环下去,可以看到切线与x轴的交点逐渐向方程的解靠拢。
设随机初始化的点为 ( x n , f ( x n ) ) (x_n, f(x_n)) (xn,f(xn)),则切线方程为:
y − f ( x n ) = f ′ ( x n ) ( x − x n ) y-f(x_n) = f^{'}(x_n)(x-x_n) y−f(xn)=f′(xn)(x−xn)
切线与x轴的交点为(令y=0)
x n + 1 = x n − f ( x n ) f ′ ( x n ) x_{n+1}=x_n-\frac{f(x_n)}{f^{'}(x_n)} xn+1=xn−f′(xn)f(xn)
这就是迭代方程
参考:如何通俗易懂地讲解牛顿迭代法?
2. 牛顿法用于最优化
应用于最优化的牛顿法是以迭代的方式来求解一个函数的最优解, 取泰勒展开式的二次项,即用()来代替()
ϕ ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 \phi(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)+\frac{1}{2} f^{\prime \prime}\left(x_{0}\right)\left(x-x_{0}\right)^{2} ϕ(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2
最优点的选择是′()=0的点,对上式求导
ϕ ′ ( x ) = f ′ ( x 0 ) + f ′ ′ ( x 0 ) ( x − x 0 ) \phi^{\prime}(x)=f^{\prime}\left(x_{0}\right)+f^{\prime \prime}\left(x_{0}\right)\left(x-x_{0}\right) ϕ′(x)=f′(x0)+f′′(x0)(x−x0)
所以,最优化的牛顿迭代公式是:
x n + 1 = x n − f ′ ( x n ) f ′ ′ ( x n ) x_{n+1}=x_{n}-\frac{f^{\prime}\left(x_{n}\right)}{f^{\prime \prime}\left(x_{n}\right)} xn+1=xn−f′′(xn)f′(xn)
参考: 牛顿法和牛顿迭代法
3. 总结
牛顿法用于求方程解时迭代式为:
x n + 1 = x n − f ( x n ) f ′ ( x n ) x_{n+1}=x_{n}-\frac{f\left(x_{n}\right)}{f^{\prime}\left(x_{n}\right)} xn+1=xn−f′(xn)f(xn)
巧妙记忆方法 ϕ ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) \phi(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right) ϕ(x)=f(x0)+f′(x0)(x−x0) 令 ϕ ( x ) \phi(x) ϕ(x)=0即可推导出来
牛顿法用于最优化时迭代为:
x n + 1 = x n − f ′ ( x n ) f ′ ′ ( x n ) x_{n+1}=x_{n}-\frac{f^{\prime}\left(x_{n}\right)}{f^{\prime \prime}\left(x_{n}\right)} xn+1=xn−f′′(xn)f′(xn)
高维下的牛顿优化法:
X n + 1 = X n − f ′ ( X n ) f ′ ′ ( X n ) = X n − J f ( X n ) H ( X n ) = X n − H − 1 ( X n ) ⋅ J f ( X n ) \begin{aligned} X_{n+1} &=X_{n}-\frac{f^{\prime}\left(\mathrm{X}_{n}\right)}{f^{\prime \prime}\left(\mathrm{X}_{n}\right)}=X_{n}-\frac{J_{f}\left(\mathrm{X}_{n}\right)}{H\left(\mathrm{X}_{n}\right)} =X_{n}-H^{-1}\left(\mathrm{X}_{n}\right) \cdot J_{f}\left(\mathrm{X}_{n}\right) \end{aligned} Xn+1=Xn−f′′(Xn)f′(Xn)=Xn−H(Xn)Jf(Xn)=Xn−H−1(Xn)⋅Jf(Xn)
其中, J J J 定义为雅可比矩阵,对应一阶偏导数
J f ( X n ) = [ ∂ y 1 ∂ x 1 ⋯ ∂ y 1 ∂ x n ⋮ ⋱ ⋮ ∂ y m ∂ x 1 ⋯ ∂ y m ∂ x n ] J_{f}\left(X_{n}\right)=\left[\begin{array}{ccc} \frac{\partial y_{1}}{\partial x_{1}} & \cdots & \frac{\partial y_{1}}{\partial x_{n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_{m}}{\partial x_{1}} & \cdots & \frac{\partial y_{m}}{\partial x_{n}} \end{array}\right] Jf(Xn)=⎣⎢⎡∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎦⎥⎤
H H H 为 Hessian矩阵,对应二阶偏导数
H ( f ) = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] H(f)=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right] H(f)=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
牛顿法与梯度下降比较
梯度下降法和牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法是用二阶的海森矩阵的逆矩阵求解。相对而言,使用牛顿法收敛更快(迭代更少次数)。但是每次迭代的时间比梯度下降法长(计算开销大)。

如图,红色为牛顿法,绿色为梯度下降法
至于为什么牛顿法收敛更快,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部
参考文献
如何通俗易懂地讲解牛顿迭代法?
牛顿法和牛顿迭代法
梯度下降法、牛顿法和拟牛顿法
牛顿法与Hessian矩阵