数据挖掘实战(6):实战篇
博客内容是书籍: 《Python数据分析与挖掘实战》 的阅读笔记。
内容分为三个部分:
第一部分:第13章:财政收入影响因素分析及预测模型 的内容;
第二部分:第14章:基于基站定位数据的商圈分析 的内容;
第三部分:第15章:电商产品评论数据情感分析 的内容;
课件 PDF 和 源码 移步到Github : https://github.com/Stormzudi/Python-Data-Mining
邮箱:[email protected]
简单说下:博客的内容是按照原书的结构整理的,也算是读书笔记。
编译器:Pycharm
目录
-
- 第一部分:
-
- 整理思维导图
- 1. 背景与挖掘目标
- 2. 分析方法与过程
-
- 2.1 数据抽取
- 2.2 数据探索分析
- 2.3 模型构建
- 3. 小结
- 第二部分:
-
- 整理思维导图
- 1. 背景与挖掘目标
- 2. 分析方法与过程
-
- 2.1 数据抽取
- 2.2 数据探索分析
- 2.3 数据预处理
- 2.4 模型构建
- 3. 小结
- 第三部分:
-
- 整理思维导图
- 1. 背景与挖掘目标
- 2. 分析方法与过程
-
- 2.1 数据抽取
- 2.2 数据预处理
- 2.3 模型构建
- 3. 小结
第一部分:
整理思维导图
在学习过程中,按照自己理解的重点将本章分成四个部分:挖掘目标、模型、建模步骤。
其中,在学习这章中,有两个地方值得我们学习,如果遇到了类似的问题,可以运用本章中解题思路进行研究。
(1)描述性统计、相关系数分析
(2)Adaptive-Lasso选择模型、GM灰色预测、BP神经网络

1. 背景与挖掘目标
背景:
在我国现行的分税制财政管理体制下,地方财政收入不仅是国家财政收入的重要组成部分,还具有其相对独立的构成内容。如何有效地利用地方财政收人,合理地分配来促进地方的发展,提高市民的收人和生活质量是每个地方政府需要考虑的首要问题。因此,对地方财政收人进行预测,不但是必要的,而且是可能的。科学、合理地预测地方财政收入,对于克服年度地方预算收支规模的随意性和盲目性,正确处理地方财政与经济的相互关系具有十分重要的意义。
挖掘目标:
1. 梳理影响地方财政收入的关键特征,分析、识别影响地方财政收入的关键特征的选择模型。
2. 在结合目标 (1) 的因素分析,对某市2015年的财政总收入及各个类别收入进行预测。
2. 分析方法与过程
在文章的开头,介绍了时间序列的分析过程中常用的模型有:多元线性回归模型,再运用最小二乘估计方法来估计回归模型的系数,通过系数能否通过检验来检验它们之间的关系,可以发现这样的结果对数据的依赖程度很大,
于是,提出了用Lasso方法来解决过拟合的问题,在正规方程后面加上第一范数的惩罚项,通过最小二乘法来求解(也可以使用梯度下降法来求解)。
文章又提到了运用新的改进的方法:Adaptive-Lasso方法,不同的是给不同的系数加上了不同的权重。

接下来就是灰色预测模型GM(1,1)。
重点在于构造了一阶微分方程,和求解。
这个模型之前用MATLAB有些过,附上它的代码。
灰色系统GM(1,1) : https://wenku.baidu.com/view/ba8816adf71fb7360b4c2e3f5727a5e9856a27f6.html
clear all
clc
load AA
x0=AA';
x1=cumsum(x0); %求一次累加序列
n=length(x0);
z=0.5*(x1(2:n)+x1(1:(n-1))); %求x1的均值生成序列
B=[-z',ones(29,1)];
Y=x0(2:end)';
ab_hat=B\Y;
a=ab_hat(1,1);
b=ab_hat(2,1);
% x=dsolve('Dx+a*x=b*x^2','x(0)=x0');%求常微分;
x=dsolve('Dx+a*x=b','x(0)=x0');%求常微分
x=simplify(x);%对符号解进行简化;
x=subs(x,{'a','b','x0'},{ab_hat(1),ab_hat(2),x0(1)});%带入参数值
x=vpa(x,6);%显示六位数
yuce=subs(x,'t',[0:n]); % 预测0~30号
yuce=double(yuce); % 将数据转化成整数型类型
% 求解已知数据的预测值
x0_hat = [yuce(1),diff(yuce)]'
x0_hat=double(x0_hat);
% 得到第31号的预测值
yuce_31 = x0_hat(n+1)
x0_hat = x0_hat(1:n)
epsilon=AA-x0_hat; %求残差
delta=abs(epsilon./AA); %求相对误差
A=[x0',x0_hat,epsilon,delta]
运用Python,编写后封装成函数后,附上它的代码。
def GM11(x0): #自定义灰色预测函数
import numpy as np
x1 = x0.cumsum() #1-AGO序列
z1 = (x1[:len(x1)-1] + x1[1:])/2.0 # 紧邻均值(MEAN)生成序列
z1 = z1.reshape((len(z1),1))
B = np.append(-z1, np.ones_like(z1), axis = 1)
Yn = x0[1:].reshape((len(x0)-1, 1))
[[a],[b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) # 计算参数
f = lambda k: (x0[0]-b/a)*np.exp(-a*(k-1))-(x0[0]-b/a)*np.exp(-a*(k-2)) # 还原值
delta = np.abs(x0 - np.array([f(i) for i in range(1,len(x0)+1)]))
C = delta.std()/x0.std()
P = 1.0*(np.abs(delta - delta.mean()) < 0.6745*x0.std()).sum()/len(x0)
return f, a, b, x0[0], C, P # 返回灰色预测函数、a、b、首项、方差比、小残差概率
2.1 数据抽取
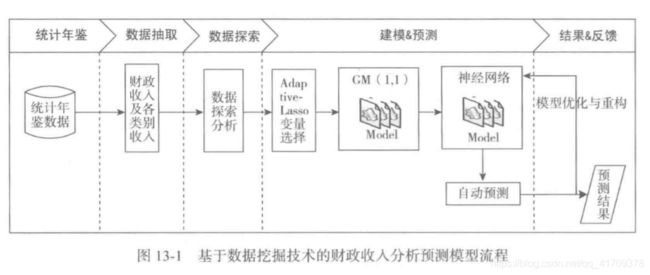
选取了时间序列为1994至2013年的数据。需要预测的是后两年的数据。在本次数据挖掘案例中,预测模型流程如下:
1)从某市统计局网站以及各统计年鉴搜集到该市财政收入以及各类别收入相关数据。
2)利用步骤1)形成的已完成数据预处理的建模数据,建立Adaptive-Lasso变量选择模型。
3)在步骤2)的基础上建立单变量的灰色预测模型以及人工神经网络预测模型。
4)利用步骤3)的预测值代人构建好的人工神经网络模型中,从而得到2014/2015年某市财政收入以及各类别收入的预测值。
2.2 数据探索分析
在数据探索分析阶段,对影响财政收入的13项指标 X i , i = 1...13 X_i,i=1...13 Xi,i=1...13 进行了分析,y表示财政收入。

这里注意的是在使用模型时,要进行标准化处理。
(1)描述分析
通过描述性统计分析,可以获得对数据的整体性认识。
可以使用专门的统计学软件进行描述性统计分析。
#-*- coding: utf-8 -*-
import numpy as np
import pandas as pd
inputfile = '../data/data1.csv' # 输入的数据文件
data = pd.read_csv(inputfile) # 读取数据
r = [data.min(), data.max(), data.mean(), data.std()] # 依次计算最小值、最大值、均值、标准差
r = pd.DataFrame(r, index = ['Min', 'Max', 'Mean', 'STD']).T # 计算相关系数矩阵
np.round(r, 2) # 保留两位小数
print(r)

(2)相关性分析
相关性分析也是统计学分析中的很重要的组成部分,相关系数矩阵可以看出哪些指标与待预测的财政收入是相关。同时,可以得到正相关和负相关。
对于相关性不显著的情况下可以剔除掉这个属性。
原始数据求解Pearson相关系数代码:
#-*- coding: utf-8 -*-
import numpy as np
import pandas as pd
inputfile = '../data/data1.csv' #输入的数据文件
data = pd.read_csv(inputfile) #读取数据
pearson = np.round(data.corr(method = 'pearson'), 2) #计算相关系数矩阵,保留两位小数
print(pearson)
2.3 模型构建
(1)Adaptive-Lasso变量选择模型
运用这个变量选择模型可以获得各个变量的系数,可以通过系数是否为0来判断是否将这个变量剔除掉。
变量选择模型的代码:
# -*- coding: utf-8 -*-
import pandas as pd
inputfile = '../data/data1.csv' # 输入的数据文件
data = pd.read_csv(inputfile) # 读取数据
# 导入LassoCV算法。
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(data.iloc[:, 0:13], data['y'])
result = model.coef_ # 各个特征的系数
print(result)
这里说明下,目前Adaptive-Lasso方法已经被弃用了,于是改用LassoCV算法,但是效果是一样的。
最后的到进行建模的属性有: X 1 X_1 X1、 X 2 X_2 X2、 X 3 X_3 X3、 X 4 X_4 X4、 X 5 X_5 X5、 X 7 X_7 X7六个属性。
(2)财政收入预测模型
在这部分的内容中,第一步是需要通过建立灰色预测模型来获得,六个属性在2014年的预测值,并评价这个预测值的精确度。
建立灰色预测模型,代码如下:
#-*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from GM11 import GM11 #引入自己编写的灰色预测函数
inputfile = '../data/data1.csv' #输入的数据文件
outputfile = '../tmp/data1_GM11.xls' #灰色预测后保存的路径
data = pd.read_csv(inputfile) #读取数据
data.index = range(1994, 2014)
data.loc[2014] = None
data.loc[2015] = None
l = ['x1', 'x2', 'x3', 'x4', 'x5', 'x7']
for i in l:
f, a, b, x0, C, P = GM11(data[i][0:20].values)
data[i][2014] = f(len(data)-1) # 2014年预测结果
data[i][2015] = f(len(data)) # 2015年预测结果
data[i] = data[i].round(2) # 保留两位小数
# data[l+['y']].to_excel(outputfile) #结果输出

得到了各个属性在2014年的预测值后,接下来就是建立神经网络模型来得到财政收入y的预测值。
建立神经网络模型,代码如下:
#-*- coding: utf-8 -*-
import pandas as pd
inputfile = '../tmp/data1_GM11.xls' #灰色预测后保存的路径
outputfile = '../data/revenue.xls' #神经网络预测后保存的结果
modelfile = '../tmp/1-net.model' #模型保存路径
data = pd.read_excel(inputfile) #读取数据
feature = ['x1', 'x2', 'x3', 'x4', 'x5', 'x7'] #特征所在列
data_train = data[0:20].copy() #取2014年前的数据建模
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean)/data_std #数据标准化
x_train = data_train[feature].values #特征数据
y_train = data_train['y'].values #标签数据
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
model = Sequential() #建立模型
model.add(Dense(output_dim=12, input_dim=6)) # 添加输入层6、隐藏层12的连接
model.add(Activation('relu')) #用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(output_dim=1, input_dim=12)) # 添加隐藏层12、输出层1的连接
model.compile(loss='mean_squared_error', optimizer='adam') #编译模型
model.fit(x_train, y_train, nb_epoch = 10000, batch_size = 16) #训练模型,学习一万次
model.save_weights(modelfile) #保存模型参数
#预测,并还原结果。
x = ((data[feature] - data_mean[feature])/data_std[feature]).values
data[u'y_pred'] = model.predict(x) * data_std['y'] + data_mean['y']
data.to_excel(outputfile)
import matplotlib.pyplot as plt #画出预测结果图
p = data[['y','y_pred']].plot(subplots = True, style=['b-o','r-*'])
plt.show()
通过代码可以得到图片:

同时通过训练得到预测的财政收入,见表格如下。

3. 小结
本章结合某市地方财政收入以及各类别收入分析和预测的案例,重点介绍了数据挖掘算法中Adaptive-Lasso方法和神经网络算法在实际案例中的应用。重点研究影响某市地方财政收入的关键因素,并在这些关键影响因素的基础上采用神经网络算法对2014、2015年的财政收入进行预测。
第二部分:
整理思维导图
在学习过程中,按照自己理解的重点将本章分成四个部分:挖掘目标、模型、建模步骤。
其中,在学习这章中,有两个地方值得我们学习,如果遇到了类似的问题,可以运用本章中解题思路进行研究。
(1)属性规约
(2)层次聚类算法

1. 背景与挖掘目标
背景:
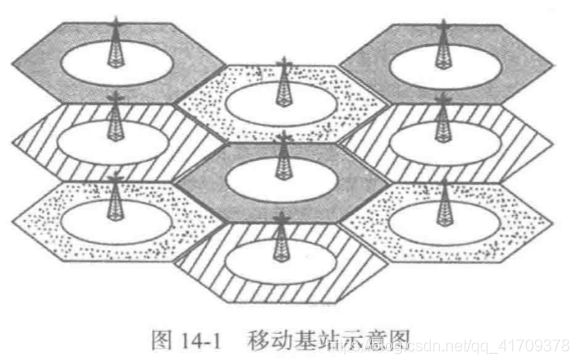
随着个人手机终端的普及,出行群体中手机拥有率和使用率已达到相当高的比例,手机移动网络也基本实现了城乡空间区域的全覆盖。根据手机信号在真实地理空间上的覆盖情况,将手机用户时间序列的手机定位数据,映射至现实的地理空间位置,即可完整、客观地还原出手机用户的现实活动轨迹,从而挖掘得到人口空间分布与活动联系的特征信息。移动通信网络的信号覆盖逻辑上被设计成由若干六边形的基站小区相互邻接而构成的蜂窝网络面状服务区,如图14-1所示,手机终端总是与其中某一个基站小区保持联系,移动通信网络的控制中心会定期或不定期地主动或被动地记录每个手机终端时间序列的基站小区编号信息。
商圈是现代市场中企业市场活动的空间,最初是站在商品和服务提供者的产地角度提出来的,后来逐渐扩展到商圈,同时也是商品和服务享用者的区域。商圈划分的目的之一是为了研究潜在的顾客的分布以制定适宜的商业对策。
挖掘目标:
1. 对用户的历史定位数据,采用数据挖掘技术,对基站进行分群。
2. 对不同的商圈分群进行特征分析,比较不同商圈类别的价值,选择合适的区域进行运营商的促销活动。
2. 分析方法与过程
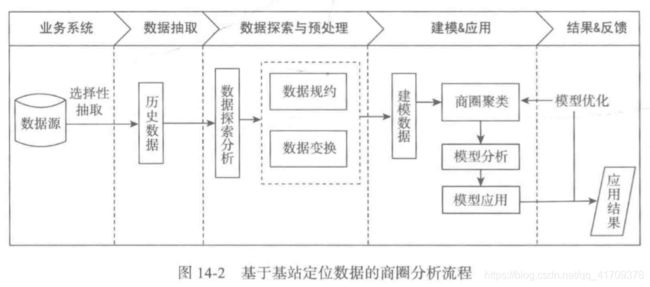
基于移动基站定位数据的商圈分析的主要步骤:
1)从移动通信运营商提供的特定接口上解析、处理、并滤除用户属性后得到用户定位数据。
2)以单个用户为例,进行数据探索分析,研究在不同基站的停留时间,并进一步地进行预处理,包括数据规约和数据变换。
3)利用步骤2)形成的已完成数据预处理的建模数据,基于基站覆盖范围区域的人流特征进行商圈聚类,对各个商圈分群进行特征分析,选择合适的区域进行运营商的促销活动。
2.1 数据抽取
从移动通信运营商提供的特定接口上解析、处理、并滤除用户属性后得到位置数据以2014-1-1为开始时间,2014-6-30为结束时间作为分析的观测窗口,抽取观测窗口内某市某区域的定位数据形成建模数据,部分数据见表14-1。

2.2 数据探索分析
在数据抽取后,可以去分析单个用户“55555”在2014年1月1日一天内的运用范围,该用户在某个时间点所处的位置可以通过基站编号来定位。
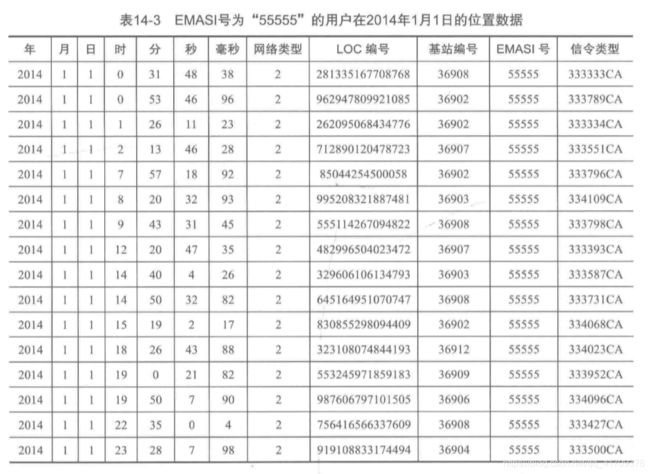
可以发现在00:31:48 ~ 00:53:46时间段上,用户在36908基站位置上。在00:53:46 ~ 02:13:46时间段上,用户在36902基站位置范围内。等等,可以出一天的时间坐标轴如下。

2.3 数据预处理
(1)数据规约
原始数据的属性较多,但网络类型、LOC编号和信令类型这3个属性对于挖掘目标没有用处,故剔除这3个冗余的属性。而衡量用户的停留时间,并不需要精确到毫秒级,故可把毫秒这一属性删除。
在计算用户的停留时间时,只计算两条记录的时间差,为了减少数据维度,把年、月和日合并记为日期,时、分和秒合并记为时间,得到表14-4。

(2)数据变换
挖掘的目标是寻找出高价值的商圈,需要根据用户的定位数据提取出衡量基站覆盖范围区域的人流特征,如人均停留时间和人流量等,高价值的商圈具有人流量大,人均停留时间长的特点,但是在写字楼工作的上班族在白天所处的基站范围基本固定,停留时间也相对较长,晚上的住宅区的居民所处的基站范围基本固定,停留时间也相对较长,仅通过停留时间作为人流特征难以区分高价值商圈和写字楼与住宅区,所以提取出来的人流特征必须能较为明显地区别这些基站范围。
下面设计工作日上班时间人均停留时间、凌晨人均停留时间、周末人均停留时间、日均人流量作为基站覆盖范围区域的人流特征。
工作日上班时间人均停留时间是所有用户在工作日上班时间处在该基站范围内的平均时间,居民一般的上班工作时间是在9:00~18:00,所以工作日上班时间人均停留时间是计算所有用户在工作日9:00~18:00处在该基站范围内的平均时间。
凌晨人均停留时间是指所有用户在00:00~07:00处在该基站范围内的平均时间,一般居民在00:00~07:00都是在住处休息,利用这个指标则可以表征出住宅区基站的人流特征。
周末人均停留时间是指所有用户周末处在该基站范围内的平均时间,高价值商圈在周末的逛街人数和时间都会大幅增加,利用这个指标则可以表征出高价值商圈的人流特征。
日均人流量指平均每天曾经在该基站范围内的人数,日均人流量大说明经过该基站区域的人数多,利用这个指标则可以表征出高价值商圈的人流特征.

在之前分析的是用户“5555”的一天的活动情况,这里需要统计N个基站下,M个用户,在观察窗口期间(L天)之内的各个指标的数据。

由于各个属性之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行离差标准化处理,离差标准化处理的Python代码如下代码。
#-*- coding: utf-8 -*-
#数据标准化到[0,1]
import pandas as pd
#参数初始化
filename = '../data/business_circle.xls' #原始数据文件
standardizedfile = '../tmp/standardized.xls' #标准化后数据保存路径
data = pd.read_excel(filename, index_col = u'基站编号') #读取数据
data = (data - data.min())/(data.max() - data.min()) #离差标准化
data = data.reset_index()
data.to_excel(standardizedfile, index = False) #保存结果
标准化后的数据见下表。

2.4 模型构建
(1)构建商圈聚类模型
数据经过预处理过后,形成建模数据。采用层次聚类算法对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图。
代码如下:
#-*- coding: utf-8 -*-
#谱系聚类图
import pandas as pd
#参数初始化
standardizedfile = '../data/standardized.xls' #标准化后的数据文件
data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import linkage,dendrogram
#这里使用scipy的层次聚类函数
Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图
P = dendrogram(Z, 0) #画谱系聚类图
plt.show()
可以得到的谱系聚类图

从上图可以看出,可把聚类类别数取3类,Python代码中取聚类类别数为k=3,输出结果typeindex为每个样本对应的类别号。
层次聚类算法如下:
#-*- coding: utf-8 -*-
#层次聚类算法
import pandas as pd
#参数初始化
standardizedfile = '../data/standardized.xls' #标准化后的数据文件
k = 3 #聚类数
data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据
from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数
model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')
model.fit(data) #训练模型
#详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
style = ['ro-', 'go-', 'bo-']
xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']
pic_output = '../tmp/type_' #聚类图文件名前缀
for i in range(k): #逐一作图,作出不同样式
plt.figure()
tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类
for j in range(len(tmp)):
plt.plot(range(1, 5), tmp.iloc[j], style[i])
plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签
plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始
plt.subplots_adjust(bottom=0.15) #调整底部
plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片
plt.show()
(2)模型分析
针对聚类结果按不同类别画出4个特征的折线图,如图所示。

对于商圈类别1,日均人流量较大,同时工作日上班时间人均停留时间、凌晨人均停留时间和周末人均停留时间相对较短,该类别基站覆盖的区域类似于商业区。

对于商圈类别2,凌晨人均停留时间和周末人均停留时间相对较长,而工作日上班时间人均停留时间较短,日均人流量较少,该类别基站覆盖的区域类似于住宅区。

对于商圈类别3,这部分基站覆盖范围的工作日上班时间人均停留时间较长,同时凌晨人均停留时间、周末人均停留时间相对较短,该类别基站覆盖的区域类似于白领上班族的工作区域。
总的来讲,商圈类别2的人流量较少,商圈类别3的人流量一般,而且白领上班族的工作区域一般的人员流动集中在上、下班时间和午间吃饭时间,这两类商圈均不利于运营商的促销活动的开展,商圈类别1的人流量大,在这样的商业区有利于进行运营商的促销活动。
3. 小结
本章结合基于基站定位数据的商圈分析的案例,重点介绍了数据挖掘算法中层次聚类算法在实际案例中的应用。研究用户的定位数据,总结出人流特征,并采用层次聚类算法进行商圈聚类,识别出不同类别的商圈,最后选择合适的区域进行运营商的促销活动。
第三部分:
整理思维导图
在学习过程中,按照自己理解的重点将本章分成四个部分:挖掘目标、模型、建模步骤。
其中,在学习这章中,有两个地方值得我们学习,如果遇到了类似的问题,可以运用本章中解题思路进行研究。
(1)LDA模型
(2)运用jieba分词、机械压缩去词

1. 背景与挖掘目标
背景:
随着网上购物越来越流行,人们对于网上购物的需求变得越来越高,这让京东、淘宝等电商平台得到了很大的发展机遇。但是,这种需求也推动了更多的店商平台的崛起,引发了激烈的竞争。在这种电商平台激烈竞争的大背景下,除了提高商品质量、压低商品价格外,了解更多消费者的心声对于店商平台来说也变得越来越有必要,其中非常重要的方式就是对消费者的文本评论数据进行内在信息的数据挖掘分析。而得到的这些信息,也有利于对应商品的生产厂家自身竞争力的提升。
挖掘目标:
1. 分析某一品牌热水器的用户情感倾向。
2. 从评论文本中挖掘出该品牌热水器的优点与不足。
3. 提炼不同品牌热水器的卖点。
2. 分析方法与过程
本次建模针对京东商城上“美的”品牌的热水器的消费者的文本评论数据,在对文本进行基本的机器预处理、中文分词、停用词过滤后,通过建立包括栈式自编码深度学习、语义网络与LDA主题模型等多种数据挖掘模型,实现对文本评论数据的倾向性判断以及所隐藏的信息的挖掘并分析,以期望得到有价值的内在内容。
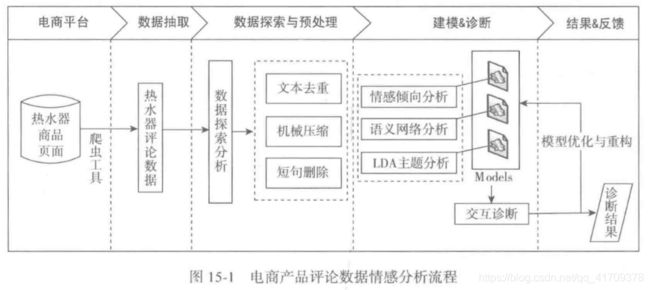
电商产品评论数据情感分析流程,主要的步骤如下:
1)利用爬虫工具——八爪鱼采集器,对京东商城进行热水器评论的数据采集。
2)对获取的数据进行基本的处理操作,包括数据预处理、中文分词、停用词过滤等操作。
3)文本评论数据经过处理后,运用多种手段对评论数据进行多方面的分析。
4)从对应结果的分析中获取文本评论数据中有价值的内容。
2.1 数据抽取
在数据抽取阶段,需要运用网页爬取的工具,选择八爪鱼采集器,抓取京东网页的数据。
最主要的是:每页评论信息。
评论汇总文件如下:

接下来就是截取评论数据,抽取代码如下:
#-*- coding: utf-8 -*-
import pandas as pd
inputfile = '../data/huizong.csv' #评论汇总文件
outputfile = '../data/meidi_jd.txt' #评论提取后保存路径
data = pd.read_csv(inputfile, encoding = 'utf-8')
data = data[[u'评论']][data[u'品牌'] == u'美的']
data.to_csv(outputfile, index = False, header = False, encoding = 'utf-8')
最后,对采集到的评论数据进行处理,得到原始文本的评论数据。

如果在运行上面的程序会报错:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd2 in position 0: invalid continuation byte

修改一处导入数据的代码为:
data = pd.read_csv(inputfile, encoding='gb18030')
2.2 数据预处理
(1)评论预处理
低甚至没有价值含量的条目,如果将这些评论数据也引入进行分词、词频统计乃至情感分析等,必然会对分析造成很大的影响,得到的结果的质量也必然是存在问题的。那么,在利用到这些文本评论数据之前就必须先进行文本预处理,把大量的此类无价值含量的评论去除。
文本评论数据的预处理主要由3个部分组成:文本去重、机械压缩去词、短句删除。
文本去重
#-*- coding: utf-8 -*-
import pandas as pd
inputfile = '../data/meidi_jd.txt' #评论文件
outputfile = '../data/meidi_jd_process_1.txt' #评论处理后保存路径
data = pd.read_csv(inputfile, encoding = 'utf-8', header = None)
l1 = len(data)
data = pd.DataFrame(data[0].unique())
l2 = len(data)
data.to_csv(outputfile, index = False, header = False, encoding = 'utf-8')
print(u'删除了%s条评论。' %(l1 - l2))

机械压缩去词
例如:
(1)可以,可以可以可以可以
可以
(2)好费电好费电好费电好费电
好费电
短句删除
在机械压缩去词后,会出现很多短句,例如:可以,很不错。
这样的短句在实际操作中要删除掉,一般通过机械压缩去词后得到的语料若小于等于4个国际字符,则将该语料删除。
(2)文本评论分词
这里不得不介绍一下 jieba 这个分词包,个人体验很不错,它提供分析,词性标注,支持用户词典等功能。
它可以将一段很长的话进行关键字分词,最大化获取语料所表达的关键信息。
2.3 模型构建
(1)情感倾向性模型
首次需要训练得到词向量,为了将文本情感分析转化成机器学习问题,首先要将其符号化,其中最常见的是one-hot编码,在神经网络模型中,有时语义文本使用one-hot编码时,向量维度会很大,这样操作起来运行速度会非常慢,这里就需要读者去优化分析辽。
在之前写过用户画像有运用过word2vec这个模块。
用户画像: https://blog.csdn.net/qq_41709378/article/details/107942339.
(2)基于语义网络的评论分析
这部分可以下载软件ROSTCM6进行具体分析,可以按照课本上的步骤进行一步一步分析。
在这部分主要目的是对某型号的好、差评文本数据生成的语义网络图,结合共词矩阵以及评论定向筛选回查来完成对评论的分析。
(3)基于LDA模型的主题分析
1. 删除前缀评分代码
#-*- coding: utf-8 -*-
import pandas as pd
#参数初始化
inputfile1 = '../data/meidi_jd_process_end_负面情感结果.txt'
inputfile2 = '../data/meidi_jd_process_end_正面情感结果.txt'
outputfile1 = '../data/meidi_jd_neg.txt'
outputfile2 = '../data/meidi_jd_pos.txt'
data1 = pd.read_csv(inputfile1, encoding = 'utf-8', header = None) #读入数据
data2 = pd.read_csv(inputfile2, encoding = 'utf-8', header = None)
data1 = pd.DataFrame(data1[0].str.replace('.*?\d+?\\t ', '')) #用正则表达式修改数据
data2 = pd.DataFrame(data2[0].str.replace('.*?\d+?\\t ', ''))
data1.to_csv(outputfile1, index = False, header = False, encoding = 'utf-8') #保存结果
data2.to_csv(outputfile2, index = False, header = False, encoding = 'utf-8')
2. 分词代码
#-*- coding: utf-8 -*-
import pandas as pd
import jieba #导入结巴分词,需要自行下载安装
#参数初始化
inputfile1 = '../data/meidi_jd_neg.txt'
inputfile2 = '../data/meidi_jd_pos.txt'
outputfile1 = '../data/meidi_jd_neg_cut.txt'
outputfile2 = '../data/meidi_jd_pos_cut.txt'
data1 = pd.read_csv(inputfile1, encoding = 'utf-8', header = None) #读入数据
data2 = pd.read_csv(inputfile2, encoding = 'utf-8', header = None)
mycut = lambda s: ' '.join(jieba.cut(s)) #自定义简单分词函数
data1 = data1[0].apply(mycut) #通过“广播”形式分词,加快速度。
data2 = data2[0].apply(mycut)
data1.to_csv(outputfile1, index = False, header = False, encoding = 'utf-8') #保存结果
data2.to_csv(outputfile2, index = False, header = False, encoding = 'utf-8')

接下来,在分好词的正面评价、负面评价文件以及过滤用的停用词表的基础上,使用Python的Gensim库完成LDA分析的代码。
#-*- coding: utf-8 -*-
import pandas as pd
#参数初始化
negfile = '../data/meidi_jd_neg_cut.txt'
posfile = '../data/meidi_jd_pos_cut.txt'
stoplist = '../data/stoplist.txt'
neg = pd.read_csv(negfile, encoding = 'utf-8', header = None) #读入数据
pos = pd.read_csv(posfile, encoding = 'utf-8', header = None)
stop = pd.read_csv(stoplist, encoding = 'utf-8', header = None, sep = 'tipdm')
#sep设置分割词,由于csv默认以半角逗号为分割词,而该词恰好在停用词表中,因此会导致读取出错
#所以解决办法是手动设置一个不存在的分割词,如tipdm。
stop = [' ', ''] + list(stop[0]) #Pandas自动过滤了空格符,这里手动添加
neg[1] = neg[0].apply(lambda s: s.split(' ')) #定义一个分割函数,然后用apply广播
neg[2] = neg[1].apply(lambda x: [i for i in x if i not in stop]) #逐词判断是否停用词,思路同上
pos[1] = pos[0].apply(lambda s: s.split(' '))
pos[2] = pos[1].apply(lambda x: [i for i in x if i not in stop])
from gensim import corpora, models
#负面主题分析
neg_dict = corpora.Dictionary(neg[2]) #建立词典
neg_corpus = [neg_dict.doc2bow(i) for i in neg[2]] #建立语料库
neg_lda = models.LdaModel(neg_corpus, num_topics = 3, id2word = neg_dict) #LDA模型训练
print("负面主题分析")
for i in range(3):
print(neg_lda.print_topic(i)) # 输出每个主题
#正面主题分析
pos_dict = corpora.Dictionary(pos[2])
pos_corpus = [pos_dict.doc2bow(i) for i in pos[2]]
pos_lda = models.LdaModel(pos_corpus, num_topics = 3, id2word = pos_dict)
print("正面主题分析")
for i in range(3):
print(neg_lda.print_topic(i)) # 输出每个主题
3. 小结
本章结合京东商城美的热水器评论的文本分析的案例,重点介绍了数据挖掘算法中文本挖掘分词算法以及LDA主题模型在实际案例中的应用。本章研究京东平台上的热水器评论问题,从分析某一热水器的用户情感倾向出发挖掘出该热水器的优点与不足,从而提升对应商品的生产厂家自身的竞争力。