【PyTorch】4 姓氏分类RNN实战(Simple RNN)——18 种起源语言的数千种姓氏分类
使用char-RNN对姓氏进行分类
- 1. 准备数据
- 2. 将名称转换为张量
- 3. 建立网络
- 4. 准备训练
- 5. 训练网络
- 6. 评估结果
- 7. 全部代码
- 小结
这是官方NLP From Scratch的一个教程(1/3),原英文链接,中文链接,本文是其详细的注解
1. 准备数据
大多数都是罗马化的(但我们仍然需要从 Unicode 转换为 ASCII)
关于unicodedata库用法:
unicodedata.normalize对于每个字符,规范形式D(NFD)也称为规范分解,将每个字符转换为其分解形式。范式C(NFC)首先应用规范分解,然后再次组成预组合字符
unicodedata.category以字符串形式返回分配给字符chr的常规类别,参考此文,也可在官网Abbr. Description上找到,具体如下:
Code Description
[Cc] Other, Control
[Cf] Other, Format
[Cn] Other, Not Assigned (no characters in the file have this property)
[Co] Other, Private Use
[Cs] Other, Surrogate
[LC] Letter, Cased
[Ll] Letter, Lowercase
[Lm] Letter, Modifier
[Lo] Letter, Other
[Lt] Letter, Titlecase
[Lu] Letter, Uppercase
[Mc] Mark, Spacing Combining
[Me] Mark, Enclosing
[Mn] Mark, Nonspacing
[Nd] Number, Decimal Digit
[Nl] Number, Letter
[No] Number, Other
[Pc] Punctuation, Connector
[Pd] Punctuation, Dash
[Pe] Punctuation, Close
[Pf] Punctuation, Final quote (may behave like Ps or Pe depending on usage)
[Pi] Punctuation, Initial quote (may behave like Ps or Pe depending on usage)
[Po] Punctuation, Other
[Ps] Punctuation, Open
[Sc] Symbol, Currency
[Sk] Symbol, Modifier
[Sm] Symbol, Math
[So] Symbol, Other
[Zl] Separator, Line
[Zp] Separator, Paragraph
[Zs] Separator, Space
unicodeToAscii函数调用结果
print(unicodeToAscii('Ślusàrski'))
结果:
Slusarski
glob模块可见此文
glob.glob()函数
path = '...your path\\data\\'
print(findFiles(path + 'names\\*.txt'))
['...your path\\data\\names\\Arabic.txt', '...your path\\data\\names\\Chinese.txt', '...your path\\data\\names\\Czech.txt', '...your path\\data\\names\\Dutch.txt', '...your pathCode\\data\\names\\English.txt', '...your path\\data\\names\\French.txt', '...your path\\data\\names\\German.txt', '...your path\\data\\names\\Greek.txt', '...your path\\data\\names\\Irish.txt', '...your path\\data\\names\\Italian.txt', '...your path\\data\\names\\Japanese.txt', '...your path\\data\\names\\Korean.txt', '...your path\\data\\names\\Polish.txt', '...your path\\data\\names\\Portuguese.txt', '...your path\\data\\names\\Russian.txt', '...your path\\data\\names\\Scottish.txt', '...your path\\data\\names\\Spanish.txt', '...your path\\names\\Vietnamese.txt']
os.path.basename(filename)
Arabic.txt
Chinese.txt
...
os.path.splitext(os.path.basename(filename))
('Arabic', '.txt')
('Chinese', '.txt')
...
category_lines就是如下形式的字典:
{'Arabic': ['Khoury', 'Nahas',...
print(category_lines['Chinese'][:5])
['Ang', 'AuYong', 'Bai', 'Ban', 'Bao']
2. 将名称转换为张量
为了表示单个字母,我们使用大小为<1 x n_letters(57)>的“ one-hot vector”,例如 “b” = <0 1 0 0 0 …>,则每个单词可以表示为:
print(lineToTensor('bee'))
print(lineToTensor('bee').size())
tensor([[[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]]])
torch.Size([3, 1, 57])
3. 建立网络
此RNN模块从这里来的,这是一个最简单的simple RNN!见之前博客李宏毅机器学习课程RNN笔记的
- RNN基本概念
关于torch.cat函数可见此:
# x1
x1 = torch.tensor([[11,21,31],[21,31,41]],dtype=torch.int)
x1.shape # torch.Size([2, 3])
# x2
x2 = torch.tensor([[12,22,32],[22,32,42]],dtype=torch.int)
x2.shape # torch.Size([2, 3])
'inputs为2个形状为[2 , 3]的矩阵 '
inputs = [x1, x2]
print(inputs)
'打印查看'
[tensor([[11, 21, 31],
[21, 31, 41]], dtype=torch.int32),
tensor([[12, 22, 32],
[22, 32, 42]], dtype=torch.int32)]
In [1]: torch.cat(inputs, dim=0).shape
Out[1]: torch.Size([4, 3])
In [2]: torch.cat(inputs, dim=1).shape
Out[2]: torch.Size([2, 6])
In [3]: torch.cat(inputs, dim=2).shape
IndexError: Dimension out of range (expected to be in range of [-2, 1], but got 2)
关于nn.LogSoftmax(dim=1)的dim参数解释见此和例子:
- dim=0:对每一列的所有元素进行softmax运算,并使得每一列所有元素和为1
- dim=1:对每一行的所有元素进行softmax运算,并使得每一行所有元素和为1
要运行此网络的步骤,我们需要传递输入(在本例中为当前字母的张量)和先前的隐藏状态(首先将其初始化为零)。 我们将返回输出(每种语言的概率)和下一个隐藏状态(我们将其保留用于下一步)
input = letterToTensor('A')
hidden =torch.zeros(1, n_hidden)
output, next_hidden = rnn(input, hidden)
为了提高效率,我们不想为每个步骤创建一个新的 Tensor,因此我们将使用lineToTensor而不是letterToTensor并使用切片。 这可以通过预先计算一批张量来进一步优化
input = lineToTensor('Albert')
hidden = torch.zeros(1, n_hidden)
output, next_hidden = rnn(input[0], hidden)
print(output)
tensor([[-2.9504, -2.8402, -2.9195, -2.9136, -2.9799, -2.8207, -2.8258, -2.8399,
-2.9098, -2.8815, -2.8313, -2.8628, -3.0440, -2.8689, -2.9391, -2.8381,
-2.9202, -2.8717]], grad_fn=<LogSoftmaxBackward>)
4. 准备训练
关于topk()可见上一篇blog,这里使用的是item():
category_i = output.data.topk(1)[1].item()
output结果如下:
tensor([[-2.8896, -2.8108, -3.0282, -2.8397, -2.8814, -2.8907, -2.8278, -2.8074,
-2.8632, -2.8780, -2.9615, -2.9549, -2.8890, -2.9229, -2.9158, -2.9552,
-2.8847, -2.8536]], grad_fn=<LogSoftmaxBackward>)
获得最大值的索引:
print(categoryFromOutput(output))
('Greek', 7)
random.randint(a, b)函数返回的是[a,b]之间的随机整数(不同于np.random.randint(a,b),返回的是[a,b))
关于torch.tensor和torch.Tensor区别可见此,个人感觉区别不大
for i in range(3):
category, line, category_tensor, line_tensor = randomTrainingExample()
print(category, line, category_tensor.size(), line_tensor.size())
Greek Papadelias torch.Size([7]) torch.Size([10, 1, 57])
Russian Hatuntsev torch.Size([14]) torch.Size([9, 1, 57])
Dutch Meeuwes torch.Size([3]) torch.Size([7, 1, 57])
5. 训练网络
x = torch.Tensor([[1,2],
[3,4]])
y = torch.ones(2,2)
x.add_(-10, y.data)
print(x)
tensor([[-9., -8.],
[-7., -6.]])
UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, *, Number alpha) (Triggered internally at ..\torch\csrc\utils\python_arg_parser.cpp:766.)
x.add_(-10, y.data)
math.floor返回数字的下舍整数,小于或等于 x
训练曲线如图所示:
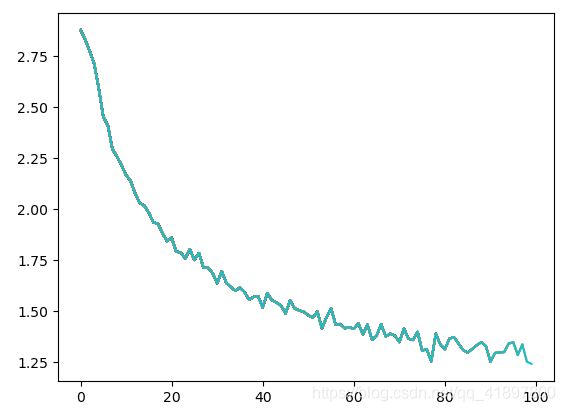
iter:5000 5.0% (time:0m 8s ) loss:3.0128 Tunison / Scottish ✗(Dutch)
iter:10000 10.0% (time:0m 16s ) loss:1.7359 Penners / Dutch ✓
iter:15000 15.0% (time:0m 25s ) loss:1.4132 Liao / Vietnamese ✗(Chinese)
iter:20000 20.0% (time:0m 33s ) loss:1.1189 Tong / Chinese ✗(Vietnamese)
iter:25000 25.0% (time:0m 41s ) loss:1.1114 Yi / Korean ✓
iter:30000 30.0% (time:0m 49s ) loss:2.0335 Aslam / Scottish ✗(English)
iter:35000 35.0% (time:0m 57s ) loss:0.5534 Gorski / Polish ✓
iter:40000 40.0% (time:1m 5s ) loss:1.8365 Simonek / Polish ✗(Czech)
iter:45000 45.0% (time:1m 13s ) loss:0.2622 Sook / Korean ✓
iter:50000 50.0% (time:1m 21s ) loss:0.5390 Gai / Chinese ✓
iter:55000 55.00000000000001% (time:1m 29s ) loss:2.5684 Muir / Chinese ✗(Scottish)
iter:60000 60.0% (time:1m 36s ) loss:1.9307 Amod / French ✗(English)
iter:65000 65.0% (time:1m 44s ) loss:0.4534 Ramires / Portuguese ✓
iter:70000 70.0% (time:1m 51s ) loss:0.2427 Jankilevsky / Russian ✓
iter:75000 75.0% (time:1m 59s ) loss:2.0286 Roux / Korean ✗(French)
iter:80000 80.0% (time:2m 7s ) loss:0.1539 Thao / Vietnamese ✓
iter:85000 85.0% (time:2m 14s ) loss:3.0313 Trampota / Spanish ✗(Czech)
iter:90000 90.0% (time:2m 22s ) loss:0.6395 Bhrighde / Irish ✓
iter:95000 95.0% (time:2m 29s ) loss:1.6953 Redman / Dutch ✗(English)
iter:100000 100.0% (time:2m 37s ) loss:1.2923 Lobo / Portuguese ✓
可以发现错误的,loss就很大,这与实际符合得很好
6. 评估结果
混淆矩阵
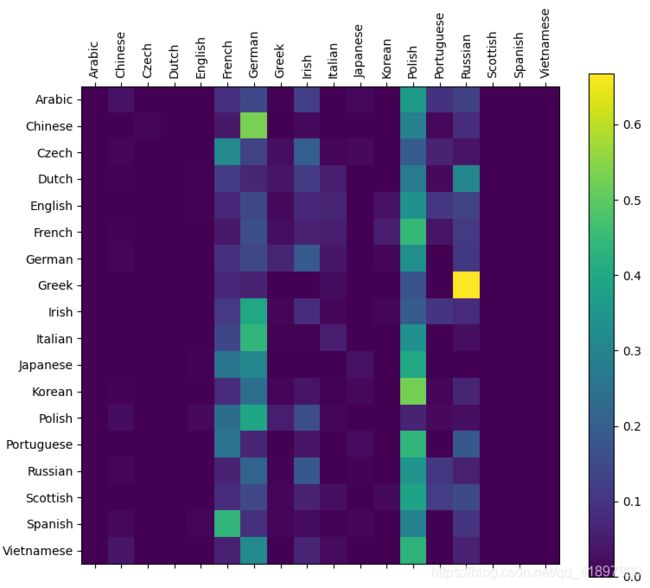
搞忘了……还没有加载模型,说怎么这么难看呢
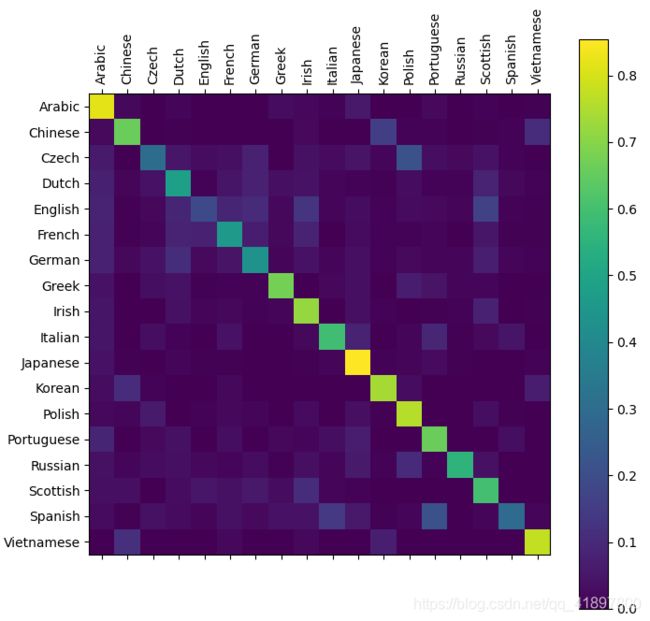
可以从主轴上挑出一些亮点,以显示它猜错了哪些语言,例如中文(朝鲜语)和西班牙语(意大利语)。模型似乎与希腊语搭配得很好,与英语搭配得很差(可能是因为与其他语言重叠)
再额外写一个评估,算总的精确度,运行三次结果分别为:0.5925、0.5876、0.5875,可见网络还是学到了一些东西
在用户输入上运行
关于函数topv, topi = output.topk(n_predictions, 1, True):
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)
- 沿给定dim维度返回输入张量input中 k 个最大值
- 如果不指定dim,则默认为input的最后一维
- 如果为largest为 False ,则返回最小的 k 个值
.topk()一个例子:
import torch
pred = torch.randn((4, 5))
print(pred)
values, indices = pred.topk(2, dim=1, largest=True, sorted=True) # k=2
print(indices)
# pred
tensor([[-0.2203, -0.7538, 1.8789, 0.4451, -0.2526],
[-0.0413, 0.6366, 1.1155, 0.3484, 0.0395],
[ 0.0365, 0.5158, 1.1067, -0.9276, -0.2124],
[ 0.6232, 0.9912, -0.8562, 0.0148, 1.6413]])
# indices!!!
tensor([[2, 3],
[2, 1],
[2, 1],
[4, 1]])
predict('Dovesky')
predict('Jackson')
predict('Satoshi')
(-0.70) Russian
(-1.24) Czech
(-2.50) English
(-0.75) Scottish
(-1.18) English
(-2.52) Dutch
(-0.73) Arabic
(-0.92) Japanese
(-3.23) Italian
predict('Yang')
predict('Si')
predict('Cheng')
(-0.49) Korean
(-1.04) Chinese
(-4.75) German
(-0.36) Korean
(-2.43) Chinese
(-2.76) Italian
(-0.57) Korean
(-1.23) Chinese
(-2.82) Scottish
7. 全部代码
import unicodedata
import string
import glob
import os
import torch
import torch.nn as nn
import random
import time
import math
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
all_letters = string.ascii_letters + " .,;'" # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ .,;'
n_letters = len(all_letters) # 57
category_lines = {}
all_categories = []
def unicodeToAscii(s):
Ascii = []
for c in unicodedata.normalize('NFD', s):
if unicodedata.category(c) != 'Mn' and c in all_letters:
Ascii.append(c)
return ''.join(Ascii)
def findFiles(path):
return glob.glob(path)
def readLines(filename):
lines = open(filename, 'r', encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
def letterToIndex(letter): # 找到letter在all_letters中的索引,例如"a" = 0, 'b' = 1
return all_letters.find(letter)
def letterToTensor(letter): # turn a letter into a <1 x n_letters> Tensor,'b' = tensor([[0., 1., 0., 0...
tensor = torch.zeros(1, n_letters)
tensor[0][letterToIndex(letter)] = 1
return tensor
def lineToTensor(line): # Turn a line into a 小结
上篇AI诗人RNN实战文章完成:
- 对处理好的numpy数组进行了一些操作
- 对中文进行操作
- 使用torch库的Embedding对输入数字进行编码
- 使用LSTM网络
本文:
- 对原始数据进行处理
- 对英文进行操作
- 使用one-hot编码
- 使用simple RNN网络
- 绘制混淆矩阵
总的来说,这次模型是Simple RNN,比AI诗人的LSTM简单一些,但是一些其他的操作,例如针对英文的unicode编码变成Ascii编码,one-hot编码等等
未来工作:继续复现更多RNN代码