Python爬取天气数据,并且进行天气预报(已实现)
分析任意一个城市的天气状况
- 先分析网页
- 爬取数据
-
- 获取城市ID
- 获得城市的昨天与今天的气温
- 城市多音字问题
- 爬取城市的历史数据(用到正则匹配)并进行数据清洗
- 天气数据分析绘图
- 用机器学习进行气温预测
-
- 将两部分数据合并成为一个xlsx文件
- 划分训练集与测试集
- 数据处理方法:
- 获取全年每天的平均最高温度
- 用不同的预测方法进行预测
- 还可以利用聚类分析分析你爬取的城市数据,有哪些城市可以是可以通过天气的分为相同一类的城市。
- 导入
先分析网页
因为版权问题不能发出爬取网页的过程,如有需要可以私信我获得数据与方法
1.我们可以找到一个 citySelectData2.js 文件,将这个文件的内容先保存到txt文件中后面对于查找任意一个城市的天气数据有巨大帮助。
2.以北京的历史天气为例
每次改变不同的月份,都会生成新的html文件(后面几条蓝色的文件)我们点开其中一个会发现data中就是我们所需要的天气数据。
3.在看上海的今天与明天的气温
网址为**https://**********/shanghai1d/**每次改变城市都是黄色标记的部分。所以我们可以利用这个使用Pinyin函数来将用户输入的城市名称转变为我们所需要的拼音在连接成一个新的我们所需要的网址。
之所以要保存今天和明天的气温是因为我们要用这个来比较我们预测温度的准确性。
爬取数据
获取城市ID
#### 先获取城市ID
def City_code(city_name):
f = open("城市代码.txt")
source = f.read()
f.close()
pos = source.find(city_name)
code = int(source[pos-8:pos][0:5])
print(code)
return code
city_name就是用户所输入的城市名称。将其在天气网站中对应的ID找出来才能进行历史温度的爬取。
获得城市的昨天与今天的气温
### 获取城市昨天与今天的气温
def WENDU(code,city_name):
p = Pinyin()
pinyin = p.get_pinyin(city_name)
pinyin = pinyin.replace("-","")
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:94.0) Gecko/20100101 Firefox/94.0'}
### 昨天的温度
url1 = "https://********/{0}1d/{1}.htm".format(pinyin,code)
r1 = requests.get(url1,headers=headers).text
soup1 = BeautifulSoup(r1,'lxml')
wendu1 = soup1('span',attrs={"class":"other-yes fl"})
wendu1_low = int(wendu1[0].text.split(":")[1].split("~")[0])
wendu1_high = int(wendu1[0].text.split("~")[1].split("°")[0])
### 今天的温度
url2 = "https://*****/{0}2d/{1}.htm".format(pinyin,code)
r2 = requests.get(url2,headers=headers).text
soup2 = BeautifulSoup(r2,'lxml')
wendu2 = soup2('span',attrs={"class":"other-yes fl"})
wendu2_low = int(wendu2[0].text.split(":")[1].split("~")[0])
wendu2_high = int(wendu2[0].text.split("~")[1].split("°")[0])
##### 输出今天的温度
wendu2 = wendu2[0].text.split(":")
print(city_name+"今天的天气情况为:"+str(wendu2[1]))
### 将昨天与前天的温度传出
out =[]
out.append(wendu1_high)
out.append(wendu1_low)
out.append(wendu2_high)
out.append(wendu2_low)
return out
爬去昨天和今天的气温为明天的气温预测做数据准备。(我只做了个简单的,可以增加过去的天数去预测明天,后天,或者一个星期的温度,原理都是一样的)使用的是requset,和BeautifulSoup进行爬取的数据。可以自行打印提取的网页信息 感受一下
(1) wendu2 = soup2(‘span’,attrs={“class”:“other-yes fl”})
(2) wendu2_low = int(wendu2[0].text.split(“:”)[1].split(“~”)[0])
(3) wendu2_high = int(wendu2[0].text.split(“~”)[1].split(“°”)[0])
这三步将网页中的最高气温与最低气温给提取出来了。
城市多音字问题
注意我们城市会有多音字的出现比如 六安 (luan)如果使用Pinyin会变成liuan 就会导致错误 可以使用有道翻译 将城市翻译成英文 这样就与天气网站中的拼音保持一致了。
###
url = "http://****/translate?smartresult=dict&smartresult=rule"
### 翻译城市多音字
t = str(int(time.time()*1000)) # 当前时间戳
s = "sr_3(QOHT)L2dx#uuGR@r" # 一段用来加密的字符串
sign_ = "fanyideskweb" + city_name + t + s
m = hashlib.md5() # 根据数据串的内容进行 md5 加密
m.update((sign_).encode('utf-8'))
# print(m.hexdigest())
word_key = { # key 这个字典为 POST 给有道词典服务器的内容
'i' :city_name,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':t,
'sign':m.hexdigest(),
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION',
'typoResult': 'false'
}
response = requests.post(url,data = word_key)# 发送请求
word_result = json.loads(response.text)
print(word_result["translateResult"][0][0]['tgt'])
pinyin = word_result["translateResult"][0][0]['tgt']
爬取城市的历史数据(用到正则匹配)并进行数据清洗
因为天气网站的城市历史数据2011-2015年的数据 与2016-至今的数据不是同种规格的。所以我分为了两次爬取,之后在合并成为一个完整的数据。(这里只贴出2011-2015年的数据爬取 后面的数据爬取类似)
def City_data_2011_2015(name,code):
print("正在爬取"+name+"2011年到2015年的天气数据:")
## 正则表达式来匹配数据
#### .是匹配除了/n之外的任何单个字符 此时为非贪心 只会匹配**** 里面的元素
r1 = '(.*?) '
re1 = re.compile(r1)
#### 看firefox可知为最高温度
r2 = '(.*?) '
re2 = re.compile(r2)
#### 看firefox可知为最低温度
r3 = '(.*?) '
re3 = re.compile(r3)
### 网站的url
## 存储2011-2015的天气预报
urls = []
for j in range(2011,2016):
url_20__ = ['http://****/Pc/GetHistory?areaInfo%5BareaId%5D={0}' \
'&areaInfo%5BareaType%5D=2&date%5Byear%5D={1}&date%5Bmonth%5D={2}'.format(code,j,str(i))for i in range(1,13)]
for x in range(len(url_20__)):
urls.append(url_20__[x])
### 网站的头
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:94.0) Gecko/20100101 Firefox/94.0'}
datess=[]
weeks=[]
wd_hs=[]
wd_ls=[]
weathers=[]
winer=[]
## 提取数据
for url in urls:
df = requests.get(url,headers = headers).json()['data']
#正则表达式提取日期
date = [l.split(' ')[0] for l in re1.findall(df)[::3]]
for i in range(len(date)):
datess.append(date[i])
#星期
week = [l.split(' ')[1] for l in re1.findall(df)[::3]]
for i in range(len(week)):
weeks.append(week[i])
#最高温度
wd_h = re2.findall(df)
for i in range(len(wd_h)):
wd_hs.append(wd_h[i])
#最低温度
wd_w = re3.findall(df)
for i in range(len(wd_w)):
if (wd_w[i]=="°"):
wd_ls.append("0°")
else:
wd_ls.append(wd_w[i])
#天气情况
wea = re1.findall(df)[1::3]
for i in range(len(wea)):
weathers.append(wea[i])
#风力
win = re1.findall(df)[2::3]
for i in range(len(win)):
winer.append(win[i])
time.sleep(1)
datas = pd.DataFrame()
datas['日期'] = pd.to_datetime(datess)
datas['星期'] = weeks
datas['最高气温'] = wd_hs
datas['最低气温'] = wd_ls
datas['天气情况'] = weathers
datas['风力'] = winer
#提取日期
datas['日期'] = datas['日期'].map(lambda x:str(x).split(' ')[0])
#去掉摄氏度
datas['最高气温'] = datas['最高气温'].map(lambda x:float(x.replace('°','')))
datas['最低气温'] = datas['最低气温'].map(lambda x:float(x.replace('°','')))
#计算平均气温
datas['平均气温'] = (datas['最高气温'] + datas['最低气温'])/2
datas.to_excel('城市数据信息/{}2011_2015_data_count.xlsx'.format(str(name)),index = None)
print(name+"2011年到2015年的数据保存成功!")
最后的数据样式是这样的
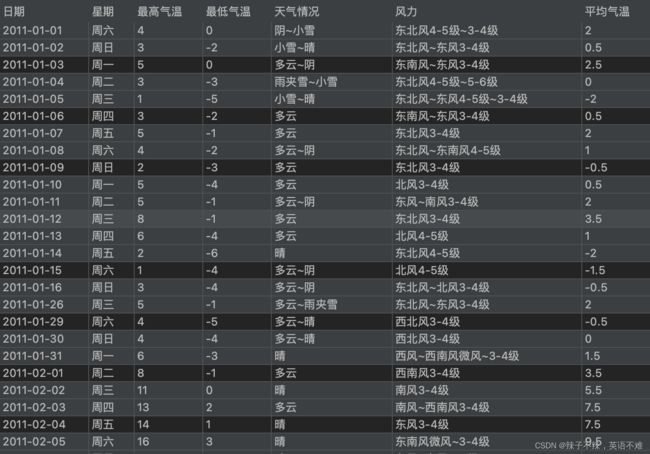
平均气温这一栏是为了之后画图给其提供横坐标位置与其他数据进行绘制关系图。
天气数据分析绘图
不把代码一一贴出了出来了展示出图例
空气质量可视化函数
#### 空气质量可视化函数
def KQ(city_name):
zhfont1 = matplotlib.font_manager.FontProperties(fname="字体/方正仿宋简体.TTF")
xlsx_file = '城市数据信息/{}2016_2022_data_count.xlsx'.format(city_name)
datas = pd.read_excel(xlsx_file)
### 温度与日期的变化
plt.figure(figsize=(12,4)) # 设置画布大小
#绘制折线图
plt.grid(True) ##增加格点
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(5))
plt.plot(list(datas['日期']),list(datas['空气质量数值']))
#设置标题
plt.title('{}空气质量变化趋势'.format(city_name),fontproperties=zhfont1)
#设置X轴标签
plt.xlabel('日期',fontproperties=zhfont1)
#设置Y轴标签
plt.ylabel('空气质量',fontproperties=zhfont1)
plt.ylim(0,450,75)
#选择标签角度
new_ticks = (0,365,730,1095,1460,1826,2191)
plt.xticks(new_ticks,rotation = 0)
plt.savefig("城市可视化图片文件夹/{}空气质量变化趋势".format(city_name),dpi=500,bbox_inches = 'tight')
sns.lineplot(list(datas['日期']),list(datas['空气质量数值']))
plt.show()
以上海为例
天气占比变化

温度与空气质量的关系
10年来的温度整体变化
最高温度的变化趋势
因为数据爬取出来了 所以想画什么样的图可以自行发挥。
爬取的数据

用机器学习进行气温预测
将两部分数据合并成为一个xlsx文件
划分训练集与测试集
如何预测 我自己的思路是 : == 比如要预测明天的气温,我们把今天的气温,昨天的气温,前天的气温找出来,算出10年来这一天的平均气温,用这些数据来预测明天的温度。
数据处理方法:
### 处理最高温度数据
def HIGHT_CHULISHUJU(city_name):
xlsx_file1 = "城市数据信息/{}2011_2015_data_count.xlsx".format(city_name) ##2011-2015年
xlsx_file2 = "城市数据信息/{}2016_2022_data_count.xlsx".format(city_name) ##2016-2011年
data1 = pd.read_excel(xlsx_file1)
data2 = pd.read_excel(xlsx_file2)
#### 将两个天数数据进行合并
data_综合日期 = list(data1["日期"])+list(data2["日期"])
data_综合星期 = list(data1["星期"])+list(data2["星期"])
data_综合最高气温 = list(data1["最高气温"])+list(data2["最高气温"])
#### 利用test为跳板 可以获得一个dataframe 然后供给data_test再次进行分割数据
test = pd.DataFrame()
test["日期"] = data_综合日期
### 获得 2011-2021年的数据的位置 与获取每年这一天的历史平均最高气温
data_test = pd.DataFrame()
data_test["年"] = test["日期"].map(lambda x : int(x.split("-")[0]))
# print(data1["年"])
data_test["月"] = test["日期"].map(lambda x : int(x.split("-")[1]))
data_test["日"] = test["日期"].map(lambda x : int(x.split("-")[2]))
data_test['星期'] = data_综合星期
data_test['真实温度'] = data_综合最高气温
avg_tempter={}
####获取全年每天的平均最高温度
###### 将数据集中的每一天的平均气温写出来
for i in range(1,13):
print("...",end="")
for j in range(1,32):
sumhea = 0
log =0
for k in range(2011,2023):
date = 0
for x in range(len(data_test['真实温度'])):
if(data_test["年"][x]==k and data_test["日"][x]==j and data_test["月"][x]==i):
date=x
log = log + 1
break
sumhea = sumhea + data_test['真实温度'][date]
avg_tempter['{0}-{1}'.format(i,j)]= float(sumhea/log)
print("\n正在处理成完整的数据集:")
#### 将获得的历史平均每一天的最高气温数据集保存下来
aveg = pd.DataFrame()
aveg["平均温度"] = avg_tempter.values()
data_index =[]
for i in avg_tempter.items():
data_index.append(i[0])
aveg["日期"] = data_index
aveg["月"] = aveg["日期"].map(lambda x : int(x.split("-")[0]))
aveg["日"] = aveg["日期"].map(lambda x : int(x.split("-")[1]))
aveg.to_excel("城市数据信息/{}历史这一天最高温度平均.xlsx".format(city_name))
###### 将历史中的这一天的最高平均温度添加到数据集中进行下一步的预测操作
avage_tempter=[]
for i in range(len(data_test['真实温度'])):
for j in range(len(aveg["平均温度"])):
if(data_test["月"][i]==aveg["月"][j] and data_test["日"][i]==aveg["日"][j]):
avage_tempter.append(aveg["平均温度"][j])
data_test['历史最高平均气温'] = avage_tempter
#######获取data数据集用于预测 将data return返回
##### 获取要用于训练的数据集的范围 可以自己进行设置
day1=0
day2=0
for i in range(len(data_test["年"])):
if (data_test["年"][i]==2012 and data_test["月"][i]==1 and data_test["日"][i]==1):
day1 = i
if (data_test["年"][i]==2022 and data_test["月"][i]==1 and data_test["日"][i]==1):
day2 = i
to_day_yesterdat = list(data_test['真实温度'][day1-2:day2-1])
yesterdat = list(data_test['真实温度'][day1-1:day2])
###### 利用data_test为跳板 可以获得一个dataframe 然后供给data 让data可以做为测试集与训练集
data = pd.DataFrame()
data["年"]=data_test["年"][day1:day2+1]
data["月"]=data_test["月"][day1:day2+1]
data["日"]=data_test["日"][day1:day2+1]
data['星期'] = data_test["星期"][day1:day2+1]
data['前天最高温度'] =to_day_yesterdat
data['昨天最高温度'] =yesterdat
data['真实最高温度'] =data_test['真实温度'][day1:day2+1]
data['每年这天的历史平均最高气温'] = data_test['历史最高平均气温'][day1:day2+1]
print("这是处理好的数据集的格式:")
print(data)
return data
样式为:
我选取了2012 -2022 这些年的数据 如果有兴趣 可以 选择全部年份 但要从2011-1-3 因为2号 1号没有前天的数据。
获取全年每天的平均最高温度
####获取全年每天的平均最高温度
###### 将数据集中的每一天的平均气温写出来
for i in range(1,13):
print("...",end="")
for j in range(1,32):
sumhea = 0
log =0
for k in range(2011,2023):
date = 0
for x in range(len(data_test['真实温度'])):
if(data_test["年"][x]==k and data_test["日"][x]==j and data_test["月"][x]==i):
date=x
log = log + 1
break
sumhea = sumhea + data_test['真实温度'][date]
avg_tempter['{0}-{1}'.format(i,j)]= float(sumhea/log)
获得的数据样式为:
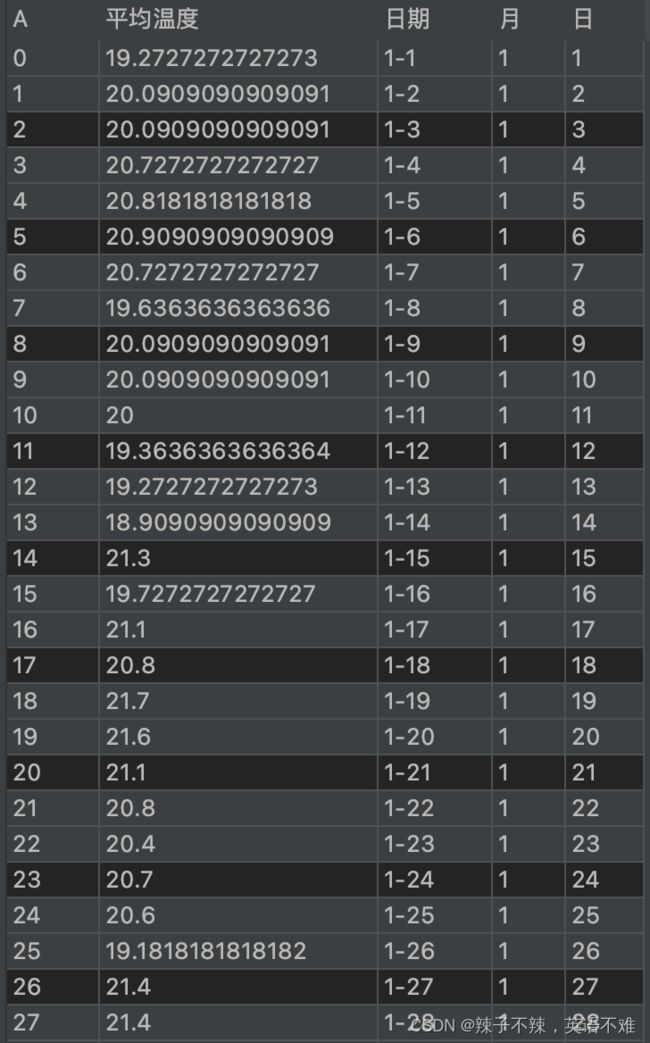
这些都是这一天最高温度的处理方法,同样的最低温度也同样的处理方法
用不同的预测方法进行预测
不一一列举了,只贴出部分代码
def HIGHT_YUCE(data,city_name,x_test):
data = data.drop(["星期"],axis=1)
### 标签
labels = np.array(data['真实最高温度']) ### 训练集的标签
data = data.drop(['真实最高温度'],axis=1)
#### 获得要预测的数据
x_test=HIGHT_INPUTYUCE(city_name,x_test)
y = np.array(data) #### 训练集
##### 均值归一化处理
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(y)
x = min_max_scaler.transform(y) #均值化处理
x_ = min_max_scaler.transform(x_test) #### 要预测的结果 转化为相同的数据格式
y=labels ### 训练标签
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2)
'''
数据的读取+均值化+划分
'''
#模型结构,采用relu函数为激活函数,输入层为6个属性
#下面为4层隐含层,每层的神经元个数依次为512,256,256,128
#输入层对应N个属性
model = keras.Sequential([
keras.layers.Dense(512,activation='relu',input_shape=[6]),
keras.layers.Dense(512,activation='relu'),
keras.layers.Dense(256,activation='relu'),
keras.layers.Dense(256,activation='relu'),
keras.layers.Dense(128,activation="relu"),
keras.layers.Dense(1)])#最后输出为一个结果,也就是预测的值
#定义损失函数loss,采用的优化器optimizer为Adam
model.compile(loss='mean_absolute_error',optimizer='Adam',metrics=['mean_squared_error'])
#记录并且开始训练模型
history = model.fit(x_train,y_train,batch_size =128,epochs=1000)#训练1000个批次,每个批次数据量为180
#### 使用test测试集 进行测试 计算出准确度
y_o_test = model.predict(x_test)
y_y_test = []
for i in range(len(y_o_test)):
y_y_test.append(y_o_test[i][0])
r = abs(y_test - y_y_test)
access1 = len(r[r<2])/len(r) ### 多层神经网络的准确度 ### 取误差为两度之间
#输出结果预测
y_pred=model.predict(x_)
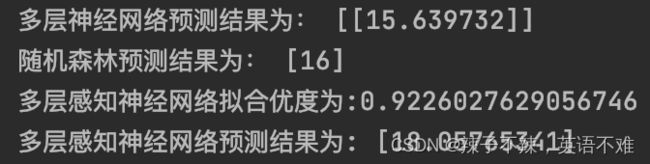
print('多层神经网络预测结果为:',y_pred)
### 画出损失函数
fig = plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("loss")
plt.plot(history.history["loss"],c = "r")
### 画出验证函数
plt.subplot(1,2,2)
plt.title("mean_squared_error")
plt.xlabel("Epoch")
plt.ylabel("mean_squared_error")
plt.plot(history.history["mean_squared_error"],c = "b")
plt.ylim(0,40,2)
plt.show()
fig.savefig("损失函数的图片/{}最高温度预测损失函数变化趋势".format(city_name),dpi=500,bbox_inches = 'tight')
输出结果:
明天最高的气温为19度

预测的结果为:
损失函数:

可以看的出来预测的结果的准确度还是较为精准的。
还可以利用聚类分析分析你爬取的城市数据,有哪些城市可以是可以通过天气的分为相同一类的城市。
可以自己多爬取几个城市尝试一下,代码附上:
def GUANLIAN2(city_name):
xlsxfile = "城市数据信息/{}2016_2022_data_count.xlsx".format(city_name)
data = pd.read_excel(xlsxfile)
data = data.drop("日期",axis = 1)
data = data.drop("星期",axis = 1)
data = data.drop("空气质量数值",axis = 1)
data = data.drop("最高气温",axis = 1)
data = data.drop("最低气温",axis = 1)
data = pd.get_dummies(data)
#### 0-1编码
labeled = data["平均气温"]
labeled = labeled.values
index =[]
for i in labeled:
index.append(int(i))
index.sort()
mideod_1 = np.percentile(index,50)
for i in range(len(data["平均气温"])):
if (data["平均气温"][i]<=mideod_1):
data["平均气温"][i] = "秋冬"
else:
data["平均气温"][i] = "春夏"
data = pd.get_dummies(data)
print("处理的数据集的格式为:")
print(data)
print("------------------------------------------------")
c = list(data.columns)
c0 = 0.5
s0 = 0.2
list1=[]
list2=[]
list3=[]
for k in range(len(c)):
for q in range(len(c)):
if c[k]!=c[q]:
c1 = data[c[k]]
c2 = data[c[q]]
I1=c1.values==1
I2=c2.values==1
t12=np.zeros((len(c1)))
t1=np.zeros((len(c1)))
t12[I1&I2]=1
t1[I1]=1
sp=sum(t12)/len(c1)
co=sum(t12)/sum(t1)
if co>c0 and sp>s0:
list1.append(c[k]+"--"+c[q])
list2.append(sp)
list3.append(co)
R = {"rule":list1,"support":list2,"confidence":list3}
R = pd.DataFrame(R)
print("有关联关系是:")
print("------------------------------------------------")
print(R)
导入
原创不易,请多多支持,如有错误欢迎指正。