Numba简介
from numba import jit
import numpy as np
import time
SIZE = 2000
x = np.random.random((SIZE, SIZE))
“”"# Numba简介
Python有解释器,比C语言满十倍甚至一百倍。
使用JIT(just-in-time)技术,使python实现c的速度
Python解释器工作原理
python自带虚拟机,用解释器将源代码转换成可执行的字节码。字节码在虚拟机上运行。
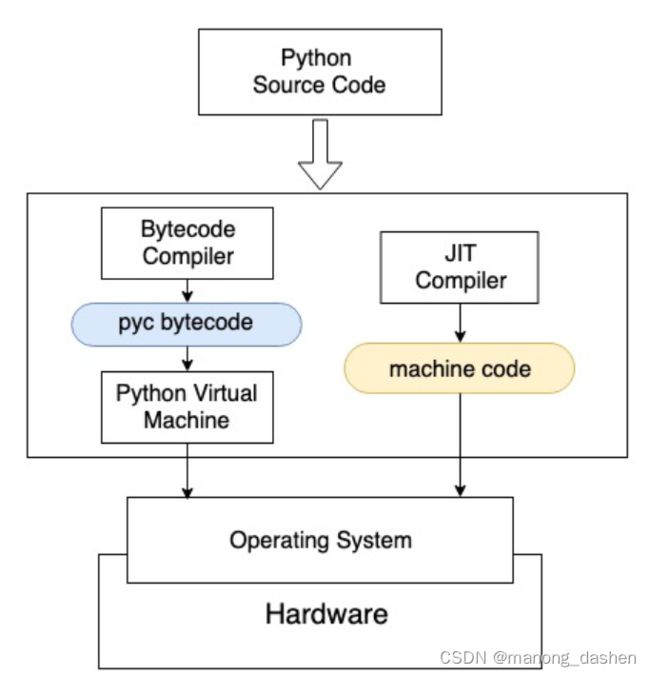
使用python example.py执行源代码时,Python解释器,会在后台启动字节码编译器,将源代码转换成字节码。字节码只能在虚拟机上运行,字节码默认后缀.pyc,python生成.pyc后一般放在内存中继续使用。pyc 字节码通过Python虚拟机与硬件交互, 虚拟机的出现导致程序和硬件之间增加了中间层, 运行效率折扣.Just-In-Time(JIT)技术为解释语言提供了优化.JIT编译器将python源代码编译成可执行的机器语言,可以在CPU等硬件上运行,跳过虚拟机.
入门Python Numba
Numba时开源JIT编译器,可以对Python代码进行CPU和GPU加速.
使用Numba只需要在原生函数上加一个装饰器.这些函数使用及时编译方式生成机器码,近乎机器码的速度运行.
安装方式
$conda install numba
使用方式
在原来的函数上添加一行注释
from numba import jit
import numpy as np
SIZE = 2000
x = np.random.random((SIZE, SIZE))
@jit
def jit_tan_sum(a):
tan_sum = 0
for i in range(SIZE):
for j in range(SIZE):
tan_sum += np.tanh(a[i, j])
return tan_sum
print(jit_tan_sum(x))
只需要在原来的上添加一行@jit,就可以将一个函数编译成机器码.代码执行效率提升很多倍.
Numba使用场景
Numba只支撑了Python原生函数和部分的NumPy函数
from numba import jit
import pandas as pd
x = {'a' : [1, 2, 3], 'b' : [20, 30, 40]}
@jit
def use_pandas(a): # 不支持
df = pd.DataFrame.from_dict(a)
df += 1
return df.cov()
print(use_pandas(x))
pandas是高层次封装,Numba不理解内部做了什么, 所以无法对其加速.而scikit-learn, tensorflow, pytorch等,已经做了大量优化,也不适合使用Numba加速.
同时, Numba不支持:
try...except异常处理with语句- 类定义
class yield from
Numba的@jit装饰器,使得用户不需要关注具体如何优化,如果发现不支持,Numba会继续使用Python原有的方式执行.也就是静茹object模式.
Numba还有nopython模式.将装饰器改为@jit(nopython=True)或者@njit, 使用强制加速模式, 不会进入object模式.
推荐将代码中计算密集的部分作为函数, 使用nopython进行优化. Numba可以与NumPy紧密结合, 可以将for循环单独提出来, 使用Numba加速.
编译开销
C/C++需要提前将整个程序编译好, 再执行可执行文件. Numba库提供的是一种懒编译, 再运行过程中第一次发现代码中有@jit, 所以叫懒编译. Numba使用时, 总时间 = 编译时间 + 运行时间. 编译开销很小. 对于多次调用的 Numba函数, 只需要编译一次.
from numba import jit
import numpy as np
import time
SIZE = 2000
x = np.random.random((SIZE, SIZE))
"""
给定n*n矩阵,对矩阵每个元素计算tanh值,然后求和。
因为要循环矩阵中的每个元素,计算复杂度为 n*n。
"""
@jit
def jit_tan_sum(a): # 函数在被调用时编译成机器语言
tan_sum = 0
for i in range(SIZE): # Numba 支持循环
for j in range(SIZE):
tan_sum += np.tanh(a[i, j]) # Numba 支持绝大多数NumPy函数
return tan_sum
# 总时间 = 编译时间 + 运行时间
start = time.time()
jit_tan_sum(x)
end = time.time()
print("Elapsed (with compilation) = %s" % (end - start))
# Numba将加速的代码缓存下来
# 总时间 = 运行时间
start = time.time()
jit_tan_sum(x)
end = time.time()
print("Elapsed (after compilation) = %s" % (end - start))
第一次执行需要编译, 第二次使用缓存的代码, 运行时间大大降低.
原生Python速度慢的另一个原因是变量不确定. 声明一个变量的语法简单, 如 a = 1, 但是没有指定a是一个整数还是浮点数. Python解释器要进行大量的类型判断. Numba要推断输入输出的类型, 才能转化为机器码. 针对该问题, 给出了 Eager Compilation的优化方式
from numba import jit, int32
@jit("int32(int32, int32)", nopython=True)
def f2(x, y):
return x + y
Numba的更多功能
@vectorize装饰器可以将函数向量化, 变成类似NumPy函数一样, 直接处理矩阵和张量.
给定nn矩阵,对矩阵每个元素计算tanh值,然后求和。
因为要循环矩阵中的每个元素,计算复杂度为 nn。
“”"
@jit
def jit_tan_sum(a): # 函数在被调用时编译成机器语言
tan_sum = 0
for i in range(SIZE): # Numba 支持循环
for j in range(SIZE):
tan_sum += np.tanh(a[i, j]) # Numba 支持绝大多数NumPy函数
return tan_sum
总时间 = 编译时间 + 运行时间
start = time.time()
jit_tan_sum(x)
end = time.time()
print(“Elapsed (with compilation) = %s” % (end - start))
Numba将加速的代码缓存下来
总时间 = 运行时间
start = time.time()
jit_tan_sum(x)
end = time.time()
print(“Elapsed (after compilation) = %s” % (end - start))