基于R语言主成分分析
在科学研究中,经常需要从同一个体(或观测单位)上观测多个指标,这些指标从不同方面反映个体的性质。主成分分析方法为无监督机器学习的一种方法,是通过线性降维将多个定量指标转换为少数几个综合指标的一种统计分析方法。
假设对于某个问题的研究涉及到P个指标,分别用Xl,X2….XP,表示,这个指标构成的P维随机向量设为X1-XP,对X进行线性变换,可以通过线性组合的方式形成新的综合变量这里用C表示:新的综合变量和原来变量之间的关系可以用下面的
公式表示:
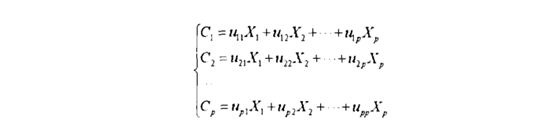
上式中的线性组合可以是任意的,由不同的线性变换得到的综合变量的统计特征也是不一样的。为了使综合变量可以较好的描述原变量的特征,应该要让(方差尽可能的大,并且Ci之问相互独立.
简单来说就是把多个指标通过空间投影,矩阵运算分析,转换为几个综合指标。
下面我们来介绍一下怎么通过R语言进行主成分分析,先导入我们的R包和数据
library(ggplot2)
library(factoextra)
library(FactoMineR)
library(foreign)
be <- read.spss("E:/r/test/Employee data.sav",
use.value.labels=F, to.data.frame=T)
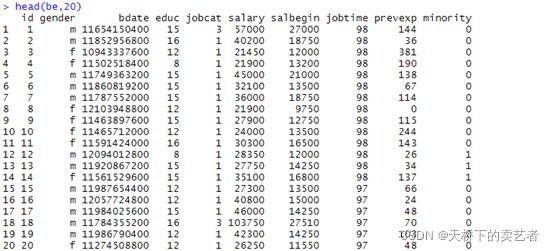
我们先来看看数据,这是一个雇员的情况数据(公众号回复:雇员数据,可以获得数据),有如下10个变量Id(观测号)、Gender(性别)、Bdate( 出 生 日 期)、Educ ( 受 教 育 程 度 ( 年 数))、Jobcat(工作种类)、Salary(目前年薪)、Salbegin(开始受聘时的年薪)、Jobtime(受雇时间)、Prevexp(受
雇以前的工作时间)、Minority(是否少数民族)。
我们取educ、salary、salbegin、jobtime、prevexp来进行主成分分析,先把数据提取出来
be1<-be[c(4,6,8,9,7)]
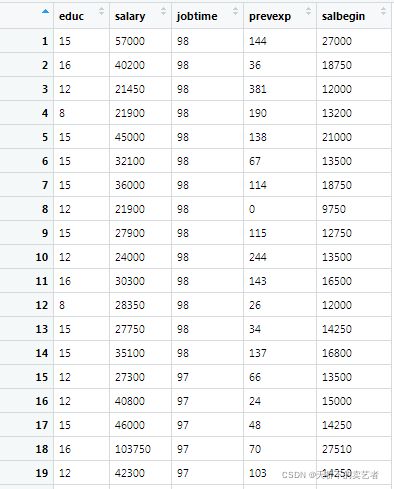
因为每个定义数据不同,取值范围波动很大,因先进行数据标准化,这一步很重要
be.scaled<-scale(be1)##标准化数据
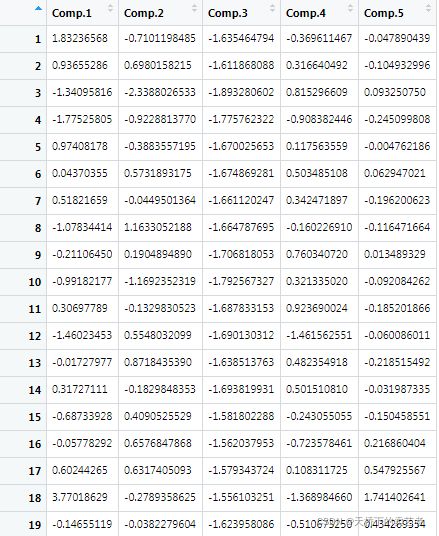
标准化后数据如下
标准话数据后就可以正式分析了,
pca <- princomp(be.scaled,cor = T)#主成分分析函数,cor为表示用样本的相关矩阵做主成分分析
画出碎石图
screeplot(pca,type="line",main="碎石图",lwd=2)
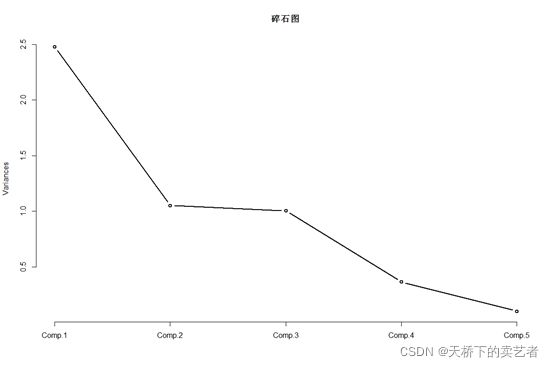
我们可以看到前3个主成分贡献比较大,,一般挑选前面几个方差最大的为主成分(累积方差贡献率在80%到90%之间)
dcor<-cor(be.scaled)###求相关矩阵
deig<-eigen(dcor) ##求相关矩阵的特征值和特征向量
deig$values###查看特征值
sum(deig$values)
sum(deig$values[1:3])/5###求前3个主成分的累积方差贡献率
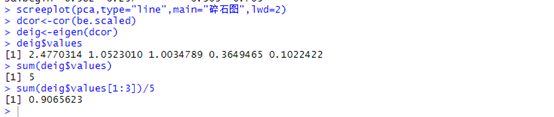
可以看到前3个成分(comp.1—comp.3)贡献率已经达到90%了,因此前三个为主成分,其实没有必要这么复杂,我们直接
summary(pca,loadings = T)
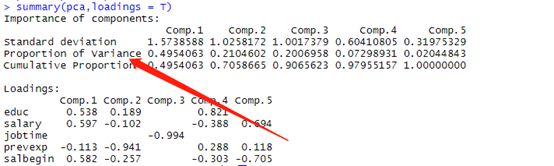
proportion of variance行给出了主成份的方差贡献率,我们把前3个加起来,结果也是一样的,loadings部分给出了载荷系数,我们可以看出各个指标的参与程度,得出各指标的系数。
生成我们的主成分的输出数据
pca_data <- predict(pca)
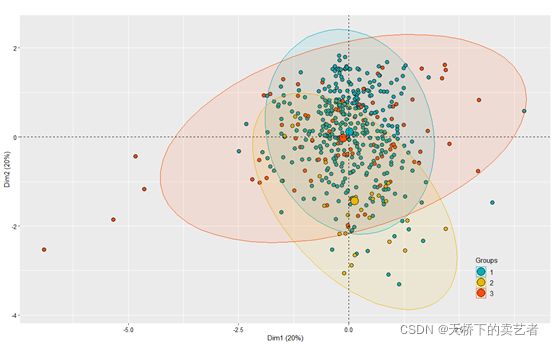
接下来进行做图,假设我们以Jobcat(工作种类)对主成分进行绘图,
be.pca<- PCA(pca_data, graph = FALSE)
我们只要在fill.ind这里定义就可以了,其他的不用修改,但这里要注意一点jobcat在数据中定义为数字,我们要把它改为因子,不然就会出错
fviz_pca_ind(be.pca,
geom.ind = "point",
pointsize =3,pointshape = 21,fill.ind = be$jobcat ,
palette = c("#00AFBB", "#E7B800", "#FC4E07"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups",
title="")+theme_grey()
重新来过
be$jobcat <-as.factor(be$jobcat)
fviz_pca_ind(be.pca,
geom.ind = "point",
pointsize =3,pointshape = 21,fill.ind = be$jobcat ,
palette = c("#00AFBB", "#E7B800", "#FC4E07"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups",
title="")+theme_grey()

还可以进一步修改,
fviz_pca_ind(be.pca,geom.ind="point",pointsize=3,
pointshape=21,fill.ind=be$jobcat,
palette=c("#00AFBB","#E7B800","#FC4E07"),
addEllipses=TRUE,legend.titl="Groups",title="")+theme_grey()+
theme(
text=element_text(size=12,face="plain",color="black"),
axis.title=element_text(size=11,face="plain",color="black"),
axis.text = element_text(size=10,face="plain",color="black"),
legend.title = element_text(size=11,face="plain",color="black"),
legend.text = element_text(size=11,face="plain",color="black"),
legend.background = element_blank(),
legend.position=c(0.88,0.15)
)
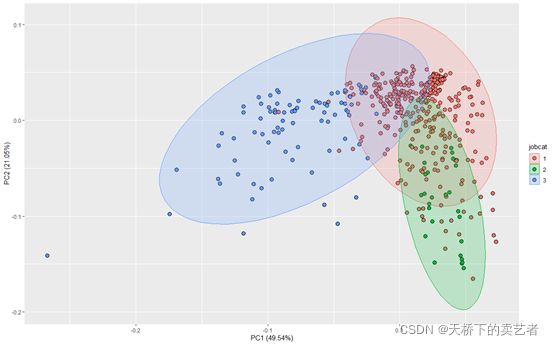
有没有简单点的方法?也可以通过ggfortify包进行快速做图,
library(ggfortify)
autoplot(prcomp(be.scaled), data = be,
shape=21,colour ="black",fill= 'jobcat', size=3,
frame = TRUE,frame.type = 'norm', frame.colour = 'jobcat')
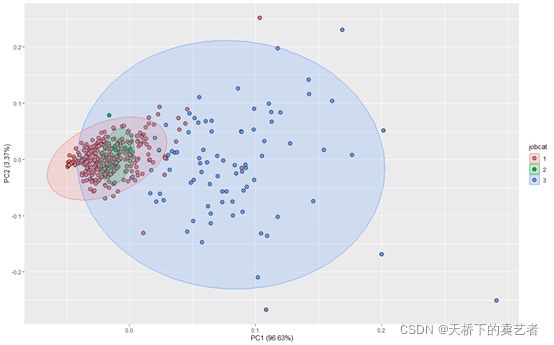
这里要注意一下,如果数据没有标准化,做出来的图完全不同,下图是没有标准化数据做的
autoplot(prcomp(be1), data = be,
shape=21,colour ="black",fill= 'jobcat', size=3,
frame = TRUE,frame.type = 'norm', frame.colour = 'jobcat')
参考文献:
[1]魏景海. 基于R下的主成分分析及应用[J]. 哈尔滨师范大学自然科学学报, 2014(4):4.
[2]胡良平. 基于SAS与R软件的主成分分析[J]. 四川精神卫生, 2018, 31(2):6.
[3]刘聪, 汪明. R软件在主成分分析中的应用研究[J]. 电脑知识与技术:学术版, 2011, 7(5):3.
[4]李小胜, 陈珍珍. 如何正确应用SPSS软件做主成分分析[J]. 统计研究, 2010, 27(8):4.
[5] Zhang J . Beautiful Data Visualization with R (《R语言数据可视化之美》)[M]. 2019.
