Yolov7-pose 训练body+foot关键点
一、Yolov7介绍:
yolov7网络由三个部分组成:input,backbone和head,与yolov5不同的是,将neck层与head层合称为head层,实际上的功能的一样的。对各个部分的功能和yolov5相同,如backbone用于提取特征,head用于预测。
根据上图的架构图走一遍网络流程:先对输入的图片预处理,对齐成640*640大小的RGB图片,输入到backbone网络中,根据backbone网络中的三层输出,在head层通过backbone网络继续输出三层不同size大小的feature map(以下简称fm),经过RepVGG block 和conv,对图像检测的三类任务(分类、前后背景分类、边框)预测,输出最后的结果。
推荐yolov7 网络架构深度解析_所向披靡的张大刀的博客-CSDN博客
github在最后
二、数据集准备
train 数据集 基于coco_whole_body_train 改造。
原始格式
${POSE_ROOT}
|-- data
`-- |-- coco
`-- |-- annotations
| |-- coco_whole_body_train2017.json
| `-- coco_whole_body_val2017.json
|-- person_detection_results
| |-- COCO_val2017_detections_AP_H_56_person.json
`-- images
|-- train2017
| |-- 000000000009.jpg
| |-- 000000000025.jpg
| |-- 000000000030.jpg
| |-- ...
`-- val2017
|-- 000000000139.jpg
|-- 000000000285.jpg
|-- 000000000632.jpg
|-- ...
Json 信息
image:包含了,宽高,地址,图像名
annotations: 包含imageid iscrowd信息还有其他关键点的信息
"bbox": [
339.88,
22.16,
153.88,
300.73
],

Yolo的格式
`-- |-- annotations
| |-- person_keypoints_train2017.json
| `-- person_keypoints_val2017.json
|-- person_detection_results
| |-- COCO_val2017_detections_AP_H_56_person.json
`-- images
| |-- train2017
| | |-- 000000000009.jpg
| | |-- 000000000025.jpg
| | |-- ...
| `-- val2017
| |-- 000000000139.jpg
| |-- 000000000285.jpg
| |-- ...
`-- labels
| |-- train2017
| | |-- 000000000009.txt
| | |-- 000000000025.txt #这里面图片的keypoint信息,以YOLO格式展示
| | |-- ...
| `-- val2017
| |-- 000000000139.txt
| |-- 000000000285.txt #这里面图片的keypoint信息,以YOLO格式展示
| |-- ...
`-- train2017.txt #这里面放的内容是:相对路径+图片名字
`-- val2017.txt #这里面放的内容是:相对路径+图片名字
打开一个labels 下的000000391895.txt格式
0 0.651281 0.479236 0.240437 0.835361 0.575000 0.169444 1.000000 0.576562 0.144444 2.000000 0.000000 0.000000 0.000000 0.596875 0.133333 2.000000 0.000000 0.000000 0.000000 0.575000 0.233333 2.000000 0.679688 0.225000 2.000000 0.565625 0.347222 2.000000 0.696875 0.347222 2.000000 0.562500 0.425000 2.000000 0.000000 0.000000 0.000000 0.620313 0.463889 1.000000 0.685937 0.461111 1.000000 0.576562 0.536111 2.000000 0.720313 0.650000 2.000000 0.564063 0.683333 2.000000 0.740625 0.797222 2.000000
解析为:

这里看到bbox 不一致,查看官方给的解释是归一化了,具体算法如下
img = images['%g' % x['image_id']]
h, w, f = img['height'], img['width'], img['file_name']
# The COCO box format is [top left x, top left y, width, height]
box = np.array(x['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
这边手动验证下
Weigth=640 heigth=360
Bbox=[339.88,22.16,153.88,300.73]
Yolo-Bbox(6_float):(339.88+153.88/2)/640=0.651281,
(22.16+300.73/2)/360=0.479236, 153.88/640=0.2404375, 300.73/360=0.835361
与yolo中的一致
Keypoints = [368/640,61/360]=[0.575,0.169444]
与yolo中的label格式一致。按照上述,制作yolo 23点的训练集和验证集。
三、 训练代码准备
有些bug没放上来,因为train的时候就能跑出来简单的bug。
修改data/coco_kpts.yaml文件中的数据读取路径。
修改models/hub/cfg文件,如yolo7_pose_kpts.yaml中的相关参数如:nkpt 从17改为32;
修改dataset第497行,有关如何读取txt数据的;
修改dataset第987行,有关数据如何变化的,将原bbox写为kpts;
修改dataset第365行,有关如何flip数据;
修改loss函数第187,和202行,有关loss_gain;
loss函数中第119行,有关sigmas,coco数据集中给出了,直接换上。
修改yolo函数第90行,有关self.inplace;
修改test第80行,有关flip_index翻转处理问题;
train.log
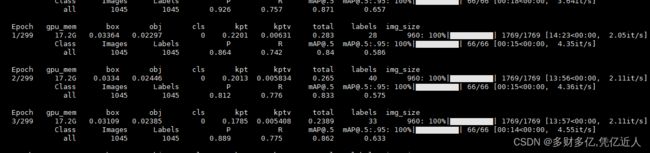
四、结论
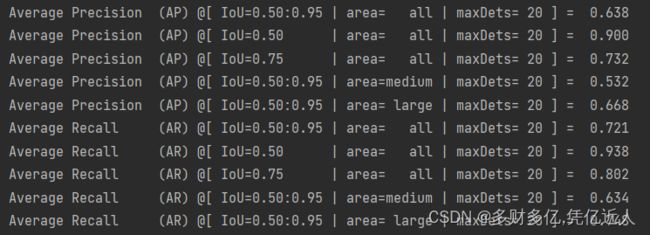
通过coco okps 计算100个迭代的mAP

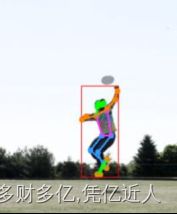
也有和我一样在body+foot的工作者 用yolov7 pose 出现了相同的问题
在多人视频下推理速度能达到30fps
会出现脚步乱连现象。
脚步乱连现象已解决,主要是和test.py 和 dataset.py 文件下的filp_idex 的设置有关。