ClickHouse用户路径分析之桑基图
ClickHouse用户路径分析之桑基图
路径分析模型
在互联网数据分析钟,有一种针对用户行为路径的分析模型——路径分析。路径分析应用是对特定事件的上下游进行可视化展示并分析用户在使用产品时的路径分布情况。比如:当用户使用某APP时,是怎样从【首页】进入【详情页】的,用户从【首页】分别进入【详情页】、【播放页】、【下载页】的比例是怎样的,以及可以帮助我们分析用户离开的节点是什么。
桑基图
桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图。它是一种特定类型的流程图,在常见的互联网分析后台中,桑基图常用来当作用户路径分析的可视化。通过桑基图,我们能清晰地看到各个事件之间的用户流向。
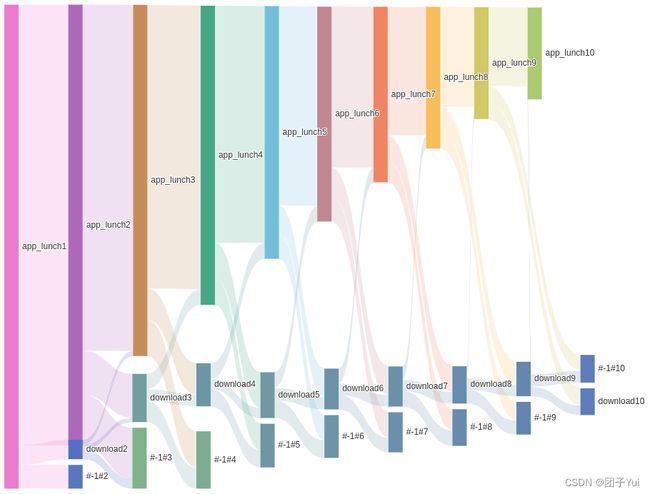
这里我们先对上图的元素进行一些说明:
-
app_lunch、download、#-1#为事件名,事件名后的序号表示此事件的层级;如:用户路径为app_lunch->download->#-1#,则此路径内位于第二个节点的download为图中的download2事件,路径内位于第三个节点的#-1#为图中的#-1#3事件。 -
#-1#为上一层的流失用户,如#-1#2即为第一层的所有流失用户

这里我们设置了app_lunch为起始事件,即用户的事件路径为app_lunch -> xxx -> xxx……(若只有单条路径app_lunch也算)的所有session,app_lunch1表示以app_lunch为起始事件的session数共有3405,所有数据会分别流向app_lunch2、download2、#-1#2,分别为用户路径为app_lunch->app_lunch->xxx->xxx……、app_lunch->download->xxx->xxxx……、app_lunch->#-1#(流失用户)三种路径。
桑基图实际统计的指标
从上述的例子,我们可以推导出,桑基图统计的,实际就是每个用户在每次seesion内符合条件的用户路径
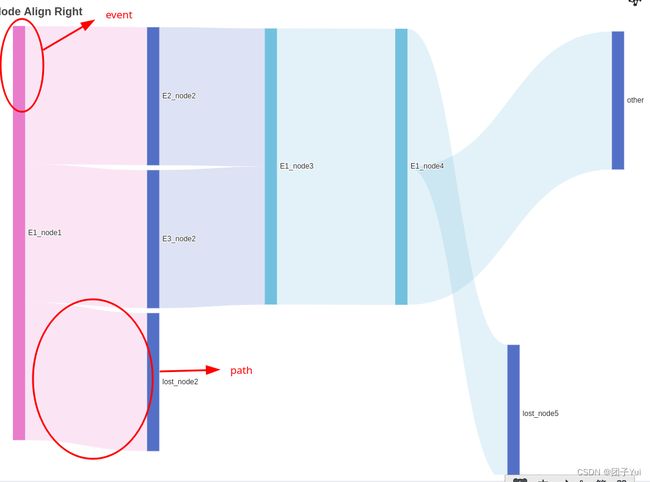

如上两图所示,我们将桑基图分为event和path两个部分,event统计每个路径,每个层级不同事件的出现次数。
- event:
以上图为例:
E1在第一列出现了三次,且第一列有且只有事件E1,因此桑基图 第一层 E1_node1=3。
E2、E3第二列各出现了一次,因此桑基图第二层 E2_node2=1,E3_node2=1
event所统计的,实际为每个${事件_层级下标}的出现次数
- path:
还是以上图为例:
我们将事件以窗口形式向右滑动并两两组合,路径链所产生的路径元组为
E1->E2->E1->E1->E2->E1->E3:
[(E1_NODE1,E2_NODE2),(E2_NODE2,E1_NODE3),(E1_NODE3,E1_NODE4)……]
path所统计的,实际就为所有( ${事件__层级下标} , ${事件__层级下标} )事件的出现次数
数据准备
SQL统计前需要注意以下几点
- session的划分
- 参考文档 3.3.1
- 是否需要合并重复事件
- 正向统计\反向统计:
- 正向统计: 以
xxxx事件开始 - 反向统计:以
xxxx事件结束 - 正向、反向统计在划分用户路径时,逻辑有着些许不同
- 正向统计: 以
- 桑基图的数据格式:
- 参考链接
数据计算
这里以正向计算(以xxxx事件开始)为模板:
WITH
/**
参数列表
**/
$startTime AS param_start_time,
$endTime AS param_end_time,
$second AS param_session_time,/*session划分时间,两个事件间隔 >$second,即视为不同seesion*/
'$startEvent' AS param_start_event,/*开始事件*/
$filterEvent AS param_filter_event,/*eg:event in('xxx','yyyy','zzzz')*/
$depth AS param_depth,/*要统计的深度,如:
A->B->C->${补充的代表流失用户事件},
此事件的深度便为4
*/
/*事件排序,session划分*/
toDateTime(minIf(etl_time, event = param_start_event)) AS end_event_mint,/*开始事件的最早出现时间*/
arrayCompact(
arraySort(
x -> (x.1),/*数组按元组内的时间asc排序*/
arrayFilter(
x -> ((x.1) >= end_event_mint),/*过滤大于等于开始事件最早出现时间的所有事件*/
groupArray((etl_time, event)) /*将用户事件与时间聚合成元组数组[(time,event),(time,event)]*/
)
)
) AS sorted_events,
arrayEnumerate(sorted_events) AS event_idxs,/*
[(time,event),(time,event)……] 数组的下标数组
如:[(time1,event1),(time2,even2)]
下标数组为[1,2]
*/
arrayFilter( /*过滤出按seesion划分后,每个开始节点的数组下标*/
(x, y, z) -> (((z.1) >= end_event_mint) AND (y > param_session_time)),
/*
(y > param_session_time):
若两事件间隔时间大于$second,则属于不同session
*/
event_idxs,/*下标数组*/
arrayDifference(sorted_events.1),/*event时间比较*/
sorted_events
) AS gap_idxs,
arrayMap(
x -> if(has(gap_idxs, x),1, 0),
event_idxs
) AS gap_masks,/*切分标记*/
arraySplit(
(x, y) -> y,
sorted_events,
gap_masks
) AS split_events, /*数据按不同session切分*/
arraySlice(arrayPushBack(event_chain_.2, '#-1#'), 1, param_depth) AS event_chain,
/*每个路径结尾补充一个用户流失事件,随后按照需要的深度对数组进行切分*/
/*
桑基图结构处理(即前文提到的path结构)
桑基图结构:{
source:'${事件名_层级}',
target:'${事件名_层级}',
value:$value
}
*/
arrayEnumerate(event_chain) AS event_chain_idx,/*获取事件路径下标数组*/
arrayPopBack(arrayMap(x -> (x, x + 1), event_chain_idx)) AS source_target_idx,
/*
下标数组按照从左至右的窗口两两划分
eg:[1,2,3,4]->[(1,2),(2,3),(3,4),(4,5)]
处理后的数组最后一条数据(4,5)为异常部分,通过函数arrayPopBack去除
*/
arrayPopBack(arrayMap(x -> (event_chain[x], event_chain[x + 1]), event_chain_idx)) AS source_target_event
/*
下标数组按照从左至右的窗口两两划分
eg:[A,B,C,D]->[(A,B),(B,C),(C,D),(D,'')]
处理后的数组最后一条数据(D,'')为异常部分,通过函数arrayPopBack去除
*/
SELECT
arrayJoin(source_target) AS t,
(t.1).1 AS idx_source,
(t.2).1 AS event_source,
(t.1).2 AS idx_targvet,
(t.2).2 AS event_target,
sum(user_count) AS value
FROM
(
SELECT
event_chain,
uniqCombined(user_id) AS user_count,
source_target_idx,
source_target_event,
arrayZip(source_target_idx, source_target_event) AS source_target
FROM
(
SELECT
user_id,
arrayJoin(split_events) AS event_chain_,
event_chain
FROM
(
SELECT
event,
user_id,
etl_time
FROM test.test_table
WHERE (etl_time>=param_start_time AND etl_time<param_end_time) AND param_filter_event
)
GROUP BY user_id
)
GROUP BY event_chain
HAVING (event_chain[1]) = param_start_event
)
GROUP BY t
补充
2022-08-18:
补充一些之前没有提到过的问题:
- 1.上文过滤并未对包含开始事件的子链进行切分,而是粗暴的使用HAVING (event_chain[1]) = param_start_event作为起始事件的规则,子链划分可作为参数单独计算:
eg:
--设A为开始事件
--按照session划分的了一个链:C->A->B->D,该条链内包含以开始事件开始的子链`A->B->D`。
--可以将是否切分子链作为一个单独的参数
WITH
$sub_start as param_sub_start
.....
if(
param_sub_start = 1 AND has(_event_chain_, param_start_event),
arraySlice(
_event_chain_,
indexOf(_event_chain_, param_start_event),
length(_event_chain_)
),
_event_chain_
) as event_chain,
....
- 2.桑基图的快速实现可以使用echarts实现
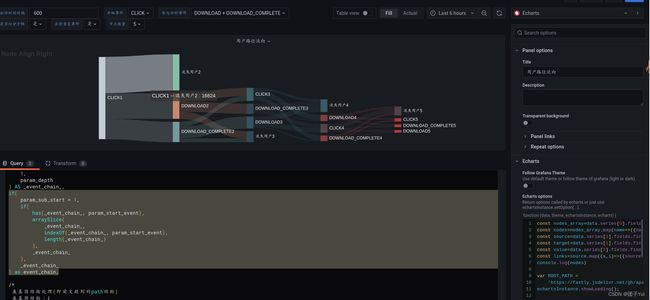
这里使用的是grafana+echarts快速实现的桑基图,有兴趣的可以参考
grafana+echarts