图卷积网络在推荐系统中的应用NGCF(Neural Graph Collaborative Filtering)配套pytorch的代码解释
注:本文所用到的代码及论文,文章底部有链接,可自行下载
论文部分:
1、简单介绍概念知识:
开发了一个新的推荐框架 Neural Graph Collaborative Filtering (NGCF),它通过在传播嵌入来利用 user-item 图结构。 这导致了用户项目图中高阶连通性的表达建模,以显式方式有效地将协作信号注入到嵌入过程中。通过利用来自用户项交互的高阶连通性来应对挑战,这是一种在交互图结构中编码协作信号的自然方式。(感觉官方术语太形式化,可看下面白话介绍)

图 1 说明了高阶连通性的概念。 推荐感兴趣的用户是u1,在用户-项目交互图的左子图中用双圆圈标记。 右子图显示了从 u1 扩展的树结构。 高阶连通性表示从路径长度 l 大于 1 的任意节点到达 u1 的路径。
例如,路径 u1 ← i2 ←u2 表示 u1 和 u2 之间的行为相似性,因为两个用户都与 i2 进行了交互; 较长的路径 u1 ← i2 ←u2 ← i4 表明 u1 很可能采用 i4,因为她的类似用户 u2 之前已经消费过 i4。 此外,从 l = 3 的整体来看,项目 i4 比项目 i5 更可能对 u1 感兴趣,因为有两条路径连接
总而言之,这项工作做出了以下主要贡献:
(1)强调了在基于模型的 CF 方法的嵌入功能中明确利用协作信号的关键重要性。
(2)提出了NGCF,一种基于图神经网络的新推荐框架,它通过执行嵌入传播以高阶连接的形式显式编码协作信号。
(3)对三百万个数据集进行实证研究。广泛的结果证明了 NGCF 的最新性能及其在通过神经嵌入传播提高嵌入质量方面的有效性。
框架中有三个组件:
(1)提供和初始化用户嵌入和项目嵌入的嵌入层;
(2) 多个嵌入传播层,通过注入高阶连接关系来细化嵌入;
(3) 预测层,聚合来自不同传播层的精细嵌入并输出用户-项目对的亲和度得分。
2、核心部分:
(1)Embedding Layer
可以看作是构建一个参数矩阵作为嵌入查找表:(注:这个主要是指创建初始的全节点embeding,连接用户和物品的结点信息)

(2)Embedding Propagation Layers(本文的核心创新点)

该过程有两个主要操作:消息构造和消息聚合。
先来个一阶聚合理解理解:
消息构造:
mu←i表示物品到用户的消息构造。其中W1和W2是用于提取传播有用信息的可训练权重矩阵,eu和ei表示用户和物品的embedding,用eu和ei内积相乘来获得邻域的的信息(通俗讲就是聚合中心结点的邻居信息),然后再加ei(通俗讲此处是指再加上自身结点信息),最后的N是u和i的度用来归一化系数,可以看做是折扣系数(这个在代码中的体现就是将邻接矩阵归一化处理,防止多层卷积聚合后导致信息值太大,会发生计划之外的偏差)
消息聚合:在这个阶段,我们聚集从u的邻域传播的消息,(对用户结点的信息进行更新)。

这个就是一阶聚合了,整合从每个item的聚合信息,然后再加上用户自身节点的信息,最后再激活一下
有了一阶传播就会有高阶传播:高阶传播实际就是将上述的一阶传播堆叠多层,这样经过 l 次聚合,每个节点都会融合其 l 阶邻居的信息,也就得到了节点的 l 阶表示

这个图就是表明u1-i4经过三阶传播的过程图
首先就是将i4、i5、i2三个物品的信息聚合到u2中,(其实在这个聚合过程进行的同时其他结点也都进行了相应的聚合邻接结点信息,例如在此时u1也聚合了i1、i2、i3的信息),然后用u1和u2继续传播聚合给i2(此时i2结点在此时已经包含图三所有结点的信息),然后再将i1、i2、i3信息给u1。至此物品i4经过三层转手操作,通过路径上的结点一步步传递到u1手中。(在这个过程,其实结点是不知道自己和远处的谁有联系或者有几层,但是当所有的结点都对自身相邻结点聚合时,信息就过来了——大力出奇迹,俗话说通过18个人你可以认识地球上任何一个人)


这个公式也不难理解,就是说每次传播时,聚合邻接结点信息时,邻接结点都是上次聚合更新后的结点信息(一定不是初始的embedding,结点信息每次更新都会发生变化的)
当然在我们将理论应用时,还是要转换成矩阵的形式,才是电脑更容易训练的方式
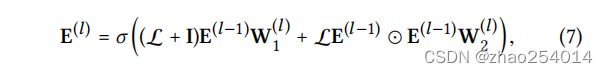

A是邻接矩阵,L就是归一化后的邻接矩阵,将得到的所有阶的embedding信息拼接起来起来作为最终的节点表示,再内积得到预测结果:


![]()
损失函数成对loss操作

pytorch代码部分:
因为本人是用自己的笔记本跑的(电脑年份较久,论文中原数据集大约3W用户,4W物品,我将其改为了4000用户,4W物品用于测试用,原数据大约每步要10分钟,现在每步大约1分钟,仅数据集大小差距)
步入正题:
首先我们设置些断点,然后开始一步步看其运行过程
debug main.py跳转至
data_generator = Data(path=args.data_path + args.dataset, batch_size=args.batch_size)这里就进入加载数据那部分了,点击

这一部分是代表找到训练集中的用户数和物品数(找到最大的数),同时将用户存入到列表中,每个用户所对应物品数求和,得到训练的数量(训练集中用户有多少个交互的物品)
全部循环结束后
self.exist_users=4001、n_items=35104、self.n_users=4000、self.n_train=181369
同样的过程在训练集中操作一遍其中self.n_items=40980,所以在训练集中找到了更多的物品
self.n_test=47341(测试集中的交互物品数)

得到最终的用户和物品数目

self.R = sp.dok_matrix((self.n_users, self.n_items), dtype=np.float32) #4001*40981这一步是生成全0稀疏矩阵(维度是: 用户数*物品数)
紧接着就是对生成邻接矩阵的陆续操作了

tolil():多标签的任务,需要对预测的top k index计算precision和nDCG。必要的一步是确定预测的index是否在稀疏矩阵中,比如13000次访问测试,列压缩稀疏矩阵csc是非常慢的,而链表稀疏矩阵lil则在50ms内就完成。
因此在需要对稀疏矩阵的元素值做大量访问时,首先将待访问的稀疏矩阵做一个转换 sp.tolil() 是非常必要的。
adj_mat = adj_mat.tolil()
R = self.R.tolil()生成邻接矩阵:
adj_mat[:self.n_users, self.n_users:] = R #将R矩阵放在右上角
adj_mat[self.n_users:, :self.n_users] = R.T #将R转置后放到左下角 其余两部分还是为0
adj_mat = adj_mat.todok()我们首先R是生成的4001*40981的用户*物品矩阵(交互的位置设为1)具体如下图:
在空的两部分还是全为0(左上and右下),这就是邻接矩阵的生成

接下来就是对邻接矩阵进行操作了:
对于归一化的操作,这里不是![]() 而是采用
而是采用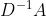 (就是行求和得度矩阵,再取-1)
(就是行求和得度矩阵,再取-1)
#归一化邻接矩阵加上自结点信息(对角矩阵)
norm_adj_mat = mean_adj_single(adj_mat + sp.eye(adj_mat.shape[0]))
mean_adj_mat = mean_adj_single(adj_mat) #归一化化邻接矩阵
#第一个是没归一化的邻接矩阵 第二个是归一化+自结点 第三个是归一化的
return adj_mat, norm_adj_mat, mean_adj_mat 接下来就进入模型设置用户与物品的embedding和weigth:
model = NGCF(data_generator.n_users,
data_generator.n_items,
norm_adj,
args).to(args.device)
......................
转至到初始化部分:
self.embedding_dict, self.weight_dict = self.init_weight()在权重部分:#gc代表聚集邻接结点的权重(对应W1), bi代表聚合邻接结点和自结点的权重(对应W2)
self.sparse_norm_adj = self._convert_sp_mat_to_sp_tensor(self.norm_adj).to(self.device)这个是将归一化+自结点的邻接矩阵 由稀疏矩阵转换为tensor张量矩阵
接下来就是训练了:
这里再细讲一下.sample()的使用
pos_items, neg_items = [], []
for u in users:
pos_items += sample_pos_items_for_u(u, 1)
neg_items += sample_neg_items_for_u(u, 1)首先是从用户存在列表(exist_users)中随机选取1024个用户,然后pos是指从每个用户交互过的物品中随机选取一个,neg是指从未交互物品列表中随机抽取一个物品
总共有1024次循环:最后结果是len(user)=len(pos)=len(neg)=1024
接下来进入
u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model(users,pos_items,eg_items,
drop_flag=args.node_dropout_flag)
........................................................
#进入NGCF的forward 进行传播
A_hat = self.sparse_dropout #结点失活0.1 #最初的用户-物品的embedding 44982*64
ego_embeddings = torch.cat([self.embedding_dict['user_emb'],
self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings] #得到用户和物品的embed结合 [44982, 64]
for k in range(len(self.layers)): #生成1-3跳embed信息
#聚合u所有邻居的消息 44982*64
side_embeddings = torch.sparse.mm(A_hat, ego_embeddings)
# transformed sum messages of neighbors.目标结点进行特征变换矩阵
sum_embeddings = torch.matmul(side_embeddings, self.weight_dict['W_gc_%d' % k]) \
+ self.weight_dict['b_gc_%d' % k]
# bi messages of neighbors.
# element-wise product
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
# 合并自嵌入,邻居的嵌入
# transformed bi messages of neighbors.再次变换特征
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_%d' % k]) \
+ self.weight_dict['b_bi_%d' % k]
# non-linear activation. #非线性激活函数,u到u和i到u的两部分
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
# message dropout. 得到的信息结点再次失活
ego_embeddings = nn.Dropout(self.mess_dropout[k])(ego_embeddings)
# normalize the distribution of embeddings. #标准化
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
#当前阶数的embed加入进去 (当前阶数的embedding+用户-物品的embe(这个每次更新后都会更新))
#上面的all—embed是一个列表经过三次循环后,包含1-3的embed+自身结点的embed,所以列表索引为4
all_embeddings = torch.cat(all_embeddings, 1) # 所有跳数组合44982*256
#分用户和物品em
u_g_embeddings = all_embeddings[:self.n_user, :] #4001*256
i_g_embeddings = all_embeddings[self.n_user:, :] #40981*256
"""
*********************************************************
look up.
"""
# 查询此批次1024数据的embed
u_g_embeddings = u_g_embeddings[users, :] #此批次用户的embed
pos_i_g_embeddings = i_g_embeddings[pos_items, :] #正样本的embed
neg_i_g_embeddings = i_g_embeddings[neg_items, :] #负样本的embed接下来我们进行brp 损失函数
batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss(u_g_embeddings,
pos_i_g_embeddings,
neg_i_g_embeddings)
..........................
pos_scores = torch.sum(torch.mul(users, pos_items), axis=1) #用户与正样本相乘 再求和
neg_scores = torch.sum(torch.mul(users, neg_items), axis=1) #用户与负样本相乘 再求和
下面就顺着下去
这段代码就是说每10步会跳出去一次,其余的9步会输出 perf-str,也就是输出损失函数

满足10epoch时,就会执行测试集
ret = test(model, users_to_test, drop_flag=False)在这个测试集中和训练集的操作大同小异,此处不细致展开,在取样时只取正样本罢了,然后各种判断实验结果的指标
![]()
至此,陆陆续续写了一天,本人也是在读学生,记录学习时的一些思路,奈何实力有限,所以有哪些错误的地方还请指出,哈哈,毕竟共同进步,后路的论文还会陆续更新,敬请期待!!!!
论文及代码获取:
github:https://github.com/huangtinglin/NGCF-PyTorch
或者网盘获取
链接:https://pan.baidu.com/s/103DlE-aU66wlqOuA2u4PeA
提取码:715z
复制这段内容后打开百度网盘手机App,操作更方便哦