图像分割(七) —— Transformer and CNN Hybrid Deep Neural Network
Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
- Abstract
- Method
-
- A. Architecture
- B. Swin Transformer-Based Encoder
- C. CNN-Based Decoder
Abstract
本文提出了一种变压器和卷积神经网络(CNN)混合深度神经网络,用于非常高分辨率(VHR)遥感图像的语义分割。该模型遵循了一个编码器-解码器的结构。编码器模块使用一种新的通用骨干双变压器来提取特征,以实现更好的远程空间依赖建模。该解码器模块利用了基于cnn的遥感图像分割模型的一些有效的块和成功的策略。在框架的中间,应用基于深度可分卷积(SASPP)的空间空间金字塔池块获得多尺度上下文。U形解码器用于逐步恢复特征图的大小。在相同大小的编码器和解码器特征图之间建立了三个跳跃连接,以保持局部细节的传输,增强了多尺度特征的通信。在分割前添加一个挤压激励(SE)通道注意块进行特征增强。结合一个辅助边界检测分支,为语义分割提供边缘约束。在国际摄影测量和遥感学会(ISPRS)Vaihingen and Potsdam benchmarks 测试上进行了广泛的消融实验,以测试该网络的多个组件的有效性。
将Swin变换器结构应用于VHR遥感图像的语义分割任务中,设计了一种基于cnn的解码器来恢复特征图的大小,并获得了语义分割结果。在解码器模块中,应用了基于cnn的VHR遥感图像研究中的多个有效块和成功的策略。
本文的主要贡献如下:
- 我们将Swin变压器主干与基于cnn的解码器相结合,构建了一个新的VHR遥感图像语义分割的深度学习框架。Swin变压器的结构使其能够建模图像中的长期空间依赖性,并同时获得层次特征。
- 采用基于深度可分离卷积(SASPP)块的空间金字塔池块,设计SE块保留局部细节,恢复特征映射的分辨率,获得竞争性的分割结果。通过消融研究,我们测试了解码器模块中每个组件的影响。
- 我们综合比较了几种最流行的基于CNN和转换器的骨干技术对VHR遥感图像语义分割的效果,并进一步可视化和分析了其输出特征图的特征。
- 受基于cnn的遥感图像分析的启发,我们采用了双任务网络设计,并增加了辅助边界检测任务,以提高边界像素定位的精度,降低语义分割的盐和胡椒噪声。考虑到基于cnn的主干和基于转换器的主干所提取的特征图之间的差异,我们设计了两种边界检测策略。通过实验比较,我们在该网络中选择了一个更有效的边界检测分支。
Method
A. Architecture
所提出的变压器和CNN混合语义分割网络的框架(见图1)遵循编码器-解码器范式,并由以下模块组成。
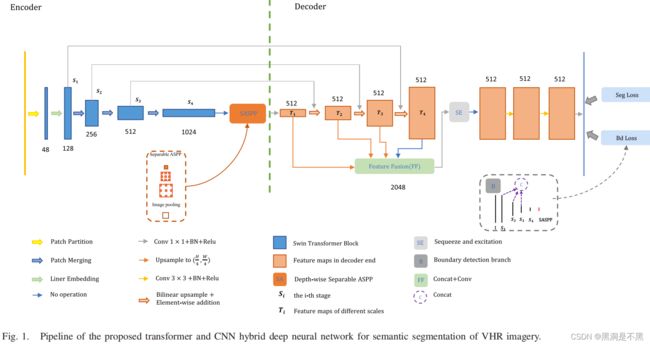
- 采用Swin transformer backbone进行特征提取。与基于Cnn的主干网相比,Swin变压器不包含感应偏置,因此可以更好地建模图像中的长期空间依赖性。同时,与其他基于变压器的骨干网相比,Swin变压器具有较低的计算复杂度、较快的推理速度,并可以输出分层特征映射。
- 在网络中间插入一个SASPP块,根据最大尺寸特征图整合多尺度上下文信息。
- 采用 U 形解码器逐步恢复特征图的大小。在相同大小的编码器和解码器特征图之间建立了三种跳跃连接,以保持局部细节的传输,增强了多尺度特征的通信。在分割前添加一个SE通道注意块,重新分配多分辨率特征图的权值,以获得更好的分割结果。
- 利用双任务设计,添加了一个边界检测任务来辅助语义分割任务。考虑到Swin变压器输出的特征图与基于Cnn的骨干网之间的差异,我们设计了两种边界检测策略,并在该网络中结合了一种更有效的策略。
B. Swin Transformer-Based Encoder
该编码器由两部分组成:Swin变压器主干用于提取层次特征图,SASPP块用于捕获多尺度上下文信息
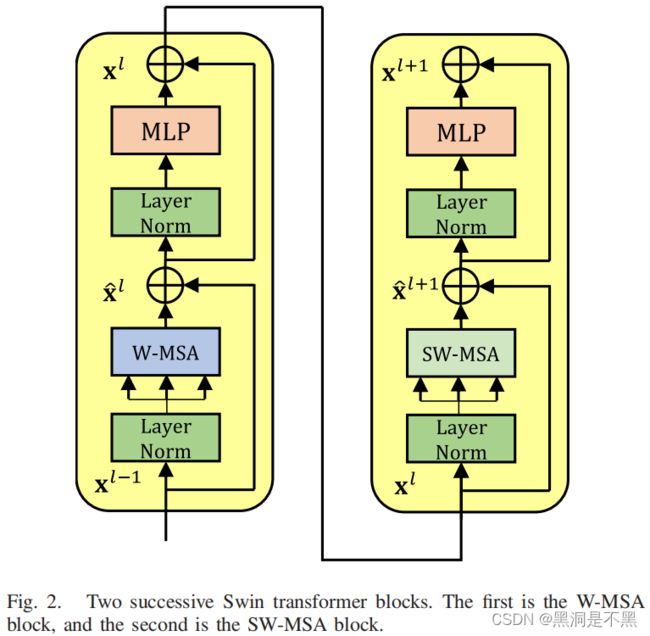
*1) Swin Transformer Block *
Swin transformer block是 Swin transformer backbone 的核心。它包括两种形式的基于窗口的多头自注意(W-MSA)块和基于移位窗口的多头自注意(SW-MSA)块。将W-MSA块和SW-MSA块依次连接起来,从而更有效地获得全局空间依赖性。具体计算过程如图2所示。
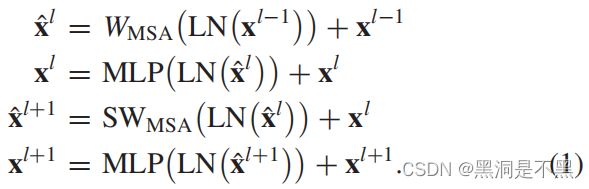
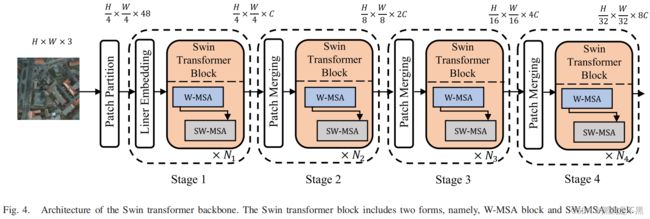
2) Swin Transformer Backbone
Swin变压器主干网的体系结构很简单,由一个补丁分区模块和四个阶段组成。每个阶段包含一个线性嵌入/补丁合并块和偶数个的Swin变压器块(见图4)。具体来说,Swin变压器的主干首先通过块分区将输入图像分割成不重叠的块。在Swin变压器[20]的原始工作中,每个补丁的大小为4×4,这意味着图像细节比ViT结构[16]得到了更好的保存。然后,在第一阶段,补丁线性化并输入到连续的N1 Swin变压器块。第2-4阶段的补丁合并与第1阶段的线性嵌入略有不同。首先将四个相邻的补丁连接起来,并合并成一个补丁。因此,将特征图的分辨率更改为一半,并将信道号更改为4次。通过1×1卷积,将通道减少一半,然后,这些特征输入随后连续的Ni(i = 2,3,4)Swin变压器块中。
3) Multiscale Context Extraction
我们使用经典的SASPP [45]块来提取多尺度特征。从第4阶段输出的特征图中提取不同感受域的特征。SASPP块包含5个平行分支,即: 1)全局平均池化层;2)三个3×3深度可分离的卷积,速率为{2、3、4};3)1×1卷积。速率根据阶段4中特征图的大小设置。我们将原始图像裁剪为300×300作为输入。因此,第4阶段的输出特性为10×10。在这种情况下,膨胀卷积的速率设置为{2,3,4},对应于阶段4的特征图上的距离{5,7,9},原始图像上的距离{160,224,288}
C. CNN-Based Decoder
我们应用一个 U 形解码器来逐步恢复特征图的大小,并预测语义分割结果。在相同大小的编码器和解码器特征图之间建立了三个跳过连接,以保持局部细节的传输,增强了多尺度特征的通信。此外,在分割前添加一个SE块,以有选择性地增强更重要特征的权重,减少不相关特征的权重。基于cnn的解码器的体系结构如图5所示。

首先,将第1-3阶段输出的张量的通道维数利用1×1的卷积转换为512,以准备特征融合。由SASPP块输出的特征图的形式可以标记为 T 1 ∈ R ( H / 32 ) × ( W / 32 ) × 512 T_1∈R^{(H/32)×(W/32)×512} T1∈R(H/32)×(W/32)×512. 它连接两个分支:一个分支链接到特征融合块,另一个分支首先上采样到 [ ( H / 16 ) , ( W / 16 ) ] [(H/16),(W/16)] [(H/16),(W/16)],然后以元素加法的方式与阶段3输出的特征图合并。输出的特征图可以标记为 T 2 ∈ R ( H / 16 ) × ( W / 16 ) × 512 T_2∈R^{(H/16)×(W/16)×512} T2∈R(H/16)×(W/16)×512. T 2 T_2 T2也连接到两个分支:一个分支是融合模块,另一个分支继续上采样到 [ ( H / 8 ) , ( W / 8 ) ] [(H/8),(W/8)] [(H/8),(W/8)] ,然后通过元素添加与阶段2输出的特征图融合。结果可以标记为 T 3 ∈ R ( H / 8 ) × ( W / 8 ) × 512 T_3∈R^{(H/8)×(W/8)×512} T3∈R(H/8)×(W/8)×512. T 3 T_3 T3 仍然连接两个分支:一个分支是特征融合块,另一个分支继续上采样并与阶段1输出的特征图融合,得到 T 4 ∈ R ( H / 4 ) × ( W / 4 ) × 512 T_4∈R^{(H/4)×(W/4)×512} T4∈R(H/4)×(W/4)×512. T 4 T_4 T4 最终被输入到特征融合模块中。
在特征融合模块中,首先通过双线性插值将 T 1 − T 3 T_1-T_3 T1−T3上采样到与 T 4 T_4 T4 相同的分辨率,然后将特征图连接起来,构建 T 0 ∈ R ( H / 4 ) × ( W / 4 ) × 2048 T_0∈R^{(H/4)×(W/4)×2048} T0∈R(H/4)×(W/4)×2048. 为了增强通道之间的交互作用,我们使用SE块来重新校准特征映射的权重。其目的是选择性地激发从多尺度特征中进行语义分割时更有效的特征。然后对SE块输出的特征映射进行两次连续的3×3卷积和一次1×1卷积,得到最终预测的语义分割结果。
由Swin变压器主干和上述基于cnn的解码器组成的范式是我们工作的基线。根据SwinB或SwinS作为骨干的具体用途,这些模型可以分别表示为SwinB-CNN或SwinS-CNN.
1) SE Block
假设 F t r \mathcal{F}_{tr} Ftr 将输入张量 X ∈ R h ′ × w ′ × c ′ X∈R^{h'×w'×c'} X∈Rh′×w′×c′ 转换为张量 U ∈ R h × w × c U∈R^{h×w×c} U∈Rh×w×c 变换,我们将以SE操作实现 U ∈ R h × w × c U∈R^{h×w×c} U∈Rh×w×c 为例来说明SE块的建设。
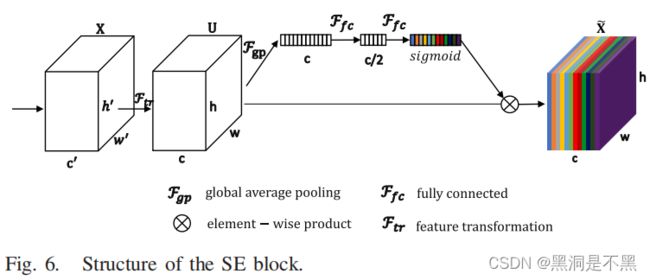
如图6所示,首先通过全局平均池压缩 U ∈ R h × w × c U∈R^{h×w×c} U∈Rh×w×c 的空间维数,生成向量 P ∈ R c P∈R^c P∈Rc. 因此,向量中的每个元素都可以看作是嵌入了相应通道的全局信息。具体来说, P ∈ R c P∈R^c P∈Rc可按以下公式计算:
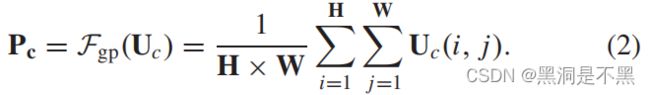
然后,通过两个连续的全连接层得到权值向量 V ∈ R c V∈R^c V∈Rc,其详细结构可表示为

F f c 1 \mathcal{F}_{fc1} Ffc1和 F f c 2 \mathcal{F}_{fc2} Ffc2中的神经元数量分别设置为(c/2)和c,最后,对权值向量V与输入特征U进行元素乘积,得到最终的输出张量 X ~ \tilde{X} X~
2) Boundary Detection
基于对[7]、[31]、[33]研究的探索,在基于cnn的遥感图像分割网络中结合边缘约束,可以有效地提高模型的性能。因此,我们采用双任务网络设计,利用辅助边界检测任务来提高边界像素定位的精度,降低语义分割中的盐噪声和胡椒噪声。
为了避免许多新参数的引入,边界检测任务和语义分割任务共享相同的主干。编码器-解码器结构中的特征映射直接用于预测边缘像素。我们在本工作中尝试了两种不同的边界检测结构,如图7所示。第一种结构应用第1、2和4阶段输出的特征图来预测边缘像素,第二种结构应用第1-3阶段输出的特征图来预测边缘像素。第一个设计借鉴了基于cnn的边缘提取方法的经验,使用浅层特征来保存局部细节,并使用深层特征来抑制复杂的纹理[7],[46] [36]。第二种设计是我们根据第一个设计的特性调整的结构。我们调整的原因和两种策略的比较实验分别显示在V-A和V-D节的比较。
采用最新研究的边界度量(BF1)来评价边界检测[47]的精度,并采用1−BF1作为模型训练的损失函数。 B F 1 = 2 × ( p r e c i s i o n × r e c a l l ) / ( p r e c i s i o n + r e c a l l ) BF1 = 2 × (precision × recall)/(precision + recall) BF1=2×(precision×recall)/(precision+recall) 可以全面评价边界检测结果的查全率和精度。
我们使用最广泛使用的交叉熵损失来评估语义分割的准确性。总损失是边缘损失和分割损失的加权之和 l o s s t o t a l = α ⋅ l o s s s e g + β ⋅ l o s s b d (4) loss_{total} = α · loss_{seg} + β · loss_{bd}\tag{4} losstotal=α⋅lossseg+β⋅lossbd(4)理论上,α和β的设置应该是动态的。由于模型训练早期的边缘定位不准确,边界检测对模型训练后期语义分割的影响也需要通过多个实验进行分析。然而,根据我们使用预训练的模型对多组α和β组合进行的实验,α和β的值对模型的收敛速度和精度影响不大。因此,在我们的双任务实验中,我们统一地将α的权重设为1,β设为0.15。