吴恩达深度学习笔记-循环神经网络(RNN) (第13课)
序列模型
- 一、为什么选择序列模型
- 二、数学符号
- 三、循环神经网络
- 四、穿越时间的反向传播
- 五、不同类型的循环神经网络
- 六、语言模型和序列生成
- 七、新序列采样
- 八、RNN神经网络的梯度消失
- 九、GRU单元(门控循环单元)
- 十、长短期记忆(LSTM)
- 十一、双向RNN(Bidirectional BNN,BRNN)
- 十二、深层循环神经网络
- 十三、RNN为什么要使用Clipping?
- 十四、解决梯度消失
一、为什么选择序列模型
序列模型的应用:
-
语言识别:

-
音乐生成:
输入可以是空集,也可以是几个数字。有点类似神经风格迁移。

-
情感分类:

-
DNA序列分析:

-
机器翻译:

-
视频动作识别:

-
命名实体识别:

在序列模型问题中,输入数据 X X X和输出数据 Y Y Y可能都是序列, X X X 和 Y Y Y可能会不一样长;也有可能输入数据 X X X和输出数据 Y Y Y的其中一个是序列。
二、数学符号
以命名体识别为例子,如下图,输入样本 X X X,然后输出结果 Y Y Y; Y Y Y中的 1 1 1表示是人名。

- x < t > x^{
} x<t>:序列样本 x x x的第t个元素 - y < t > y^{
} y<t>:输出序列 y y y的第t个元素 - x ( i ) < t > x^{(i)
} x(i)<t>:第 i i i个样本序列样本 x ( i ) x^{(i)} x(i)的第t个元素 - T x T_x Tx、 T y T_y Ty:输入序列的长度、输出序列的长度
- T x ( i ) T_x^{(i)} Tx(i):第 i i i个样本的输入序列长度
如何表达句子中的各类单词呢?
做一张词汇表,在用one-hot编码表示,如下图:

每一个单词都使用 10000 × 1 10000\times1 10000×1的one-hot表示,当出现词汇表之外的单词,可以使用UNK或其他字符串来表示。
上述问题就成为从一组one-hot编码 X X X映射到 Y Y Y的监督学习问题。
三、循环神经网络
如何建立模型实现 X X X到 Y Y Y的映射呢?
可以使用标注的神经网络来解决,但存在三个问题:

- 首先对于命名体识别例子来说,输入和输出的数量是不固定的;虽可以使用零填充使每个输入句子都达到最大长度,但是效果并不好。
- 其次,一个像这样单纯的神经网络结构,它并不共享从文本的不同位置上学到的特征。即,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如 x < t > x^{
} x<t> 时,它也能够自动识别其为人名的一部分的话,这就很棒了。
我们可以使用循环神经网络(RNN)来解决序列模型问题。结果构图如下:

注意上图是逻辑结构上的展开,实际展开如下图所示:

- 每一次输入都代表一个
时间步,黑色块表示滞后一个时间步;即当前循环输入结束,黑色块的输出才会用于下一次循环。在0时刻需要构造一个激活值 a < 0 > a^{<0>} a<0>,通常是零向量。
RNN从左到右,依次传递,因此第 < t >
对于RNN中的权重表示如下图所示:

- 不同元素位置的 W y a 、 W a a 、 W a x W_{ya}、W_{aa}、W_{ax} Wya、Waa、Wax表示了不同时间步下的权重矩阵;即只存在三个矩阵,不同时间步下数值会不同。
前向传播:
a < 1 > = g 1 ( W a a ⋅ a < 0 > + W a x ⋅ x < 1 > + b a ) a^{<1>}=g_1(W_{aa}\cdot a^{<0>}+W_{ax}\cdot x^{<1>}+b_a) a<1>=g1(Waa⋅a<0>+Wax⋅x<1>+ba)
y ^ < 1 > = g 2 ( W y a ⋅ a < 1 > + b y ) \hat{y}^{<1>}=g_2(W_{ya}\cdot a^{<1>}+b_y) y^<1>=g2(Wya⋅a<1>+by)
总结为:
a < t > = g 1 ( W a a ⋅ a < t − 1 > + W a x ⋅ x < t > + b a ) a^{
y ^ < t > = g 2 ( W y a ⋅ a < t > + b y ) \hat{y}^{
循环神经网络的激活函数通常使用 t a n h tanh tanh,有时会使用 R e L U ReLU ReLU。对于输出的 y y y,激活函数根据问题性质选择 s o f t m a x softmax softmax或者 s i g m o i d sigmoid sigmoid。
看上述公式:
W a x W_{ax} Wax中 a x ax ax的: a a a在左边表示这是要计算 a a a的; x x x在右边表示右边要乘于 x x x
其余同理
简化表达前向传播:
W a a ⋅ a < t − 1 > + W a x ⋅ x < t > = [ W a a W a x ] ⋅ [ a < t − 1 > x < t > ] → W a ⋅ [ a < t − 1 > x < t > ] W_{aa}\cdot a^{
因此公式简化为:
a < t > = g 1 ( W a ⋅ [ a < t − 1 > , x < t > ] + b a ) a^{
y ^ < t > = g 2 ( W y ⋅ a < t > + b y ) \hat{y}^{
- RNN存在的问题是,没有使用后面元素带来的信息,如下图的句子是需要后面的信息来确定Teddy是否是名字的。后面的BRNN会解决这个问题。

四、穿越时间的反向传播
输出的 y ^ \hat{y} y^表示为是名字的概率,对于结果只有0或者1,所以可以使用交叉熵的形式来表示损失函数:
L < t > ( y ^ < t > , y < t > ) = − y < t > ⋅ l o g y ^ < t > − ( 1 − y < t > ) ⋅ l o g ( 1 − y ^ < t > ) L^{
总元素的损失函数为:
L ( y ^ , y ) = ∑ t = 1 T y L < t > ( y ^ < t > , y < t > ) L(\hat{y},y)=\sum\limits_{t=1}^{T_y} {L^{
反向传播过程如下图的红色箭头所示,最关键的是中间 a a a的反向传播,这个传播从右至左像穿越到过去去梯度下降一样,因此被叫做穿越时间的反向传播。

五、不同类型的循环神经网络
-
o n e t o o n e one\ to \ one one to one,即 T x = T y T_x=T_y Tx=Ty:
一对一不使用RNN,就是一个标注的神经网络

-
o n e t o m a n y one\ to \ many one to many,即 T x = 1 , T x < T y T_x=1,T_x<T_y Tx=1,Tx<Ty:
额外的将输出送到下一个时间步【音乐生成】

-
M a n y t o o n e Many \ to \ one Many to one,即 T y = 1 , T x 大于 T y T_y=1,T_x大于T_y Ty=1,Tx大于Ty:
【情感分类】
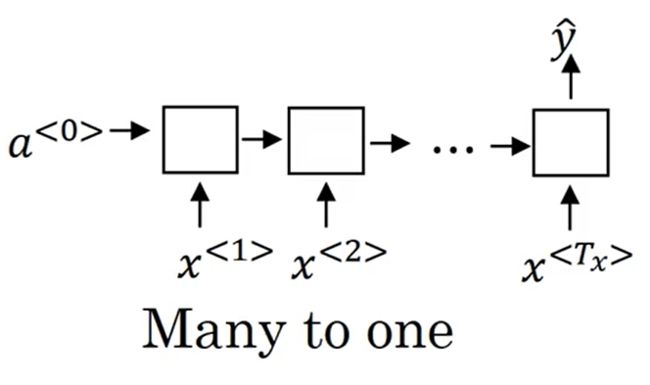
-
M a n y t o m a n y Many \ to \ many Many to many,即 T x = T y T_x=T_y Tx=Ty:
【DNA序列分析】
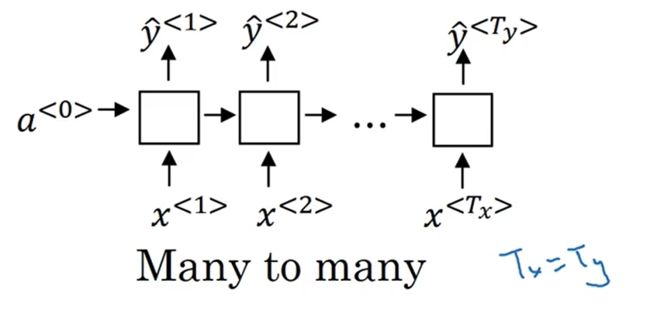
-
M a n y t o m a n y Many \ to \ many Many to many,即 T y ! = T y T_y!=T_y Ty!=Ty:
此时RNN分成两个部分,没有输出的前半部分称为编码器,获取输入,比如法语句子;有输出的后半部分是解码器,它会读取整个句子,然后输出翻译成其他语言的结果。【机器翻译】

六、语言模型和序列生成
- 什么是语言模型呢?
例如在语音识别系统中,听到一个句子可能有两种翻译:
“ t h e a p p l e a n d p e a r s a l a d w a s d e l i c i o u s the\ apple\ and\ pear \ salad\ was \ delicious the apple and pear salad was delicious”。
“ t h e a p p l e a n d p a i r s a l a d w a s d e l i c i o u s the\ apple\ and\ pair \ salad\ was \ delicious the apple and pair salad was delicious”。
那么到底是pear还是pair呢?这两个单词读音上很类似,很明显pear在语义上更为合理,语音系统应该选择第一句。这时候就需要语言模型去计算这两句话各自出现的概率,比如第一句话的概率是10-10,第二句话的概率是10-13,从而选择概率较大的第二句话。
所以语言模型所做的就是:给出某个特定的句子的出现概率是多少。
如何构建一个语言模型呢?
首先我们需要一个训练集,包含很多英语文本的语料库(数量众多的英文句子组成的文本)。然后对语料库的每句话进行分词并建立vocabulary,对每个单词进行one-hot编码。
可以添加两个编码
The Egyptian Mau is a bread of cat.
加上
The Egyptian
训练集准备好后,就开始构建相应的RNN模型:
精髓在于 x < t > = y < t − 1 > x^{

假设我们想要得到句子:
Cats average 15 hours of sleep a day.
出现的概率,即想要计算概率 P ( y < 1 > , y < 2 > , … , y < T y > ) = ? P(y^{<1>},y^{<2>},…,y^{
- RNN模型首先会输入两个0向量 a < 0 > a^{<0>} a<0>和 x < 1 > x^{<1>} x<1>,经过softmax函数后的输出 y ^ < 1 > \hat{y}^{<1>} y^<1>表示任一单词出现的概率,在这个句子中主要关注的是单词Cats,即概率 P ( C a t s ) P(Cats) P(Cats)。
- 下一个时间步, x < 2 > = y < 1 > x^{<2>}=y^{<1>} x<2>=y<1>,即将第一个词Cats作为输入,告诉RNN第一个单词是Cats;经过softmax后的输出 y ^ < 2 > \hat{y}^{<2>} y^<2>表示的是第一个单词是Cats的情况下,第二个单词是任一单词的概率,这里只关注average,即 P ( a v e r a g e ∣ C a t s ) P(average|Cats) P(average∣Cats)。
- 以此类推,最后一个时间步 x < T x > = y < T x − 1 > x^{
}=y^{ x<Tx>=y<Tx−1>,输出的是P(|Cats average 15 hours of sleep a day)的概率值。
最后这个句子出现的的概率值等于所有输出 y ^ < 1 > − y ^ < T y > \hat{y}^{<1>}-\hat{y}^{
因为 P ( y < 1 > , y < 2 > , y < 3 > ) = P ( y < 1 > ) ∗ P ( y < 1 > ∣ y < 2 > ) ∗ P ( y < 1 > ∣ y < 2 > , y < 3 > ) P(y^{<1>},y^{<2>},y^{<3>})=P(y^{<1>})*P(y^{<1>}|y^{<2>})*P(y^{<1>}|y^{<2>},y^{<3>}) P(y<1>,y<2>,y<3>)=P(y<1>)∗P(y<1>∣y<2>)∗P(y<1>∣y<2>,y<3>)
单个单词(第t个时间步)的损失函数定义为:
L ( y ^ < t > , y < t > ) = − ∑ i y i < t > ⋅ l o g y ^ i < t > L(\hat{y}^{
整个句子的损失函数为:
L = ∑ t L < t > ( y ^ < t > , y < t > ) L=\sum\limits_{t}L^{
y ^ < t > \hat{y}^{
} y^<t>和 y < t > y^{} y<t>都是与one-hot编码相同维度的向量,损失函数的i表示的是这个向量的第i个元素。
七、新序列采样
当语言模型RNN训练好后,可以进行新的序列采样,从而随机产生新的语句。
首先先来了解一下numpy.random.choice():
这个函数用于对一维数组进行随机抽取元素
numpy.random.choice(a, size=None, replace=True, p=None)
- a:从a数组中抽取元素
size:抽取元素的个数,最后形成size大小的数组
replace:是否可以取相同的元素
p:与a数组相同维度,表示取数组a中每个元素的概率
产生新语句的流程:
- 先输出 a < 0 > 、 x 1 a^{<0>}、x^{1} a<0>、x1得到输出 y ^ < 1 > \hat{y}^{<1>} y^<1>,然后将 y ^ < 1 > \hat{y}^{<1>} y^<1>作为numpy.random.choice()的参数p随机抽取一个单词作为这个新语句的开头。(得到第一个单词)
- 当遇到
的时候我们可以重新采样。 - 将第一个时间步的输出 y ^ < 1 > \hat{y}^{<1>} y^<1>作为第二个时间步的输入得到 y ^ < 2 > \hat{y}^{<2>} y^<2>,将 y ^ < 2 > \hat{y}^{<2>} y^<2>作为numpy.random.choice()的参数p随机抽取一个单词,作为新句子的第二个单词。
- 以此类推,我们可以得到很多的单词组成一个新的句子。
- 可以规定得到
或者限定新句子长度(规定时间步长度)来停止无止境的新单词生成。

之前介绍的都是以单词为基本单位的的RNN(word level RNN)。另外一种情况是character level RNN,即词汇表由单个英文字母组成。
character level RNN的优点是不存在
八、RNN神经网络的梯度消失
看下面两句话:
The c a t \color{blue}{cat} cat, which already ate fish……, w a s \color{blue}{was} was full.
The c a t s \color{blue}{cats} cats, which already ate fish……, w e r e \color{blue}{were} were full.
后面的were、was对前面的cats、cat有较强的依赖关系,这两个单词之间隔了很多个单词,就像一个深层神经网络,后面的单词是很难参考到前面的单词的;一般RNN模型各元素受附近的前几个元素影响较大,难以建立跨度较大的依赖性。
并且这种跨度很大的依赖关系,普通的RNN网络会出现梯度消失或者梯度爆炸,从而捕捉不到这个依赖关系。
梯度消失是训练RNN时首要的问题,尽管梯度爆炸也会出现,但是梯度爆炸很明显,因为指数级大的梯度会让你的参数变得极其大,以至于你的网络参数崩溃,你会看到很多NaN,或者不是数字的情况,这意味着你的网络计算出现了数值溢出。
如果发现了梯度爆炸的问题,一个解决方法就是用梯度修剪(gradient clipping):设定一个阈值,一旦梯度最大值达到这个阈值,就对整个梯度向量进行尺度缩小。
梯度爆炸可以使用gradient clipping来解决,但是梯度消失就很棘手了。
九、GRU单元(门控循环单元)
参考博文:红色石头Will
RNN隐藏单元结构:

其中 a < t > = t a n h ( W a [ a < t − 1 > , x < t > ] + b a ) a^{
GRU和RNN结构上很相似,结构如下图:

相比RNN添加了记忆细胞 c < t > c^{
它们的具体公式如下:
- c ~ < t > = t a n h ( W c [ c < t − 1 > , x < t > ] + b c ) \tilde{c}^{
}=tanh(W_c[c^{ c~<t>=tanh(Wc[c<t−1>,x<t>]+bc)}]+b_c) - Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) Γ_u=σ(W_u[c^{
}]+b_u) - c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > c^{
}=Γ_u*\tilde{c}^{ c<t>=Γu∗c~<t>+(1−Γu)∗c<t−1>}+(1-Γ_u)*c^{ }
【注意,以上表达式中的∗表示元素相乘,而非矩阵相乘。】
下面为个人理解:
- 看1公式, c ~ < t > \tilde{c}^{
} c~<t>和普通RNN一样,只是 a a a换成了 c c c。 c < t > c^{} c<t>是 a < t > a^{} a<t>的升级版。 - 第2个公式,根据当前输入和前层传过来的记忆细胞来决定是否更改当前记忆细胞的值。
- 第3个公式,当 Γ u Γ_u Γu=0, c < t > c^{
} c<t>更新为 c ~ < t − 1 > \tilde{c}^{} c~<t−1>;当 Γ u Γ_u Γu=1, c < t > c^{} c<t>不更新。所以 c < t > c^{} c<t>的值是可以一直不变的传下去的,这就是所谓的记忆功能。
再看之前的那句话:
The c a t \color{blue}{cat} cat, which already ate fish……, w a s \color{blue}{was} was full.
【为了方便理解,极端的想象 Γ u Γ_u Γu=1或1】
可以在 c a t \color{blue}{cat} cat的时候更新记忆细胞( Γ u Γ_u Γu=1),之后在不做改动的传递 c < t > c^{
c < t > c^{
上面介绍的是GRU的简化版本,完整的GRU添加了新的参数 Γ r Γ_r Γr,表达式如下:
c ~ < t > = t a n h ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c ) \tilde{c}^{
Γ u = σ ( W u [ c < t − 1 > , x < t > ] + b u ) Γ_u=σ(W_u[c^{
Γ r = σ ( W r [ c < t − 1 > , x < t > ] + b r ) Γ_r=σ(W_r[c^{
c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > c^{
【 Γ r Γ_r Γr表示下一个 c ~ < t > \tilde{c}^{
某些地方将 c ~ < t > \tilde{c}^{
} c~<t>称为 h ~ \tilde{h} h~, Γ u Γ_u Γu称为 u u u, Γ r Γ_r Γr称为 r r r, c < t > c^{} c<t>称为 h h h
十、长短期记忆(LSTM)
LSTM是更加强大的解决梯度消失的方法。对应RNN隐藏层单元结构如下图所示:

相比之前的GRU多添加了几个门 ( Γ ) (Γ) (Γ),公式如下:
c ~ < t > = t a n h ( W c [ a < t − 1 > , x < t > ] + b c ) \tilde{c}^{
Γ u = σ ( W u [ a < t − 1 > , x < t > ] + b u ) Γ_u=σ(W_u[a^{
Γ f = σ ( W f [ a < t − 1 > , x < t > ] + b f ) Γ_f=σ(W_f[a^{
Γ o = σ ( W o [ a < t − 1 > , x < t > ] + b o ) Γ_o=σ(W_o[a^{
c < t > = Γ u ∗ c ~ < t > + Γ f ∗ c < t − 1 > c^{
a < t > = Γ o ∗ c < t > a^{
- update gate(更新门): Γ u Γ_u Γu
- forget gate(遗忘门): Γ f Γ_f Γf
- output gate(输出没): Γ o Γ_o Γo
也可以将 c < t − 1 > c^{
则公式变成:
c ~ < t > = t a n h ( W c [ a < t − 1 > , x < t > ] + b c ) \tilde{c}^{
Γ u = σ ( W u [ a < t − 1 > , x < t > , c < t − 1 > ] + b u ) Γ_u=σ(W_u[a^{
Γ f = σ ( W f [ a < t − 1 > , x < t > , c < t − 1 > ] + b f ) Γ_f=σ(W_f[a^{
Γ o = σ ( W o [ a < t − 1 > , x < t > , c < t − 1 > ] + b o ) Γ_o=σ(W_o[a^{
c < t > = Γ u ∗ c ~ < t > + Γ f ∗ c < t − 1 > c^{
a < t > = Γ o ∗ c < t > a^{
将LSTM不同时间步罗列在一起如下图所示,图中的条线体现了只要你正确地设置了遗忘门和更新门,LSTM是可以把的 c < 0 > c^{<0>} c<0>值一直往下传递到最右边的,也就是记忆功能。

GRU只有两个门,需要的参数比LSTM少,鲁棒性比LSTM好,不容易过拟合。GRU基本精神时旧的不去,新的不来,GRU会把input gate和forget gate连起来,当forget gate把memory里的值清空时,input gate才会打开,再放入新的值
十一、双向RNN(Bidirectional BNN,BRNN)
参考博文:红色石头Will
BRNN结构图如下所示,紫色的表示前向的传播,绿色表示的是反向的传播。

输出表达式为:
y ^ < t > = g ( W y [ a → < t > , a ← < t > ] + b y ) \hat{y}^{
BRNN当前的输出需要考虑过去和未来的信息,上图的方框可以使用GRU或者LSTM单元。
BRNN缺点:
需要完整的数据的序列,你才能预测任意位置。比如要构建一个语音识别系统,那么双向RNN模型需要考虑整个语音表达,则需要等待这个人说完,然后获取整个语音表达才能处理这段语音,并进一步做语音识别。
十二、深层循环神经网络
Deep RNN结构如下图所示,由多层RNN组成。

其中 a [ l ] < t > = g ( W a [ l ] [ a [ l ] < t − 1 > , a [ l − 1 ] < t > ] + b a [ l ] ) a^{[l]
a [ l ] < t > a^{[l]
} a[l]<t>表示第l层的第t个时间步
一般Deep RNN没有像之前神经网络那样动不动就上百层,3层RNNs已经较复杂了。上面的方格可以使用普通的RNN单元、GRU单元或者LSTM单元。
此外还可以在输出 y ^ [ t ] \hat{y}^{[t]} y^[t]上做文章,如输出再连接一个神经网络,如下图所示:

十三、RNN为什么要使用Clipping?
RNN网络在一段时间内都不能被训练出来,因为缺少了clipping操作。
因为 T h e e r r o r s u r f a c e i s r o u g h . The\ error\ surface\ is\ rough. The error surface is rough.如下图,我们希望在训练时能够碰到平滑下降的蓝色曲线,但是在RNN种大部分情况碰到的都是陡峭的绿色曲线。

以下面的RNN结构为例子,

- 当 w w w=1时, y 1000 = 1 y^{1000}=1 y1000=1;这时候将 w w w扩大一点, w = 1.01 w=1.01 w=1.01, y 1000 ≈ 2000 y^{1000}≈2000 y1000≈2000;此时 ∂ L ∕ ∂ w ∂L∕∂w ∂L∕∂w非常的大,那么我们需要用很小的学习率去更新。
- 当 w w w=0.99时, y 1000 ≈ 0 y^{1000}≈0 y1000≈0;这时候将 w w w大幅度缩小, w = 0.01 w=0.01 w=0.01, y 1000 ≈ 0 y^{1000}≈0 y1000≈0,输出基本没有变化;此时 ∂ L ∕ ∂ w ∂L∕∂w ∂L∕∂w非常的小,那么我们需要用很大的学习率去更新。
- 梯度时大时小, e r r o r s u r f a c e error\ surface error surface很崎岖,很难用 l e a r n i n g r a t e learning\ rate learning rate去调整梯度。
综上,当 w w w值比较接近时, l o s s loss loss的值也会有很大的不同。损失函数图像可能如下图所示,可以看到图像要么非常的平坦(上面图中 w < 1 w<1 w<1的情况),要么非常的陡峭(上面图中 w > 1 w>1 w>1的情况)。
- 如果梯度下降刚好落到悬崖边上,梯度值就会大的离谱,更新后的参数值就会像下图的飞机一样飞了出去。
- 当梯度下降落到平坦的地方上,很容易会停滞不前。

想要解决这个梯度爆炸的问题,需要Clipping方法:先设置一个阈值( t h r e s h o l d threshold threshold),当梯度大于 t h r e s h o l d threshold threshold时,就让梯度等于 t h r e s h o l d threshold threshold即可。
使用clipping和未使用clipping的差异如下图所示:

十四、解决梯度消失
解决梯度消失, L S T M LSTM LSTM就是最广泛使用的技巧,它会把 e r r o r s u r f a c e error\ surface error surface上那些比较平坦的地方拿掉。
普通的RNN网络,如下图,就像一个一直在记忆的人,记忆过的东西都会不保留的带入到下一时刻,信息量就会越来越多( w w w的累乘)。
L S T M LSTM LSTM比上图的 R N N RNN RNN多了一个遗忘功能,想记就记(可以消除 w w w累乘带来的影响),不想记就忘,也可以有所保留的记忆。
所以LSTM能解决梯度消失的原因在于对memory的处理其实是不一样的:
- RNN中,每个新的时间点,memory里的旧值都会被新值所覆盖
- LSTM中,每个新的时间点,memory里的值会乘上遗忘门(变成累加保留的方式了)。