(系列笔记)13.SVR模型
SVR——一种“宽容的回归模型”
严格的线性回归
线性回归:在向量空间里用线性函数去拟合样本。该模型以所有样本实际位置到该线性函数的综合距离为损失,通过最小化损失来求取线性函数的参数。对于线性回归而言,一个样本只要不算正好落在作为模型的线性函数上,就要被计算损失。
宽容的支持向量回归(SVR)
介绍一种“宽容的”回归模型:支持向量回归(Support Vector Regression,SVR)
模型函数
支持向量回归模型的模型函数也是一个线性函数: y = w x + b y=wx+b y=wx+b,但是和线性回归是两个不同的回归模型!
不同点在于:计算损失的原则不同,目标函数和最优化算法也不同。
原理
SVR在线性函数两侧制造了一个“间隔带”,对于所有落入到间隔带内的样本,都不计算损失;只有间隔带之外的,才计入损失函数。之后再通过最小化间隔带的宽度与总损失来最优化模型。如下图这样,只有那些圈了红圈的样本(或在隔离带边缘之外,或落在隔离带边缘上),才被计入最后的损失:
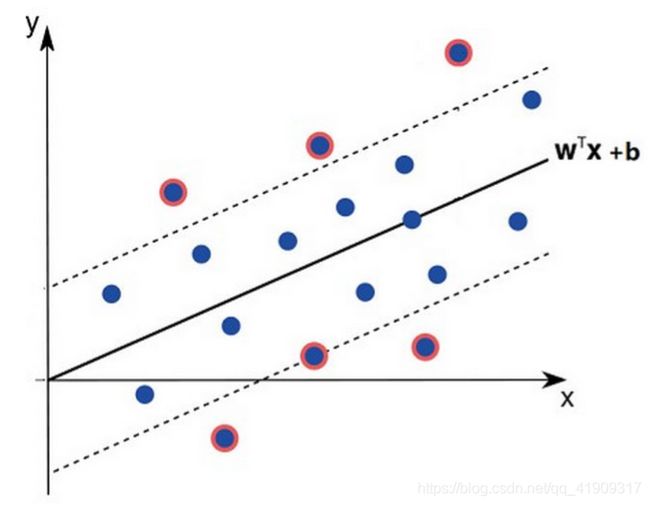
SVR的两个松弛变量
有一点和SVM是正好相反的:SVR希望样本点都落在“隔离带”内,而SVM希望样本点都在“隔离带”外。这导致SVR要同时引入两个松弛变量: ξ \xi ξ和 ξ ∗ \xi^* ξ∗
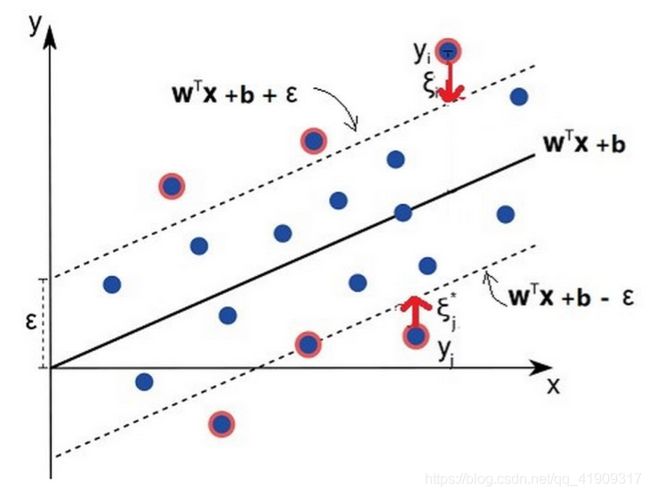
上图显示了SVR的基本情况:
- f ( x ) = w x + b f(x)=wx+b f(x)=wx+b是我们最终要求得的模型函数;
- w x + b + ϵ wx+b+\epsilon wx+b+ϵ w x + b − ϵ wx+b-\epsilon wx+b−ϵ(也就是 f ( x ) + ϵ f(x)+\epsilon f(x)+ϵ和 f ( x ) − ϵ f(x)-\epsilon f(x)−ϵ)是隔离带的上下边缘;
- ξ ∗ \xi^* ξ∗是隔离带下边缘之下样本点,到隔离带下边缘上的投影,与该样本点 y y y值的差。
公式表述:
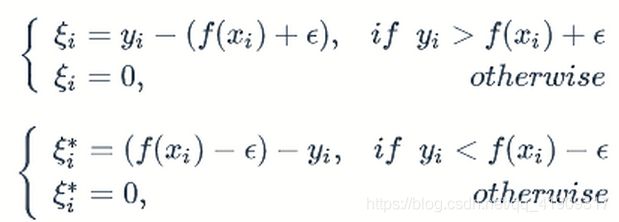
对于任意样本 x i x_i xi,如果它在隔离带里面或者隔离带边缘上,则 ξ \xi ξ和 ξ ∗ \xi^* ξ∗都为0;如果它在隔离带上边缘上方,则 ξ > 0 \xi>0 ξ>0 , ξ ∗ \xi^* ξ∗=0;如果它在隔离带下边缘下方,则 ξ = 0 \xi=0 ξ=0 , ξ ∗ 0 \xi^*0 ξ∗0;
SVR的主问题和对偶问题
SVR主问题的数学描述
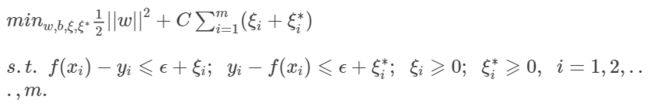
SVR的拉格朗日函数和对偶问题
我们针对上述主问题引入拉格朗日乘子:
![]()
构建拉格朗日函数:
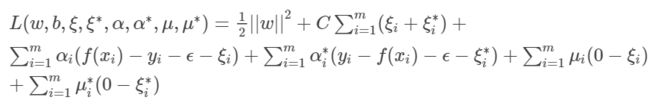
它对应的对偶问题是:
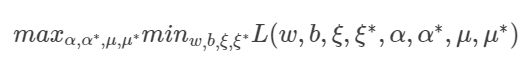
求解SVR对偶问题
按照前面讲的方法,首先要求最小化部分:
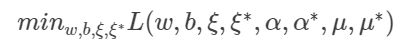
然后分别对 w , b , ξ i , ξ i ∗ w,b,\xi_i,\xi_i^* w,b,ξi,ξi∗求偏导,并令偏导为0:
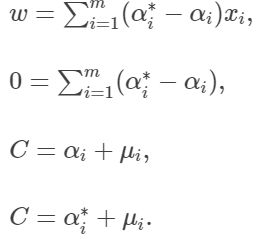
用SMO算法求解SVR
使用SMO算法前,还需将 α i \alpha_i αi和 α i ∗ \alpha_i^* αi∗转化为一个参数,因为SMO算法针对的是任意样本 x i x_i xi只对应一个参数 α i \alpha_i αi的情况。
过程采用拉格朗日对偶法,对偶问题有解的充要条件是满足KKT条件,对于SVR的对偶问题,其KKT条件如下:

由KKT条件可见,当且仅当 f ( x i ) − y i − ϵ − ξ i = 0 f(x_i)-y_i-\epsilon-\xi_i=0 f(xi)−yi−ϵ−ξi=0时, α i \alpha_i αi才可以取非0值,当且仅当
y i − f ( x i ) − ϵ − ξ i ∗ = 0 y_i-f(x_i)-\epsilon-\xi_i^*=0 yi−f(xi)−ϵ−ξi∗=0, α i ∗ \alpha_i^* αi∗才可以取非0值。
f ( x i ) − y i − ϵ − ξ i = 0 = > y i = f ( x i ) − ϵ − ξ i f(x_i)-y_i-\epsilon-\xi_i=0=>y_i=f(x_i)-\epsilon-\xi_i f(xi)−yi−ϵ−ξi=0=>yi=f(xi)−ϵ−ξi对应的是在隔离带下边缘以下的样本;
y i − f ( x i ) − ϵ − ξ i ∗ = 0 = > y i = f ( x i ) + ϵ + ξ i ∗ y_i-f(x_i)-\epsilon-\xi_i^*=0=>y_i=f(x_i)+\epsilon+\xi_i^* yi−f(xi)−ϵ−ξi∗=0=>yi=f(xi)+ϵ+ξi∗对应的是在隔离带上边缘以上的样本。
一个样本不可能同时在上边缘上和上边缘下,所以这两个等式只有体格而成立,所以相应的 α i \alpha_i αi和 α i ∗ \alpha_i^* αi∗中至少有一个为0。
假设: λ i = α i − α i ∗ \lambda_i=\alpha_i-\alpha_i^* λi=αi−αi∗
既然 α i \alpha_i αi和 α i ∗ \alpha_i^* αi∗中至少有一个为0,且 0 < = α i , α i ∗ , < = C 0<=\alpha_i,\alpha_i^*,<=C 0<=αi,αi∗,<=C,于是: ∣ λ i ∣ = α i + α i ∗ |\lambda_i|=\alpha_i+\alpha_i^* ∣λi∣=αi+αi∗
将 λ i \lambda_i λi和 ∣ λ i ∣ |\lambda_i| ∣λi∣代入对偶问题,则有:
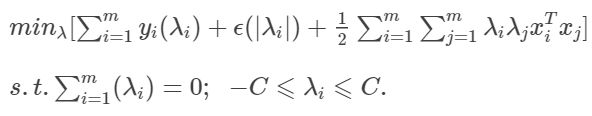
如此一来,即可以用SMO求解了(这个推导过程仅仅用于说明SMO也可以应用于SVR,具体的求解过程和SVM的SMO算法还是有所差异的)
支持向量与求解线性模型参数
因为 f ( x ) = w x + b f(x)=wx+b f(x)=wx+b,以及前面求出的 w = ∑ i = 1 m ( α i ∗ − α i ) x i w=\sum_{i=1}^{m}{(\alpha_i^*-\alpha_i)x_i} w=∑i=1m(αi∗−αi)xi,因此:

由此可见,只有满足 α i ∗ − α i = ̸ 0 \alpha_i^*-\alpha_i=\not 0 αi∗−αi≠0的样本才对 w w w取值有意义,才是SVR的支持向量。也就上,当样本满足下列条件之一时,才是支持向量:

换言之,这个样本要么在隔离带上边缘以上,要么在隔离带下边缘以下(含两个边缘本身),也就是说,落在 ϵ − \epsilon- ϵ−隔离带之外的样本,才是SVR的支持向量。
可见,无论是SVM还是SVR,它们的解都仅限于支持向量,即只是全部训练样本的一部分,因此SVM和SVR的解都具有稀疏性。
通过最优化方法求解出了 w w w之后,我们还需要求b。
f ( x i ) = w x i + b = > b = f ( x i ) − w x i f(x_i)=wx_i+b=>b=f(x_i)-wx_i f(xi)=wxi+b=>b=f(xi)−wxi,而且对于那些落在隔离带边缘上的支持向量,有 f ( x i ) = y i + ϵ f(x_i)=y_i+\epsilon f(xi)=yi+ϵ,落在隔离带下边缘上的支持变量有 f ( x i ) = y i − ϵ f(x_i)=y_i-\epsilon f(xi)=yi−ϵ。因此,
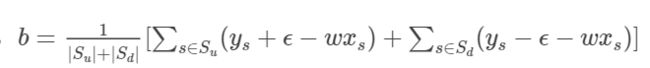
其中 S u S_u Su是位于隔离带上边缘的支持向量集合,而 S d S_d Sd则是位于隔离带下边缘的支持向量集合。
SVR的核技巧
前面讲过的适用于SVM的核技巧也同样适用于SVR。SVR 核技巧的实施办法和 SVM 一样,也是将输入空间的 x x x通过映射函数 ϕ ( x ) \phi(x) ϕ(x)映射到更高维度的特征空间,然后再在特征空间内做本文前述的一系列操作。
因此,在特征空间中的线性模型为: f ( x ) = w ϕ ( x ) + b f(x)=w\phi(x)+b f(x)=wϕ(x)+b
其中:

对照SVM核函数的做法,我们也令:
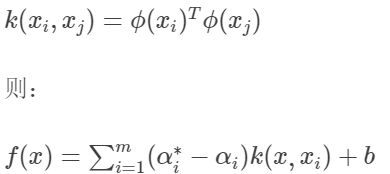
具体核技巧的实施过程,对照SVM即可。