支持向量回归(Support Vector Regression)
支持向量回归(Support Vector Regression)
文章目录
- 支持向量回归(Support Vector Regression)
-
- 带松弛变量的SVR
- 带松弛变量的SVR目标函数的优化
- SVM回归模型的支持向量
- SVR的算法过程
- 带松弛变量的SVR的一种解释: ε \varepsilon ε不敏感损失+L2正则
-
- ε \varepsilon ε不敏感损失( ε \varepsilon ε-insensitive loss)
- 带松弛变量的SVR的一种解释
- 总结
支持向量机除了能够分类,还可以用于回归。
回归的目的是得到一个能够尽量拟合训练集样本的模型 f ( x ) f(\mathbf{x}) f(x),通常用的方法是构建一个样本标签与模型预测值的损失函数,使损失函数最小化从而确定模型 f ( x ) f(\mathbf{x}) f(x)。

例如,在线性回归模型中,损失函数(L2损失,L1损失,huber损失)由模型输出 f ( x ) f(\mathbf{x}) f(x)与真实输出 y y y之间的差别来计算,通过最小化损失函数来确定模型 f ( x ) f(\mathbf{x}) f(x),当且仅当 f ( x ) f(\mathbf{x}) f(x)与 y y y完全相等时,损失才为0。
那支持向量机是如何用于回归的呢?
支持向量机的精髓在于间隔最大化。
- 在分类任务中,使靠超平面最近的样本点之间的间隔最大;

- 而在回归任务中,同样也是间隔最大,不同的是它使靠超平面最远的样本点之间的间隔最大。

如果使靠超平面最远的样本点之间的间隔最大,那么上图样本点的回归超平面结果就应该变成下左图那样。

显然,我们希望回归能达到右图的效果,于是SVR对间隔加了限制,对所有的样本点,回归模型 f ( x ) f(\mathbf{x}) f(x)与 y y y的偏差必须 ≤ ε \le \varepsilon ≤ε。我们把这个偏差范围称作 ε \varepsilon ε管道。
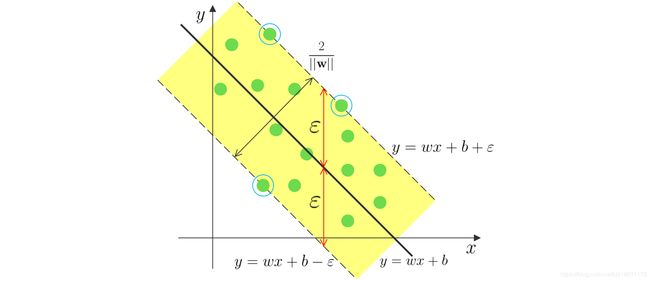
依据以上的思路,SVR的优化问题可以用数学式表示为
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 2 s . t . ∣ y i − ( w T x i + b ) ∣ ≤ ε , i = 1 , 2 , ⋯ , N \begin{aligned} &\min_{\mathbf{w},b} \frac{1}{2} ||\mathbf{w}||_2^2 \\ s.t. \quad |y_i - (\mathbf{w}^T &\mathbf{x}_i + b)| \le \varepsilon, \quad i = 1,2,\cdots,N \end{aligned} s.t.∣yi−(wTw,bmin21∣∣w∣∣22xi+b)∣≤ε,i=1,2,⋯,N
SVR的目的是:保证所有样本点在 ε \varepsilon ε管道内的前提下,回归超平面 f ( x ) f(\mathbf{x}) f(x)尽可能地平。

在 ε \varepsilon ε不变的前提下,回归超平面 f ( x ) f(\mathbf{x}) f(x)尽可能平和间隔尽可能大是等效的。
带松弛变量的SVR
实际应用中, ε \varepsilon ε设置太小无法保证所有样本点都在 ε \varepsilon ε管道内, ε \varepsilon ε太大回归超平面会被一些异常点带偏。
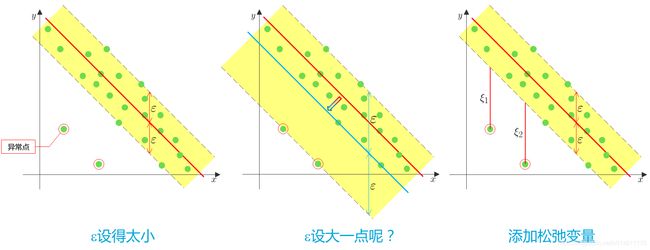
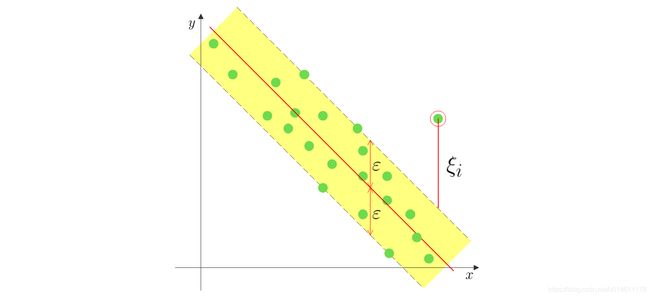
和软间隔SVM模型类似,SVR允许每个样本 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)添加松弛变量 ξ i ≥ 0 \xi_i \ge 0 ξi≥0,用来描述样本点偏离 ε \varepsilon ε管道的程度。
如何添加松弛变量?
如果直接在约束条件中加上松弛变量,变成 ∣ y i − ( w T x i + b ) ∣ ≤ ε + ξ i |y_i - (\mathbf{w}^T \mathbf{x}_i + b)| \le \varepsilon + \xi_i ∣yi−(wTxi+b)∣≤ε+ξi,即
{ y i − ( w T x i + b ) ≤ ε + ξ i 上 界 约 束 ( w T x i + b ) − y i ≤ ε + ξ i 下 界 约 束 \left\{ \begin{aligned} y_i - (\mathbf{w}^T \mathbf{x}_i + b) &\le \varepsilon + \xi_i \quad 上界约束 \\ (\mathbf{w}^T \mathbf{x}_i + b) - y_i &\le \varepsilon + \xi_i \quad 下界约束 \end{aligned} \right. {yi−(wTxi+b)(wTxi+b)−yi≤ε+ξi上界约束≤ε+ξi下界约束
显然,超出间隔上界的样本点影响到了下界面的约束。
那么是否可以对超出不同界面的样本点分开添加松弛变量?
比如:样本点超出间隔上界,我们令
{ y i − ( w T x i + b ) ≤ ε + ξ i 上 界 约 束 ( w T x i + b ) − y i ≤ ε 下 界 约 束 \left\{ \begin{aligned} y_i - (\mathbf{w}^T \mathbf{x}_i + b) &\le \varepsilon + \xi_i \quad 上界约束 \\ (\mathbf{w}^T \mathbf{x}_i + b) - y_i &\le \varepsilon \quad 下界约束 \end{aligned} \right. {yi−(wTxi+b)(wTxi+b)−yi≤ε+ξi上界约束≤ε下界约束
超出间隔下界,令
{ y i − ( w T x i + b ) ≤ ε 上 界 约 束 ( w T x i + b ) − y i ≤ ε + ξ i 下 界 约 束 \left\{ \begin{aligned} y_i - (\mathbf{w}^T \mathbf{x}_i + b) &\le \varepsilon \quad 上界约束 \\ (\mathbf{w}^T \mathbf{x}_i + b) - y_i &\le \varepsilon + \xi_i \quad 下界约束 \end{aligned} \right. {yi−(wTxi+b)(wTxi+b)−yi≤ε上界约束≤ε+ξi下界约束
但是事先不知道样本点超出的是上界还是下界,因此也不可行,而且超出上界和超出下界的约束条件形式还不相同。
其实,上下界的松弛变量可以用不同符号来表示: ξ i ⋀ ≥ 0 , ξ i ⋁ ≥ 0 \xi_i^{\bigwedge} \ge 0,\xi_i^{\bigvee} \ge 0 ξi⋀≥0,ξi⋁≥0,约束条件变成
{ y i − ( w T x i + b ) ≤ ε + ξ i ⋀ 上 界 约 束 ( w T x i + b ) − y i ≤ ε + ξ i ⋁ 下 界 约 束 \left\{ \begin{aligned} y_i - (\mathbf{w}^T \mathbf{x}_i + b) &\le \varepsilon + \xi_i^{\bigwedge} \quad 上界约束 \\ (\mathbf{w}^T \mathbf{x}_i + b) - y_i &\le \varepsilon + \xi_i^{\bigvee} \quad 下界约束 \end{aligned} \right. ⎩⎨⎧yi−(wTxi+b)(wTxi+b)−yi≤ε+ξi⋀上界约束≤ε+ξi⋁下界约束
当 ξ i ⋀ ≠ 0 , ξ i ⋁ = 0 \xi_i^{\bigwedge} \ne 0,\xi_i^{\bigvee} = 0 ξi⋀=0,ξi⋁=0时,样本点超出上界;
当 ξ i ⋀ = 0 , ξ i ⋁ ≠ 0 \xi_i^{\bigwedge} = 0,\xi_i^{\bigvee} \ne 0 ξi⋀=0,ξi⋁=0时,样本点超出下界;
当 ξ i ⋀ = 0 , ξ i ⋁ = 0 \xi_i^{\bigwedge} = 0,\xi_i^{\bigvee} = 0 ξi⋀=0,ξi⋁=0时,样本点在 ε \varepsilon ε通道内。
ξ i ⋀ ≠ 0 , ξ i ⋁ ≠ 0 \xi_i^{\bigwedge} \ne 0, \xi_i^{\bigvee} \ne 0 ξi⋀=0,ξi⋁=0这种情况不可能出现,因为这表示样本点既超出上界又超出下界,明显不可能发生。
引入松弛变量,SVR的优化问题形式为
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 N ( ξ i ⋁ + ξ i ⋀ ) s . t . − ε − ξ i ⋁ ≤ y i − ( w T x i + b ) ≤ ε + ξ i ⋀ , i = 1 , 2 , ⋯ , N ξ i ⋁ ≥ 0 , ξ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} &\min_{\mathbf{w},b} \frac{1}{2} ||\mathbf{w}||_2^2 + C \sum_{i=1}^N (\xi_i^{\bigvee} + \xi_i^{\bigwedge}) \\ s.t. \quad - \varepsilon - \xi_i^{\bigvee}& \le y_i - (\mathbf{w}^T \mathbf{x}_i + b) \le \varepsilon + \xi_i^{\bigwedge}, \quad i = 1,2,\cdots,N \\ &\xi_i^{\bigvee} \ge 0, \xi_i^{\bigwedge} \ge 0, \quad i = 1,2,\cdots,N \end{aligned} s.t.−ε−ξi⋁w,bmin21∣∣w∣∣22+Ci=1∑N(ξi⋁+ξi⋀)≤yi−(wTxi+b)≤ε+ξi⋀,i=1,2,⋯,Nξi⋁≥0,ξi⋀≥0,i=1,2,⋯,N
带松弛变量的SVR目标函数的优化
依然与SVM分类模型类似,先用拉格朗日乘子法,将目标函数变成:
L ( w , b , α ⋁ , α ⋀ , ξ ⋁ , ξ ⋀ , μ ⋁ , μ ⋀ ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 N ( ξ i ⋁ + ξ i ⋀ ) + ∑ i = 1 N α i ⋁ [ − ε − ξ i ⋁ − y i + ( w T x i + b ) ] + ∑ i = 1 N α i ⋀ [ y i − ( w T x i + b ) − ε − ξ i ⋀ ] − ∑ i = 1 N μ i ⋁ ξ i ⋁ − ∑ i = 1 N μ i ⋀ ξ i ⋀ \begin{aligned} &L(\mathbf{w},b,\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) \\ = &\frac{1}{2} ||\mathbf{w}||_2^2 + C \sum_{i=1}^N (\xi_i^{\bigvee} + \xi_i^{\bigwedge}) + \sum_{i=1}^N \alpha_i^{\bigvee} [- \varepsilon - \xi_i^{\bigvee} - y_i + (\mathbf{w}^T \mathbf{x}_i + b)] \\ &+ \sum_{i=1}^N \alpha_i^{\bigwedge} [y_i - (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigwedge}] - \sum_{i=1}^N \mu_i^{\bigvee} \xi_i^{\bigvee} - \sum_{i=1}^N \mu_i^{\bigwedge} \xi_i^{\bigwedge} \end{aligned} =L(w,b,α⋁,α⋀,ξ⋁,ξ⋀,μ⋁,μ⋀)21∣∣w∣∣22+Ci=1∑N(ξi⋁+ξi⋀)+i=1∑Nαi⋁[−ε−ξi⋁−yi+(wTxi+b)]+i=1∑Nαi⋀[yi−(wTxi+b)−ε−ξi⋀]−i=1∑Nμi⋁ξi⋁−i=1∑Nμi⋀ξi⋀
其中, α i ⋁ ≥ 0 , α i ⋀ ≥ 0 , μ i ⋁ ≥ 0 , μ i ⋀ ≥ 0 \alpha_i^{\bigvee} \ge 0, \alpha_i^{\bigwedge} \ge 0, \mu_i^{\bigvee} \ge 0, \mu_i^{\bigwedge} \ge 0 αi⋁≥0,αi⋀≥0,μi⋁≥0,μi⋀≥0都是拉格朗日系数。
那么优化问题变为
min w , b , ξ ⋁ , ξ ⋀ max α ⋁ , α ⋀ , μ ⋁ , μ ⋀ L ( w , b , α ⋁ , α ⋀ , ξ ⋁ , ξ ⋀ , μ ⋁ , μ ⋀ ) s . t . ξ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N ξ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} \min_{\mathbf{w}, b, \boldsymbol{\xi}^{\bigvee}, \boldsymbol{\xi}^{\bigwedge}} \, \max_{\boldsymbol{\alpha}^{\bigvee}, \boldsymbol{\alpha}^{\bigwedge}, \boldsymbol{\mu}^{\bigvee}, \boldsymbol{\mu}^{\bigwedge}} \, L(&\mathbf{w},b,\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) \\ s.t. \quad \xi_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \xi_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \\ \quad \alpha_i^{\bigvee} \ge 0,& \quad i=1,2,\cdots,N \\ \alpha_i^{\bigwedge} \ge 0,& \quad i=1,2,\cdots,N \\ \mu_i^{\bigvee} \ge 0,& \quad i=1,2,\cdots,N \\ \mu_i^{\bigwedge} \ge 0,& \quad i=1,2,\cdots,N \end{aligned} w,b,ξ⋁,ξ⋀minα⋁,α⋀,μ⋁,μ⋀maxL(s.t.ξi⋁≥0,ξi⋀≥0,αi⋁≥0,αi⋀≥0,μi⋁≥0,μi⋀≥0,w,b,α⋁,α⋀,ξ⋁,ξ⋀,μ⋁,μ⋀)i=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,N
优化问题满足KKT条件,可以等价为对偶问题
max α ⋁ , α ⋀ , μ ⋁ , μ ⋀ min w , b , ξ ⋁ , ξ ⋀ L ( w , b , α ⋁ , α ⋀ , ξ ⋁ , ξ ⋀ , μ ⋁ , μ ⋀ ) s . t . ξ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N ξ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} \max_{\boldsymbol{\alpha}^{\bigvee}, \boldsymbol{\alpha}^{\bigwedge}, \boldsymbol{\mu}^{\bigvee}, \boldsymbol{\mu}^{\bigwedge}} \, \min_{\mathbf{w}, b, \boldsymbol{\xi}^{\bigvee}, \boldsymbol{\xi}^{\bigwedge}} \, L(&\mathbf{w},b,\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) \\ s.t. \quad \xi_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \xi_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \\ \quad \alpha_i^{\bigvee} \ge 0,& \quad i=1,2,\cdots,N \\ \alpha_i^{\bigwedge} \ge 0,& \quad i=1,2,\cdots,N \\ \mu_i^{\bigvee} \ge 0,& \quad i=1,2,\cdots,N \\ \mu_i^{\bigwedge} \ge 0,& \quad i=1,2,\cdots,N \end{aligned} α⋁,α⋀,μ⋁,μ⋀maxw,b,ξ⋁,ξ⋀minL(s.t.ξi⋁≥0,ξi⋀≥0,αi⋁≥0,αi⋀≥0,μi⋁≥0,μi⋀≥0,w,b,α⋁,α⋀,ξ⋁,ξ⋀,μ⋁,μ⋀)i=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,N
先求目标函数的最小化问题
min w , b , ξ ⋁ , ξ ⋀ L ( w , b , α ⋁ , α ⋀ , ξ ⋁ , ξ ⋀ , μ ⋁ , μ ⋀ ) \min_{\mathbf{w},b,\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge}} L(\mathbf{w},b,\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) w,b,ξ⋁,ξ⋀minL(w,b,α⋁,α⋀,ξ⋁,ξ⋀,μ⋁,μ⋀)
对参数求偏导得:
{ ∂ L ∂ w = 0 ⇒ w = ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i ∂ L ∂ b = 0 ⇒ ∑ i = 1 N ( α i ⋀ − α i ⋁ ) = 0 ∂ L ∂ ξ i ⋁ = 0 ⇒ C − α i ⋁ − μ i ⋁ = 0 ∂ L ∂ ξ i ⋀ = 0 ⇒ C − α i ⋀ − μ i ⋀ = 0 \left\{ \begin{aligned} &\frac{\partial L}{\partial \mathbf{w}} = 0 \Rightarrow \mathbf{w} = \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) \mathbf{x}_i \\ &\frac{\partial L}{\partial b} = 0 \Rightarrow \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) = 0 \\ &\frac{\partial L}{\partial \xi_i^{\bigvee}} = 0 \Rightarrow C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} = 0 \\ &\frac{\partial L}{\partial \xi_i^{\bigwedge}} = 0 \Rightarrow C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} = 0 \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂w∂L=0⇒w=i=1∑N(αi⋀−αi⋁)xi∂b∂L=0⇒i=1∑N(αi⋀−αi⋁)=0∂ξi⋁∂L=0⇒C−αi⋁−μi⋁=0∂ξi⋀∂L=0⇒C−αi⋀−μi⋀=0
令
ψ ( α ⋁ , α ⋀ , μ ⋁ , μ ⋀ ) = min w , b , ξ ⋁ , ξ ⋀ L ( w , b , α ⋁ , α ⋀ , ξ ⋁ , ξ ⋀ , μ ⋁ , μ ⋀ ) \psi(\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) = \min_{\mathbf{w}, b, \boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge}} L(\mathbf{w},b,\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\xi}^{\bigvee},\boldsymbol{\xi}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) ψ(α⋁,α⋀,μ⋁,μ⋀)=w,b,ξ⋁,ξ⋀minL(w,b,α⋁,α⋀,ξ⋁,ξ⋀,μ⋁,μ⋀)
把以上偏导结果代入目标函数得到
ψ ( α ⋁ , α ⋀ , μ ⋁ , μ ⋀ ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 N ( ξ i ⋁ + ξ i ⋀ ) + ∑ i = 1 N α i ⋁ [ − ε − ξ i ⋁ − y i + ( w T x i + b ) ] + ∑ i = 1 N α i ⋀ [ y i − ( w T x i + b ) − ε − ξ i ⋀ ] − ∑ i = 1 N μ i ⋁ ξ i ⋁ − ∑ i = 1 N μ i ⋀ ξ i ⋀ = 1 2 ∣ ∣ w ∣ ∣ 2 2 + ∑ i = 1 N [ ( C − α i ⋁ − μ i ⋁ ) ξ i ⋁ + ( C − α i ⋀ − μ i ⋀ ) ξ i ⋀ ] + ∑ i = 1 N α i ⋁ [ − ε − y i + ( w T x i + b ) ] + ∑ i = 1 N α i ⋀ [ y i − ( w T x i + b ) − ε ] = 1 2 ∣ ∣ w ∣ ∣ 2 2 + ∑ i = 1 N α i ⋁ [ − ε − y i + ( w T x i + b ) ] + ∑ i = 1 N α i ⋀ [ y i − ( w T x i + b ) − ε ] = 1 2 w T w − w T ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i + b ∑ i = 1 N ( α i ⋁ − α i ⋀ ) − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] = 1 2 w T ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i − w T ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] = − 1 2 w T ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] = − 1 2 [ ∑ j = 1 N ( α j ⋀ − α j ⋁ ) x j ] T ∑ i = 1 N ( α i ⋀ − α i ⋁ ) x i − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] = − 1 2 ∑ i = 1 N ∑ j = 1 N ( α i ⋀ − α i ⋁ ) ( α j ⋀ − α j ⋁ ) x j T x i − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] = − 1 2 ∑ i = 1 N ∑ j = 1 N ( α i ⋀ − α i ⋁ ) ( α j ⋀ − α j ⋁ ) x i T x j − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] \begin{aligned} &\psi(\boldsymbol{\alpha}^{\bigvee},\boldsymbol{\alpha}^{\bigwedge},\boldsymbol{\mu}^{\bigvee},\boldsymbol{\mu}^{\bigwedge}) \\ = &\frac{1}{2} ||\mathbf{w}||_2^2 + C \sum_{i=1}^N (\xi_i^{\bigvee} + \xi_i^{\bigwedge}) + \sum_{i=1}^N \alpha_i^{\bigvee} [- \varepsilon - \xi_i^{\bigvee} - y_i + (\mathbf{w}^T \mathbf{x}_i + b)] \\ &+ \sum_{i=1}^N \alpha_i^{\bigwedge} [y_i - (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigwedge}] - \sum_{i=1}^N \mu_i^{\bigvee} \xi_i^{\bigvee} - \sum_{i=1}^N \mu_i^{\bigwedge} \xi_i^{\bigwedge} \\ = &\frac{1}{2} ||\mathbf{w}||_2^2 + \sum_{i=1}^N [(C-\alpha_i^{\bigvee}-\mu_i^{\bigvee})\xi_i^{\bigvee} + (C-\alpha_i^{\bigwedge}-\mu_i^{\bigwedge}) \xi_i^{\bigwedge}] \\ &+ \sum_{i=1}^N \alpha_i^{\bigvee} [- \varepsilon - y_i + (\mathbf{w}^T \mathbf{x}_i + b)] + \sum_{i=1}^N \alpha_i^{\bigwedge} [y_i - (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon] \\ = &\frac{1}{2} ||\mathbf{w}||_2^2 + \sum_{i=1}^N \alpha_i^{\bigvee} [- \varepsilon - y_i + (\mathbf{w}^T \mathbf{x}_i + b)] + \sum_{i=1}^N \alpha_i^{\bigwedge} [y_i - (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon] \\ = &\frac{1}{2} \mathbf{w}^T \mathbf{w} - \mathbf{w}^T \sum_{i=1}^N ( \alpha_i^{\bigwedge} - \alpha_i^{\bigvee} ) \mathbf{x}_i + b \sum_{i=1}^N (\alpha_i^{\bigvee} - \alpha_i^{\bigwedge}) - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ = &\frac{1}{2} \mathbf{w}^T \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) \mathbf{x}_i - \mathbf{w}^T \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) \mathbf{x}_i - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ = & - \frac{1}{2} \mathbf{w}^T \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) \mathbf{x}_i - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ = & - \frac{1}{2} [ \sum_{j=1}^N (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_j ]^T \sum_{i=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) \mathbf{x}_i - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ = & - \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_j^T\mathbf{x}_i - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ = & - \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N (\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_i^T\mathbf{x}_j - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \end{aligned} =========ψ(α⋁,α⋀,μ⋁,μ⋀)21∣∣w∣∣22+Ci=1∑N(ξi⋁+ξi⋀)+i=1∑Nαi⋁[−ε−ξi⋁−yi+(wTxi+b)]+i=1∑Nαi⋀[yi−(wTxi+b)−ε−ξi⋀]−i=1∑Nμi⋁ξi⋁−i=1∑Nμi⋀ξi⋀21∣∣w∣∣22+i=1∑N[(C−αi⋁−μi⋁)ξi⋁+(C−αi⋀−μi⋀)ξi⋀]+i=1∑Nαi⋁[−ε−yi+(wTxi+b)]+i=1∑Nαi⋀[yi−(wTxi+b)−ε]21∣∣w∣∣22+i=1∑Nαi⋁[−ε−yi+(wTxi+b)]+i=1∑Nαi⋀[yi−(wTxi+b)−ε]21wTw−wTi=1∑N(αi⋀−αi⋁)xi+bi=1∑N(αi⋁−αi⋀)−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]21wTi=1∑N(αi⋀−αi⋁)xi−wTi=1∑N(αi⋀−αi⋁)xi−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]−21wTi=1∑N(αi⋀−αi⋁)xi−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]−21[j=1∑N(αj⋀−αj⋁)xj]Ti=1∑N(αi⋀−αi⋁)xi−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]−21i=1∑Nj=1∑N(αi⋀−αi⋁)(αj⋀−αj⋁)xjTxi−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]−21i=1∑Nj=1∑N(αi⋀−αi⋁)(αj⋀−αj⋁)xiTxj−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]
因为目标函数已经消去了参数 ξ ⋁ \boldsymbol{\xi}^{\bigvee} ξ⋁和 ξ ⋀ \boldsymbol{\xi}^{\bigwedge} ξ⋀,所以相应的约束条件也可以去掉。
剩下约束条件
α i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} \alpha_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \alpha_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \end{aligned} αi⋁≥0,αi⋀≥0,μi⋁≥0,μi⋀≥0,i=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,N
联合等式
C − α i ⋁ − μ i ⋁ = 0 , i = 1 , 2 , ⋯ , N C − α i ⋀ − μ i ⋀ = 0 , i = 1 , 2 , ⋯ , N \begin{aligned} C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} = 0,& \quad i = 1,2,\cdots,N \\ C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} = 0,& \quad i = 1,2,\cdots,N \end{aligned} C−αi⋁−μi⋁=0,C−αi⋀−μi⋀=0,i=1,2,⋯,Ni=1,2,⋯,N
可以去掉 μ i ⋁ , μ i ⋀ \mu_i^{\bigvee}, \mu_i^{\bigwedge} μi⋁,μi⋀,等效为
0 ≤ α i ⋁ ≤ C , i = 1 , 2 , ⋯ , N 0 ≤ α i ⋀ ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} 0 \le \alpha_i^{\bigvee} \le C,& \quad i = 1,2,\cdots,N \\ 0 \le \alpha_i^{\bigwedge} \le C,& \quad i = 1,2,\cdots,N \end{aligned} 0≤αi⋁≤C,0≤αi⋀≤C,i=1,2,⋯,Ni=1,2,⋯,N
去掉包含参数 μ i ⋁ , μ i ⋀ \mu_i^{\bigvee}, \mu_i^{\bigwedge} μi⋁,μi⋀的约束条件的原因和软间隔SVM分类模型的类似,是为了让整个优化问题涉及的参数尽量少,方便优化问题的求解。
综上,优化问题的数学形式表示为:
max α ⋁ , α ⋀ − 1 2 ∑ i = 1 N ∑ j = 1 N ( α i ⋀ − α i ⋁ ) ( α j ⋀ − α j ⋁ ) x i T x j − ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] s . t . ∑ i = 1 N ( α i ⋀ − α i ⋁ ) = 0 0 ≤ α i ⋁ ≤ C , i = 1 , 2 , ⋯ , N 0 ≤ α i ⋀ ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} \max_{\boldsymbol{\alpha}^{\bigvee}, \boldsymbol{\alpha}^{\bigwedge}} \, - \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N (\alpha_i^{\bigwedge} - &\alpha_i^{\bigvee}) (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_i^T \mathbf{x}_j - \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ s.t. \quad &\sum_{i=1}^N(\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) = 0 \\ &0 \le \alpha_i^{\bigvee} \le C, \quad i=1,2,\cdots,N \\ &0 \le \alpha_i^{\bigwedge} \le C, \quad i=1,2,\cdots,N \end{aligned} α⋁,α⋀max−21i=1∑Nj=1∑N(αi⋀−s.t.αi⋁)(αj⋀−αj⋁)xiTxj−i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]i=1∑N(αi⋀−αi⋁)=00≤αi⋁≤C,i=1,2,⋯,N0≤αi⋀≤C,i=1,2,⋯,N
目标函数去掉负号,将上述的最大化问题变成最小化问题,得到等价问题:
min α ⋁ , α ⋀ 1 2 ∑ i = 1 N ∑ j = 1 N ( α i ⋀ − α i ⋁ ) ( α j ⋀ − α j ⋁ ) x i T x j + ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] s . t . ∑ i = 1 N ( α i ⋀ − α i ⋁ ) = 0 0 ≤ α i ⋁ ≤ C , i = 1 , 2 , ⋯ , N 0 ≤ α i ⋀ ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} \min_{\boldsymbol{\alpha}^{\bigvee}, \boldsymbol{\alpha}^{\bigwedge}} \, \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N (\alpha_i^{\bigwedge} - &\alpha_i^{\bigvee}) (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_i^T\mathbf{x}_j + \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ s.t. \quad &\sum_{i=1}^N(\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) = 0 \\&0 \le \alpha_i^{\bigvee} \le C, \quad i=1,2,\cdots,N \\&0 \le \alpha_i^{\bigwedge} \le C, \quad i=1,2,\cdots,N \end{aligned} α⋁,α⋀min21i=1∑Nj=1∑N(αi⋀−s.t.αi⋁)(αj⋀−αj⋁)xiTxj+i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]i=1∑N(αi⋀−αi⋁)=00≤αi⋁≤C,i=1,2,⋯,N0≤αi⋀≤C,i=1,2,⋯,N
通过SMO算法可以求得最优参数 α ⋁ ∗ {\boldsymbol{\alpha}^{\bigvee}}^* α⋁∗和 α ⋀ ∗ {\boldsymbol{\alpha}^{\bigwedge}}^* α⋀∗,然后计算
w ∗ = ∑ i = 1 N ( α i ⋀ ∗ − α i ⋁ ∗ ) x i \mathbf{w}^* = \sum_{i=1}^N ({\alpha_i^{\bigwedge}}^* - {\alpha_i^{\bigvee}}^*) \mathbf{x}_i w∗=i=1∑N(αi⋀∗−αi⋁∗)xi
与软间隔SVM分类模型类似,SVR的支持向量并不都在最大间隔边界上,而且SVR上下界的数学表达式还不相同,为方便处理,我们只选用下界的支持向量(当然,你也可以选用上界的支持向量)。

对任一下界的支持向量 ( x k , y k ) (\mathbf{x}_k,y_k) (xk,yk),有
b ∗ = y k + ϵ − w ∗ T x k b^* = y_k +\epsilon - {\mathbf{w}^*}^T \mathbf{x}_k b∗=yk+ϵ−w∗Txk
实践中常采用一种求 b ∗ b^* b∗的更鲁棒(robust)的方法:选取多个(或所有)下界(或上界)的支持向量求解b后再取平均。
SVM回归模型的支持向量
已知KKT条件(部分,不是全部):
C − α i ⋁ − μ i ⋁ = 0 , i = 1 , 2 , ⋯ , N C − α i ⋀ − μ i ⋀ = 0 , i = 1 , 2 , ⋯ , N α i ⋁ [ ε + ξ i ⋁ + y i − ( w T x i + b ) ] = 0 , i = 1 , 2 , ⋯ , N α i ⋀ [ ε + ξ i ⋀ − y i + ( w T x i + b ) ] = 0 , i = 1 , 2 , ⋯ , N μ i ⋁ ξ i ⋁ = 0 , i = 1 , 2 , ⋯ , N μ i ⋀ ξ i ⋀ = 0 , i = 1 , 2 , ⋯ , N y i ≥ ( w T x i + b ) − ε − ξ i ⋁ , i = 1 , 2 , ⋯ , N y i ≤ ( w T x i + b ) + ε + ξ i ⋀ , i = 1 , 2 , ⋯ , N ξ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N ξ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N α i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋁ ≥ 0 , i = 1 , 2 , ⋯ , N μ i ⋀ ≥ 0 , i = 1 , 2 , ⋯ , N \begin{aligned} C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} = 0,& \quad i = 1,2,\cdots,N \\ C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} = 0,& \quad i = 1,2,\cdots,N \\ \alpha_i^{\bigvee} [ \varepsilon + \xi_i^{\bigvee} + y_i - (\mathbf{w}^T \mathbf{x}_i + b)] = 0,& \quad i = 1,2,\cdots,N \\ \alpha_i^{\bigwedge} [ \varepsilon + \xi_i^{\bigwedge} - y_i + (\mathbf{w}^T \mathbf{x}_i + b) ] = 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigvee} \xi_i^{\bigvee} = 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigwedge} \xi_i^{\bigwedge} = 0,& \quad i = 1,2,\cdots,N \\ y_i \ge (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee},& \quad i = 1,2,\cdots,N \\ y_i \le (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge},& \quad i = 1,2,\cdots,N \\ \xi_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \xi_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \\ \alpha_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \alpha_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigvee} \ge 0,& \quad i = 1,2,\cdots,N \\ \mu_i^{\bigwedge} \ge 0,& \quad i = 1,2,\cdots,N \end{aligned} C−αi⋁−μi⋁=0,C−αi⋀−μi⋀=0,αi⋁[ε+ξi⋁+yi−(wTxi+b)]=0,αi⋀[ε+ξi⋀−yi+(wTxi+b)]=0,μi⋁ξi⋁=0,μi⋀ξi⋀=0,yi≥(wTxi+b)−ε−ξi⋁,yi≤(wTxi+b)+ε+ξi⋀,ξi⋁≥0,ξi⋀≥0,αi⋁≥0,αi⋀≥0,μi⋁≥0,μi⋀≥0,i=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,Ni=1,2,⋯,N
我们有以下推论:
-
如果 α i ⋁ ≠ 0 \alpha_i^{\bigvee} \ne 0 αi⋁=0且 α i ⋀ ≠ 0 \alpha_i^{\bigwedge} \ne 0 αi⋀=0,那么根据
{ α i ⋁ [ ε + ξ i ⋁ + y i − ( w T x i + b ) ] = 0 α i ⋀ [ ε + ξ i ⋀ − y i + ( w T x i + b ) ] = 0 \left\{ \begin{aligned} \alpha_i^{\bigvee} [ \varepsilon + \xi_i^{\bigvee} + y_i - (\mathbf{w}^T \mathbf{x}_i + b)] &= 0 \\ \alpha_i^{\bigwedge} [ \varepsilon + \xi_i^{\bigwedge} - y_i + (\mathbf{w}^T \mathbf{x}_i + b) ] &= 0 \end{aligned} \right. ⎩⎨⎧αi⋁[ε+ξi⋁+yi−(wTxi+b)]αi⋀[ε+ξi⋀−yi+(wTxi+b)]=0=0
样本点 ( x i , y i ) (\mathbf{x}_i, y_i) (xi,yi)就必须满足
{ ε + ξ i ⋁ + y i − ( w T x i + b ) = 0 ε + ξ i ⋀ − y i + ( w T x i + b ) = 0 \left\{ \begin{aligned} \varepsilon + \xi_i^{\bigvee} + y_i - (\mathbf{w}^T \mathbf{x}_i + b) &= 0 \\ \varepsilon + \xi_i^{\bigwedge} - y_i + (\mathbf{w}^T \mathbf{x}_i + b) &= 0 \end{aligned} \right. ⎩⎨⎧ε+ξi⋁+yi−(wTxi+b)ε+ξi⋀−yi+(wTxi+b)=0=0
即
{ y i = ( w T x i + b ) − ε − ξ i ⋁ y i = ( w T x i + b ) + ε + ξ i ⋀ \left\{ \begin{aligned} y_i = (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee} \\ y_i = (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge} \end{aligned} \right. ⎩⎨⎧yi=(wTxi+b)−ε−ξi⋁yi=(wTxi+b)+ε+ξi⋀
因为
{ ξ i ⋁ ≥ 0 ξ i ⋀ ≥ 0 \left\{ \begin{aligned} \xi_i^{\bigvee} \ge 0 \\ \xi_i^{\bigwedge} \ge 0 \end{aligned} \right. ⎩⎨⎧ξi⋁≥0ξi⋀≥0所以样本点 ( x i , y i ) (\mathbf{x}_i, y_i) (xi,yi)同时在上界外和下界外,显然是不可能的。

- 如果 α i ⋁ = 0 \alpha_i^{\bigvee}=0 αi⋁=0且 α i ⋀ = 0 \alpha_i^{\bigwedge}=0 αi⋀=0,根据
{ C − α i ⋁ − μ i ⋁ = 0 C − α i ⋀ − μ i ⋀ = 0 \left\{ \begin{aligned} C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} &= 0 \\ C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} &= 0 \end{aligned} \right. ⎩⎨⎧C−αi⋁−μi⋁C−αi⋀−μi⋀=0=0
有
{ μ i ⋁ = C μ i ⋀ = C \left\{ \begin{aligned} \mu_i^{\bigvee} &= C \\ \mu_i^{\bigwedge} &= C \end{aligned} \right. ⎩⎨⎧μi⋁μi⋀=C=C
再根据
{ μ i ⋁ ξ i ⋁ = 0 μ i ⋀ ξ i ⋀ = 0 \left\{ \begin{aligned} \mu_i^{\bigvee} \xi_i^{\bigvee} &= 0 \\ \mu_i^{\bigwedge} \xi_i^{\bigwedge} &= 0 \end{aligned} \right. ⎩⎨⎧μi⋁ξi⋁μi⋀ξi⋀=0=0
有
{ ξ i ⋁ = 0 ξ i ⋀ = 0 \left\{ \begin{aligned} \xi_i^{\bigvee} &= 0 \\ \xi_i^{\bigwedge} &= 0 \end{aligned} \right. ⎩⎨⎧ξi⋁ξi⋀=0=0
所以
{ y i ≥ ( w T x i + b ) − ε y i ≤ ( w T x i + b ) + ε \left\{ \begin{aligned} y_i &\ge (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon \\ y_i &\le (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon \end{aligned} \right. {yiyi≥(wTxi+b)−ε≤(wTxi+b)+ε
样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)在 ε \varepsilon ε通道内,不是支持向量;
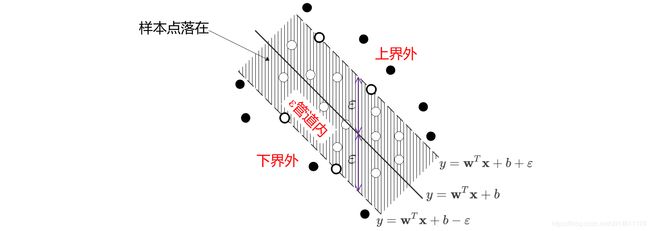
上面两种情况的讨论可以总结出
α i ⋁ ≠ 0 ⇒ y i = ( w T x i + b ) − ε − ξ i ⋁ α i ⋀ ≠ 0 ⇒ y i = ( w T x i + b ) + ε + ξ i ⋀ α i ⋁ = 0 ⇒ y i ≥ ( w T x i + b ) − ε α i ⋀ = 0 ⇒ y i ≤ ( w T x i + b ) + ε \begin{aligned} \alpha_i^{\bigvee} \ne 0 \quad&\Rightarrow \quad y_i = (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee} \\ \alpha_i^{\bigwedge} \ne 0 \quad&\Rightarrow \quad y_i = (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge} \\ \alpha_i^{\bigvee}=0 \quad&\Rightarrow \quad y_i \ge (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon \\ \alpha_i^{\bigwedge}=0 \quad&\Rightarrow \quad y_i \le (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon \end{aligned} αi⋁=0αi⋀=0αi⋁=0αi⋀=0⇒yi=(wTxi+b)−ε−ξi⋁⇒yi=(wTxi+b)+ε+ξi⋀⇒yi≥(wTxi+b)−ε⇒yi≤(wTxi+b)+ε
- 如果 α i ⋁ ≠ 0 \alpha_i^{\bigvee} \ne 0 αi⋁=0且 α i ⋀ = 0 \alpha_i^{\bigwedge} = 0 αi⋀=0,有
{ y i = ( w T x i + b ) − ε − ξ i ⋁ y i ≤ ( w T x i + b ) + ε ⇒ y i = ( w T x i + b ) − ε − ξ i ⋁ \left\{ \begin{aligned} y_i &= (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee} \\ y_i &\le (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon \end{aligned} \right. \quad \Rightarrow \quad y_i = (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee} {yiyi=(wTxi+b)−ε−ξi⋁≤(wTxi+b)+ε⇒yi=(wTxi+b)−ε−ξi⋁
说明样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)在最大间隔的下界外,是支持向量。
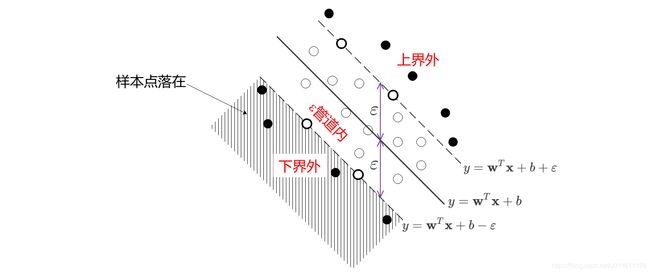
可以更进一步讨论:
-
如果 0 < α i ⋁ < C 0 \lt \alpha_i^{\bigvee} \lt C 0<αi⋁<C,根据
C − α i ⋁ − μ i ⋁ = 0 C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} = 0 C−αi⋁−μi⋁=0
可知
μ i ⋁ > 0 \mu_i^{\bigvee} \gt 0 μi⋁>0
由
μ i ⋁ ξ i ⋁ = 0 \mu_i^{\bigvee} \xi_i^{\bigvee} = 0 μi⋁ξi⋁=0
得出
ξ i ⋁ = 0 \xi_i^{\bigvee} = 0 ξi⋁=0
因此
y i = ( w T x i + b ) − ε y_i = (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon yi=(wTxi+b)−ε
说明样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)恰好落在最大间隔的下界; -
如果 α i ⋁ = C \alpha_i^{\bigvee} = C αi⋁=C,根据
C − α i ⋁ − μ i ⋁ = 0 C - \alpha_i^{\bigvee} - \mu_i^{\bigvee} = 0 C−αi⋁−μi⋁=0
可知
μ i ⋁ = 0 \mu_i^{\bigvee} = 0 μi⋁=0
由
μ i ⋁ ξ i ⋁ = 0 \mu_i^{\bigvee} \xi_i^{\bigvee} = 0 μi⋁ξi⋁=0
得出
ξ i ⋁ ≥ 0 \xi_i^{\bigvee} \ge 0 ξi⋁≥0
由于样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)满足
y i = ( w T x i + b ) − ε − ξ i ⋁ y_i = (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon - \xi_i^{\bigvee} yi=(wTxi+b)−ε−ξi⋁
说明样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)不高于最大间隔的下界; -
同理,如果 α i ⋁ = 0 \alpha_i^{\bigvee} = 0 αi⋁=0且 α i ⋀ ≠ 0 \alpha_i^{\bigwedge} \ne 0 αi⋀=0,那么有
{ y i = ( w T x i + b ) + ε + ξ i ⋀ y i ≥ ( w T x i + b ) − ε ⇒ y i = ( w T x i + b ) + ε + ξ i ⋀ \left\{ \begin{aligned} y_i &= (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge} \\ y_i &\ge (\mathbf{w}^T \mathbf{x}_i + b) - \varepsilon \end{aligned} \quad \Rightarrow \quad y_i = (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge} \right. {yiyi=(wTxi+b)+ε+ξi⋀≥(wTxi+b)−ε⇒yi=(wTxi+b)+ε+ξi⋀
说明样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)在最大间隔的上界外,是支持向量。
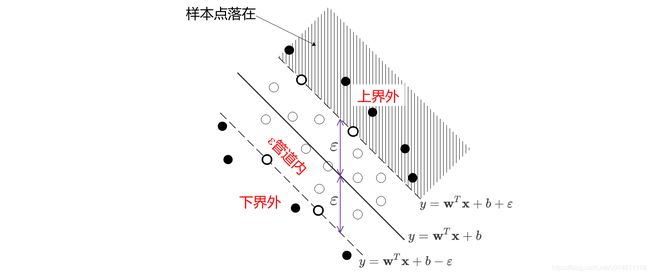
-
如果 0 < α i ⋀ < C 0 \lt \alpha_i^{\bigwedge} \lt C 0<αi⋀<C,根据
C − α i ⋀ − μ i ⋀ = 0 C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} = 0 C−αi⋀−μi⋀=0
可知
μ i ⋀ > 0 \mu_i^{\bigwedge} \gt 0 μi⋀>0
由
μ i ⋀ ξ i ⋀ = 0 \mu_i^{\bigwedge} \xi_i^{\bigwedge} = 0 μi⋀ξi⋀=0
得出
ξ i ⋀ = 0 \xi_i^{\bigwedge} = 0 ξi⋀=0
因此
y i = ( w T x i + b ) + ε y_i = (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon yi=(wTxi+b)+ε
样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)恰好落在最大间隔的上界; -
如果 α i ⋀ = C \alpha_i^{\bigwedge} = C αi⋀=C,根据
C − α i ⋀ − μ i ⋀ = 0 C - \alpha_i^{\bigwedge} - \mu_i^{\bigwedge} = 0 C−αi⋀−μi⋀=0
可知
μ i ⋀ = 0 \mu_i^{\bigwedge} = 0 μi⋀=0
由
μ i ⋀ ξ i ⋀ = 0 \mu_i^{\bigwedge} \xi_i^{\bigwedge} = 0 μi⋀ξi⋀=0
得出
ξ i ⋀ ≥ 0 \xi_i^{\bigwedge} \ge 0 ξi⋀≥0
由于样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)满足
y i = ( w T x i + b ) + ε + ξ i ⋀ y_i = (\mathbf{w}^T \mathbf{x}_i + b) + \varepsilon + \xi_i^{\bigwedge} yi=(wTxi+b)+ε+ξi⋀
说明样本点 ( x i , y i ) (\mathbf{x}_i,y_i) (xi,yi)不低于最大间隔的上界;
所以,当 0 < α i ⋁ < C 0 \lt \alpha_i^{\bigvee} \lt C 0<αi⋁<C时,样本点是落在最大间隔下界的支持向量。
如果你要找落在最大间隔上界的支持向量,应该要找 0 < α i ⋀ < C 0 \lt \alpha_i^{\bigwedge} \lt C 0<αi⋀<C的样本点。
SVR的算法过程
输入:训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(\mathbf{x}_1,y_1), (\mathbf{x}_2,y_2), \cdots, (\mathbf{x}_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}。
输出:分离超平面和分类决策函数。
算法步骤:
-
选择一个惩罚系数 C > 0 C \gt 0 C>0,构造约束优化问题
min α ⋁ , α ⋀ 1 2 ∑ i = 1 N ∑ j = 1 N ( α i ⋀ − α i ⋁ ) ( α j ⋀ − α j ⋁ ) x i T x j + ∑ i = 1 N [ ( ε − y i ) α i ⋀ + ( ε + y i ) α i ⋁ ] s . t . ∑ i = 1 N ( α i ⋀ − α i ⋁ ) = 0 0 ≤ α i ⋁ ≤ C , i = 1 , 2 , ⋯ , N 0 ≤ α i ⋀ ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} \min_{\boldsymbol{\alpha}^{\bigvee}, \boldsymbol{\alpha}^{\bigwedge}} \, \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N (\alpha_i^{\bigwedge} - &\alpha_i^{\bigvee}) (\alpha_j^{\bigwedge} - \alpha_j^{\bigvee}) \mathbf{x}_i^T\mathbf{x}_j + \sum_{i=1}^N [ ( \varepsilon - y_i ) \alpha_i^{\bigwedge} + (\varepsilon + y_i) \alpha_i^{\bigvee} ] \\ s.t. \quad &\sum_{i=1}^N(\alpha_i^{\bigwedge} - \alpha_i^{\bigvee}) = 0 \\&0 \le \alpha_i^{\bigvee} \le C, \quad i=1,2,\cdots,N \\&0 \le \alpha_i^{\bigwedge} \le C, \quad i=1,2,\cdots,N \end{aligned} α⋁,α⋀min21i=1∑Nj=1∑N(αi⋀−s.t.αi⋁)(αj⋀−αj⋁)xiTxj+i=1∑N[(ε−yi)αi⋀+(ε+yi)αi⋁]i=1∑N(αi⋀−αi⋁)=00≤αi⋁≤C,i=1,2,⋯,N0≤αi⋀≤C,i=1,2,⋯,N -
用SMO算法求出最优参数 α ⋁ ∗ {\boldsymbol{\alpha}^{\bigvee}}^* α⋁∗和 α ⋀ ∗ {\boldsymbol{\alpha}^{\bigwedge}}^* α⋀∗。
-
计算 w ∗ = ∑ i = 1 N ( α i ⋀ ∗ − α i ⋁ ∗ ) x i \mathbf{w}^* = \sum_{i=1}^N ({\alpha_i^{\bigwedge}}^* - {\alpha_i^{\bigvee}}^*) \mathbf{x}_i w∗=∑i=1N(αi⋀∗−αi⋁∗)xi。
-
寻找一个满足 0 < α i ⋁ ∗ < C 0 \lt {\alpha_i^{\bigvee}}^* \lt C 0<αi⋁∗<C的样本点 ( x k , y k ) (\mathbf{x}_k,y_k) (xk,yk),计算 b ∗ = y k + ϵ − w ∗ T x k b^* = y_k +\epsilon - {\mathbf{w}^*}^T \mathbf{x}_k b∗=yk+ϵ−w∗Txk。
-
构建最终的回归超平面 w ∗ T x + b ∗ = 0 {\mathbf{w}^*}^T \mathbf{x} + b^*=0 w∗Tx+b∗=0和预测函数 f ( x ) = sgn ( w ∗ T x + b ∗ ) f(x) = \text{sgn}({\mathbf{w}^*}^T \mathbf{x} + b^*) f(x)=sgn(w∗Tx+b∗)。
与SVM类似,非线性情况下SVR也可以使用核方法,算法流程只要将内积 x i T x j \mathbf{x}_i^T \mathbf{x}_j xiTxj都替换成核函数 κ ( x i , x j ) \kappa(\mathbf{x}_i, \mathbf{x}_j) κ(xi,xj)即可。
带松弛变量的SVR的一种解释: ε \varepsilon ε不敏感损失+L2正则
ε \varepsilon ε不敏感损失( ε \varepsilon ε-insensitive loss)
ε \varepsilon ε不敏感损失表达式
L ε ( x ) = { 0 , ∣ x ∣ ≤ ε ∣ x ∣ − ε , ∣ x ∣ > ε L_{\varepsilon}(x)= \left\{ \begin{aligned} 0, \quad |x| \le \varepsilon \\ |x| - \varepsilon, \quad |x| \gt \varepsilon \end{aligned} \right. Lε(x)={0,∣x∣≤ε∣x∣−ε,∣x∣>ε

带松弛变量的SVR的一种解释
带松弛变量的SVR的优化函数: L ( w , b ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 + C ∑ i = 1 N ( ξ i ⋁ + ξ i ⋀ ) L(\mathbf{w}, b) = \frac{1}{2}||\mathbf{w}||_2