【python机器学习基础教程】(二)
监督学习
监督学习算法
朴素贝叶斯分类器
朴素贝叶斯分类器通过单独查看每个特征来学习参数,并从每个特征中收集简单的类别统计数据。
scikit-learn中实现了三种朴素贝叶斯分类器:GaussianNB、BernoulliNB和MultinomialNB。GaussianNB可应用于任意连续数据,而BernoulliNB假定输入数据为二分类数据,MultinomialNB假定输入数据为计数数据(即每个特征代表某个对象的整数计数,比如一个单词在句子里出现的次数)。BernoulliNB和MultinomialNB主要用于文本数据分类。
BernoulliNB分类器计算每个类别中每个特征不为0的元素个数。
决策树
mglearn.plots.plot_animal_tree()
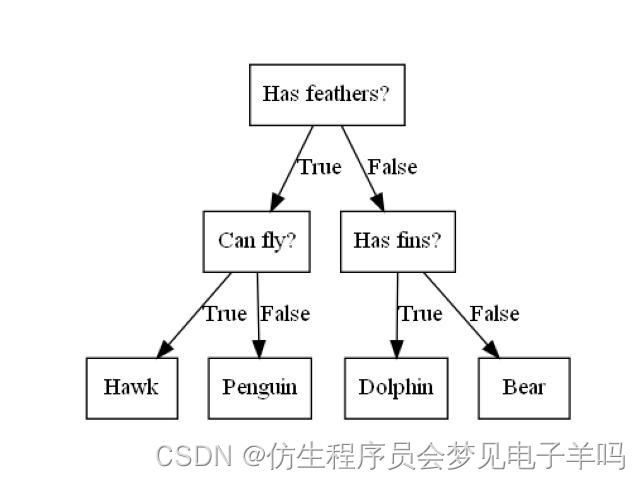
在这张图中,树的每一个结点代表一个问题或一个包含答案的终结点(也叫叶结点)
防止过拟合有两种常见的策略:一种是及早停止树的生长,也叫预剪枝;另一种是先构造树,但随后删除或折叠信息量很少的结点,也叫后剪枝。
决策树集成
集成是合并多个机器学习模型来构建更强大模型的方法。
已证明有两种集成模型对大量分类和回归 的数据集都是有效的,二者都以决策树为基础,分别是随机森林和梯度提升决策树
随机森林
构造随机森林
分析随机森林
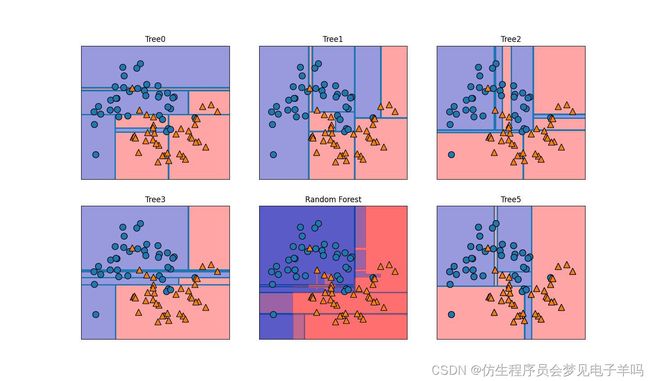
下面将5棵树组成的随机森林应用到two_moons数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100,noise=0.25,random_state=3)
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)
forest=RandomForestClassifier(n_estimators=5,random_state=2)
forest.fit(X_train,y_train)
作为随机森林的一部分,树被保存在estimator_属性中。
fig,axes=plt.subplots(2,3,figsize=(20,10))
for i,(ax,tree) in enumerate(zip(axes.ravel(),forest.estimators_)):
ax.set_title("Tree{}".format(i))
mglearn.plots.plot_tree_partition(X_train,y_train,tree,ax=ax)
mglearn.plots.plot_2d_separator(forest,X_train,fill=True,ax=axes[-1,1],alpha=.4)
axes[-1,1].set_title("Random Forest")
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)
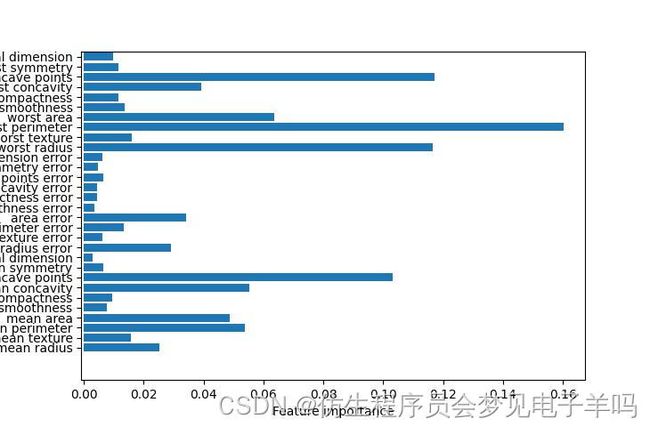
def plot_feature_importances_cancer(model):
n_features=cancer.data.shape[1]
plt.barh(range(n_features),model.feature_importances_,align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
forest= RandomForestClassifier(n_estimators=100,random_state=0)
forest.fit(X_train,y_train)
plot_feature_importances_cancer(forest)
拟合乳腺癌数据集得到的随机森林的特征重要性。
梯度提升 回归树(梯度提升机)
梯度提升回归树是另一种集成方法,通过合并多个决策树来构建一个更强大的模型。
梯度提升背后的主要思想是合并许多简单的模型(在这个语境中叫做弱学习器),比如深度较小的树。每棵树只能对部分数据做出好的预测,因此,添加的树越来越多,可以不断提高迭代性能。
除了预剪枝与集成中树的数量外,梯度提升的另一个重要参数是learning_rate(学习率),用以控制每棵树纠正前一棵树的错误的强度。
核支持向量机
核支持向量机(SVM)是可以推广到更复杂模型的扩展,这些模型无法被输入空间的超平面定义。
线性模型和非线性特征
from sklearn.datasets import make_blobs
X,y=make_blobs(centers=4,random_state=8)
y=y%2
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
二分类数据集,其类别并不是线性可分的:
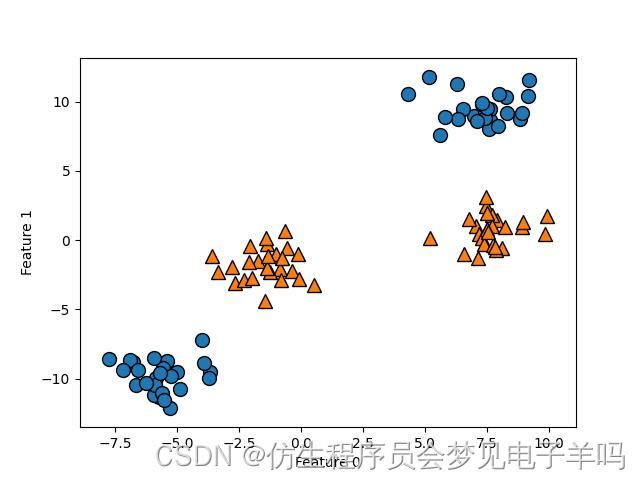
from sklearn.svm import LinearSVC
linear_svm = LinearSVC().fit(X,y)
mglearn.plots.plot_2d_separator(linear_svm ,X)
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")

现在我们对输入特征进行扩展,比如说添加第二个特征的平方(feature1 **2)作为一个新特征。现在我们将每个数据点表示为三维数据点,这个新的表示可以画成三维散点图:
X_new = np.hstack([X,X[:,1:]**2])
from mpl_toolkits.mplot3d import Axes3D,axes3d
figure=plt.figure()
ax= Axes3D(figure,elev=-152,azim=-26)
mask=y==0
ax.scatter(X_new[mask,0],X_new[mask,1],X_new[mask,2],c='b',cmap=mglearn.cm2,s=60)
ax.scatter(X_new[~mask,0],X_new[~mask,1],X_new[~mask,2],c='r',marker='^',cmap=mglearn.cm2,s=60)
ax.set_xlabel("feature0")
ax.set_ylabel("feature1")
ax.set_zlabel("feature1 **2")
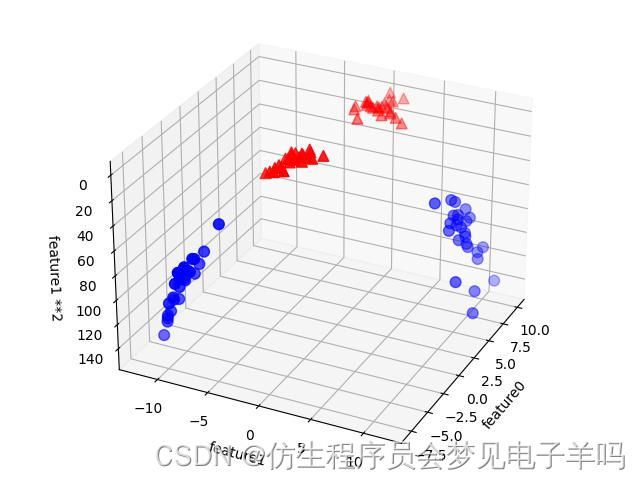
在数据的新表示中,现在可以用线性模型(三维空间中的平面)将这两个类别分开。
我们可以用线性模型拟合扩展后的数据来验证这一点:
linear_svm_3d=LinearSVC().fit(X_new,y)
coef,intercept=linear_svm_3d.coef_.ravel(),linear_svm_3d.intercept_
figure=plt.figure()
ax= Axes3D(figure,elev=-152,azim=-26)
xx=np.linspace(X_new[:,0].min()-2,X_new[:,0].max()+2,50)
yy=np.linspace(X_new[:,1].min()-2,X_new[:,1].max()+2,50)
XX,YY =np.meshgrid(xx,yy)
ZZ=(coef[0]*XX+coef[1]*YY+intercept)/-coef[2]
ax.plot_surface(XX,YY,ZZ,rstride=8,cstride=8,alpha=0.3)
ax.scatter(X_new[mask,0],X_new[mask,1],X_new[mask,2],c='b',cmap=mglearn.cm2,s=60)
ax.scatter(X_new[~mask,0],X_new[~mask,1],X_new[~mask,2],c='r',marker='^',cmap=mglearn.cm2,s=60)
ax.set_xlabel("feature0")
ax.set_ylabel("feature1")
ax.set_zlabel("feature1 **2")
线性SVM对扩展后的三维数据集给出的决策边界
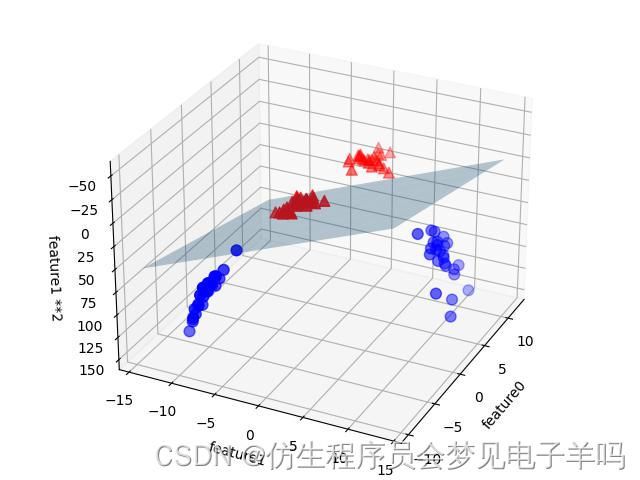
如果将线性SVM模型看作原始特征的函数,那么它实际上已经不是线性的了。它不是一条直线,而是一个椭圆。
ZZ=YY**2
dec=linear_svm_3d.decision_function(np.c_[XX.ravel(),YY.ravel(),ZZ.ravel()])
plt.contourf(XX,YY,dec.reshape(XX.shape),levels=[dec.min(),0,dec.max()],cmap=mglearn.cm2,alpha=0.5)
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
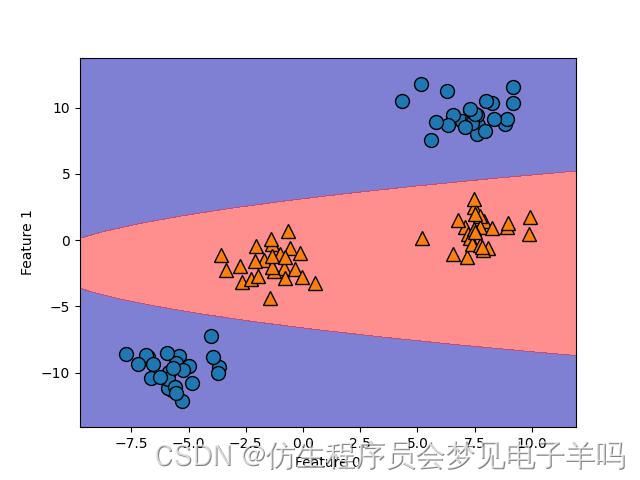
核技巧
核技巧的原理是:直接计算扩展特征表示中数据点之间的距离(内积),而不用实际对扩展进行计算。
对于支持向量机,将数据映射到更高维空间中有两种常用 方法:
一种是多项式核,在一定阶数内计算原始特征所有可能的多项式;
另一种是径向基函数核,也叫高斯核。
理解SVM
在训练过程中,SVM学习每个训练数据点对于两个类别之间的决策边界的重要性。
通常只有一部分训练数据点对于定义决策边界来说很重要:位于类别之间边界上的那些点。
这些点叫做支持向量,支持向量机正是由此得名。
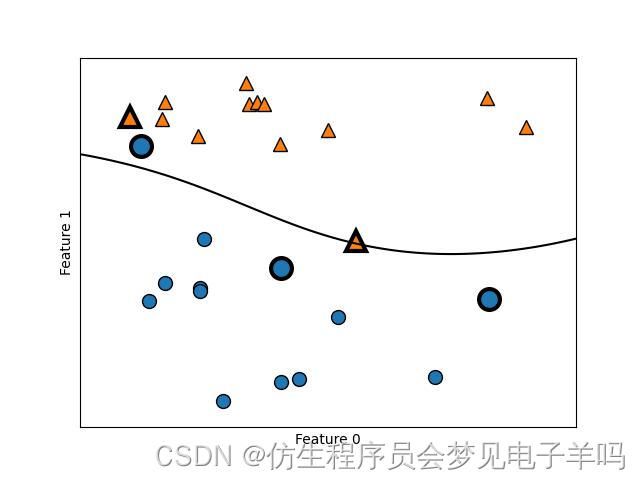
下图是支持向量机对一个二维二分类数据集上的训练结果。
决策边界用黑色表示,支持向量是尺寸较大的点。
下列代码将在forge数据集上训练SVM并创建此图。
from sklearn.svm import SVC
X,y=mglearn.tools.make_handcrafted_dataset()
svm=SVC(kernel='rbf',C=10,gamma=0.1).fit(X,y)
mglearn.plots.plot_2d_separator(svm,X,eps=.5)
mglearn.discrete_scatter(X[:,0],X[:,1],y)
sv=svm.support_vectors_
sv_labels=svm.dual_coef_.ravel()>0
mglearn.discrete_scatter(sv[:,0],sv[:,1],sv_labels,s=15,markeredgewidth=3)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
RBF核SVM给出的决策边界和支持向量
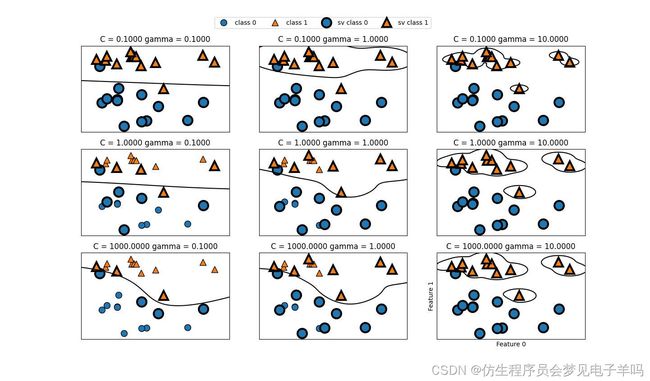
fig,axes=plt.subplots(3,3,figsize=(15,10))
for ax,C in zip(axes,[-1,0,3]):
for a,gamma in zip(ax,range(-1,2)):
mglearn.plots.plot_svm(log_C=C,log_gamma=gamma,ax=a)
axes[0,0].legend(["class 0","class 1","sv class 0","sv class 1"],ncol=4,loc=(.9,1.2))
神经网络(深度学习)
此时此处只讨论相对简单的方法,即用于分类和回归的多层感知机(MLP)。
MLP也被称为(普通)前馈神经网络,有时也简称为神经网络。
线性回归的预测公式为:
y ^ = w [ 0 ] ∗ x [ 0 ] + w [ 1 ] ∗ x [ 1 ] + ⋅ ⋅ ⋅ + w [ p ] ∗ x [ p ] + b \hat{y}=w[0]*x[0]+w[1]*x[1]+···+w[p]*x[p]+b y^=w[0]∗x[0]+w[1]∗x[1]+⋅⋅⋅+w[p]∗x[p]+b
简单来说, y ^ \hat{y} y^是输入特征 x [ 0 ] x[0] x[0]到 x [ p ] x[p] x[p]的加权求和,权重为学到的系数 w [ 0 ] w[0] w[0]到 w [ p ] w[p] w[p].
我们将这个公式可视化:
display(mglearn.plots.plot_logistic_regression_graph())
digraph {
graph [rankdir=LR splines=line]
node [fixedsize=True shape=circle]
subgraph cluster_0 {
node [shape=circle]
“x[0]” [labelloc=c]
“x[1]” [labelloc=c]
“x[2]” [labelloc=c]
“x[3]” [labelloc=c]
label = “inputs” color = “white” }
subgraph cluster_2 {
node [shape=circle]
label = “output” color = “white” y
}
“x[0]” -> y [label=“w[0]”]
“x[1]” -> y [label=“w[1]”]
“x[2]” -> y [label=“w[2]”]
“x[3]” -> y [label=“w[3]”]
}
display(mglearn.plots.plot_single_hidden_layer_graph())
digraph {
graph [rankdir=LR splines=line]
node [fixedsize=True shape=circle]
subgraph cluster_0 {
node [shape=circle]
“x[0]”
“x[1]”
“x[2]”
“x[3]”
label = “inputs” color = “white” }
subgraph cluster_1 {
node [shape=circle]
label = “hidden layer” color = “white” h0 [label=“h[0]”]
h1 [label=“h[1]”]
h2 [label=“h[2]”]
}
subgraph cluster_2 {
node [shape=circle]
y
label = “output” color = “white” }
“x[0]” -> h0
“x[0]” -> h1
“x[0]” -> h2
“x[1]” -> h0
“x[1]” -> h1
“x[1]” -> h2
“x[2]” -> h0
“x[2]” -> h1
“x[2]” -> h2
“x[3]” -> h0
“x[3]” -> h1
“x[3]” -> h2
h0 -> y
h1 -> y
h2 -> y
}
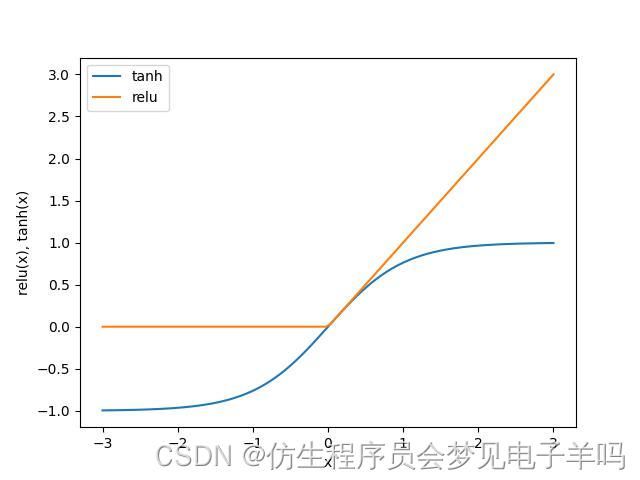
line = np.linspace(-3, 3, 100)
plt.plot(line, np.tanh(line), label="tanh")
plt.plot(line, np.maximum(line, 0), label="relu")
plt.legend(loc="best")
plt.xlabel("x")
plt.ylabel("relu(x), tanh(x)")
plt.show()
双曲正切激活函数与校正线性激活函数
神经网络调参
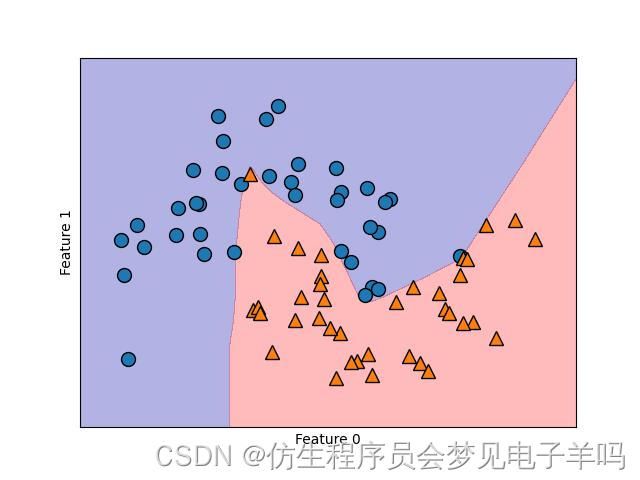
我们将MLPClassifier应用到之前用过的teo_moons数据集上,以此研究MLP的工作原理。
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100,noise=0.25,random_state=3)
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)
mlp=MLPClassifier(solver='lbfgs',random_state=0).fit(X_train,y_train)
mglearn.plots.plot_2d_separator(mlp,X_train,fill=True,alpha=.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
包含100个隐单元的神经网络在two_moons数据集上学到的决策边界
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=100,noise=0.25,random_state=3)
X_train,X_test,y_train,y_test=train_test_split(X,y,stratify=y,random_state=42)
mlp=MLPClassifier(solver='lbfgs',random_state=0,hidden_layer_sizes=[10])
mlp.fit(X_train,y_train)
mglearn.plots.plot_2d_separator(mlp,X_train,fill=True,alpha=.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
包含10个隐单元的神经网络在two_moons数据集上学到的决策边界
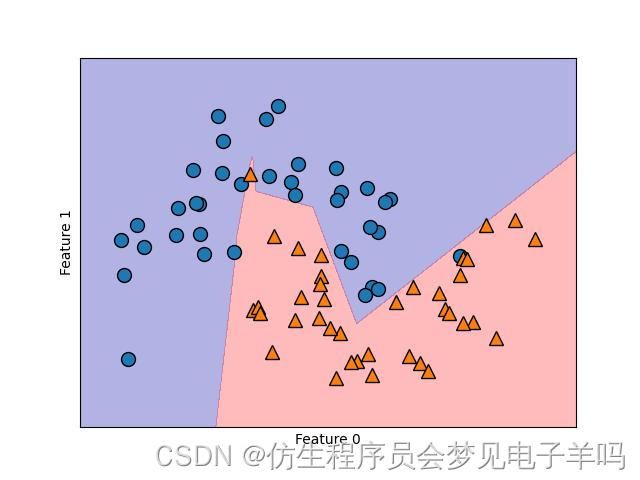
只有10个隐单元时,决策边界看起来更加参差不齐。默认的非线性是relu。如果使用单隐层,那么决策函数将由10个直线段组成。如果想要得到更加平滑的决策边界,可以添加更多的隐单元、添加第二个隐层或者使用tanh非线性。
#使用2个隐层,每个包含10个单元
mlp=MLPClassifier(solver='lbfgs',random_state=0,hidden_layer_sizes=[10,10])
mlp.fit(X_train,y_train)
mglearn.plots.plot_2d_separator(mlp,X_train,fill=True,alpha=.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
包含两个隐层、每个隐层包含10个隐单元的神经网络学到的决策边界(激活函数为relu)
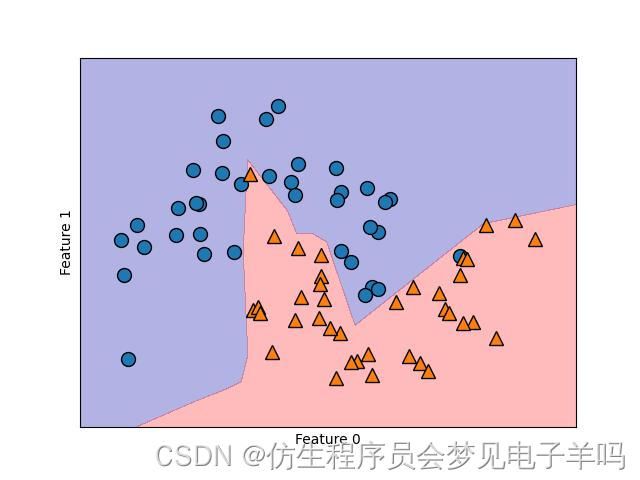
#使用2个隐层,每个包含10个单元,这次使用tanh非线性
mlp=MLPClassifier(solver='lbfgs',activation='tanh',random_state=0,hidden_layer_sizes=[10,10])
mlp.fit(X_train,y_train)
mglearn.plots.plot_2d_separator(mlp,X_train,fill=True,alpha=.3)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
包含两个隐层、每个隐层包含10个隐单元的神经网络学到的决策边界(激活函数为tanh)
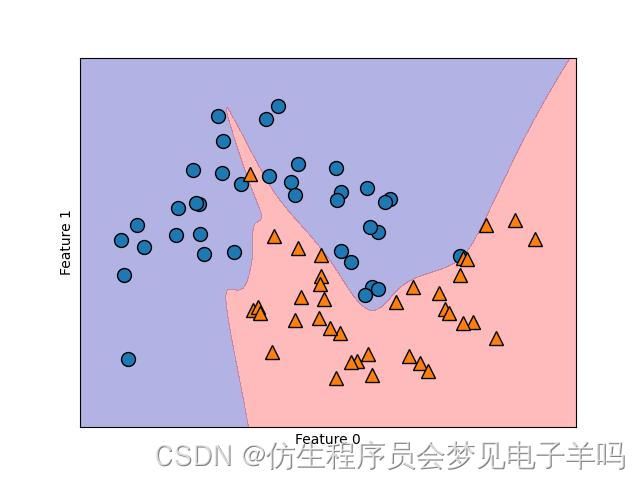
为了在现实世界的数据上进一步理解神经网络,我们将MLPClassifier应用在乳腺癌数据集上。
首先使用默认参数:
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
print("Cancer data per-feature maxima:\n{}".format(cancer.data.max(axis=0)))
Cancer data per-feature maxima:
[2.811e+01 3.928e+01 1.885e+02 2.501e+03 1.634e-01 3.454e-01 4.268e-01
2.012e-01 3.040e-01 9.744e-02 2.873e+00 4.885e+00 2.198e+01 5.422e+02
3.113e-02 1.354e-01 3.960e-01 5.279e-02 7.895e-02 2.984e-02 3.604e+01
4.954e+01 2.512e+02 4.254e+03 2.226e-01 1.058e+00 1.252e+00 2.910e-01
6.638e-01 2.075e-01]
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
mlp=MLPClassifier(random_state=42)
mlp.fit(X_train,y_train)
mean_on_train=X_train.mean(axis=0)
std_on_train=X_train.std(axis=0)
X_train_scaled=(X_train-mean_on_train)/std_on_train
X_test_scaled=(X_test-mean_on_train)/std_on_train
mlp=MLPClassifier(random_state=0)
mlp.fit(X_train_scaled,y_train)
mlp=MLPClassifier(max_iter=1000,random_state=0)
mlp.fit(X_train,y_train)
mlp=MLPClassifier(max_iter=1000,alpha=1,random_state=0)
mlp.fit(X_train,y_train)
plt.figure(figsize=(20,5))
plt.imshow(mlp.coefs_[0],interpolation='none',cmap='viridis')
plt.yticks(range(30),cancer.feature_names)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature ")
plt.colorbar()

分类器的不确定度估计
决策函数
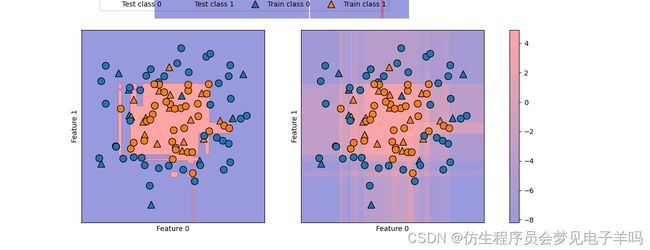
对于二分类的情况,decision_function返回值的形状是(n_samples,),为每个样本都返回一个浮点数:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import make_circles
X,y=make_circles(noise=0.25,factor=0.5,random_state=1)
y_named=np.array(["blue","red"])[y]
X_train,X_test,y_train_named,y_test_named,y_train,y_test=train_test_split(X,y_named,y,random_state=0)
gbrt=GradientBoostingClassifier(random_state=0)
gbrt.fit(X_train,y_train_named)
print("X_test.shape:{}".format(X_test.shape))
print("Decision function shape:{}".format(gbrt.decision_function(X_test).shape))
X_test.shape:(25, 2)
Decision function shape:(25,)
decision_function=gbrt.decision_function(X_test)
fig,axes=plt.subplots(1,2,figsize=(13,5))
mglearn.tools.plot_2d_separator(gbrt,X,ax=axes[0],alpha=.4,fill=True,cm=mglearn.cm2)
scores_image=mglearn.tools.plot_2d_scores(gbrt,X,ax=axes[1],alpha=.4,cm=mglearn.ReBl)
for ax in axes:
mglearn.discrete_scatter(X_test[:,0],X_test[:,1],y_test,markers='^',ax=ax)
mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train,markers='o',ax=ax)
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
cbar=plt.colorbar(scores_image,ax=axes.tolist())
axes[0].legend(["Test class 0","Test class 1","Train class 0","Train class 1"],ncol=4,loc=(.1,1.1))
梯度提升模型在一个二维玩具数据集上的决策边界(左)和决策函数(右)