NNDL 实验六 卷积神经网络(3)LeNet实现MNIST
目录
5.3 基于LeNet实现手写体数字识别实验
5.3.1 数据
5.3.2 模型构建
5.3.3 模型训练
5.3.4 模型评价
5.3.5 模型预测
使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)
5.3 基于LeNet实现手写体数字识别实验
5.3.1 数据
手写体数字识别是计算机视觉中最常用的图像分类任务,让计算机识别出给定图片中的手写体数字(0-9共10个数字)。由于手写体风格差异很大,因此手写体数字识别是具有一定难度的任务。
我们采用常用的手写数字识别数据集:MNIST数据集。MNIST数据集是计算机视觉领域的经典入门数据集,包含了60,000个训练样本和10,000个测试样本。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28×2828×28像素)。图5.12给出了部分样本的示例。

为了节省训练时间,本节选取MNIST数据集的一个子集进行后续实验,数据集的划分为:
- 训练集:1,000条样本
- 验证集:200条样本
- 测试集:200条样本
MNIST数据集分为train_set、dev_set和test_set三个数据集,每个数据集含两个列表分别存放了图片数据以及标签数据。比如train_set包含:
- 图片数据:[1 000, 784]的二维列表,包含1 000张图片。每张图片用一个长度为784的向量表示,内容是 28×2828×28 尺寸的像素灰度值(黑白图片)。
- 标签数据:[1 000, 1]的列表,表示这些图片对应的分类标签,即0~9之间的数字。
观察数据集分布情况,代码实现如下:
# 读取标签数据集
with open('./train-labels.idx1-ubyte', 'rb') as lbpath:
labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图片数据集
with open('./train-images.idx3-ubyte', 'rb') as imgpath:
images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)
train_images, train_labels = images[:1000], labels[:1000]
dev_images, dev_labels = images[1000:1200], labels[1000:1200]
test_images, test_labels = images[1200:1400], labels[1200:1400]
train_set, dev_set,test_set= [train_images, train_labels], [dev_images, dev_labels],[test_images, test_labels]
print('Length of train/dev/test set:{}/{}/{}'.format(len(train_set[0]), len(dev_set[0]),len(test_set[0]) ))Length of train/dev/test set:1000/200/200from PIL import Image
import matplotlib.pyplot as plt
image, label = train_set[0][0], train_set[1][0]
image, label = np.array(image).astype('float32'), int(label)
# 原始图像数据为长度784的行向量,需要调整为[28,28]大小的图像
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
print("The number in the picture is {}".format(label))
plt.figure(figsize=(5, 5))
plt.imshow(image)
plt.savefig('conv-number5.pdf')
The number in the picture is 5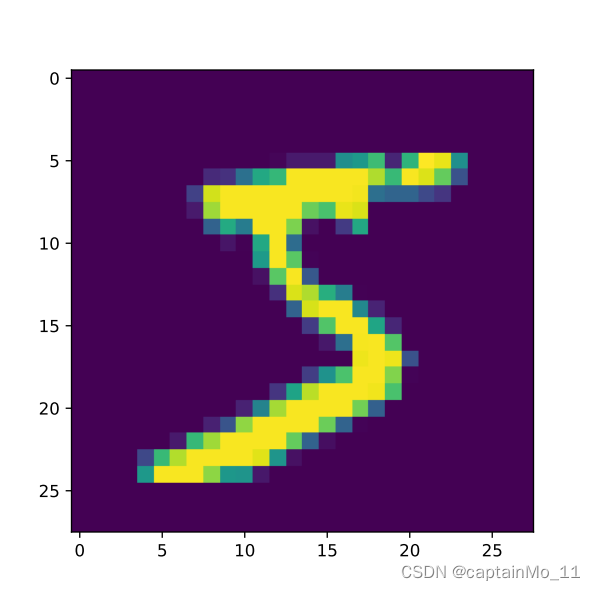
5.3.1.1 数据预处理
from torchvision.transforms import Compose, Resize, Normalize
# 数据预处理
transforms = Compose([Resize(32), Normalize(mean=[127.5], std=[127.5],)])
import random
import torch.utils.data as io
class MNIST_dataset(io.Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
return image, label
def __len__(self):
return len(self.dataset[0])
# 固定随机种子
random.seed(0)
# 加载 mnist 数据集
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
5.3.2 模型构建
这里的LeNet-5和原始版本有4点不同:
C3层没有使用连接表来减少卷积数量。
汇聚层使用了简单的平均汇聚,没有引入权重和偏置参数以及非线性激活函数。
卷积层的激活函数使用ReLU函数。
最后的输出层为一个全连接线性层。
网络共有7层,包含3个卷积层、2个汇聚层以及2个全连接层的简单卷积神经网络接,受输入图像大小为32×32=1024,输出对应10个类别的得分。
1.测试LeNet-5模型,构造一个形状为 [1,1,32,32]的输入数据送入网络,观察每一层特征图的形状变化。
class Model_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Model_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5×5
self.conv1 = Conv2D(in_channels=in_channels, out_channels=6, kernel_size=5,)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool2 = Pool2D(size=(2,2), mode='max', stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5×5,步长为1
self.conv3 = Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, )
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool4 = Pool2D(size=(2,2), mode='avg', stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5×5
self.conv5 = Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1,)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(120, 84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(84, num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, axis=[2,3])
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
# 这里用np.random创建一个随机数组作为输入数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,查看LeNet中所包含的子层
#print(model.state_dict().keys())
model_modules = [x for x in model.modules()]
print(model_modules[1:])
x = torch.tensor(inputs)
for item in model_modules[1:]:
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
#print(len(list(item.parameters())))
try:
x = item(x)
except:
# 如果是最后一个卷积层输出,需要展平后才可以送入全连接层
x = torch.reshape(x, [x.shape[0], -1])
x = item(x)
if len(list(item.parameters()))==2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item, x.shape, list(item.parameters())[0].shape,
list(item.parameters())[1].shape)
else:
# 汇聚层没有参数
print(item, x.shape)[Conv2D(), Pool2D(), Conv2D(), Pool2D(), Conv2D(), Linear(in_features=120, out_features=84, bias=True), Linear(in_features=84, out_features=10, bias=True)]
Conv2D() torch.Size([1, 6, 28, 28]) torch.Size([6, 1, 5, 5]) torch.Size([6, 1])
Pool2D() torch.Size([1, 6, 14, 14])
Conv2D() torch.Size([1, 16, 10, 10]) torch.Size([16, 6, 5, 5]) torch.Size([16, 1])
Pool2D() torch.Size([1, 16, 5, 5])
Conv2D() torch.Size([1, 120, 1, 1]) torch.Size([120, 16, 5, 5]) torch.Size([120, 1])
Linear(in_features=120, out_features=84, bias=True) torch.Size([1, 84]) torch.Size([84, 120]) torch.Size([84])
Linear(in_features=84, out_features=10, bias=True) torch.Size([1, 10]) torch.Size([10, 84]) torch.Size([10])2.
使用自定义算子,构建LeNet-5模型
自定义的Conv2D和Pool2D算子中包含多个for循环,所以运算速度比较慢。
使用pytorch中的相应算子,构建LeNet-5模型
torch.nn.Conv2d();torch.nn.MaxPool2d();torch.nn.avg_pool2d()
class Model_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Model_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5×5
self.conv1 = Conv2D(in_channels=in_channels, out_channels=6, kernel_size=5,)
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool2 = Pool2D(size=(2,2), mode='max', stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5×5,步长为1
self.conv3 = Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, )
# 汇聚层:汇聚窗口为2×2,步长为2
self.pool4 = Pool2D(size=(2,2), mode='avg', stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5×5
self.conv5 = Conv2D(in_channels=16, out_channels=120, kernel_size=5, stride=1,)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(120, 84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(84, num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, axis=[2,3])
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return outputclass Paddle_LeNet(nn.Module):
def __init__(self, in_channels, num_classes=10):
super(Paddle_LeNet, self).__init__()
# 卷积层:输出通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为6,输出通道数为16,卷积核大小为5*5
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 汇聚层:汇聚窗口为2*2,步长为2
self.pool4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 卷积层:输入通道数为16,输出通道数为120,卷积核大小为5*5
self.conv5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 全连接层:输入神经元为120,输出神经元为84
self.linear6 = nn.Linear(in_features=120, out_features=84)
# 全连接层:输入神经元为84,输出神经元为类别数
self.linear7 = nn.Linear(in_features=84, out_features=num_classes)
def forward(self, x):
# C1:卷积层+激活函数
output = F.relu(self.conv1(x))
# S2:汇聚层
output = self.pool2(output)
# C3:卷积层+激活函数
output = F.relu(self.conv3(output))
# S4:汇聚层
output = self.pool4(output)
# C5:卷积层+激活函数
output = F.relu(self.conv5(output))
# 输入层将数据拉平[B,C,H,W] -> [B,CxHxW]
output = torch.squeeze(output, 2)
output = torch.squeeze(output, 2)
# F6:全连接层
output = F.relu(self.linear6(output))
# F7:全连接层
output = self.linear7(output)
return output
3.测试两个网络的运算速度。
import time
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 创建Paddle_LeNet类的实例,指定模型名称和分类的类别数目
paddle_model = Paddle_LeNet(in_channels=1, num_classes=10)
# 计算Model_LeNet类的运算速度
model_time = 0
for i in range(60):
strat_time = time.time()
out = model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
model_time += (end_time - strat_time)
avg_model_time = model_time / 50
print('Model_LeNet speed:', avg_model_time, 's')
# 计算Paddle_LeNet类的运算速度
paddle_model_time = 0
for i in range(60):
strat_time = time.time()
paddle_out = paddle_model(x)
end_time = time.time()
# 预热10次运算,不计入最终速度统计
if i < 10:
continue
paddle_model_time += (end_time - strat_time)
avg_paddle_model_time = paddle_model_time / 50
print('Paddle_LeNet speed:', avg_paddle_model_time, 's')
Model_LeNet speed: 0.7908068466186523 s
Paddle_LeNet speed: 0.0005187749862670899 s直接导入库要比自定义的算子快很多。
4.令两个网络加载同样的权重,测试一下两个网络的输出结果是否一致。
# 这里用np.random创建一个随机数组作为测试数据
inputs = np.random.randn(*[1,1,32,32])
inputs = inputs.astype('float32')
x = torch.tensor(inputs)
# 创建Model_LeNet类的实例,指定模型名称和分类的类别数目
model = Model_LeNet(in_channels=1, num_classes=10)
# 获取网络的权重
params = model.state_dict()
# 自定义Conv2D算子的bias参数形状为[out_channels, 1]
# paddle API中Conv2D算子的bias参数形状为[out_channels]
# 需要进行调整后才可以赋值
for key in params:
if 'bias' in key:
params[key] = params[key].squeeze()
# 创建Paddle_LeNet类的实例,指定模型名称和分类的类别数目
paddle_model = Paddle_LeNet(in_channels=1, num_classes=10)
# 将Model_LeNet的权重参数赋予给Paddle_LeNet模型,保持两者一致
paddle_model.load_state_dict(params)
# 打印结果保留小数点后6位
torch.set_printoptions(6)
# 计算Model_LeNet的结果
output = model(x)
print('Model_LeNet output: ', output)
# 计算Paddle_LeNet的结果
paddle_output = paddle_model(x)
print('Paddle_LeNet output: ', paddle_output)
Model_LeNet output: tensor([[109042.375000, 826.511658, 19116.425781, 8992.041016,
26914.462891, 4552.554199, -41347.921875, 128910.500000,
19684.457031, 14371.383789]], grad_fn=)
Paddle_LeNet output: tensor([[109042.328125, 826.501892, 19116.421875, 8992.035156,
26914.462891, 4552.554199, -41347.914062, 128910.453125,
19684.453125, 14371.379883]], grad_fn=)
结果近似相同。
5.统计LeNet-5模型的参数量和计算量。
在飞桨中,还可以使用paddle.flopsAPI自动统计计算量。pytorch可以么?
from torchsummary import summary
summary(paddle_model,input_size=(1,32,32))
5.3.3 模型训练
使用交叉熵损失函数,并用随机梯度下降法作为优化器来训练LeNet-5网络。
用RunnerV3在训练集上训练5个epoch,并保存准确率最高的模型作为最佳模型。
# 学习率大小
lr = 0.3
# 批次大小
batch_size = 64
# 加载数据
train_loader = io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = io.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = io.DataLoader(test_dataset, batch_size=batch_size)
# 定义LeNet网络
# 自定义算子实现的LeNet-5
#model = Model_LeNet(in_channels=1, num_classes=10)
# 飞桨API实现的LeNet-5
model = Paddle_LeNet(in_channels=1, num_classes=10)
# 定义优化器
optimizer = opt.SGD(model.parameters(),lr, )
# 定义损失函数
loss_fn = F.cross_entropy
# 定义评价指标
metric = metric.Accuracy(is_logist=True)
# 实例化 RunnerV3 类,并传入训练配置。
runner = runnerV3.RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader, num_epochs=5, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
# 加载最优模型
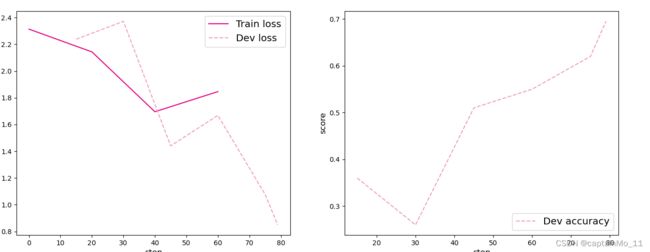
runner.load_model('best_model.pdparams')[Train] epoch: 0/5, step: 0/80, loss: 2.31379
[Train] epoch: 0/5, step: 15/80, loss: 2.25382
D:\pythonProject2\nndl\metric.py:55: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
batch_correct = torch.sum(torch.tensor(preds==labels, dtype=torch.float32)).numpy()
[Evaluate] dev score: 0.36000, dev loss: 2.23824
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.36000
[Train] epoch: 1/5, step: 30/80, loss: 2.41069
[Evaluate] dev score: 0.26000, dev loss: 2.37212
[Train] epoch: 2/5, step: 45/80, loss: 1.55699
[Evaluate] dev score: 0.51000, dev loss: 1.44048
[Evaluate] best accuracy performence has been updated: 0.36000 --> 0.51000
[Train] epoch: 3/5, step: 60/80, loss: 1.84617
[Evaluate] dev score: 0.55000, dev loss: 1.66818
[Evaluate] best accuracy performence has been updated: 0.51000 --> 0.55000
[Train] epoch: 4/5, step: 75/80, loss: 0.92327
[Evaluate] dev score: 0.62000, dev loss: 1.07769
[Evaluate] best accuracy performence has been updated: 0.55000 --> 0.62000
[Evaluate] dev score: 0.69500, dev loss: 0.84913
[Evaluate] best accuracy performence has been updated: 0.62000 --> 0.69500
[Train] Training done!
5.3.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失变化情况。
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))[Test] accuracy/loss: 0.7100/0.8367
5.3.5 模型预测
同样地,我们也可以使用保存好的模型,对测试集中的某一个数据进行模型预测,观察模型效果。
# 获取测试集中第一条数
X, label = next(iter(test_loader))
logits = runner.predict(X)
# 多分类,使用softmax计算预测概率
pred = F.softmax(logits,dim=1)
print(pred.shape)
# 获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
print(pred_class)
label = label[2].numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
# 可视化图片
plt.figure(figsize=(2, 2))
image, label = test_set[0][2], test_set[1][2]
image= np.array(image).astype('float32')
image = np.reshape(image, [28,28])
image = Image.fromarray(image.astype('uint8'), mode='L')
plt.imshow(image)
plt.savefig('cnn-number2.pdf')
6
The true category is 6 and the predicted category is 6使用前馈神经网络实现MNIST识别,与LeNet效果对比。(选做)
两种网络训练50轮:
前馈神经网络源代码:
import struct
import numpy as np
import torch.optim as opt
from nndl import runnerV3, metric
import random
import torch.utils.data as io
import torch.nn.functional as F
import torch.nn as nn
import torch
from PIL import Image
import matplotlib.pyplot as plt
from torchvision.transforms import Compose, Resize, Normalize
import torchvision.transforms as transforms
import torchmetrics
from nndl.dataset import load_data
class Accuracy(torchmetrics.Metric):
def __init__(self,is_logist=True):
"""
输入:
- is_logist: outputs是logist还是激活后的值
"""
# 用于统计正确的样本个数
super().__init__()
self.add_state("num_correct",torch.tensor(0))
# 用于统计样本的总数
self.add_state("num_count", torch.tensor(0))
#self.add_state("is_logist", is_logist)
def update(self, outputs, labels):
"""
输入:
- outputs: 预测值, shape=[N,class_num]
- labels: 标签值, shape=[N,1]
"""
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, -1)
if self.is_logist:
# logist判断是否大于0
p = []
for i in range(len(outputs)):
if outputs[i] > 0.:
p.append([1])
else:
p.append([0])
preds = torch.tensor(p)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
p = []
for i in range(len(outputs)):
if outputs[i] > 0.5:
p.append([1])
else:
p.append([0])
preds = torch.tensor(p)
else:
# 多分类时,使用'paddle.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).int()
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, -1)
batch_correct = torch.sum(torch.eq(preds, labels).float()).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def compute(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
class Model_MLP_L2_V3(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Model_MLP_L2_V3, self).__init__()
# 构建第一个全连接层
self.fc1 = nn.Linear(
input_size,
hidden_size,
)
nn.init.normal_(self.fc1.weight, mean=0, std=0.01)
nn.init.constant_(self.fc1.bias,1.0)
# 构建第二全连接层
self.fc2 = nn.Linear(
hidden_size,
output_size,
)
nn.init.normal_(self.fc2.weight, mean=0, std=0.01)
nn.init.constant_(self.fc2.bias, 1.0)
# 定义网络使用的激活函数
self.act = nn.Sigmoid()
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
return outputs
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.compute()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'paddle.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
# 数据预处理
transforms = Compose([transforms.ToTensor(), Normalize(mean=[0.5], std=[0.5], )])
class IrisDataset(io.Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
# 调用第三章中的数据读取函数,其中不需要将标签转成one-hot类型
X, y = load_data(shuffle=True)
if mode == 'train':
self.X, self.y = X[:num_train], y[:num_train]
elif mode == 'dev':
self.X, self.y = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.X, self.y = X[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
def __len__(self):
return len(self.y)
class MNIST_dataset(io.Dataset):
def __init__(self, dataset, transforms, mode='train'):
self.mode = mode
self.transforms =transforms
self.dataset = dataset
def __getitem__(self, idx):
# 获取图像和标签
image, label = self.dataset[0][idx], self.dataset[1][idx]
image, label = np.array(image).astype('float32'), int(label)
image = Image.fromarray(image.astype('uint8'), mode='L')
image = self.transforms(image)
image = torch.squeeze(image, 0)
image = torch.squeeze(image, 1)
return image, label
def __len__(self):
return len(self.dataset[0])
# 读取标签数据集
with open('./train-labels.idx1-ubyte', 'rb') as lbpath:
labels_magic, labels_num = struct.unpack('>II', lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
# 读取图片数据集
with open('./train-images.idx3-ubyte', 'rb') as imgpath:
images_magic, images_num, rows, cols = struct.unpack('>IIII', imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(images_num, rows * cols)
train_images, train_labels = images[:1000], labels[:1000]
dev_images, dev_labels = images[1000:1200], labels[1000:1200]
test_images, test_labels = images[1200:1400], labels[1200:1400]
train_set, dev_set,test_set= [train_images, train_labels], [dev_images, dev_labels],[test_images, test_labels]
print("train_set[0].shape::",train_set[0].shape)
train_dataset = MNIST_dataset(dataset=train_set, transforms=transforms, mode='train')
test_dataset = MNIST_dataset(dataset=test_set, transforms=transforms, mode='test')
dev_dataset = MNIST_dataset(dataset=dev_set, transforms=transforms, mode='dev')
print("train_dataset:",next(iter(train_dataset))[0].shape)
batch_size = 64
train_loader = io.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = io.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = io.DataLoader(test_dataset, batch_size=batch_size)
print("test_loader:",next(iter(test_loader))[0].shape)
lr = 0.2
fnn_model = Model_MLP_L2_V3(input_size=784, output_size=10, hidden_size=6)
# 定义网络
model = fnn_model
# 定义优化器
optimizer = opt.SGD(model.parameters(),lr, )
# 定义损失函数。softmax+交叉熵
loss_fn = F.cross_entropy
metric = Accuracy(is_logist=True)
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 15
eval_steps = 15
runner.train(train_loader, dev_loader,
num_epochs=50, log_steps=log_steps, eval_steps = eval_steps,
save_path="best_model.pdparams")
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
from nndl import Plot_training_loss_acc
Plot_training_loss_acc.plot_training_loss_acc(runner, 'cnn-loss1.pdf')
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))结果如下:
[Train] Training done!
[Test] accuracy/loss: 0.7700/0.7905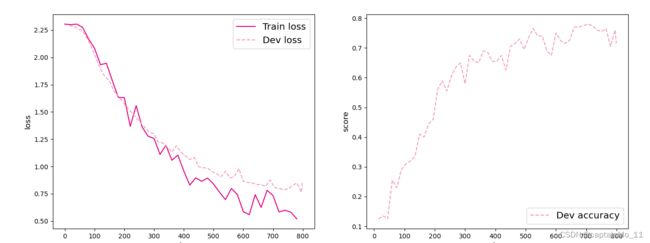
卷积神经网络结果如下:
[Evaluate] dev score: 0.91500, dev loss: 0.51545
[Train] Training done!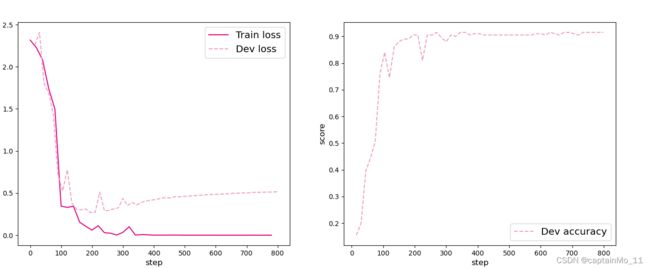 由结果可知,卷进神经网络准确率高达90%以上,而前馈神经网络只有80%左右,同时卷积神经网络的计算量要小于前馈神经网络。
由结果可知,卷进神经网络准确率高达90%以上,而前馈神经网络只有80%左右,同时卷积神经网络的计算量要小于前馈神经网络。
所以卷积神经网络有明显的优势。
可视化LeNet中的部分特征图和卷积核,谈谈自己的看法。(选做)
原图:
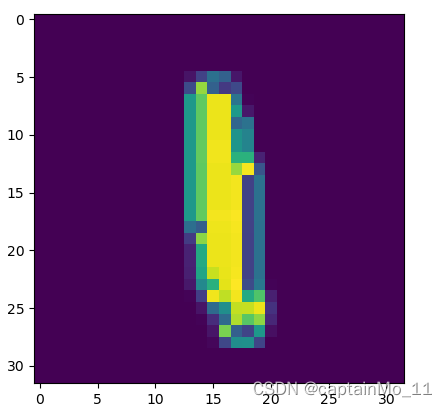
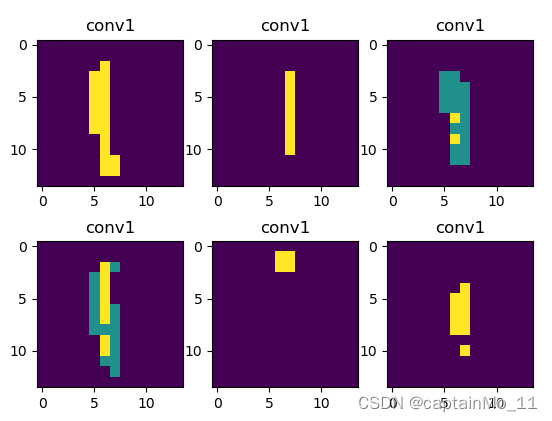
第一层卷积的部分特征图:
第二层卷积的部分特征图
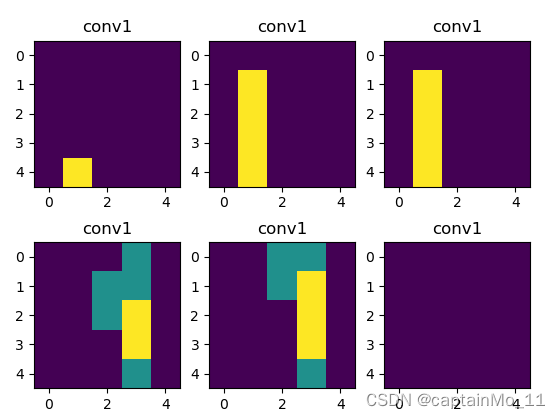
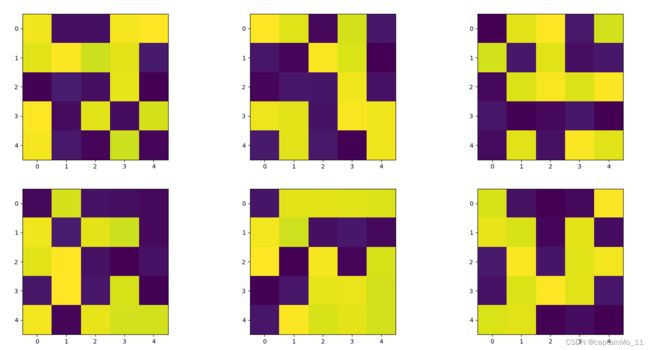
第一层部分卷积核
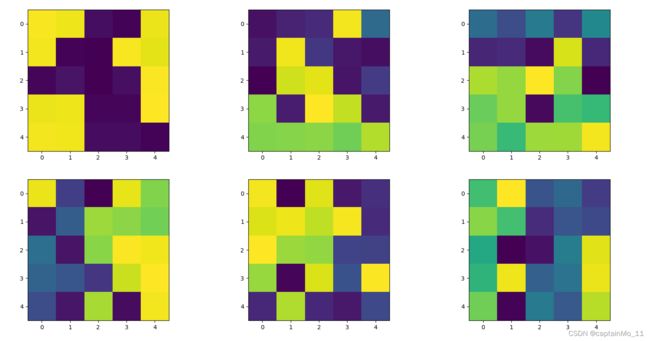
第二层卷积核:
第三次部分卷积核:
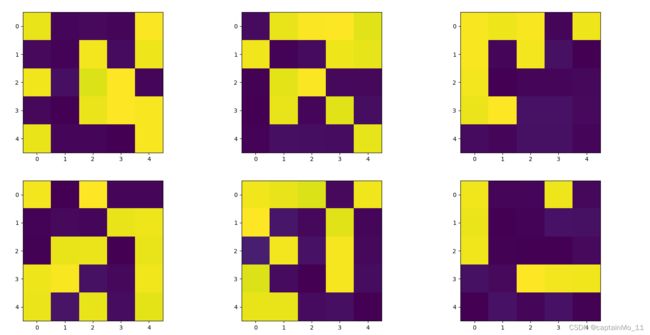
随着层数的加深,层所提取的特征变得越来越抽象,关于特定输入的信息越来越少,而关于目标的信息则越来越多,深度神经网络可以有效地作为信息整流管道(information distillation pipeline),输入原始数据,反复对其进行变换,将无关信息过滤掉,并放大和细化有用的信息(比如与图像类别有关的信息)。
浅层特征更多的倾向于对图像边缘的检测,检测到的内容全面,同时也会有关键信息提取出来
随着层次的加深,特征图也越来抽象
越深的层次,空白区域越多,说明卷积核没有得到它们所需要的特征