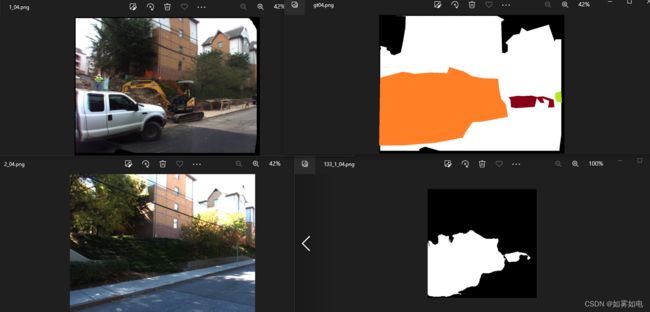
IDET变化检测模型
这里只跑两类:0不变,1变化。下面贴出来的代码都是有改动的,其它的代码自己去原始链接里下载。
原始链接:
GitHub - rfww/IDET: IDET: Iterative Difference-Enhanced Transformers for High-Quality ChangeDetectionIDET: Iterative Difference-Enhanced Transformers for High-Quality ChangeDetection - GitHub - rfww/IDET: IDET: Iterative Difference-Enhanced Transformers for High-Quality ChangeDetection https://github.com/rfww/IDET
https://github.com/rfww/IDET
1数据准备
使用的数据集是CMU
链接:https://pan.baidu.com/s/1scNalGm9bnzME5TVw7ZNRQ
提取码:1plz
--来自百度网盘超级会员V6的分享
公共数据集CMU解压以后数据的格式

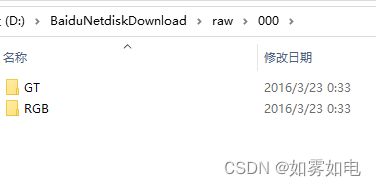

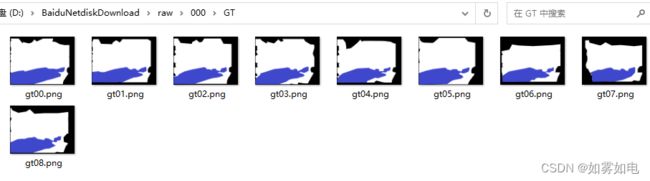
数据预处理,主要是把RGB和GT的路径按照IDET的数据加载函数要求写入到txt,利用下面的脚本生成,其中data_root就是数据的根目录,数据随便放哪里都行,因为生成的txt记录的是全路径
proTxt.py
import os
import random
data_root = 'D:/BaiduNetdiskDownload/raw/'
files_list = os.listdir(data_root)
all_datas = []
f1_train = open('./data_CMU/train/image.txt', 'w+')
f2_train = open('./data_CMU/train/image2.txt', 'w+')
f3_train = open('./data_CMU/train/label.txt', 'w+')
f1_val = open('./data_CMU/val/image.txt', 'w+')
f2_val = open('./data_CMU/val/image2.txt', 'w+')
f3_val = open('./data_CMU/val/label.txt', 'w+')
f1_test = open('./data_CMU/test/image.txt', 'w+')
f2_test = open('./data_CMU/test/image2.txt', 'w+')
f3_test = open('./data_CMU/test/label.txt', 'w+')
count = 0
for ff in files_list:
file_1 = os.path.join(data_root, ff)
img_path = os.path.join(file_1, 'RGB')
lab_path = os.path.join(file_1, 'GT')
im_list = os.listdir(img_path)
if 'Thumbs.db' in im_list:
im_list.remove('Thumbs.db')
# im_list.pop(-1)
num_rgb = len(im_list) / 2
for i in range(int(num_rgb)):
if len(str(i)) == 1:
im_name_1 = '1_0' + str(i)
im_name_2 = '2_0' + str(i)
gt_name = 'gt0' + str(i)
elif len(str(i)) == 2:
im_name_1 = '1_' + str(i)
im_name_2 = '2_' + str(i)
gt_name = 'gt' + str(i)
if count % 50 == 0:
im_path1 = data_root + ff + '/RGB/' + im_name_1 + '.png' + '\n'
im_path2 = data_root + ff + '/RGB/' + im_name_2 + '.png' + '\n'
lab_path = data_root + ff + '/GT/' + gt_name + '.png' + '\n'
f1_val.write(im_path1)
f2_val.write(im_path2)
f3_val.write(lab_path)
elif count % 80 == 0:
im_path1 = data_root + ff + '/RGB/' + im_name_1 + '.png' + '\n'
im_path2 = data_root + ff + '/RGB/' + im_name_2 + '.png' + '\n'
lab_path = data_root + ff + '/GT/' + gt_name + '.png' + '\n'
f1_test.write(im_path1)
f2_test.write(im_path2)
f3_test.write(lab_path)
else:
im_path1 = data_root + ff + '/RGB/' + im_name_1 + '.png' + '\n'
im_path2 = data_root + ff + '/RGB/' + im_name_2 + '.png' + '\n'
lab_path = data_root + ff + '/GT/' + gt_name + '.png' + '\n'
f1_train.write(im_path1)
f2_train.write(im_path2)
f3_train.write(lab_path)
count += 1
f1_train.close()
f2_train.close()
f3_train.close()
f1_val.close()
f2_val.close()
f3_val.close()
f1_test.close()
f2_test.close()
f3_test.close()
生成的路径放到项目的data_CMU

2.修改数据加载函数
由于这里只跑变与不变两类,所以数据加载的时候需要把原来rgb的标签变为0和1,下面我修改了数据加载函数./dataloader/dataset.py,另外还增加了预测需要的InferenceData函数,这个函数不需要加载标签,也就是推理用的函数而不是验证用。
import cv2
import numpy as np
import os
import torch
from PIL import Image
from torch.utils.data import Dataset
from utils.read_image import read_image
EXTENSIONS = ['.jpg', '.png','.JPG','.PNG']
def load_image(file):
return Image.open(file)
def is_image(filename):
return any(filename.endswith(ext) for ext in EXTENSIONS)
def image_path(root, basename, extension):
return os.path.join(root, '{}{}'.format(basename,extension))
def image_path_city(root, name):
return os.path.join(root, '{}'.format(name))
def image_basename(filename):
return os.path.basename(os.path.splitext(filename)[0])
class TrainData(Dataset):
def __init__(self, imagepath=None, imagepath2=None, labelpath=None, transform=None):
# make sure label match with image
self.transform = transform
assert os.path.exists(imagepath), "{} not exists !".format(imagepath)
assert os.path.exists(imagepath2), "{} not exists !".format(imagepath2)
assert os.path.exists(labelpath), "{} not exists !".format(labelpath)
image = read_image(imagepath)
image2 = read_image(imagepath2)
label = read_image(labelpath)
self.train_set = (
image,
image2,
label
)
def __getitem__(self, index):
filename = self.train_set[0][index]
filename2 = self.train_set[1][index]
filenameGt = self.train_set[2][index]
# roiname = os.path.join(os.path.split(filename)[0].replace("input", ""), "ROI.bmp")
# print(filename)
with open(filename, 'rb') as f:
image = load_image(f).convert('RGB')
with open(filename2, 'rb') as f:
image2 = load_image(f).convert('RGB')
with open(filenameGt, 'rb') as f:
# label = load_image(f).convert('P')
label0 = load_image(f)
lab = label0.convert('L').copy()
lab1 = np.asarray(lab).copy()
lab1[lab1 == 255] = 0
lab1[lab1 > 0] = 1
label = Image.fromarray(np.uint8(lab1))
# with open(roiname, 'rb') as f:
# roi = load_image(f).convert('1')
# roi = Image.fromarray(cv2.imread(roiname))
if self.transform is not None:#########################
image, image2, label = self.transform(image, image2, label)
return image, image2, label
def __len__(self):
return len(self.train_set[0])
class TestData(Dataset):
def __init__(self, imagepath=None, imagepath2=None, labelpath=None, transform=None):
self.transform = transform
assert os.path.exists(imagepath), "{} not exists !".format(imagepath)
assert os.path.exists(imagepath2), "{} not exists !".format(imagepath2)
assert os.path.exists(labelpath), "{} not exists !".format(labelpath)
image = read_image(imagepath)
image2 = read_image(imagepath2)
label = read_image(labelpath)
self.test_set = (
image,
image2,
label
)
print("Length of test data is {}".format(len(self.test_set[0])))
def __getitem__(self, index):
filename = self.test_set[0][index]
filename2 = self.test_set[1][index]
filenameGt = self.test_set[2][index]
with open(filename, 'rb') as f: # advance
image = load_image(f).convert('RGB')
with open(filename2,'rb') as f:
image2 = load_image(f).convert('RGB')
with open(filenameGt, 'rb') as f:
# label = load_image(f).convert('P')
label0 = load_image(f)
lab = label0.convert('L').copy()
lab1 = np.asarray(lab).copy()
lab1[lab1 == 255] = 0
lab1[lab1 > 0] = 1
label = Image.fromarray(np.uint8(lab1))
# with open(roiname, 'rb') as f: # roi
# roi = load_image(f).convert('1')
# roi = Image.fromarray(cv2.imread(roiname))
if self.transform is not None:
image_tensor, image_tensor2, label_tensor, img, img2 = self.transform(image, image2, label)
return (image_tensor, image_tensor2, label_tensor,filenameGt, np.array(img),np.array(img2))
return np.array(image), np.array(image2),filenameGt
def __len__(self):
return len(self.test_set[0])
class InferenceData(Dataset):
def __init__(self, imagepath=None, imagepath2=None, transform=None):
self.transform = transform
assert os.path.exists(imagepath), "{} not exists !".format(imagepath)
assert os.path.exists(imagepath2), "{} not exists !".format(imagepath2)
image = read_image(imagepath)
image2 = read_image(imagepath2)
self.test_set = (
image,
image2
)
print("Length of test data is {}".format(len(self.test_set[0])))
def __getitem__(self, index):
filename = self.test_set[0][index]
filename2 = self.test_set[1][index]
image_name = filename.split("/")[-1]
folder_name = filename.split("/")[-3]
with open(filename, 'rb') as f: # advance
image = load_image(f).convert('RGB')
with open(filename2, 'rb') as f:
image2 = load_image(f).convert('RGB')
if self.transform is not None:
image_tensor, image_tensor2 = self.transform(image, image2)
return image_tensor, image_tensor2, folder_name + '_' + image_name
return np.array(image), np.array(image2), folder_name + '_' + image_name
def __len__(self):
return len(self.test_set[0])
3.训练
增加了函数iou_pytorch,用于训练的时候提供iou参考。
import os
import time
import math
import torch
import numpy as np
from torchvision import models
from eval import *
import torch.nn as nn
from utils import evalIoU
from models import get_model
from torch.autograd import Variable
from dataloader.dataset import TrainData
from torch.utils.data import DataLoader
from dataloader.transform import MyTransform
from torchvision.transforms import ToPILImage
from configs.train_options import TrainOptions
from torch.optim import SGD, Adam, lr_scheduler
from criterion.criterion import CrossEntropyLoss2d
import argparse
from tqdm import tqdm
NUM_CHANNELS = 3
def iou_pytorch(outputs: torch.Tensor, labels: torch.Tensor, SMOOTH=1e-6):
# You can comment out this line if you are passing tensors of equal shape
# But if you are passing output from UNet or something it will most probably
# be with the BATCH x 1 x H x W shape
outputs = outputs.squeeze(1) # BATCH x 1 x H x W => BATCH x H x W
intersection = (outputs & labels).float().sum((1, 2)) # Will be zero if Truth=0 or Prediction=0
union = (outputs | labels).float().sum((1, 2)) # Will be zzero if both are 0
iou = (intersection + SMOOTH) / (union + SMOOTH) # We smooth our devision to avoid 0/0
thresholded = torch.clamp(20 * (iou - 0.5), 0, 10).ceil() / 10 # This is equal to comparing with thresolds
return thresholded.mean() # Or thresholded.mean() if you are interested in average across the batch
def get_loader(args):
imagepath_train = os.path.join(args.datadir, 'train/image.txt')
imagepath_train2 = os.path.join(args.datadir, 'train/image2.txt')
labelpath_train = os.path.join(args.datadir, 'train/label.txt')
#train_transform = MyTransform(reshape_size=(256, 256), crop_size=(256, 256), # remote sensing scencs
train_transform = MyTransform(reshape_size=(320, 320), crop_size=(320, 320), # street views
augment=True) # data transform for training set with data augmentation, including resize, crop, flip and so on
dataset_train = TrainData(imagepath_train, imagepath_train2, labelpath_train, train_transform) # DataSet
loader = DataLoader(dataset_train, num_workers=args.num_workers, batch_size=args.batch_size, shuffle=True, drop_last=True)
return loader
def train(args, model):
NUM_CLASSES = args.num_classes # pascal=21, cityscapes=20
savedir = args.savedir
weight = torch.ones(NUM_CLASSES)
loader = get_loader(args)
if args.cuda:
criterion = CrossEntropyLoss2d(weight).cuda()
else:
criterion = CrossEntropyLoss2d(weight)
automated_log_path = savedir + "/automated_log.txt"
if (not os.path.exists(automated_log_path)): # dont add first line if it exists
with open(automated_log_path, "a") as myfile:
myfile.write("Epoch\t\tTrain-loss\t\tTrain-IoU\t\tlearningRate")
paras = dict(model.named_parameters())
paras_new = []
for k, v in paras.items():
if 'bias' in k:
if 'dec' in k:
paras_new += [{'params': [v], 'lr': 0.02 * args.lr, 'weight_decay': 0}]
else:
paras_new += [{'params': [v], 'lr': 0.2 * args.lr, 'weight_decay': 0}]
else:
if 'dec' in k:
paras_new += [{'params': [v], 'lr': 0.01 * args.lr, 'weight_decay': 0.00004}]
else:
paras_new += [{'params': [v], 'lr': 0.1 * args.lr, 'weight_decay': 0.00004}]
optimizer = Adam(paras_new, args.lr, (0.9, 0.999), eps=1e-08, weight_decay=1e-4)
lambda1 = lambda epoch: pow((1 - ((epoch - 1) / args.num_epochs)), 0.9)
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) # learning rate changed every epoch
start_epoch = 1
for epoch in range(start_epoch, args.num_epochs + 1):
tbar = tqdm(loader, desc='\r')
scheduler.step(epoch)
epoch_loss = []
time_train = []
# confMatrix = evalIoU.generateMatrixTrainId(evalIoU.args)
epoch_iou = []
usedLr = 0
# for param_group in optimizer.param_groups:
for param_group in optimizer.param_groups:
usedLr = float(param_group['lr'])
model.cuda().train()
for step, (images, images2, labels) in enumerate(tbar):
start_time = time.time()
if args.cuda:
images = images.cuda()
images2 = images2.cuda()
labels = labels.cuda()
inputs = Variable(images)
inputs2 = Variable(images2)
targets = Variable(labels)
p1, p2, p3, p4, p5, p6, p7, p8, p9, p10, p11, p12 = model(inputs, inputs2)
loss = criterion(p1, targets[:, 0])
loss1 = criterion(p2, targets[:, 0])
loss2 = criterion(p3, targets[:, 0])
loss3 = criterion(p4, targets[:, 0])
loss4 = criterion(p5, targets[:, 0])
loss5 = criterion(p6, targets[:, 0])
loss6 = criterion(p7, targets[:, 0])
loss7 = criterion(p8, targets[:, 0])
loss8 = criterion(p9, targets[:, 0])
loss9 = criterion(p10, targets[:, 0])
loss10= criterion(p11, targets[:, 0])
loss11= criterion(p12, targets[:, 0])
p7 = torch.argmax(p7, dim=1)
iter_iou = iou_pytorch(p7, targets)
loss += loss1+loss2+loss3+loss4+loss5+loss6+loss7+loss8+loss9+loss10+loss11
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss.append(loss.item())
epoch_iou.append(iter_iou.item())
time_train.append(time.time() - start_time)
if args.steps_loss > 0 and step % args.steps_loss == 0:
average = sum(epoch_loss) / len(epoch_loss)
localtime = time.asctime(time.localtime(time.time()))
tbar.set_description('loss: %.8f | epoch: %d | step: %d | Time: %s' % (average, epoch, step, str(localtime)))
average_epoch_loss_train = sum(epoch_loss) / len(epoch_loss)
# iouAvgStr, iouTrain, classScoreList = cal_iou(evalIoU, confMatrix)
iouTrain = sum(epoch_iou) / len(epoch_iou)
if epoch % args.epoch_save == 0:
torch.save(model.state_dict(), '{}_{}.pth'.format(os.path.join(args.savedir, args.model), str(epoch)))
# save log
with open(automated_log_path, "a") as myfile:
myfile.write("\n%d\t\t%.4f\t\t%.4f\t\t%.8f" % (epoch, average_epoch_loss_train, iouTrain, usedLr))
return ''
def main(args):
'''
Train the model and record training options.
'''
savedir = '{}'.format(args.savedir)
modeltxtpath = os.path.join(savedir, 'model.txt')
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device("cuda")
#torch.backends.cudnn.enabled = False
if not os.path.exists(savedir):
os.makedirs(savedir)
with open(savedir + '/opts.txt', "w") as myfile: # record options
myfile.write(str(args))
# initialize the network
model = get_model(args) # load model
decoders = list(models.vgg16_bn(pretrained=True).features.children())
model.dec1 = nn.Sequential(*decoders[:7])
model.dec2 = nn.Sequential(*decoders[7:14])
model.dec3 = nn.Sequential(*decoders[14:24])
model.dec4 = nn.Sequential(*decoders[24:34])
model.dec5 = nn.Sequential(*decoders[34:44])
#checkpoint = torch.load(args.pretrained)
#model.load_state_dict(checkpoint)
for m in model.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = True
with open(modeltxtpath, "w") as myfile: # record model
myfile.write(str(model))
model = model.to(device)
train(args, model)
print("========== TRAINING FINISHED ===========")
if __name__ == '__main__':
parser = TrainOptions().parse()
main(parser)
对应的config,configs/train_options.py
# -*- coding:utf-8 -*-
import argparse
import os
class TrainOptions():
def __init__(self):
self.parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
self.initialized = False
def initialize(self):
self.parser.add_argument('--cuda', action='store_true', default=True)
self.parser.add_argument('--model', default="idet", help='model to train,options:fcn8,segnet...')
self.parser.add_argument('--state')
self.parser.add_argument('--num-classes', type=int, default=2)
self.parser.add_argument('--datadir', default="./data_CMU/", help='path for training data')
self.parser.add_argument('--savedir', type=str, default='./save_models2022/IDET_CDnet/', help='savedir for models')
self.parser.add_argument('--lr', type=float, default=1e-3)
self.parser.add_argument('--num-epochs', type=int, default=50)
self.parser.add_argument('--num-workers', type=int, default=2)
self.parser.add_argument('--batch-size', type=int, default=4)
self.parser.add_argument('--epoch-save', type=int,
default=10) # You can use this value to save model every X epochs
self.parser.add_argument('--iouTrain', action='store_true',
default=False) # recommended: False (takes a lot to train otherwise)
self.parser.add_argument('--steps-loss', type=int, default=100)
self.parser.add_argument('--pretrained', type=str, default='./save_models2022/IDET_CDnet/idet_50.pth')
self.parser.add_argument('--local_rank', default=-1, type=int, help='node rank of distributed training')
self.initialized = True
def parse(self):
if not self.initialized:
self.initialize()
self.opt = self.parser.parse_args()
args = vars(self.opt)
print('------------ Options -------------')
for k, v in sorted(args.items()):
print('%s: %s' % (str(k), str(v)))
print('-------------- End ----------------')
return self.opt
configs/train_options.py参数改好后,直接运行train.py就行。
训练结束时生成的模型

4.预测
配置文件configs/test_options.py
#-*- coding:utf-8 -*-
import argparse
import os
class TestOptions():
def __init__(self):
self.parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
self.initialized = False
def initialize(self):
self.parser.add_argument('--cuda', action='store_true', default=True)
self.parser.add_argument('--model', default="idet", help='model to train,options:fcn8,segnet...')
self.parser.add_argument('--model-dir', default="./save_models2022/IDET/idet_20.pth", help='path to stored-model')
self.parser.add_argument('--num-classes', type=int, default=2)
# self.parser.add_argument('--datadir', default="./data_LiveCD/test/", help='path where image2.txt and label.txt lies')
# self.parser.add_argument('--datadir', default="./data_CMU/test/", help='path where image2.txt and label.txt lies')
# self.parser.add_argument('--datadir', default="./data_WHBCD/test_C/", help='path where image2.txt and label.txt lies')
self.parser.add_argument('--datadir', default="/home/wrf/4TDisk/CD/SG/data_AICD/CD/test_CC/", help='path where image2.txt and label.txt lies')
# self.parser.add_argument('-size', default=(320, 320), help='resize the test image')
self.parser.add_argument('-size', default=(256, 256), help='resize the test image')
self.parser.add_argument('--stored', default=True, help='whether or not store the result')
self.parser.add_argument('--savedir', type=str, default='./save_results2022/IDET_CDnet/', help='options. visualize the result of segmented picture, not just show IoU')
self.initialized = True
def parse(self):
if not self.initialized:
self.initialize()
self.opt = self.parser.parse_args()
args = vars(self.opt)
print('------------ Options -------------')
for k, v in sorted(args.items()):
print('%s: %s' % (str(k), str(v)))
print('-------------- End ----------------')
return self.opt
单独改了用于预测的函数,新增脚本infer.py
import os
import time
import torch
from configs.test_options import TestOptions
from torch.autograd import Variable
import numpy as np
from PIL import Image
from torch.utils.data import DataLoader
from dataloader.transform import Transform_inference
from dataloader.dataset import InferenceData
from models import get_model
import copy
def main(args):
despath = args.savedir
if not os.path.exists(despath):
os.makedirs(despath)
# os.mkdir(despath)
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
imagedir = os.path.join(args.datadir, 'image.txt')
image2dir = os.path.join(args.datadir, 'image2.txt')
transform = Transform_inference(args.size)
dataset_infer = InferenceData(imagedir, image2dir, transform)
loader = DataLoader(dataset_infer, num_workers=4, batch_size=1, shuffle=False) # test data loader
model = get_model(args)
if args.cuda:
model = model.cuda()
checkpoint = torch.load(args.model_dir)
model.load_state_dict(checkpoint)
model.eval()
count = 0
for step, colign in enumerate(loader):
images = colign[0]
images2 = colign[1]
# label = colign[2]
file_name = colign[-1]
folder_name = file_name[0]
# ----------street view datasets:-------
# image_name = file_name[0].split("/")[-1]
# folder_name = file_name[0].split("/")[-3]
# ---------------------------------------
# ---------remote sensing dataset--------
# basename = os.path.basename(file_name)
# ---------------------------------------
if args.cuda:
images = images.cuda()
images2 = images2.cuda()
inputs = Variable(images, volatile=True)
inputs2 = Variable(images2, volatile=True)
_, _, _, _, _, _, pf, _, _, _, _, _ = model(inputs, inputs2)
out_p = pf[0].cpu().max(0)[1].data.squeeze(0).byte().numpy()
if "CDnet" in args.datadir:
# image_name = file_name[0].split("/")[-1]
# pfolder_name = file_name[0].split("/")[-4]
# folder_name = file_name[0].split("/")[-3]
pfolder_name = 'pre'
if not os.path.exists(despath + pfolder_name + '/'):
os.makedirs(despath + pfolder_name + '/')
if not os.path.exists(despath + pfolder_name + '/' + folder_name):
os.makedirs(despath + pfolder_name + '/' + folder_name)
Image.fromarray(np.uint8(out_p * 255)).save(
despath + pfolder_name + '/' + folder_name)
elif "CMU" in args.datadir or "PCD" in args.datadir:
print(despath + folder_name)
Image.fromarray(np.uint8(out_p * 255)).save(despath + folder_name)
else:
Image.fromarray(np.uint8(out_p * 255)).save(despath + folder_name) # remote sensing datasets
print("This is the {}th of image!".format(count))
if __name__ == '__main__':
parser = TestOptions().parse()
parser.datadir = './data_CMU/test/'
parser.model_dir = './save_models2022/IDET_CDnet/idet_20.pth'
main(parser)
预测结果