PyTorch快速入门教程【小土堆】-神经网络-损失函数与反向传播
1.损失函数(代价函数)
损失函数就是用来表现预测与实际数据的差距程度
(1)作用:
a.用于计算实际输出和目标之间的差距,量化数据的偏移程度,也就是误差,误差越小越好
b.为我们更新输出提供一定的依据(反向传播)
(2)常用损失函数:
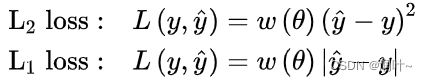
a.L1损失 nn.L1Loss:对估计值和真实值之差取绝对值,对偏离真实值的输出不敏感,因此在观测中存在异常值时有利于保持模型稳定。
b.L2损失 nn.MSELoss:L2损失通过平方计算放大了估计值和真实值的距离,因此对偏离观测值的输出给予很大的惩罚。此外,L2损失是平滑函数,在求解其优化问题时有利于误差梯度的计算;
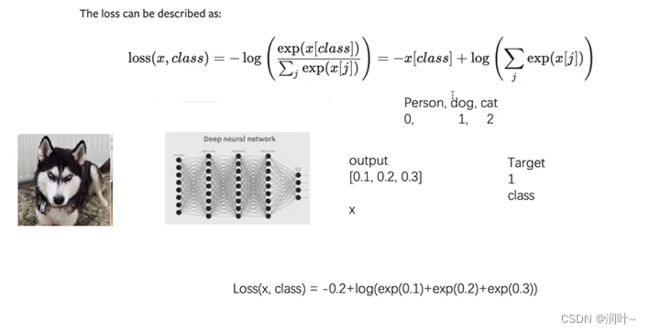
c. 交叉熵损失函数 nn.CrossEntropyLoss: 是分类中最常用的损失函数,交叉熵是用来度量两个概率分布的差异性的,用来衡量模型学习到的分布和真实分布的差异。
(3) 代码演示
import torch
from torch.nn import L1Loss
from torch import nn
input=torch.tensor([1,2,3],dtype=torch.float32)
targets=torch.tensor([1,2,5],dtype=torch.float32)
inputs=torch.reshape(input,[1,1,1,3])#batch_size=1,channel=1,尺寸1*3
#1.L1损失 误差和的平均值
targets=torch.reshape(targets,[1,1,1,3])
loss=L1Loss()
result=loss(input,targets)
print(result)
#2.L2损失 误差平方和的平均值
loss_mse=nn.MSELoss()
result_mse=loss_mse(input,targets)
print(result_mse)
#3.交叉熵 适用于 训练一个分类问题 这个问题有C个类别
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))#batch_size=1,clss=3 类别是3个
loss_cross=nn.CrossEntropyLoss()
result_closs=loss_cross(x,y)
print(result_closs)(4)在数据集上的演示
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.modul1=nn.Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.modul1(x)
return x
loss=nn.CrossEntropyLoss()
tudui=Tudui()
for data in dataloader:
imgs,targets=data
output=tudui(imgs)
result_loss=loss(output,targets)#计算误差
# print(result_loss)
#反向传播
result_loss.backward()
print("ok")