python的jieba库和词云图
1.安装第三方库
首先要实现中文分词和词云图,先要安装jieba库和wordcloud库,安装截图为jupyter notebook 安装的截图。
指令为:
pip install wordcloud
安装完成截图:

pip install jieba
安装完成截图:

2.中文分词库:jieba
中文分词也就是将一句话拆分成一些词语,例如“人生苦短,我学python”,可以拆分成“人生”,“苦短”,“我”,“用”,“python”。
我用一个简单的例子,如何用jieba库进行中文分词。
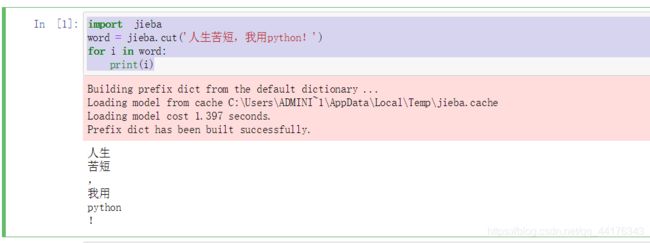
import jieba
word = jieba.cut('人生苦短,我用python!')
for i in word:
print(i)
运行结果如下:
接下来我们对网络下载的小说《天龙八部》进行中文分词,源代码如下:
import pandas as pd
import os
character = open('D:\\Python\\天龙八部人物表.txt',encoding='utf-8').read()
import re
data = re.split(r'\s+|:|,',character)
data = pd.DataFrame(data,columns =['姓名'])
data['词性'] = 'nr'
data.to_excel('D:\\Python\\天龙八部人物分词.xlsx',index = False,header = None)
#添加自定义词库
import jieba
#jieba.enable_parallel(4) #并行分词不支持windows系统
jieba.load_userdict('D:\\Python\\天龙八部人物词典.txt')
stopwords = [line.rstrip() for line in open('D:\\Python\\停用词表.txt',encoding = 'utf-8')]
def seg_sentence(sentence):
sentence_seged = jieba.cut(sentence.strip())
outstr = ''
for word in sentence_seged:
if word not in stopwords:
if word != '\t':
outstr+=word
outstr+=''
return outstr
inputs = open('D:\\Python\\天龙八部.txt','r',encoding='GB18030')
outputs = open('D:\\Python\\天龙八部分词.txt','w',encoding = 'utf-8')
for line in inputs:
line_seg =seg_sentence(line)
outputs.write(line_seg+'\n')
outputs.close()
inputs.close()
运行结果:

3.文本分析
(1)分词后,就可以进行文本分析,分析之前先加载一下分词后的txt文本。
text = open('D:\\Python\\天龙八部分词.txt',encoding ='utf-8').read()
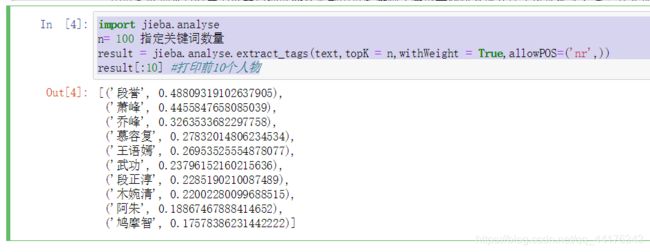
(2)指定词性,提取关键词,并打印出TF-IDF方法计算出的权重最大的前10人物。
import jieba.analyse
n= 100 指定关键词数量
result = jieba.analyse.extract_tags(text,topK = n,withWeight = True,allowPOS=('nr',))
result[:10] #打印前10个人物
运行结果:
4.设置云属性
keywords = dict()#关键词
for i in result:
keywords[i[0]] = i[1]
#设置词云属性
from PIL import Image
import numpy as np
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
image = Image.open('D:\\Python\\图片.jpeg')
graph = np.array(image)
wc = WordCloud(font_path='C:\Windows/Fonts/simsun.ttc',background_color = 'white',max_words = n,mask = graph)#字体,背景颜色,词云显示最大词数,背景样式
注意:有的同学可能找不见设置字体的文件,simsun.ttc文件到底在哪了,我们一起找一下:
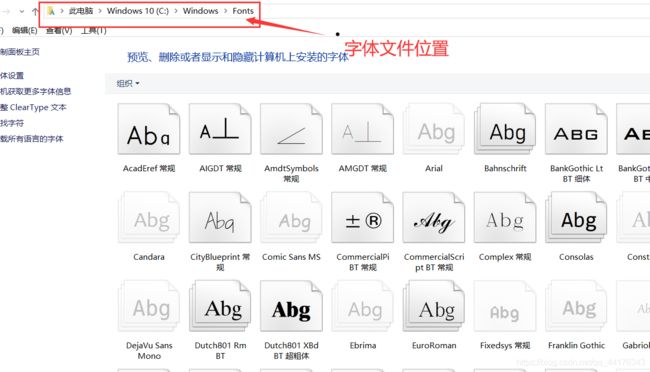
怎么写到代码中,我们鼠标右击点击属性查看:

这样我们就得到了font Path的具体内容;
5.生成词云
wc.generate_from_frequencies(keywords)
plt.imshow(wc)
image_color=ImageColorGenerator(graph)
plt.imshow(wc.recolor(color_func = image_color))
plt.axis("off")
plt.show()
wc.to_file('词云.jpg')
运行结果:
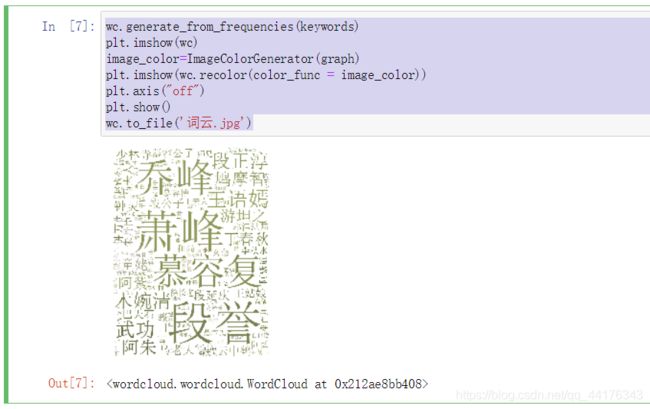
查看生成的“词云.jpg”文件。

参考书籍:python机器学习——数据分析与评分卡建模(微课版)