YOLOV5部署全系列教程(2)
YOLOV5部署全系列教程(2)
本篇是系列教程记录第二篇,主要讲述基于jetson NX开发板进行yolov5的一个部署。
文章目录
- YOLOV5部署全系列教程(2)
- 一、yolov5环境部署
-
- 1.matplotlib安装
-
- 1.1第一种
- 1.2第二种
- 2.pytorch安装
- 二、tensoRT加速
- 总结
一、yolov5环境部署
在部署环境之前,首先进行开发板的刷机处理,本人参考的某位大佬的部署教程,传送门在这,大家亦可参考,这里不过多介绍。
在刷完机,应该显示的是Ubuntu18.04的版本,现在开始部署yolov5的环境,和之前一样,本文采用的4.0的版本,各位可以根据各自需求选择相应的版本。
在部署环境之前,本人强调希望不要构建conda环境,因为架构的原因,部署conda环境时,可能会出现各类第三方库无法安装,或者安装好找不到的现象。
这里直接建议直接在原生的python3.6的环境进行安装(这里强调一定是python3.6版本)因为英伟达官方只给出了3.6版本的torch编译版本。
1.matplotlib安装
首先是matplotlib包安装,若使用
pip install matplotlib
进行安装,大概率是会报错的,其原因就是架构问题,需要为开发板的arrch架构重新编译wheel,本文提供两种方法,建议使用第二种。
1.1第一种
不使用pip进行安装,使用系统安装指令进行,但这样无法确定版本号
sudo apt-get install python3-matplotlib
1.2第二种
直接下载以及编译好的wheel,直接进行build,这里提供我下载好的3.3.3版本,传送门在这提取码:5tlq
pip install matplotlib-3.3.3-cp36-cp36m-linux_aarch64.whl
2.pytorch安装
安装pytorch是,千万不要使用pip install torch 这个指令,虽然使用这个指令也可以安装上,但是在后续使用时会出现cuda unavailable的情况,无法使用GPU,因此需要同安装matplotlib一样,下载编译好的wheel进行安装,由于nvidia官方只给出了python3.6版本的wheel,这就是为什么之前强调一定使用python3.6版本的原因,如果是其他版本的python则需要重新编译,大概耗时五到六个小时,且不保证一定会编译正确。
这里提供官方的下载地址传送门在这里面有torch各个版本的下载地址,但是貌似需要梯子才能下载。这里我也提供本人所下载的torch1.8版本wheel,传送门在这torch-1.8.0-cp36-cp36m-linux_aarch64.whl 提取码:s92e
pip install torch-1.8.0-cp36-cp36m-linux_aarch64.whl
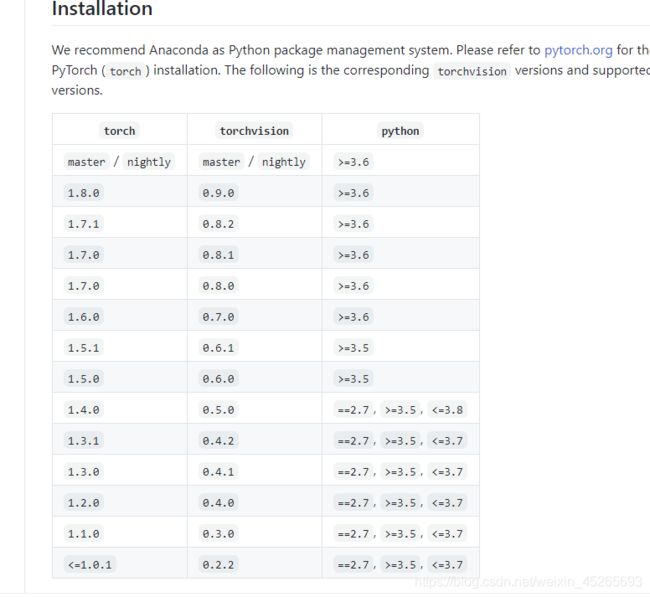
安装好torch后,需要安装对应版本的torchvision,具体对应的版本在这里下载https://github.com/pytorch/vision
在对应的tag中选择你要下载的版本,下载好后直接cd到文件夹中,进行安装
cd torchvision
sudo python3 setup.py install
如果出现illegal instruction,只需在后面加上–user就好了。
python3 setup.py install --user
至此torch安装完成。
测试一下
输入python或者python3打开python编辑器
import torch
torch.__version__
import torchvision
torchvision.__version__
torch.cuda.is_available()
如果结果都对应上了,恭喜你安装成功。
如果遇到OSError: libmpi_cxx.so.20: cannot open shared object file: No such file or directory这类问题,这里有解决方案,传送门在这。
如果其他库也顺利安装上了,至此就可以开始在开发板上进行原生yolov5的测试了。
二、tensoRT加速
刷完机后开发板Jetpack本身自带tensorRT,这个可以通过这个链接进行查看,传送门在这。
下面就可以部署tensorRT加速了,这里感谢wangxinyu大佬做好的各个网络的加速版本,传送门在这,大家可以找自己的想要的版本。
按照这里面的教程应该就可以实现yolov5的部署,但是这里面只有对图片进行检测,本人稍加修改加入了视频检测的功能。传送门在这
主要修改了yolov5.cpp,暂且记为yolov5_v.cpp
#include (end - start).count() << "ms" << std::endl;
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(img, res[j].bbox);
cv::rectangle(img, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
//cv::putText(img, std::to_string((int)res[j].class_id), cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(img, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
}
cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
fcount = 0;
}
}
if(!vedio_dir.empty()){
//cv::VideoCapture capture(0);//'0,1,2...'represent the camera
cv::VideoCapture capture(vedio_dir);
//int fourcc = cv::VideoWriter::fourcc('M','J','P','G');
//capture.set(cv::CAP_PROP_FOURCC, fourcc);
if(!capture.isOpened()){
std::cout << "Error opening video stream or file" << std::endl;
return -1;
}
int key;
int fcount = 0;
cv::Mat frame;
while(1)
{
capture >> frame;
if(frame.empty())
{
std::cout << "Fail to read image from vedio!" << std::endl;
break;
}
fcount++;
//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;
for (int b = 0; b < fcount; b++) {
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
cv::Mat img = frame;
if (img.empty()) continue;
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
//std::cout << std::chrono::duration_cast(end - start).count() << "ms" << std::endl;
int fps = 1000.0/std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout<<"fps:"<<fps<<std::endl;
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
std::string jetson_fps = "Jetson NX FPS: " + std::to_string(fps);
cv::putText(frame, jetson_fps, cv::Point(11,80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5",frame);
key = cv::waitKey(1);
if (key == 'q'){
break;
}
fcount = 0;
}
capture.release();
}
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
// Print histogram of the output distribution
//std::cout << "\nOutput:\n\n";
//for (unsigned int i = 0; i < OUTPUT_SIZE; i++)
//{
// std::cout << prob[i] << ", ";
// if (i % 10 == 0) std::cout << std::endl;
//}
//std::cout << std::endl;
return 0;
}
具体编译流程请看传送门的readme。
./yolov5_v -s ../yolov5s.wts ../yolov5s.engine s
测试视频
./yolov5_v -d ../yolov5s.engine v ../test1.mp4
or 测试图片
./yolov5_v -d ../yolov5s.engine i ../smaple/
总结
本文简单记录一下自己的jetson NX的部署流程,若有其他疑问欢迎大家批评指正!