pytorch问题索引
20220629
调试代码时候,找不到入口,通过下面的位置进入

20220613




各种归一化在nlp和cv中的输入输出维度
参数只包括权重,不包括偏置
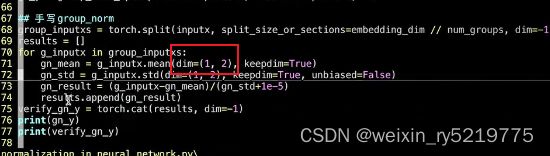
这两个维度的范围不包括,不计算,而是在剩下的维度进行计算
concat(dim=-1):最后一个维度就是行向量,就是横向扩展
nums_featurers:NLP:词嵌入维度,图片的话是通道?

层归一化:仅仅对嵌入向量层进行归一化
批归一化:对批维度下进行归一化
实例归一化:用在风格迁移上,同一个batch下,在所有通道,把所有时间步的点进行归一化,减去所有时刻不变的东西(样本的风格,把图像的风格和语音中人的身份给消除了?类别协同过滤),留下有差异的部分,
组归一化:对输入样本进行分组,对每个分组进行归一化和batchsize无关,nlp的num_channel是embedding_dim?
权重归一化:上面四个是对每一层的输入进行归一化,这里是对权重进行归一化
keep_dim:把在某个维度上计算的结果,复制拷贝到其他剩余的维度
sampler:就是batchsize层面还是每个具体样本?
层归一化:RNN每一步就是一层
对张量维度的理解:从右往左,不同层级的中括号,范围越来越大,每一层的单个元素都是由下一层级整个范围所构成
nlp中每批每个句子长度不一样,而且预测句子长度也不一定与训练数据一致,所以不常用batchnorm
二用layernorm
over/across batch或者dimension:跨batch,跨维度,仅仅局限于一个batch或者某个维度进行处理
keep_dim:保持输出和输入维度一致
算某个指标的时候,包含的维度越多,也就意味着所覆盖的元素范围越多

tensor*tensor:广播到每一层,对应位置元素相乘
乘法
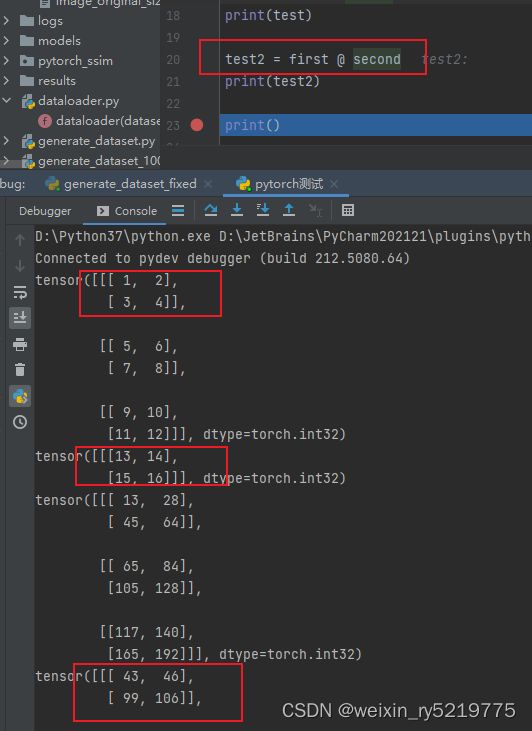
tensor@tensor是矩阵内积操作,广播到每一层
20220608
注册模块通过字典来注册
apply:递归的应用到某些函数上面
parameter和buffer:buffer是parameter的均值,方差等 slot_parameter?

nn.sequential是container容器
linear(in_size,out_size)是神经元节点
conv2d(in,out) in,out是通道数

维度可以理解为元组里面的索引
![]()
torchsummary:打印网络结构和参数数目
xx(input)就等同于调用 xx.forward()
随机种子设置不止要对pytorch设置,manul_seed ,numpy也要设置
python看不到源码,说明不是python代码写的
BrokenPipeError: [Errno 32] Broken pipe
https://blog.csdn.net/qq_33666011/article/details/81873217
num_works的问题
20220601
parameter和buffer的 names。
buffer是临时保存的对象,并不属于模型参数,比如BatchNorm’s running_mean
ImportError: No module named 'tensorboardX'
pip3 install tensorboardX
self = reduction.pickle.load(from_parent) EOFError: Ran out of input的解决方法
https://blog.csdn.net/weixin_44025103/article/details/124886754
20220530
https://blog.csdn.net/gulaixiangjuejue/article/details/108592941
RuntimeError: expected dtype Double but got dtype Float 问题解决
或者单独转换为相同的数据格式
tensor和array输出全部值,显示全部值
torch.set_printoptions(profile="full") # 全部数据
torch.set_printoptions(profile="default") # 默认部分数据
import sys
np.set_printoptions(threshold=sys.maxsize)
20220526
https://blog.csdn.net/cpluss/article/details/90260550
gather
torch.gather(input, dim, index, out=None) → Tensor
torch.gather(t, 1, torch.LongTensor([[0,0],[1,0]]))
在指定维度,取出索引所在位置的数值
20210623
RuntimeError: expected device cpu and dtype Float but got device cpu and dtype Bool ()
调试到对应的位置 查看具体哪个变量的类型不对
20210622
https://blog.csdn.net/weixin_41041772/article/details/109820870
通俗理解torch.distributed.barrier()工作原理
20210614
https://blog.csdn.net/scut_salmon/article/details/82414730
optimizer.zero_grad()意思是把梯度置零,也就是把loss关于weight的导数变成0.
torch代码解析 为什么要使用optimizer.zero_grad()
https://www.zhihu.com/question/303070254/answer/573504133
每个batch的梯度是单独计算的 是按批次更新的 而不是按全部数据更新的
https://www.cnblogs.com/wanghui-garcia/p/11399053.html
pytorch torch.nn 实现上采样——nn.Upsample
torch.nn.Module.apply(fn)
https://blog.csdn.net/m0_46653437/article/details/112649816
the parameters of a model (see also torch-nn-init).
将一个函数fn递归地应用到模块自身以及该模块的每一个子模块(即在函
数.children()中返回的子模块).该方法通常用来初始化一个模型中的参数(另见
torch-nn-init部分的内容).
https://www.cnblogs.com/wmc258/p/14539677.html
torch.nn.init.normal(tensor, mean=0, std=1)
从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
参数:
tensor – n维的torch.Tensor
mean – 正态分布的均值
std – 正态分布的标准差
torch.nn.Init.normal_()的用法
20210609
https://www.zhihu.com/question/288350769
torch.manual_seed(1)
https://blog.csdn.net/zziahgf/article/details/78489562
计算 Log-Sum-Exp
https://www.zhihu.com/question/402741396
clone()
https://blog.csdn.net/kdongyi/article/details/108180250
Pytorch中contiguous()函数理解
相当于深拷贝
self.optimizer = self._decay_learning_rate(epoch=epoch - 1, init_lr=self.config.learning_rate)
#直接改写为adam
# self.optimizer=torch.optim.Adam(self.optimizer.param_groups,lr=self.config.learning_rate)
self.optimizer=torch.optim.Adam(self.model.parameters,lr=self.config.learning_rate)
设置优化器
https://blog.csdn.net/qq_40367479/article/details/82530324
decay_rate是衰减指数,可设为略小于1的值,比如0.98。global_step是当前的迭代轮数,decay_steps是你想要每迭代多少轮就衰减的度量值,可叫作衰减速度。比如decay_steps = 1000,意味着当global_step达到1000时就给learning_rate乘上0.98的一次方,达到2000就乘上0.98的二次方,以此类推,不断缩小学习率。
另一种方法
# 自己写的学习率衰减函数
def _decay_learning_rate(self, epoch, init_lr):
"""lr decay
Args:
epoch: int, epoch
init_lr: initial lr
"""
lr = init_lr / (1 + self.config.lr_rate_decay * epoch)
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
return self.optimizer
学习率衰减(learning rate decay)
https://blog.csdn.net/jining11/article/details/103825447
pytorch加载模型时使用map_location来在CPU、GPU间辗转腾挪
https://blog.csdn.net/qq_39852676/article/details/106326580
pytorch中model.to(device)和map_location=device的区别
20210608
https://blog.csdn.net/xu380393916/article/details/97280035
pytorch 中的 forward 的使用与解释
https://blog.csdn.net/u011501388/article/details/84062483
PyTorch之前向传播函数forward
https://blog.csdn.net/qq_41375609/article/details/102891831
hook

标量没有维度
列表有维度
20210422
解决安装torchvision自动更新torch到最新版本
不使用pip install torchvision == 0.4.0
使用pip install --no-deps torchvision == 0.4.0
完美解决安装完torchvision之后继续更新torch到1.2.0版本(目前最新版)。
20210420
https://zhuanlan.zhihu.com/p/108342960
pytorch项目
20210128
https://blog.csdn.net/kyle1314608/article/details/113758100
pytorch常用代码
RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 4792320 bytes. Buy new RAM!
报这个错的时候 可以更改bert预训练模型的json 参数
比如少用几层 每层少用几个头
也就是少用一些参数
tf_model.h5,model.ckpt.index
和
pytorch_model.bin
是并列关系 用pytorch 就用下面
用tf就用上面的训练模型
20201219
https://blog.csdn.net/kyle1314608/article/details/111405214
tensor和模型 保存与加载 PyTorch
20201210
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
原因是变量没有设置为require_grad=True 没有设置梯度更新为True
或者叫梯度不更新的问题
import torch
from torch import Variable
x=torch.randn(3)
x=Variable(x,requires_grad=True)#生成变量
print(x)#输出x的值
y=x*2
y.backward(torch.FloatTensor([1,0.1,0.01]))#自动求导
print(x.grad)#求对x的梯度
通过上面把任何变量设置需要梯度更新
https://blog.csdn.net/kyle1314608/article/details/110959432
numpy转tensor 并有梯度更新
dim 维度的方向
https://www.cnblogs.com/jiangkejie/p/9981707.html
detach
https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-autograd
https://ptorch.com/docs/2/developer-docs
说明书 手册 指南
20201202
https://blog.csdn.net/kyle1314608/article/details/110489180
数据类型转换
https://blog.csdn.net/kyle1314608/article/details/110486424
#测试
aa=torch.zeros([2,2])
bb=torch.zeros([2,3])
cc=torch.cat((aa,bb),1)
#测试
torch 拼接
某个矩阵列数要增加 且填充为零 padding
loss = -(target * logsigmoid(input) + (1 - target) * logsigmoid(-input))
RuntimeError: expected device cpu and dtype Float but got device cpu and dtype Long
把target 和 input 由 target.long() 改成 target.float()
dataTar = torch.from_numpy(dataTar)
TypeError: can’t convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.
把ndarray里面字符型的元素转换为数值
Python报错xxx.whl is not a supported wheel on this platform
linux 现在安装pytorch版本和本地安装的python版本不一致
bug提示某个对象的某种属性无效了,一般情况下是因为软件版本的变更造成的
降低软件版本,或者把属性改成当前的属性
tensor 转 array 再转list
pred=np.array(pred).tolist()
RuntimeError: Assertion cur_target 0 cur_target n_classes failed
网络分类标签应该跟真实分类标签一样多
分类标签必须从零开始
分类标签必须连续 1 2 34 等
https://blog.csdn.net/qq_28418387/article/details/97971328
pytorch 构建tensor
https://blog.csdn.net/qq_42146630/article/details/98784062
Pytorch手写数字识别(一)
https://blog.csdn.net/Lee_lg/article/details/103901632
Python模块问题:ImportError: cannot import name ‘PILLOW_VERSION’ from ‘PIL’
https://blog.csdn.net/Albert201605/article/details/79893585
MNIST 数据集 转换为CSV
https://blog.csdn.net/zhe_csdn/article/details/93655053
pytorch的Tensor变量之间的转换
RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes’ failed. at
https://blog.csdn.net/m0_37369043/article/details/102632297
标签必须从零开始
https://pytorch-cn.readthedocs.io/zh/latest/package_references/Tensor/
# https://www.w3cschool.cn/pytorch/pytorch-uvpm3bm3.html
# https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch/
pytorch中文文档 重点